 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Variable Name Recovery in Decompiled Binary Code using Constrained Masked Language Modeling
Mar 23, 2021
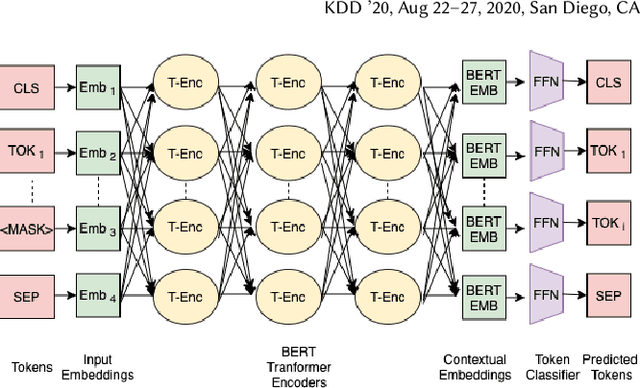
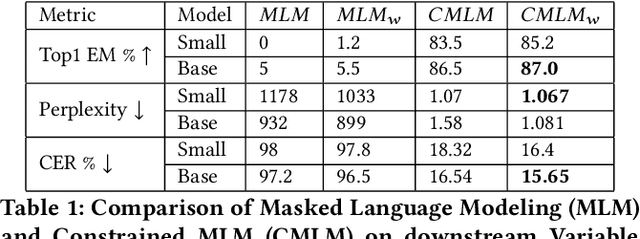
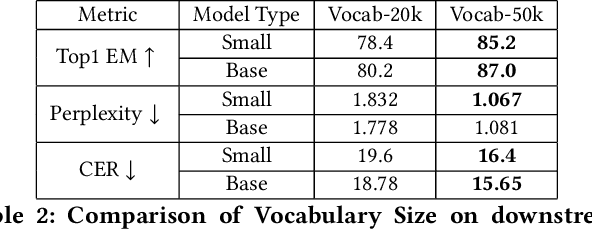
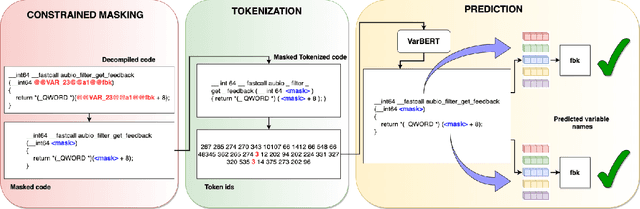
Decompilation is the procedure of transforming binary programs into a high-level representation, such as source code, for human analysts to examine. While modern decompilers can reconstruct and recover much information that is discarded during compilation, inferring variable names is still extremely difficult. Inspired by recent advances in natural language processing, we propose a novel solution to infer variable names in decompiled code based on Masked Language Modeling, Byte-Pair Encoding, and neural architectures such as Transformers and BERT. Our solution takes \textit{raw} decompiler output, the less semantically meaningful code, as input, and enriches it using our proposed \textit{finetuning} technique, Constrained Masked Language Modeling. Using Constrained Masked Language Modeling introduces the challenge of predicting the number of masked tokens for the original variable name. We address this \textit{count of token prediction} challenge with our post-processing algorithm. Compared to the state-of-the-art approaches, our trained VarBERT model is simpler and of much better performance. We evaluated our model on an existing large-scale data set with 164,632 binaries and showed that it can predict variable names identical to the ones present in the original source code up to 84.15\% of the time.
Human Perception Modeling for Automatic Natural Image Matting
Mar 31, 2021
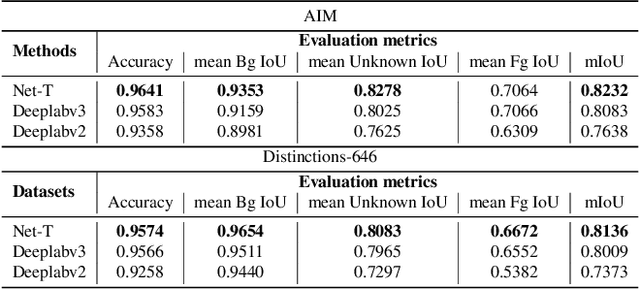
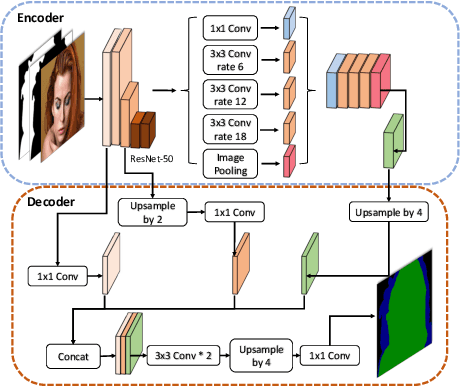

Natural image matting aims to precisely separate foreground objects from background using alpha matte. Fully automatic natural image matting without external annotation is quite challenging. Well-performed matting methods usually require accurate handcrafted trimap as extra input, which is labor-intensive and time-consuming, while the performance of automatic trimap generation method of dilating foreground segmentation fluctuates with segmentation quality. In this paper, we argue that how to handle trade-off of additional information input is a major issue in automatic matting, which we decompose into two subtasks: trimap and alpha estimation. By leveraging easily-accessible coarse annotations and modeling alpha matte handmade process of capturing rough foreground/background/transition boundary and carving delicate details in transition region, we propose an intuitively-designed trimap-free two-stage matting approach without additional annotations, e.g. trimap and background image. Specifically, given an image and its coarse foreground segmentation, Trimap Generation Network estimates probabilities of foreground, unknown, and background regions to guide alpha feature flow of our proposed Non-Local Matting network, which is equipped with trimap-guided global aggregation attention block. Experimental results show that our matting algorithm has competitive performance with current state-of-the-art methods in both trimap-free and trimap-needed aspects.
Multimodal Punctuation Prediction with Contextual Dropout
Feb 12, 2021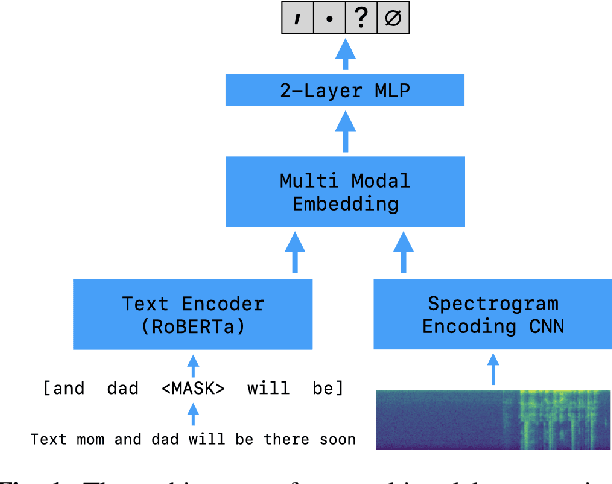

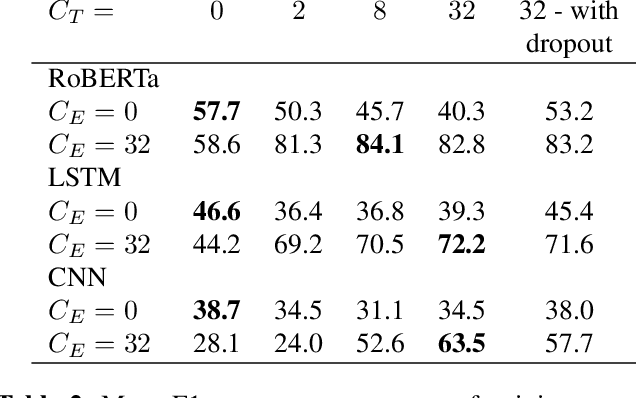
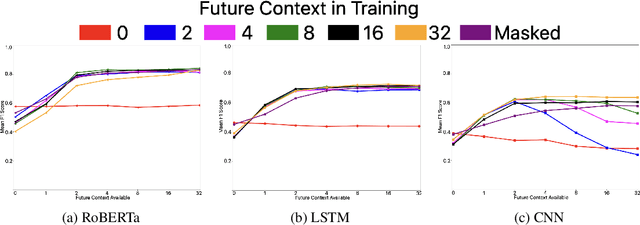
Automatic speech recognition (ASR) is widely used in consumer electronics. ASR greatly improves the utility and accessibility of technology, but usually the output is only word sequences without punctuation. This can result in ambiguity in inferring user-intent. We first present a transformer-based approach for punctuation prediction that achieves 8% improvement on the IWSLT 2012 TED Task, beating the previous state of the art [1]. We next describe our multimodal model that learns from both text and audio, which achieves 8% improvement over the text-only algorithm on an internal dataset for which we have both the audio and transcriptions. Finally, we present an approach to learning a model using contextual dropout that allows us to handle variable amounts of future context at test time.
StackRec: Efficient Training of Very Deep Sequential Recommender Models by Layer Stacking
Dec 14, 2020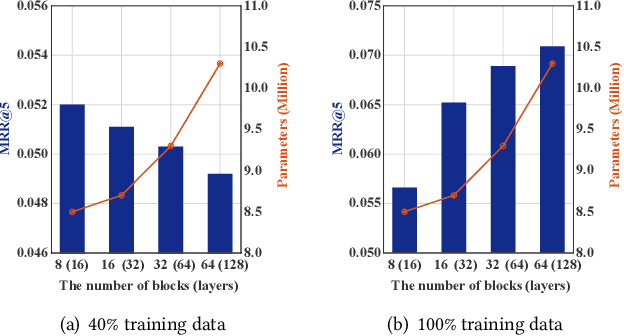
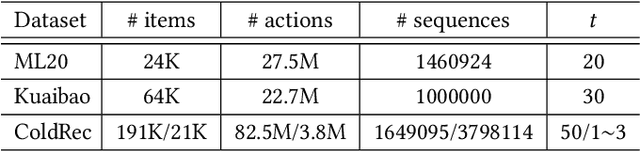
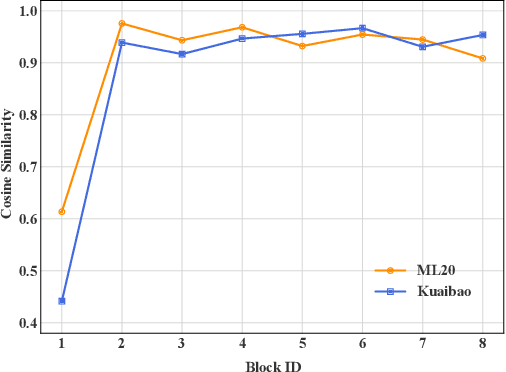
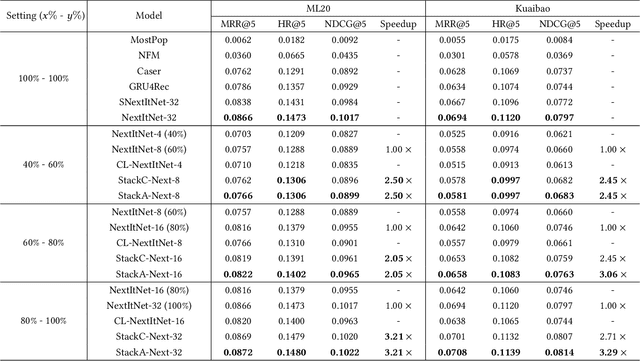
Deep learning has brought great progress for the sequential recommendation (SR) tasks. With the structure of advanced residual networks, sequential recommender models can be stacked with many hidden layers, e.g., up to 100 layers on real-world SR datasets. Training such a deep network requires expensive computation and longer training time, especially in situations when there are tens of billions of user-item interactions. To deal with such a challenge, we present StackRec, a simple but very efficient training framework for deep SR models by layer stacking. Specifically, we first offer an important insight that residual layers/blocks in a well-trained deep SR model have similar distribution. Enlightened by this, we propose progressively stacking such pre-trained residual layers/blocks so as to yield a deeper but easier-to-train SR model. We validate the proposed StackRec by instantiating with two state-of-the-art SR models in three practical scenarios and real-world datasets. Extensive experiments show that StackRec achieves not only comparable performance, but also significant acceleration in training time, compared to SR models that are trained from scratch.
Promoting Fairness through Hyperparameter Optimization
Mar 23, 2021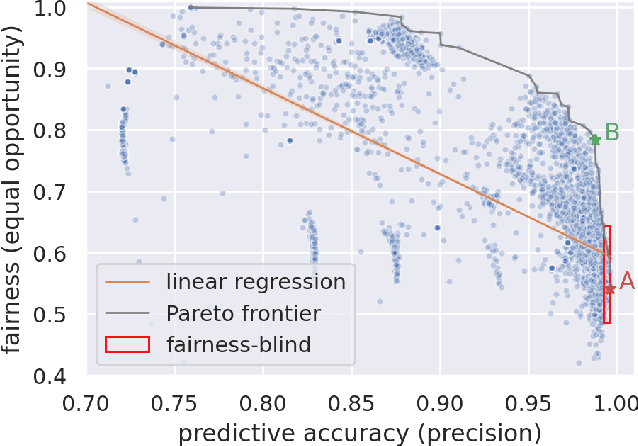

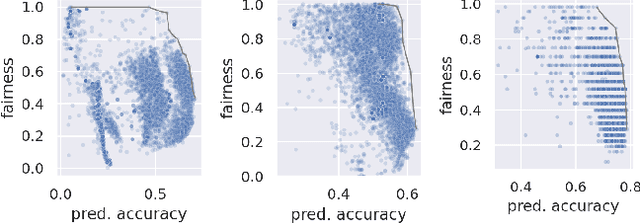
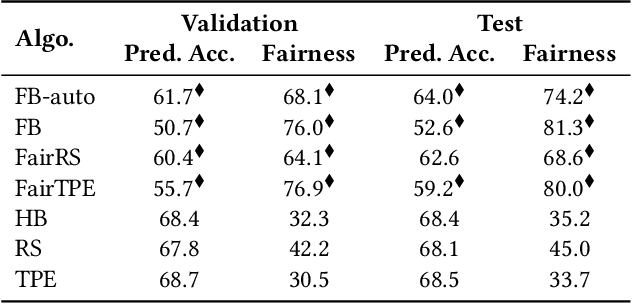
Considerable research effort has been guided towards algorithmic fairness but real-world adoption of bias reduction techniques is still scarce. Existing methods are either metric- or model-specific, require access to sensitive attributes at inference time, or carry high development and deployment costs. This work explores, in the context of a real-world fraud detection application, the unfairness that emerges from traditional ML model development, and how to mitigate it with a simple and easily deployed intervention: fairness-aware hyperparameter optimization (HO). We propose and evaluate fairness-aware variants of three popular HO algorithms: Fair Random Search, Fair TPE, and Fairband. Our method enables practitioners to adapt pre-existing business operations to accommodate fairness objectives in a frictionless way and with controllable fairness-accuracy trade-offs. Additionally, it can be coupled with existing bias reduction techniques to tune their hyperparameters. We validate our approach on a real-world bank account opening fraud use case, as well as on three datasets from the fairness literature. Results show that, without extra training cost, it is feasible to find models with 111% average fairness increase and just 6% decrease in predictive accuracy, when compared to standard fairness-blind HO.
SDOD:Real-time Segmenting and Detecting 3D Objects by Depth
Jan 26, 2020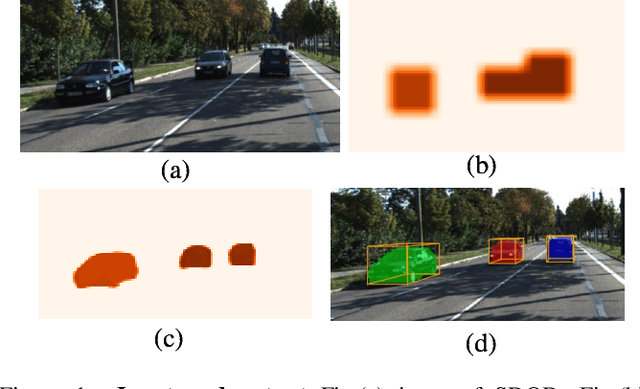
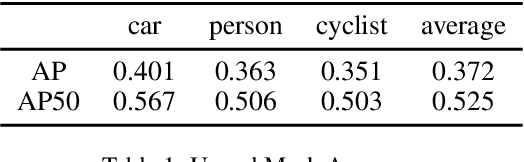
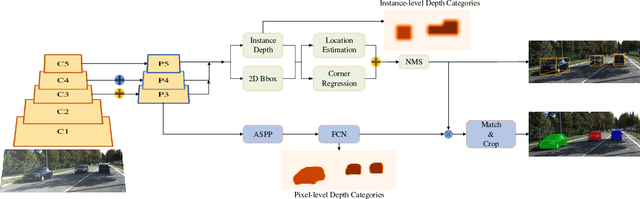
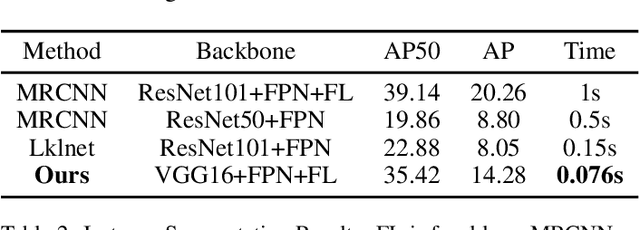
Most existing instance segmentation methods only focus on 2D objects and are not suitable for 3D scenes such as autonomous driving. In this paper, we propose a model that splits instance segmentation and object detection into two parallel branches. We discretize the objects depth into "depth categories" (background set to 0, objects set to [1, K]), then the instance segmentation task has been transformed into a pixel-level classification task. Mask branch predicts pixel-level "depth categories", 3D branch predicts instance-level "depth categories", we produce instance mask by assigning pixels which have same "depth categories" to each instance. In addition, in order to solve the problem of imbalanced between mask labels and 3D labels in the KITTI dataset (200 for mask, 7481 for 3D), we use unreal mask generated by other instance segmentation method to train mask branch. Despite the use of unreal mask labels, experiments result on KITTI dataset still achieves state-of-the-art performance in vehicle instance segmentation.
Seeing through a Black Box: Toward High-Quality Terahertz TomographicImaging via Multi-Scale Spatio-Spectral Image Fusion
Mar 31, 2021
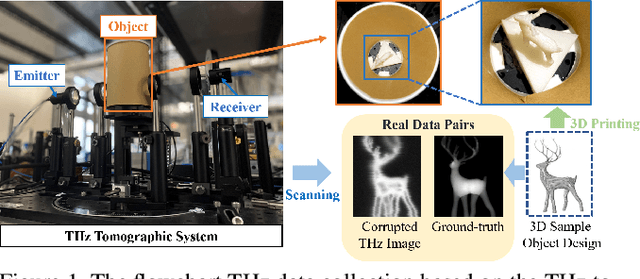
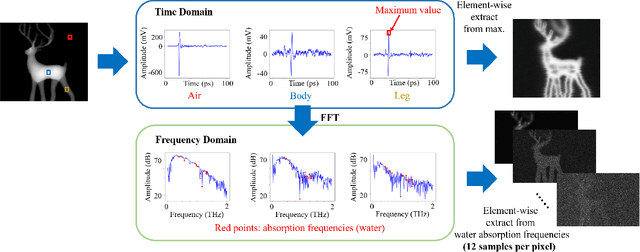
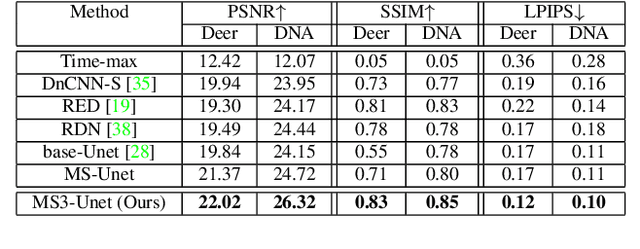
Terahertz tomographic imaging has recently arisen significant attention due to its non-invasive, non-destructive, non-ionizing, material-classification, and ultrafast-frame-rate nature for object exploration and inspection. However, its strong water absorption nature and low noise tolerance lead to undesired blurring and distortion of reconstructed terahertz images. Research groups aim to deal with this issue through the use of synthetic data in the training phase, but still, their performances are highly constrained by the diffraction-limited terahertz signals. In this paper, we propose a novel multi-scale spatio-spectral fusion Unet (MS3-Unet) that extracts multi-scale features from the different spectral of terahertz image data for restoration. MS3-Unet utilizes multi-scale branches to extract spatio-spectral features which are then processed by element-wise adaptive filters, and then fused to achieve high-quality terahertz image restoration. Here, we experimentally construct ultra-high-speed terahertz time-domain spectroscopy system covering a broad frequency range from 0.1 THz to 4 THz for building up temporal/spectral/spatial/phase/material terahertz database of hidden 3-D objects. Complementary to a quantitative evaluation, we demonstrate the effectiveness of the proposed MS3-Unet image restoration approach on 3-D terahertz tomographic reconstruction applications.
Real-Time Fine-Grained Air Quality Sensing Networks in Smart City: Design, Implementation and Optimization
Oct 18, 2018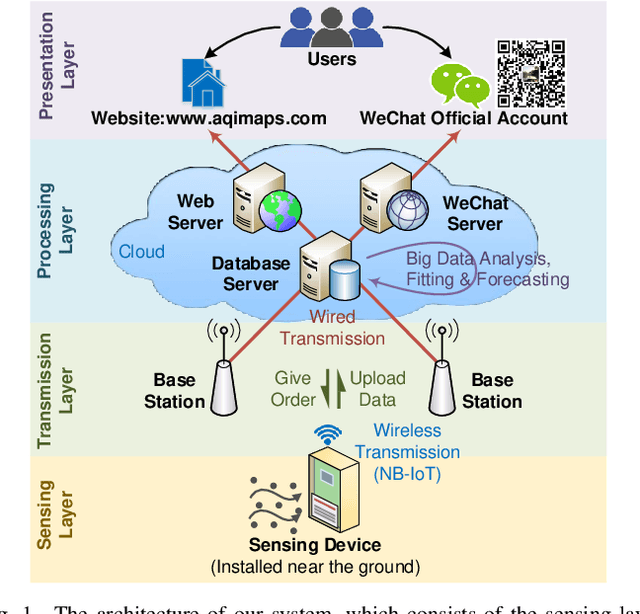
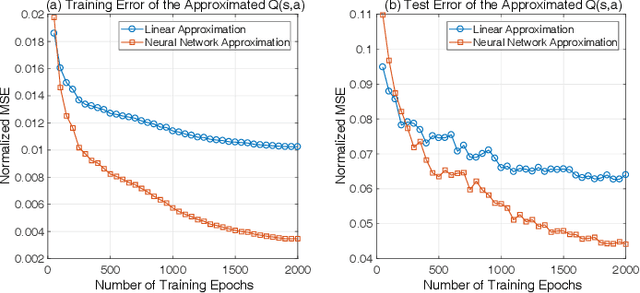
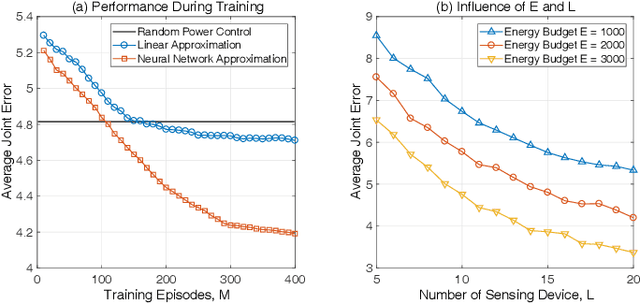
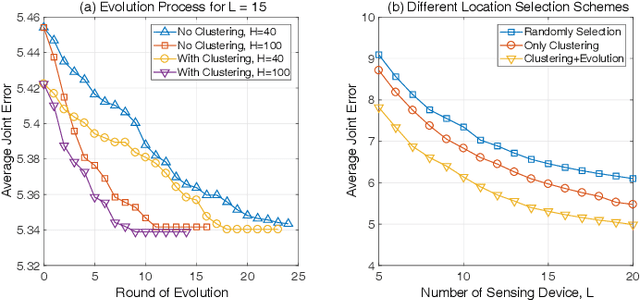
Driven by the increasingly serious air pollution problem, the monitoring of air quality has gained much attention in both theoretical studies and practical implementations. In this paper, we present the architecture, implementation and optimization of our own air quality sensing system, which provides real-time and fine-grained air quality map of the monitored area. As the major component, the optimization problem of our system is studied in detail. Our objective is to minimize the average joint error of the established real-time air quality map, which involves data inference for the unmeasured data values. A deep Q-learning solution has been proposed for the power control problem to reasonably plan the sensing tasks of the power-limited sensing devices online. A genetic algorithm has been designed for the location selection problem to efficiently find the suitable locations to deploy limited number of sensing devices. The performance of the proposed solutions are evaluated by simulations, showing a significant performance gain when adopting both strategies.
HandTailor: Towards High-Precision Monocular 3D Hand Recovery
Feb 18, 2021
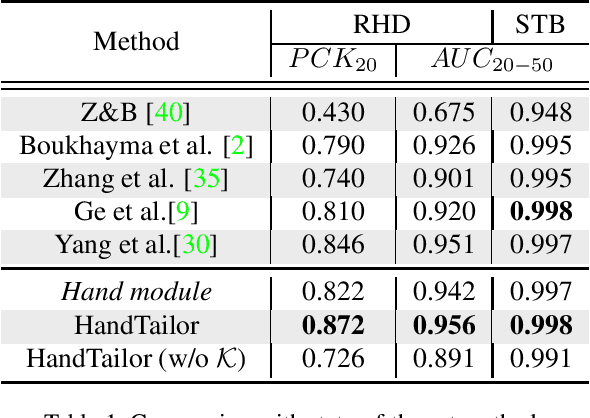
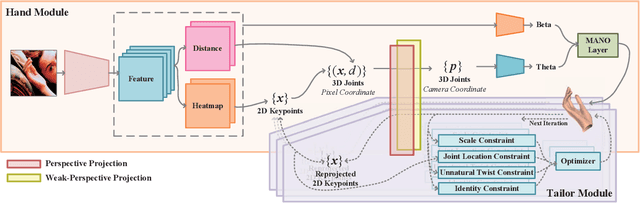
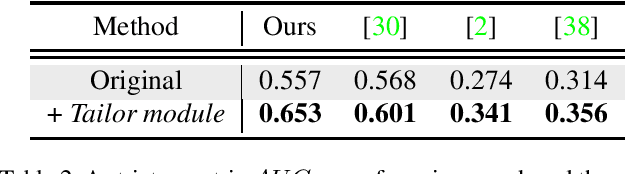
3D hand pose estimation and shape recovery are challenging tasks in computer vision. We introduce a novel framework HandTailor, which combines a learning-based hand module and an optimization-based tailor module to achieve high-precision hand mesh recovery from a monocular RGB image. The proposed hand module unifies perspective projection and weak perspective projection in a single network towards accuracy-oriented and in-the-wild scenarios. The proposed tailor module then utilizes the coarsely reconstructed mesh model provided by the hand module as initialization, and iteratively optimizes an energy function to obtain better results. The tailor module is time-efficient, costs only 8ms per frame on a modern CPU. We demonstrate that HandTailor can get state-of-the-art performance on several public benchmarks, with impressive qualitative results on in-the-wild experiments.
Spillover Algorithm: A Decentralized Coordination Approach for Multi-Robot Production Planning in Open Shared Factories
Jan 23, 2021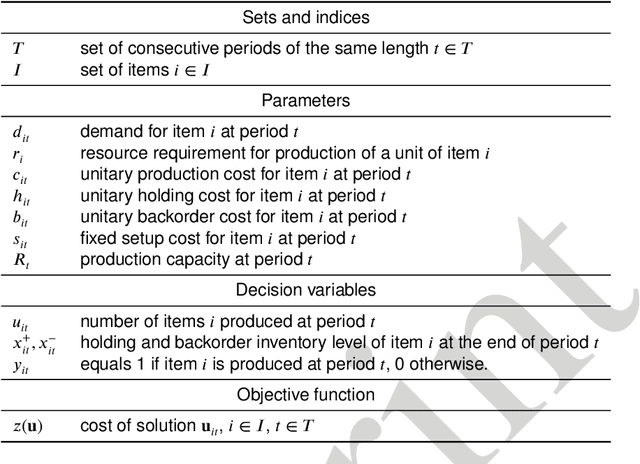
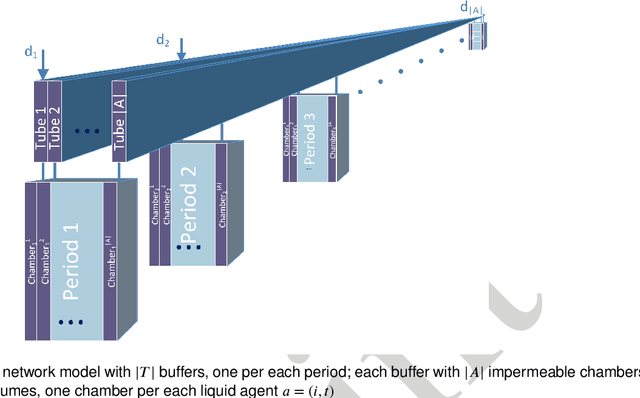

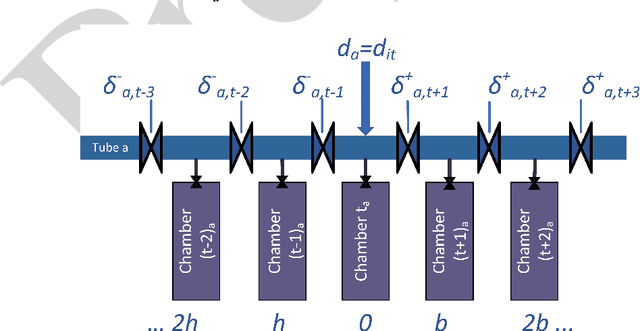
Open and shared manufacturing factories typically dispose of a limited number of robots that should be properly allocated to tasks in time and space for an effective and efficient system performance. In particular, we deal with the dynamic capacitated production planning problem with sequence independent setup costs where quantities of products to manufacture and location of robots need to be determined at consecutive periods within a given time horizon and products can be anticipated or backordered related to the demand period. We consider a decentralized multi-agent variant of this problem in an open factory setting with multiple owners of robots as well as different owners of the items to be produced, both considered self-interested and individually rational. Existing solution approaches to the classic constrained lot-sizing problem are centralized exact methods that require sharing of global knowledge of all the participants' private and sensitive information and are not applicable in the described multi-agent context. Therefore, we propose a computationally efficient decentralized approach based on the spillover effect that solves this NP-hard problem by distributing decisions in an intrinsically decentralized multi-agent system environment while protecting private and sensitive information. To the best of our knowledge, this is the first decentralized algorithm for the solution of the studied problem in intrinsically decentralized environments where production resources and/or products are owned by multiple stakeholders with possibly conflicting objectives. To show its efficiency, the performance of the Spillover Algorithm is benchmarked against state-of-the-art commercial solver CPLEX 12.8.