 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Photothermal-SR-Net: A Customized Deep Unfolding Neural Network for Photothermal Super Resolution Imaging
Apr 21, 2021
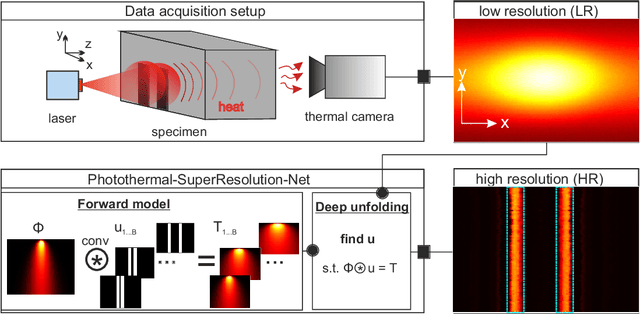

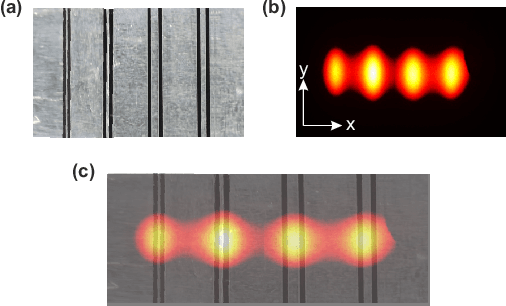
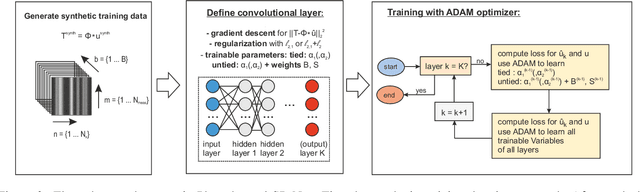
This paper presents deep unfolding neural networks to handle inverse problems in photothermal radiometry enabling super resolution (SR) imaging. Photothermal imaging is a well-known technique in active thermography for nondestructive inspection of defects in materials such as metals or composites. A grand challenge of active thermography is to overcome the spatial resolution limitation imposed by heat diffusion in order to accurately resolve each defect. The photothermal SR approach enables to extract high-frequency spatial components based on the deconvolution with the thermal point spread function. However, stable deconvolution can only be achieved by using the sparse structure of defect patterns, which often requires tedious, hand-crafted tuning of hyperparameters and results in computationally intensive algorithms. On this account, Photothermal-SR-Net is proposed in this paper, which performs deconvolution by deep unfolding considering the underlying physics. This enables to super resolve 2D thermal images for nondestructive testing with a substantially improved convergence rate. Since defects appear sparsely in materials, Photothermal-SR-Net applies trained block-sparsity thresholding to the acquired thermal images in each convolutional layer. The performance of the proposed approach is evaluated and discussed using various deep unfolding and thresholding approaches applied to 2D thermal images. Subsequently, studies are conducted on how to increase the reconstruction quality and the computational performance of Photothermal-SR-Net is evaluated. Thereby, it was found that the computing time for creating high-resolution images could be significantly reduced without decreasing the reconstruction quality by using pixel binning as a preprocessing step.
Prediction of Solar Radiation Using Artificial Neural Network
Apr 01, 2021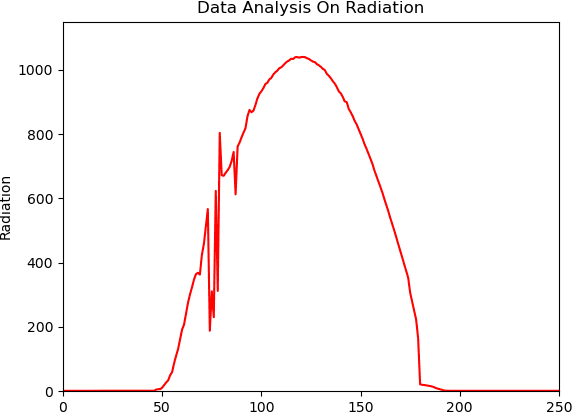
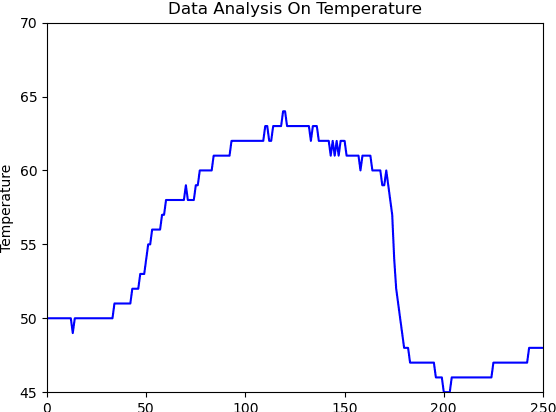
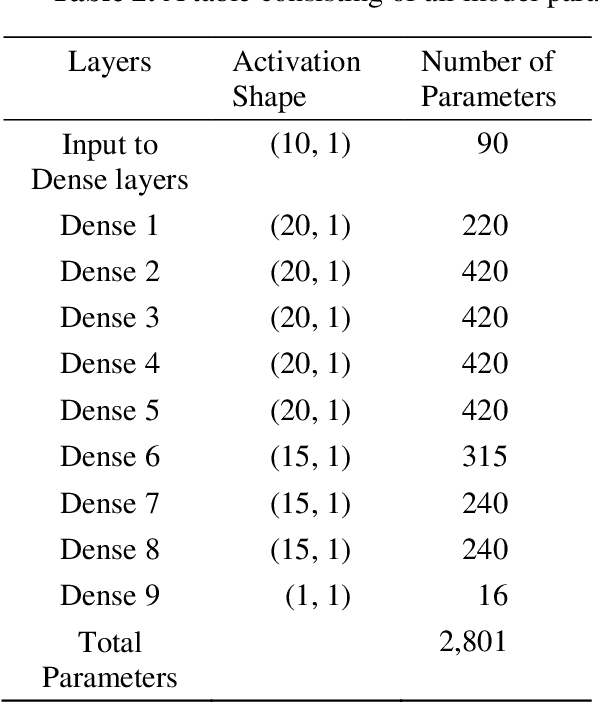
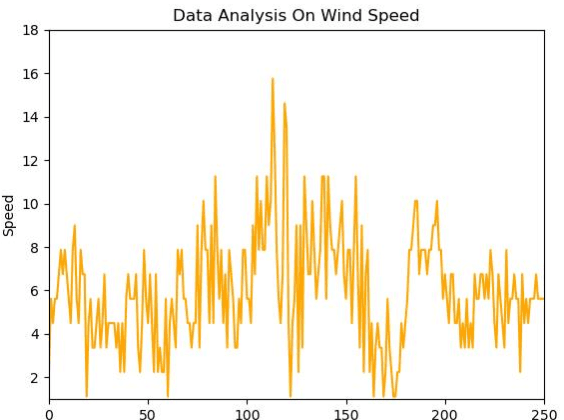
Most solar applications and systems can be reliably used to generate electricity and power in many homes and offices. Recently, there is an increase in many solar required systems that can be found not only in electricity generation but other applications such as solar distillation, water heating, heating of buildings, meteorology and producing solar conversion energy. Prediction of solar radiation is very significant in order to accomplish the previously mentioned objectives. In this paper, the main target is to present an algorithm that can be used to predict an hourly activity of solar radiation. Using a dataset that consists of temperature of air, time, humidity, wind speed, atmospheric pressure, direction of wind and solar radiation data, an Artificial Neural Network (ANN) model is constructed to effectively forecast solar radiation using the available weather forecast data. Two models are created to efficiently create a system capable of interpreting patterns through supervised learning data and predict the correct amount of radiation present in the atmosphere. The results of the two statistical indicators: Mean Absolute Error (MAE) and Mean Squared Error (MSE) are performed and compared with observed and predicted data. These two models were able to generate efficient predictions with sufficient performance accuracy.
* Published as open access, 12 pages, 13 images and 2 tables
Piecewise Deterministic Markov Processes for Continuous-Time Monte Carlo
Nov 23, 2016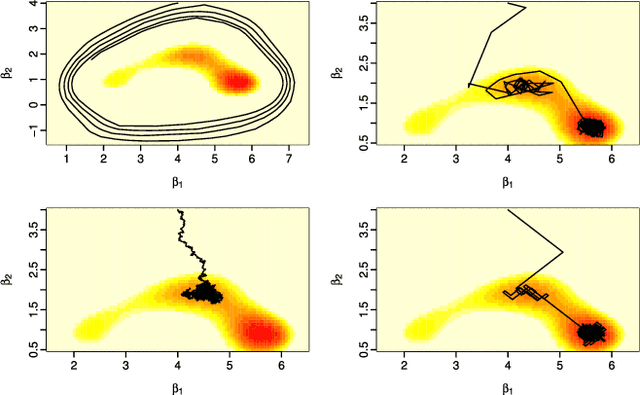
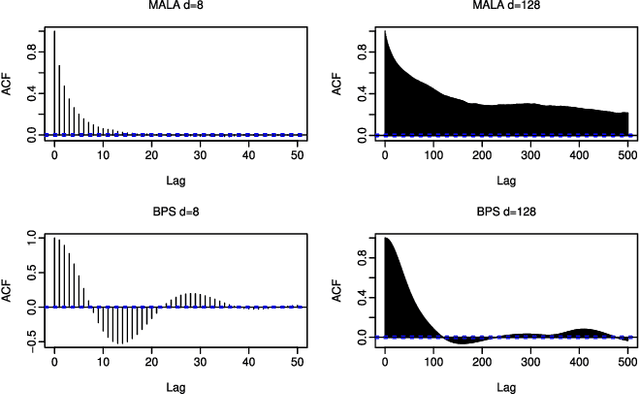
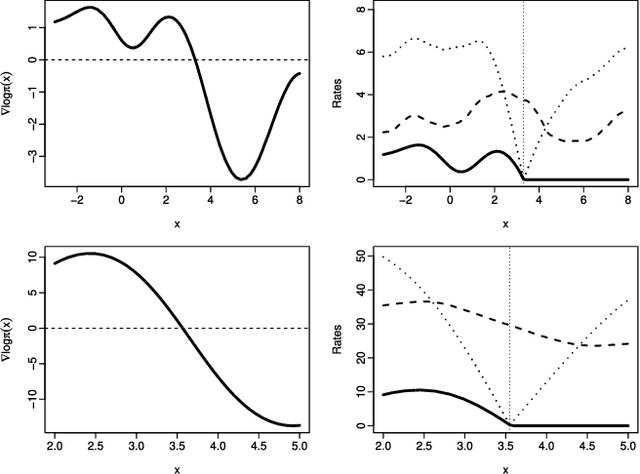
Recently there have been exciting developments in Monte Carlo methods, with the development of new MCMC and sequential Monte Carlo (SMC) algorithms which are based on continuous-time, rather than discrete-time, Markov processes. This has led to some fundamentally new Monte Carlo algorithms which can be used to sample from, say, a posterior distribution. Interestingly, continuous-time algorithms seem particularly well suited to Bayesian analysis in big-data settings as they need only access a small sub-set of data points at each iteration, and yet are still guaranteed to target the true posterior distribution. Whilst continuous-time MCMC and SMC methods have been developed independently we show here that they are related by the fact that both involve simulating a piecewise deterministic Markov process. Furthermore we show that the methods developed to date are just specific cases of a potentially much wider class of continuous-time Monte Carlo algorithms. We give an informal introduction to piecewise deterministic Markov processes, covering the aspects relevant to these new Monte Carlo algorithms, with a view to making the development of new continuous-time Monte Carlo more accessible. We focus on how and why sub-sampling ideas can be used with these algorithms, and aim to give insight into how these new algorithms can be implemented, and what are some of the issues that affect their efficiency.
Validation of non-negative matrix factorization for assessment of atomic pair-distribution function (PDF) data in a real-time streaming context
Oct 22, 2020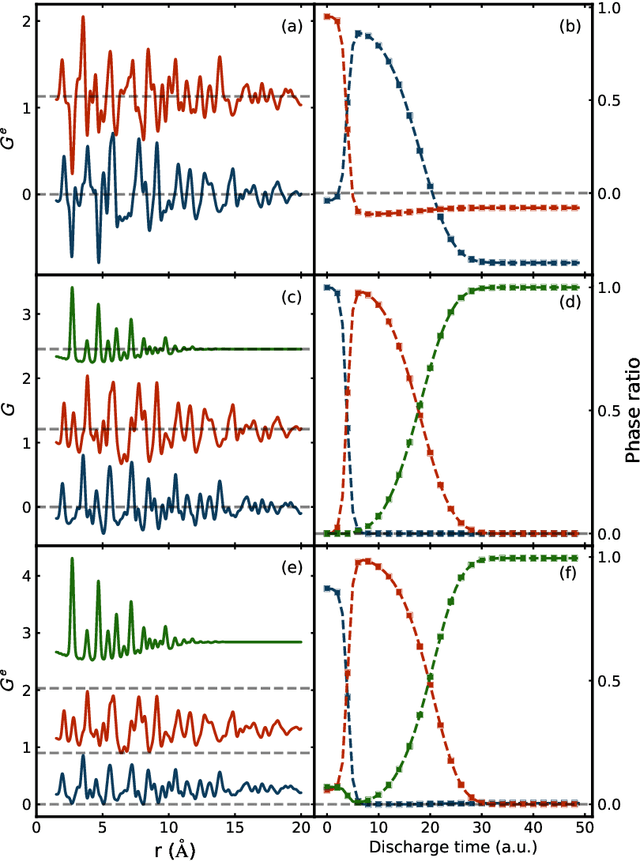
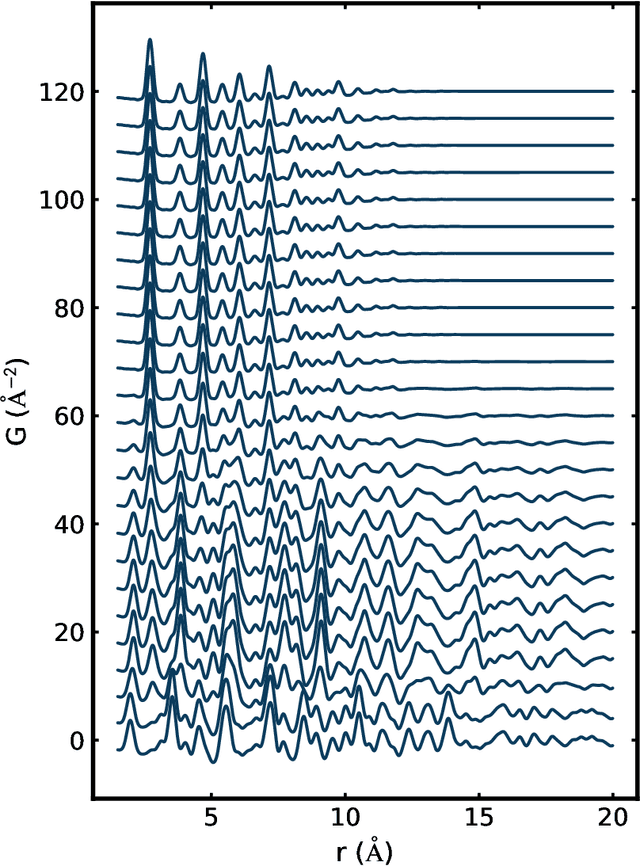
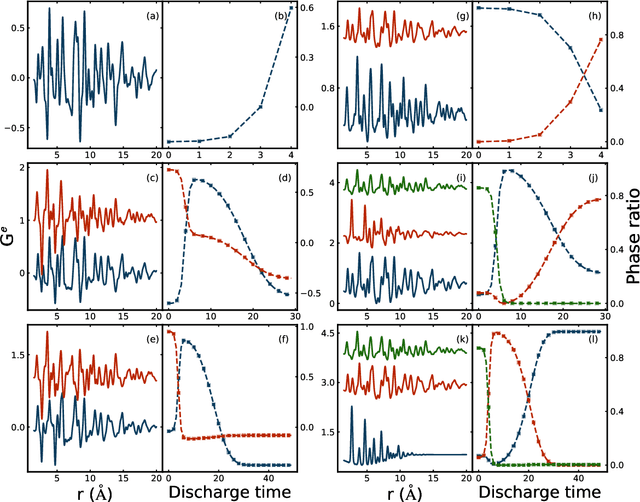
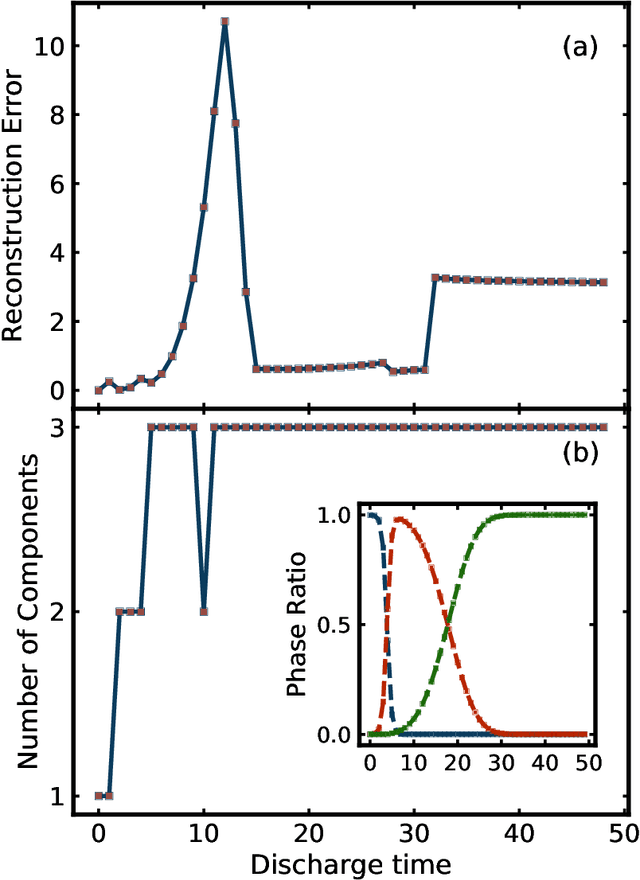
We validate the use of matrix factorization for the automatic identification of relevant components from atomic pair distribution function (PDF) data. We also present a newly developed software infrastructure for analyzing the PDF data arriving in streaming manner. We then apply two matrix factorization techniques, Principal Component Analysis (PCA) and Non-negative Matrix Factorization (NMF), to study simulated and experiment datasets in the context of in situ experiment.
Safety-Critical Online Control with Adversarial Disturbances
Sep 20, 2020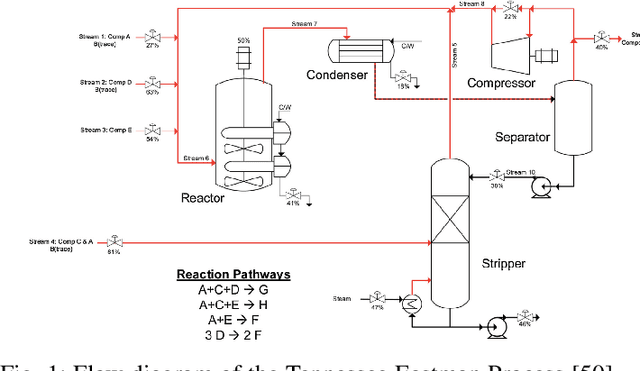
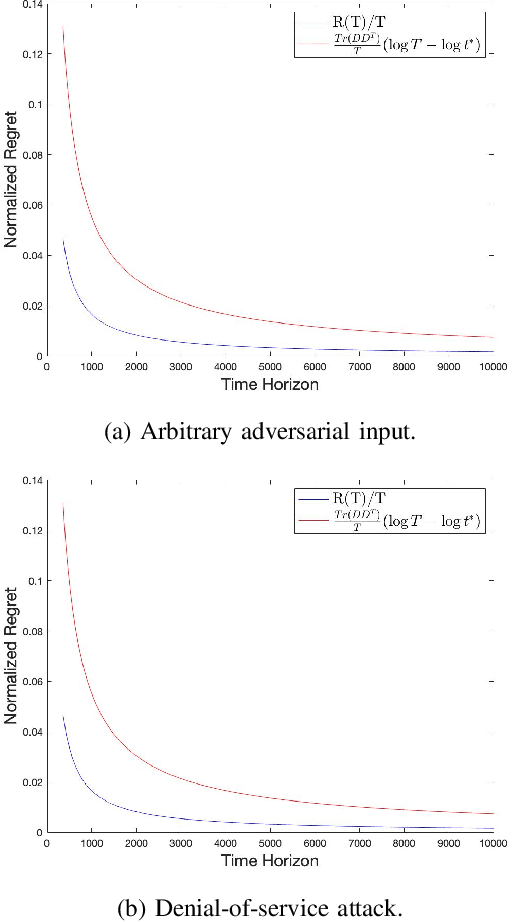
This paper studies the control of safety-critical dynamical systems in the presence of adversarial disturbances. We seek to synthesize state-feedback controllers to minimize a cost incurred due to the disturbance, while respecting a safety constraint. The safety constraint is given by a bound on an H-inf norm, while the cost is specified as an upper bound on the H-2 norm of the system. We consider an online setting where costs at each time are revealed only after the controller at that time is chosen. We propose an iterative approach to the synthesis of the controller by solving a modified discrete-time Riccati equation. Solutions of this equation enforce the safety constraint. We compare the cost of this controller with that of the optimal controller when one has complete knowledge of disturbances and costs in hindsight. We show that the regret function, which is defined as the difference between these costs, varies logarithmically with the time horizon. We validate our approach on a process control setup that is subject to two kinds of adversarial attacks.
Use square root affinity to regress labels in semantic segmentation
Mar 07, 2021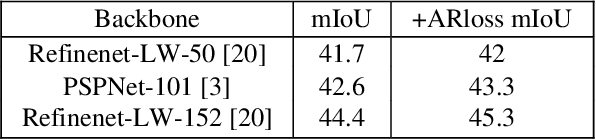


Semantic segmentation is a basic but non-trivial task in computer vision. Many previous work focus on utilizing affinity patterns to enhance segmentation networks. Most of these studies use the affinity matrix as a kind of feature fusion weights, which is part of modules embedded in the network, such as attention models and non-local models. In this paper, we associate affinity matrix with labels, exploiting the affinity in a supervised way. Specifically, we utilize the label to generate a multi-scale label affinity matrix as a structural supervision, and we use a square root kernel to compute a non-local affinity matrix on output layers. With such two affinities, we define a novel loss called Affinity Regression loss (AR loss), which can be an auxiliary loss providing pair-wise similarity penalty. Our model is easy to train and adds little computational burden without run-time inference. Extensive experiments on NYUv2 dataset and Cityscapes dataset demonstrate that our proposed method is sufficient in promoting semantic segmentation networks.
Privacy-Preserving Federated Depression Detection from Multi-Source Mobile Health Data
Mar 07, 2021
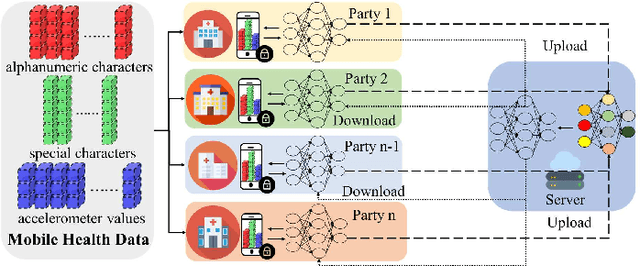
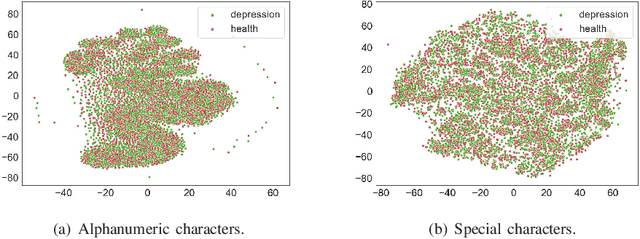
Depression is one of the most common mental illness problems, and the symptoms shown by patients are not consistent, making it difficult to diagnose in the process of clinical practice and pathological research.Although researchers hope that artificial intelligence can contribute to the diagnosis and treatment of depression, the traditional centralized machine learning needs to aggregate patient data, and the data privacy of patients with mental illness needs to be strictly confidential, which hinders machine learning algorithms clinical application.To solve the problem of privacy of the medical history of patients with depression, we implement federated learning to analyze and diagnose depression. First, we propose a general multi-view federated learning framework using multi-source data,which can extend any traditional machine learning model to support federated learning across different institutions or parties.Secondly, we adopt late fusion methods to solve the problem of inconsistent time series of multi-view data.Finally, we compare the federated framework with other cooperative learning frameworks in performance and discuss the related results.
Formation Control for UAVs Using a Flux Guided Approach
Mar 16, 2021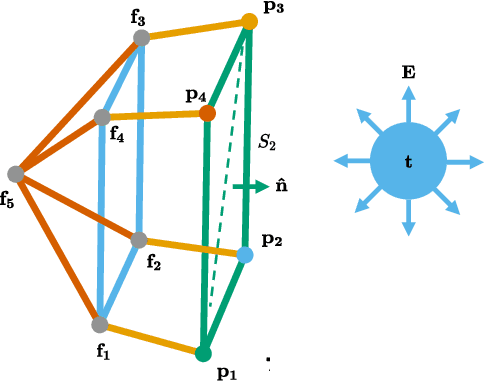
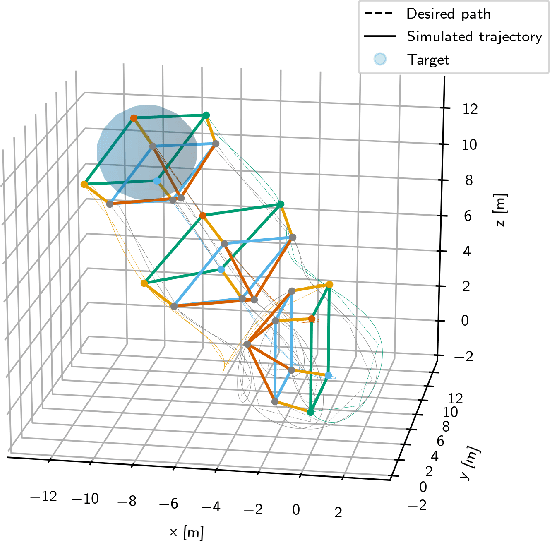
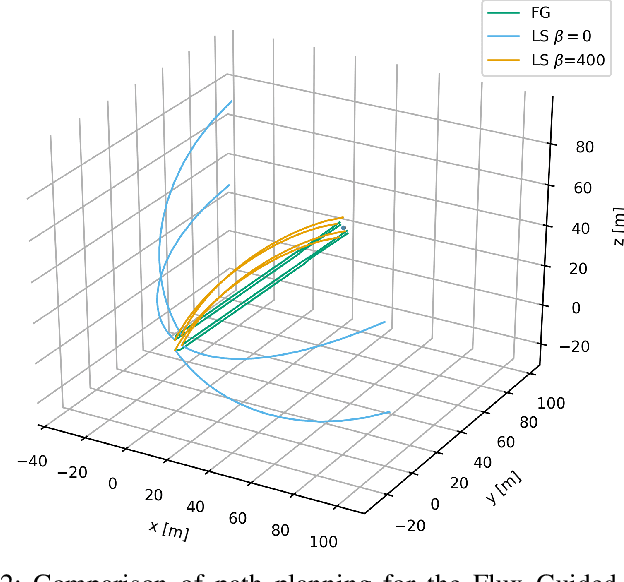
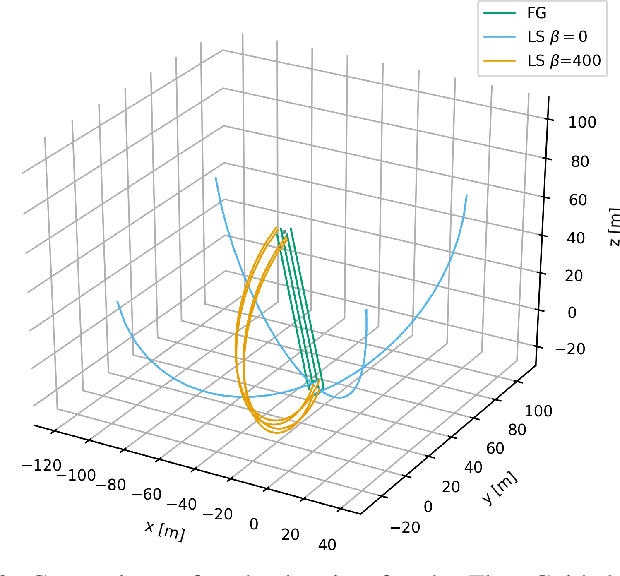
While multiple studies have proposed methods for the formation control of unmanned aerial vehicles (UAV), the trajectories generated are generally unsuitable for tracking targets where the optimum coverage of the target by the formation is required at all times. We propose a path planning approach called the Flux Guided (FG) method, which generates collision-free trajectories while maximising the coverage of one or more targets. We show that by reformulating an existing least-squares flux minimisation problem as a constrained optimisation problem, the paths obtained are $1.5 \times$ shorter and track directly toward the target. Also, we demonstrate that the scale of the formation can be controlled during flight, and that this feature can be used to track multiple scattered targets. The method is highly scalable since the planning algorithm is only required for a sub-set of UAVs on the open boundary of the formation's surface. Finally, through simulating a 3d dynamic particle system that tracks the desired trajectories using a PID controller, we show that the resulting trajectories after time-optimal parameterisation are suitable for robotic controls.
On Evolving Attention Towards Domain Adaptation
Mar 25, 2021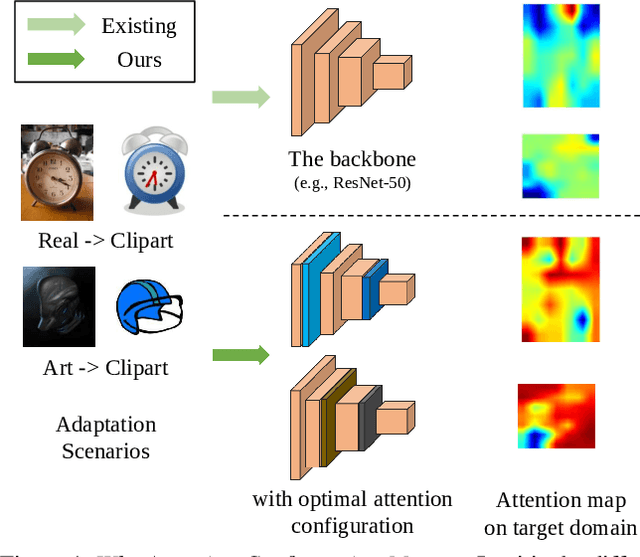
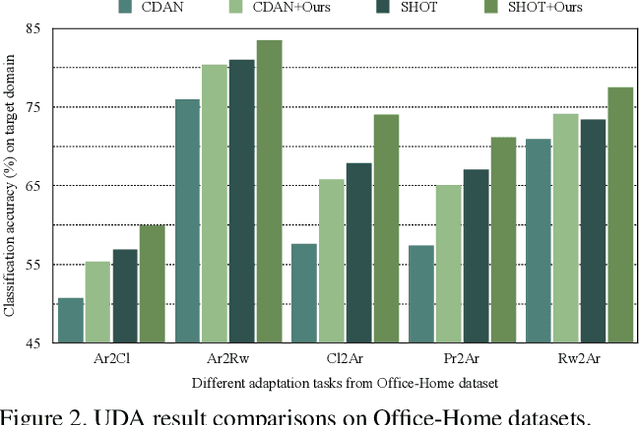
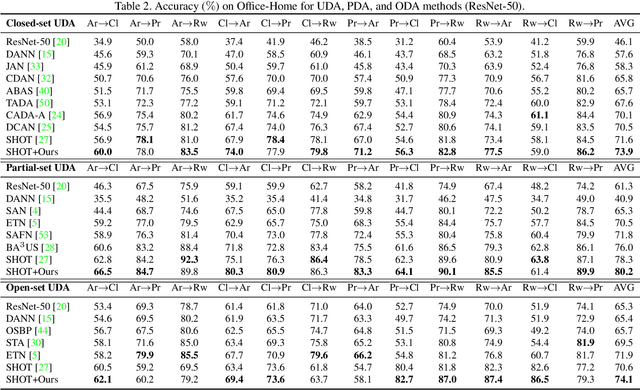
Towards better unsupervised domain adaptation (UDA). Recently, researchers propose various domain-conditioned attention modules and make promising progresses. However, considering that the configuration of attention, i.e., the type and the position of attention module, affects the performance significantly, it is more generalized to optimize the attention configuration automatically to be specialized for arbitrary UDA scenario. For the first time, this paper proposes EvoADA: a novel framework to evolve the attention configuration for a given UDA task without human intervention. In particular, we propose a novel search space containing diverse attention configurations. Then, to evaluate the attention configurations and make search procedure UDA-oriented (transferability + discrimination), we apply a simple and effective evaluation strategy: 1) training the network weights on two domains with off-the-shelf domain adaptation methods; 2) evolving the attention configurations under the guide of the discriminative ability on the target domain. Experiments on various kinds of cross-domain benchmarks, i.e., Office-31, Office-Home, CUB-Paintings, and Duke-Market-1510, reveal that the proposed EvoADA consistently boosts multiple state-of-the-art domain adaptation approaches, and the optimal attention configurations help them achieve better performance.
Learning to Shape Rewards using a Game of Switching Controls
Mar 16, 2021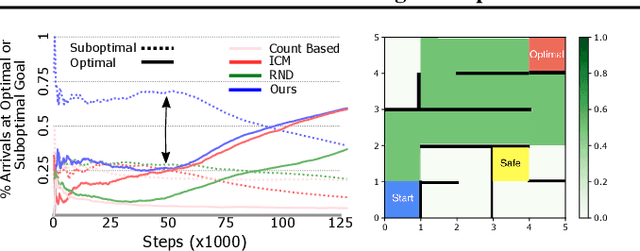
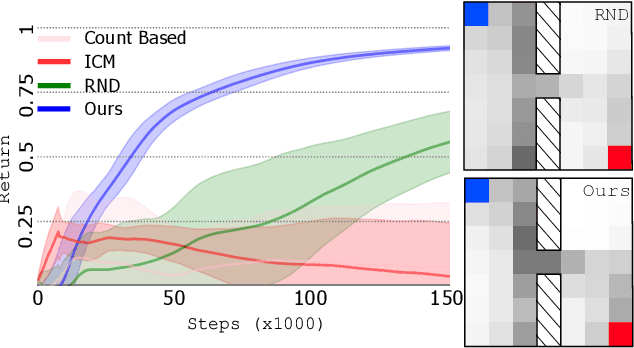
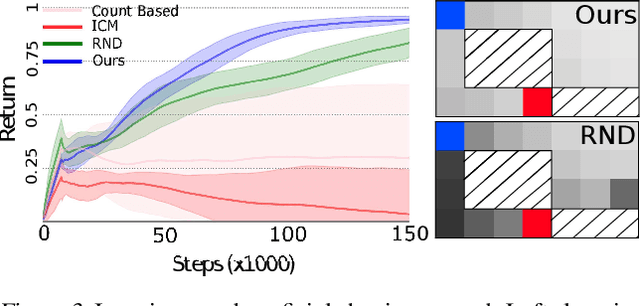
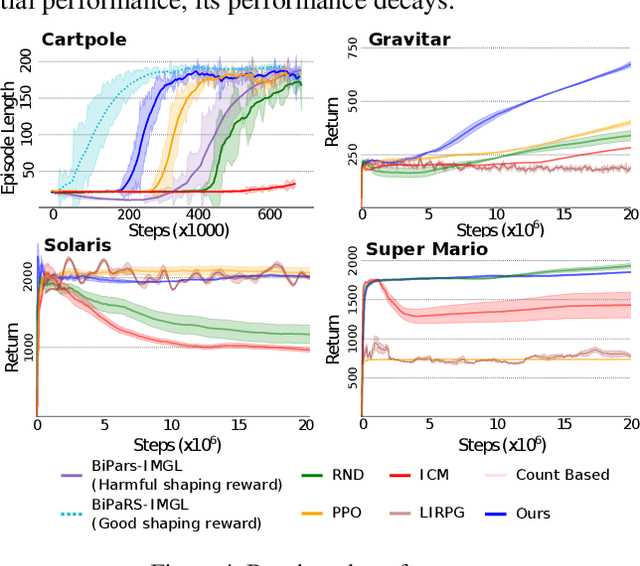
Reward shaping (RS) is a powerful method in reinforcement learning (RL) for overcoming the problem of sparse and uninformative rewards. However, RS relies on manually engineered shaping-reward functions whose construction is typically time-consuming and error-prone. It also requires domain knowledge which runs contrary to the goal of autonomous learning. In this paper, we introduce an automated RS framework in which the shaping-reward function is constructed in a novel stochastic game between two agents. One agent learns both which states to add shaping rewards and their optimal magnitudes and the other agent learns the optimal policy for the task using the shaped rewards. We prove theoretically that our framework, which easily adopts existing RL algorithms, learns to construct a shaping-reward function that is tailored to the task and ensures convergence to higher performing policies for the given task. We demonstrate the superior performance of our method against state-of-the-art RS algorithms in Cartpole and the challenging console games Gravitar, Solaris and Super Mario.