 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Offline Selectors Cannot Beat the Best Single Model: A Diagnostic Study on edX Dropout Prediction
Jun 02, 2026Different predictors often excel on different inputs, so picking the best one per instance promises higher accuracy than committing to a single model. In practice, selectors trained from logged data routinely fail to beat the strongest single predictor. Three causes typically go unseparated before more tuning is applied: a mismatched learner, a state that does not predict which model wins, or buffer-to-deployment label shift. A three-stage diagnostic rules them out on a shared buffer. Stage~1 estimates a local ceiling on oracle recovery from $k$-NN label consistency. Stage~2 asks whether paired BC and offline-RL learners (BC, DQN, and CQL across penalty weights) reach that ceiling. Stage~3 ablates the selector state to test whether richer features would raise it. The combined verdict points to the most promising next step: tuning the learner, redesigning the state, or collecting new data. We apply it to selecting among five dropout-prediction models on edX clickstream data. Across 16 windows, the oracle beats the strongest single base model by 9.7 accuracy points on average, yet BC, DQN, and CQL land in the same test-accuracy band below it (robust to a tenfold buffer sweep and $N{=}2{,}000$ held-out examples). The bottleneck is local representational ambiguity: CQL closes the imitation gap without a deployment gain (not conservatism), regret clusters tightly across learners (not tie-breaking), and the three learners converge on test accuracy (not shift). The next iteration should change the state or collect new data, not tune the offline learner further.
Extending the Hint Factory for the assistance dilemma: A novel, data-driven HelpNeed Predictor for proactive problem-solving help
Oct 08, 2020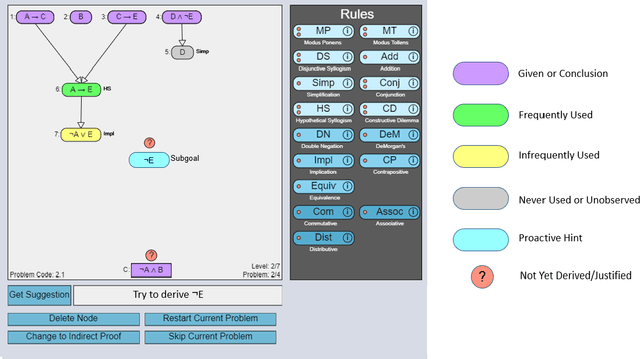
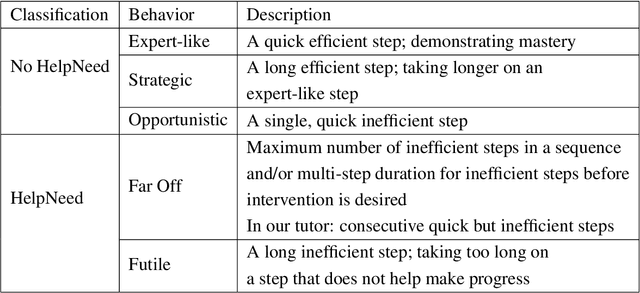
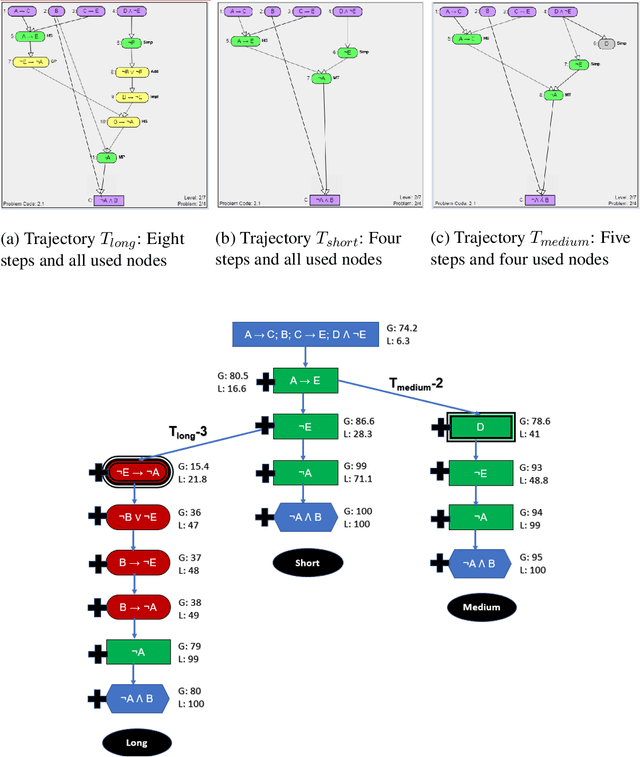

Determining when and whether to provide personalized support is a well-known challenge called the assistance dilemma. A core problem in solving the assistance dilemma is the need to discover when students are unproductive so that the tutor can intervene. Such a task is particularly challenging for open-ended domains, even those that are well-structured with defined principles and goals. In this paper, we present a set of data-driven methods to classify, predict, and prevent unproductive problem-solving steps in the well-structured open-ended domain of logic. This approach leverages and extends the Hint Factory, a set of methods that leverages prior student solution attempts to build data-driven intelligent tutors. We present a HelpNeed classification, that uses prior student data to determine when students are likely to be unproductive and need help learning optimal problem-solving strategies. We present a controlled study to determine the impact of an Adaptive pedagogical policy that provides proactive hints at the start of each step based on the outcomes of our HelpNeed predictor: productive vs. unproductive. Our results show that the students in the Adaptive condition exhibited better training behaviors, with lower help avoidance, and higher help appropriateness (a higher chance of receiving help when it was likely to be needed), as measured using the HelpNeed classifier, when compared to the Control. Furthermore, the results show that the students who received Adaptive hints based on HelpNeed predictions during training significantly outperform their Control peers on the posttest, with the former producing shorter, more optimal solutions in less time. We conclude with suggestions on how these HelpNeed methods could be applied in other well-structured open-ended domains.