 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TAPER: Time-Aware Patient EHR Representation
Aug 16, 2019
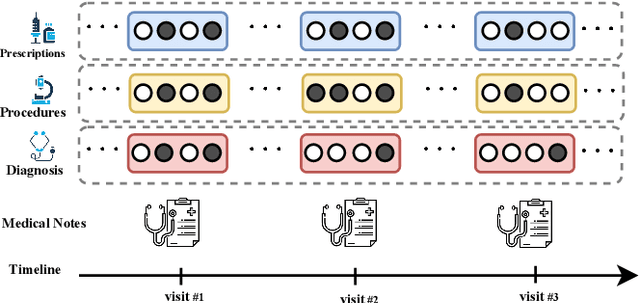
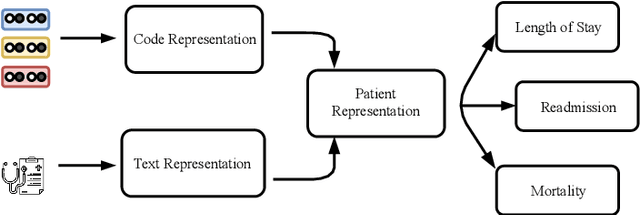
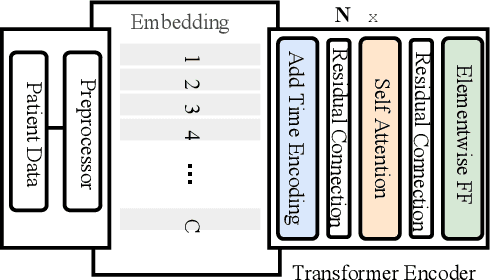
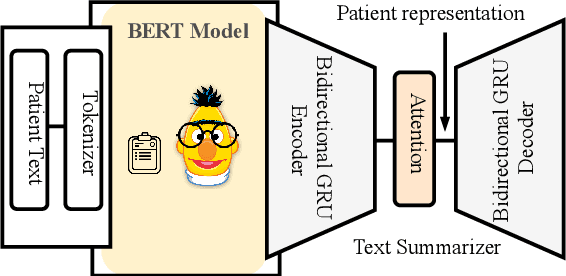
Effective representation learning of electronic health records is a challenging task and is becoming more important as the availability of such data is becoming pervasive. The data contained in these records are irregular and contain multiple modalities such as notes, and medical codes. They are preempted by medical conditions the patient may have, and are typically jotted down by medical staff. Accompanying codes are notes containing valuable information about patients beyond the structured information contained in electronic health records. We use transformer networks and the recently proposed BERT language model to embed these data streams into a unified vector representation. The presented approach effectively encodes a patient's visit data into a single distributed representation, which can be used for downstream tasks. Our model demonstrates superior performance and generalization on mortality, readmission and length of stay tasks using the publicly available MIMIC-III ICU dataset.
Path Dependent Structural Equation Models
Aug 24, 2020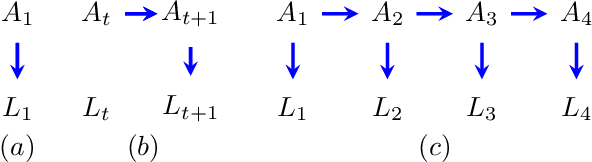
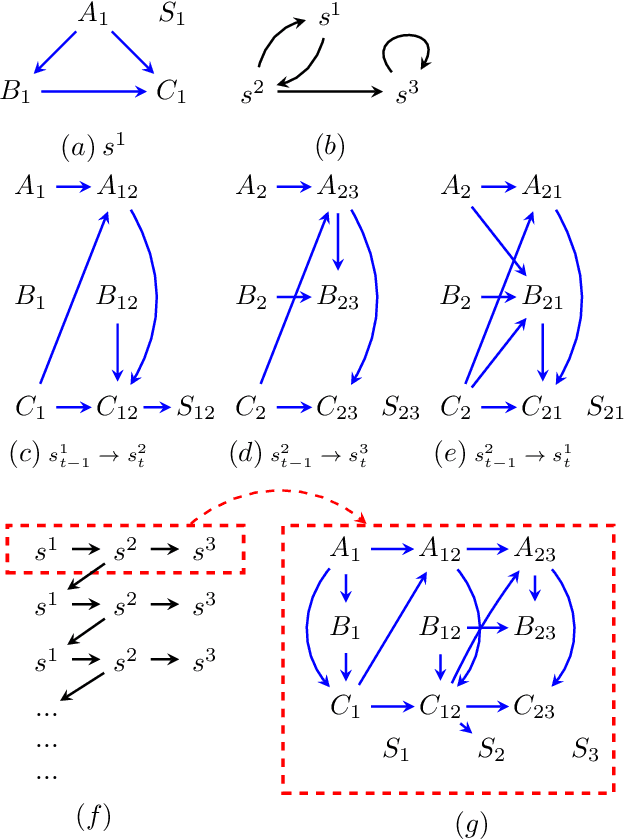
Causal analyses of longitudinal data generally assume structure that is invariant over time. Graphical causal models describe these data using a single causal diagram repeated at every time step. In structured systems that transition between qualitatively different states in discrete time steps, such an approach is deficient on two fronts. First, time-varying variables may have state-specific causal relationships that need to be captured. Second, an intervention can result in state transitions downstream of the intervention different from thoseactually observed in the data. In other words, interventions may counterfactually alter the subsequent temporal evolution of the system. We introduce a generalization of causal graphical models, Path Dependent Structural Equation Models (PDSEMs), that can describe such systems. We show how causal inference may be performed in such models and illustrate its use in simulations and data obtained from a septoplasty surgical procedure.
Splitting Gaussian Process Regression for Streaming Data
Oct 06, 2020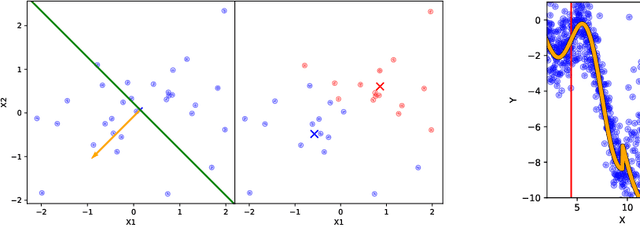
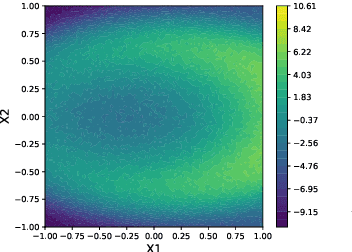
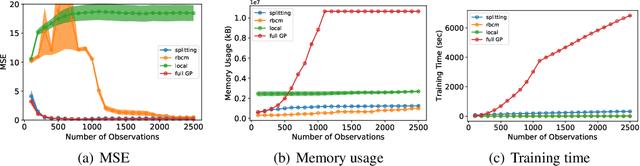
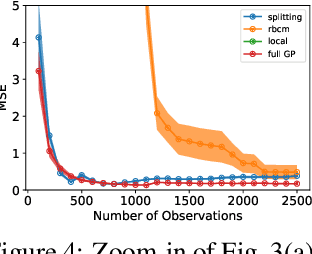
Gaussian processes offer a flexible kernel method for regression. While Gaussian processes have many useful theoretical properties and have proven practically useful, they suffer from poor scaling in the number of observations. In particular, the cubic time complexity of updating standard Gaussian process models make them generally unsuitable for application to streaming data. We propose an algorithm for sequentially partitioning the input space and fitting a localized Gaussian process to each disjoint region. The algorithm is shown to have superior time and space complexity to existing methods, and its sequential nature permits application to streaming data. The algorithm constructs a model for which the time complexity of updating is tightly bounded above by a pre-specified parameter. To the best of our knowledge, the model is the first local Gaussian process regression model to achieve linear memory complexity. Theoretical continuity properties of the model are proven. We demonstrate the efficacy of the resulting model on multi-dimensional regression tasks for streaming data.
Estimating Traffic Speeds using Probe Data: A Deep Neural Network Approach
Apr 19, 2021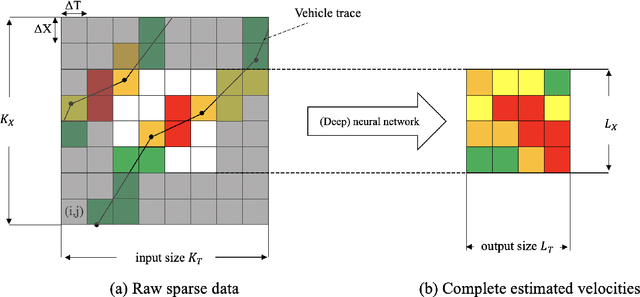
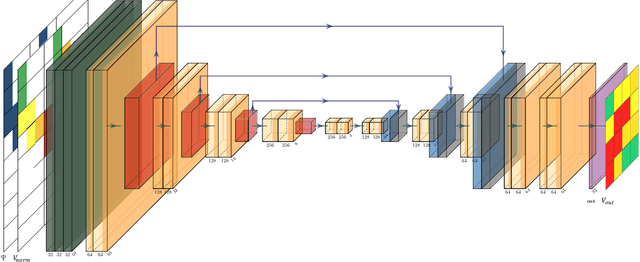
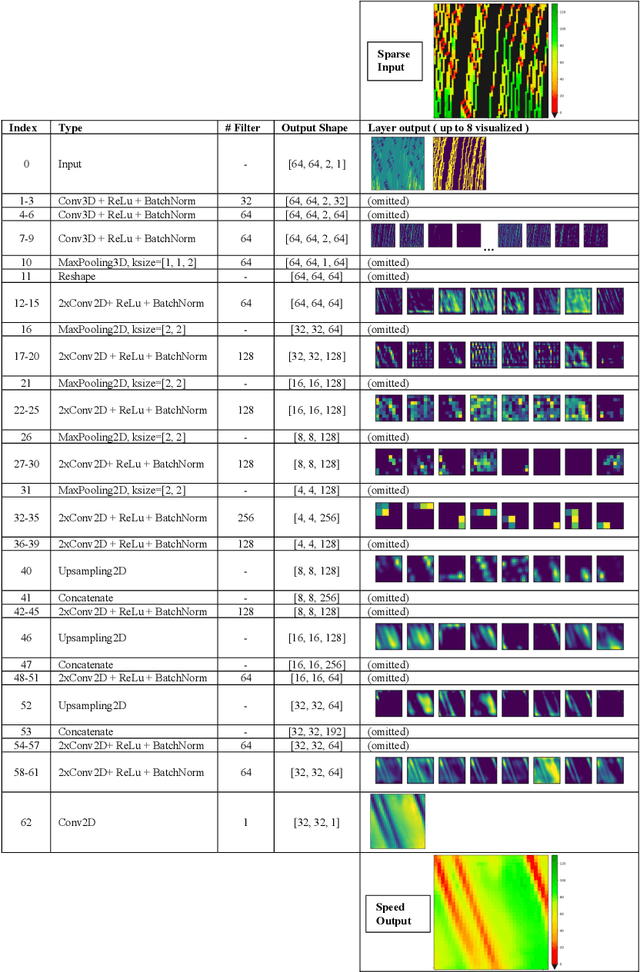

This paper presents a dedicated Deep Neural Network (DNN) architecture that reconstructs space-time traffic speeds on freeways given sparse data. The DNN is constructed in such a way, that it learns heterogeneous congestion patterns using a large dataset of sparse speed data, in particular from probe vehicles. Input to the DNN are two equally sized input matrices: one containing raw measurement data, and the other indicates the cells occupied with data. The DNN, comprising multiple stacked convolutional layers with an encoding-decoding structure and feed-forward paths, transforms the input into a full matrix of traffic speeds. The proposed DNN architecture is evaluated with respect to its ability to accurately reconstruct heterogeneous congestion patterns under varying input data sparsity. Therefore, a large set of empirical Floating-Car Data (FCD) collected on German freeway A9 during two months is utilized. In total, 43 congestion distinct scenarios are observed which comprise moving and stationary congestion patterns. A data augmentation technique is applied to generate input-output samples of the data, which makes the DNN shift-invariant as well as capable of managing varying data sparsities. The DNN is trained and subsequently applied to sparse data of an unseen congestion scenario. The results show that the DNN is able to apply learned patterns, and reconstructs moving as well as stationary congested traffic with high accuracy; even given highly sparse input data. Reconstructed speeds are compared qualitatively and quantitatively with the results of several state-of-the-art methods such as the Adaptive Smoothing Method (ASM), the Phase-Based Smoothing Method (PSM) and a standard Convolutional Neural Network (CNN) architecture. As a result, the DNN outperforms the other methods significantly.
Exploiting Underlay Spectrum Sharing in Cell-Free Massive MIMO Systems
Apr 19, 2021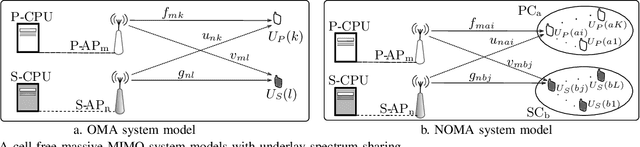
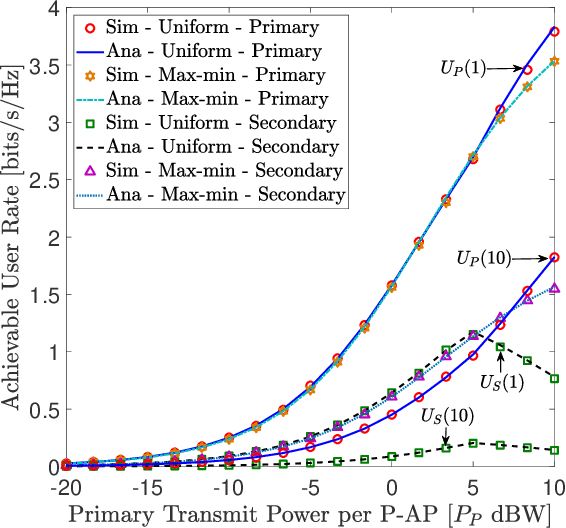
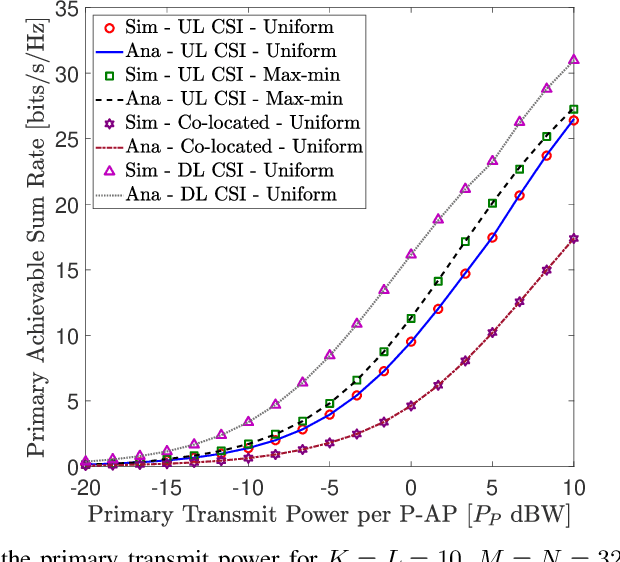
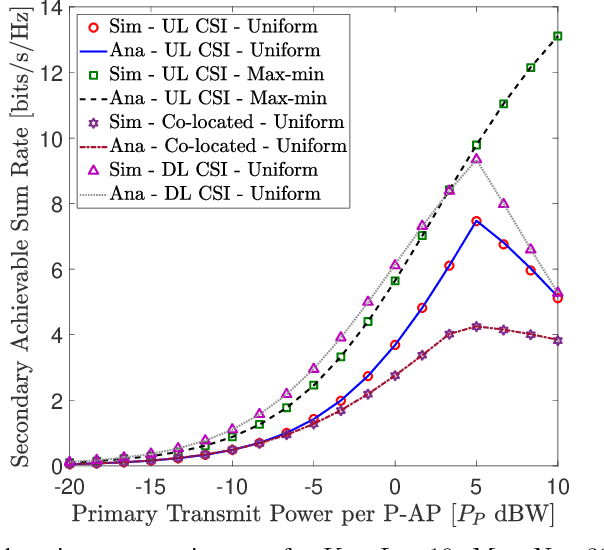
We investigate the coexistence of underlay spectrum sharing in cell-free massive multiple-input multiple-output (MIMO) systems. A primary system with geographically distributed primary access points (P-APs) serves a multitude of primary users (PUs), while a secondary system serves a large number of secondary users (SUs) in the same primary/licensed spectrum by exploiting the underlay spectrum sharing. To mitigate the secondary co-channel interference inflected at PUs, stringent secondary transmit power constraints are defined for the secondary access points (S-APs). A generalized pilots sharing scheme is used to locally estimate the uplink channels at P-APs/S-APs, and thereby, conjugate precoders are adopted to serve PUs/SUs in the same time-frequency resource element. Moreover, the effect of a user-centric AP clustering scheme is investigated by assigning a suitable set of APs to a particular user. The impact of estimated downlink (DL) channels at PUs/SUs via DL pilots beamformed by P-APs/S-APs is investigated. The achievable primary/secondary rates at PUs/SUs are derived for the statistical DL and estimated DL CSI cases. User-fairness for PUs/SUs is achieved by designing efficient transmit power control policies based on a multi-objective optimization problem formulation of joint underlay spectrum sharing and max-min criteria. The proposed orthogonal multiple-access based analytical framework is also extended to facilitate non-orthogonal multiple-access. Our analysis and numerical results manifest that the primary/secondary performance of underlay spectrum sharing can be boosted by virtue of the average reduction of transmit powers/path-losses, uniform coverage/service, and macro-diversity gains, which are inherent to distributed transmissions/receptions of cell-free massive MIMO.
Towards Utility-based Prioritization of Requirements in Open Source Environments
Feb 17, 2021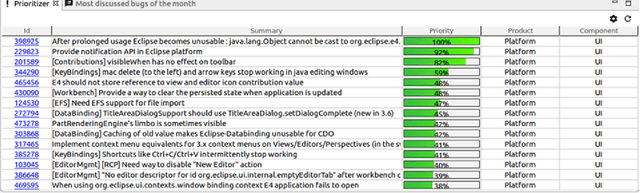
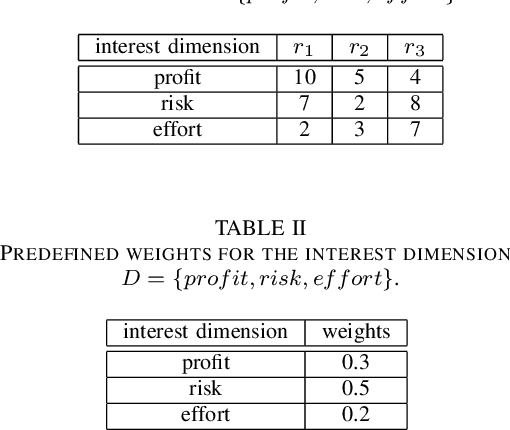


Requirements Engineering in open source projects such as Eclipse faces the challenge of having to prioritize requirements for individual contributors in a more or less unobtrusive fashion. In contrast to conventional industrial software development projects, contributors in open source platforms can decide on their own which requirements to implement next. In this context, the main role of prioritization is to support contributors in figuring out the most relevant and interesting requirements to be implemented next and thus avoid time-consuming and inefficient search processes. In this paper, we show how utility-based prioritization approaches can be used to support contributors in conventional as well as in open source Requirements Engineering scenarios. As an example of an open source environment, we use Bugzilla. In this context, we also show how dependencies can be taken into account in utility-based prioritization processes.
CAPTRA: CAtegory-level Pose Tracking for Rigid and Articulated Objects from Point Clouds
Apr 08, 2021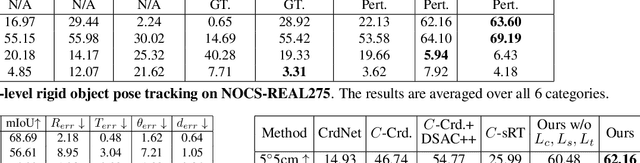
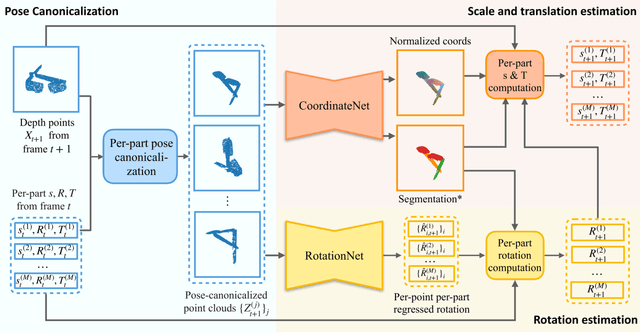
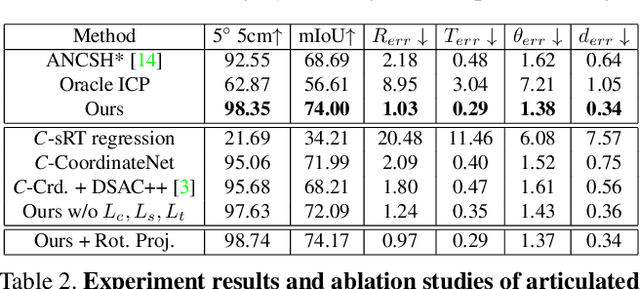
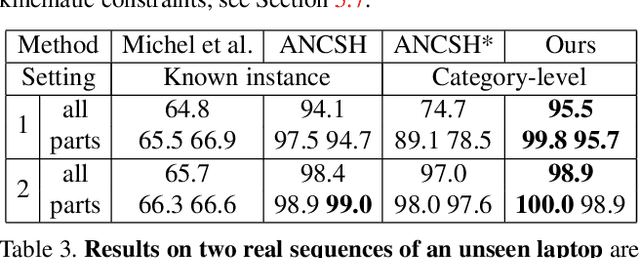
In this work, we tackle the problem of category-level online pose tracking of objects from point cloud sequences. For the first time, we propose a unified framework that can handle 9DoF pose tracking for novel rigid object instances as well as per-part pose tracking for articulated objects from known categories. Here the 9DoF pose, comprising 6D pose and 3D size, is equivalent to a 3D amodal bounding box representation with free 6D pose. Given the depth point cloud at the current frame and the estimated pose from the last frame, our novel end-to-end pipeline learns to accurately update the pose. Our pipeline is composed of three modules: 1) a pose canonicalization module that normalizes the pose of the input depth point cloud; 2) RotationNet, a module that directly regresses small interframe delta rotations; and 3) CoordinateNet, a module that predicts the normalized coordinates and segmentation, enabling analytical computation of the 3D size and translation. Leveraging the small pose regime in the pose-canonicalized point clouds, our method integrates the best of both worlds by combining dense coordinate prediction and direct rotation regression, thus yielding an end-to-end differentiable pipeline optimized for 9DoF pose accuracy (without using non-differentiable RANSAC). Our extensive experiments demonstrate that our method achieves new state-of-the-art performance on category-level rigid object pose (NOCS-REAL275) and articulated object pose benchmarks (SAPIEN , BMVC) at the fastest FPS ~12.
Offboard 3D Object Detection from Point Cloud Sequences
Mar 08, 2021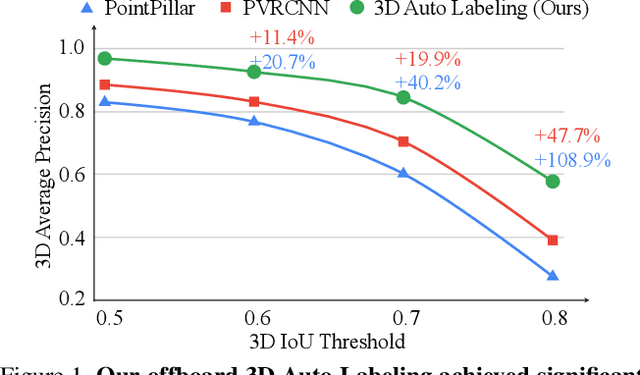
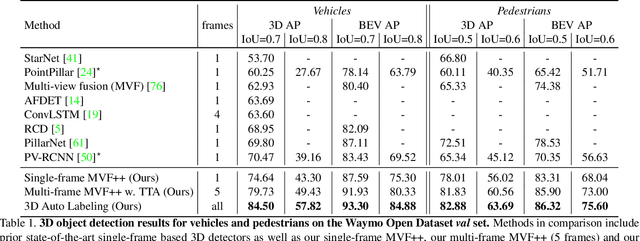
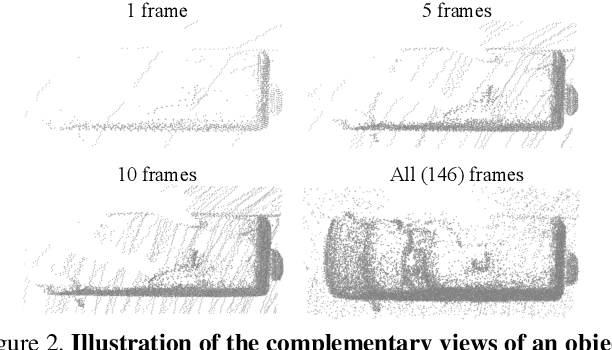

While current 3D object recognition research mostly focuses on the real-time, onboard scenario, there are many offboard use cases of perception that are largely under-explored, such as using machines to automatically generate high-quality 3D labels. Existing 3D object detectors fail to satisfy the high-quality requirement for offboard uses due to the limited input and speed constraints. In this paper, we propose a novel offboard 3D object detection pipeline using point cloud sequence data. Observing that different frames capture complementary views of objects, we design the offboard detector to make use of the temporal points through both multi-frame object detection and novel object-centric refinement models. Evaluated on the Waymo Open Dataset, our pipeline named 3D Auto Labeling shows significant gains compared to the state-of-the-art onboard detectors and our offboard baselines. Its performance is even on par with human labels verified through a human label study. Further experiments demonstrate the application of auto labels for semi-supervised learning and provide extensive analysis to validate various design choices.
Co-occurrences using Fasttext embeddings for word similarity tasks in Urdu
Feb 22, 2021
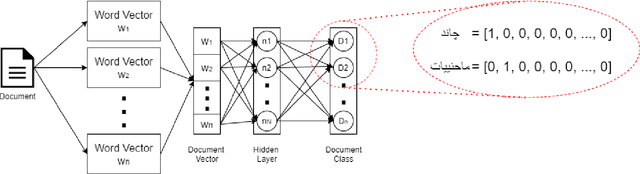
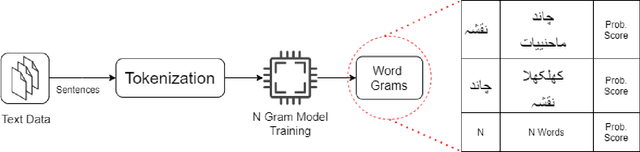
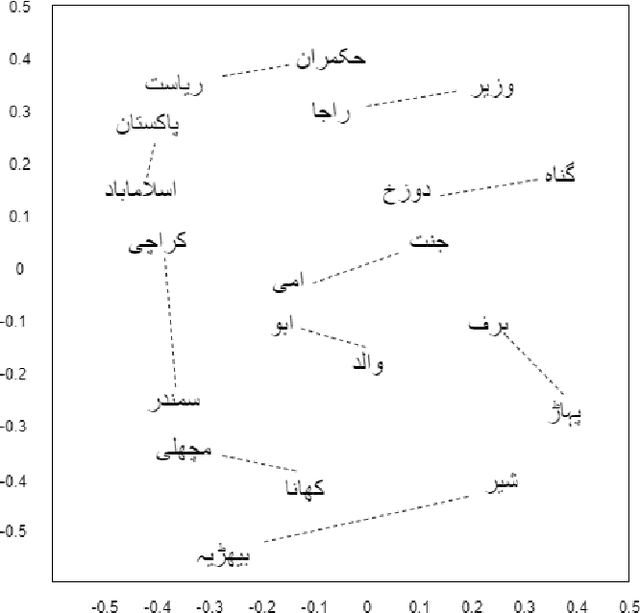
Urdu is a widely spoken language in South Asia. Though immoderate literature exists for the Urdu language still the data isn't enough to naturally process the language by NLP techniques. Very efficient language models exist for the English language, a high resource language, but Urdu and other under-resourced languages have been neglected for a long time. To create efficient language models for these languages we must have good word embedding models. For Urdu, we can only find word embeddings trained and developed using the skip-gram model. In this paper, we have built a corpus for Urdu by scraping and integrating data from various sources and compiled a vocabulary for the Urdu language. We also modify fasttext embeddings and N-Grams models to enable training them on our built corpus. We have used these trained embeddings for a word similarity task and compared the results with existing techniques.
Computationally-Efficient Roadmap-based Inspection Planning via Incremental Lazy Search
Mar 25, 2021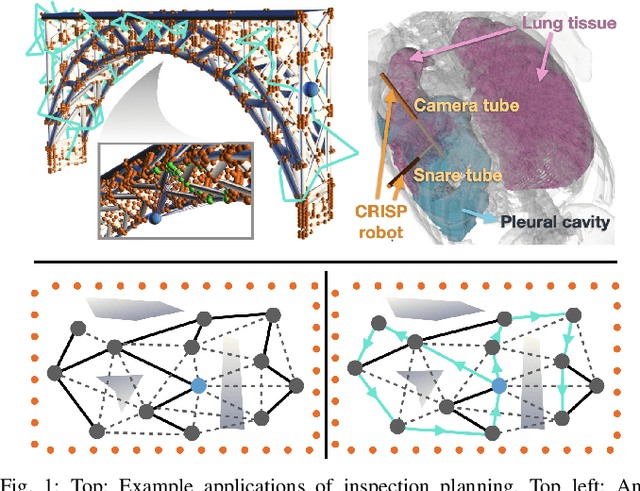
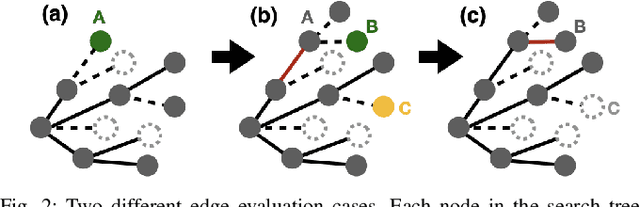

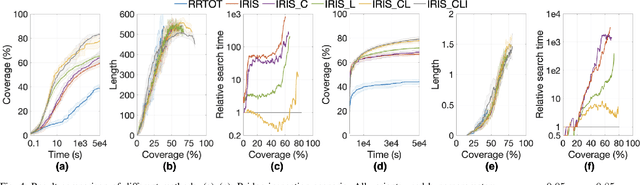
The inspection-planning problem calls for computing motions for a robot that allow it to inspect a set of points of interest (POIs) while considering plan quality (e.g., plan length). This problem has applications across many domains where robots can help with inspection, including infrastructure maintenance, construction, and surgery. Incremental Random Inspection-roadmap Search (IRIS) is an asymptotically-optimal inspection planner that was shown to compute higher-quality inspection plans orders of magnitudes faster than the prior state-of-the-art method. In this paper, we significantly accelerate the performance of IRIS to broaden its applicability to more challenging real-world applications. A key computational challenge that IRIS faces is effectively searching roadmaps for inspection plans -- a procedure that dominates its running time. In this work, we show how to incorporate lazy edge-evaluation techniques into \iris's search algorithm and how to reuse search efforts when a roadmap undergoes local changes. These enhancements, which do not compromise IRIS's asymptotic optimality, enable us to compute inspection plans much faster than the original IRIS. We apply IRIS with the enhancements to simulated bridge inspection and surgical inspection tasks and show that our new algorithm for some scenarios can compute similar-quality inspection plans 570x faster than prior work.