 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliminating Inductive Bias in Reward Models with Information-Theoretic Guidance
Dec 29, 2025Reward models (RMs) are essential in reinforcement learning from human feedback (RLHF) to align large language models (LLMs) with human values. However, RM training data is commonly recognized as low-quality, containing inductive biases that can easily lead to overfitting and reward hacking. For example, more detailed and comprehensive responses are usually human-preferred but with more words, leading response length to become one of the inevitable inductive biases. A limited number of prior RM debiasing approaches either target a single specific type of bias or model the problem with only simple linear correlations, \textit{e.g.}, Pearson coefficients. To mitigate more complex and diverse inductive biases in reward modeling, we introduce a novel information-theoretic debiasing method called \textbf{D}ebiasing via \textbf{I}nformation optimization for \textbf{R}M (DIR). Inspired by the information bottleneck (IB), we maximize the mutual information (MI) between RM scores and human preference pairs, while minimizing the MI between RM outputs and biased attributes of preference inputs. With theoretical justification from information theory, DIR can handle more sophisticated types of biases with non-linear correlations, broadly extending the real-world application scenarios for RM debiasing methods. In experiments, we verify the effectiveness of DIR with three types of inductive biases: \textit{response length}, \textit{sycophancy}, and \textit{format}. We discover that DIR not only effectively mitigates target inductive biases but also enhances RLHF performance across diverse benchmarks, yielding better generalization abilities. The code and training recipes are available at https://github.com/Qwen-Applications/DIR.
Learning to Shape Rewards using a Game of Switching Controls
Mar 16, 2021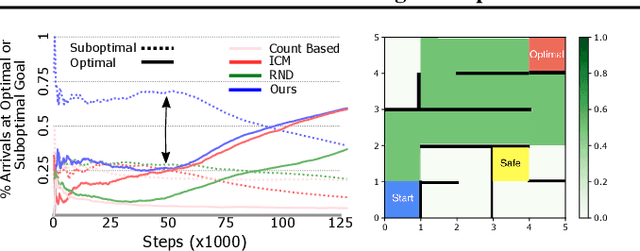
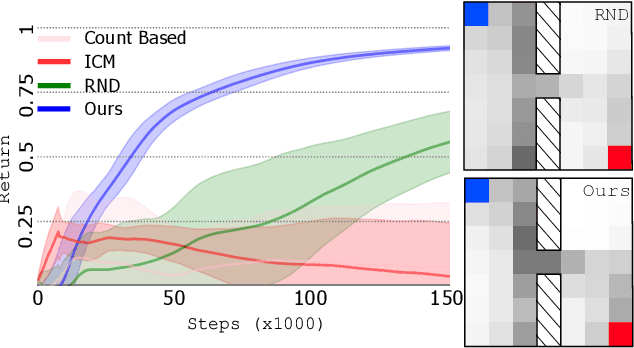
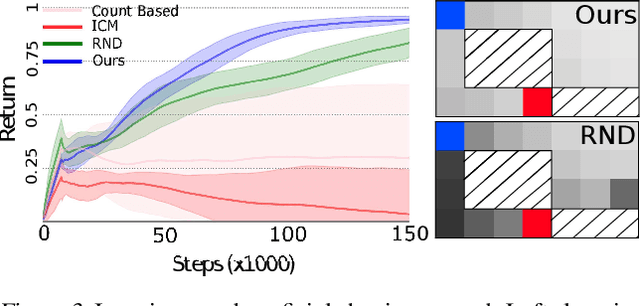
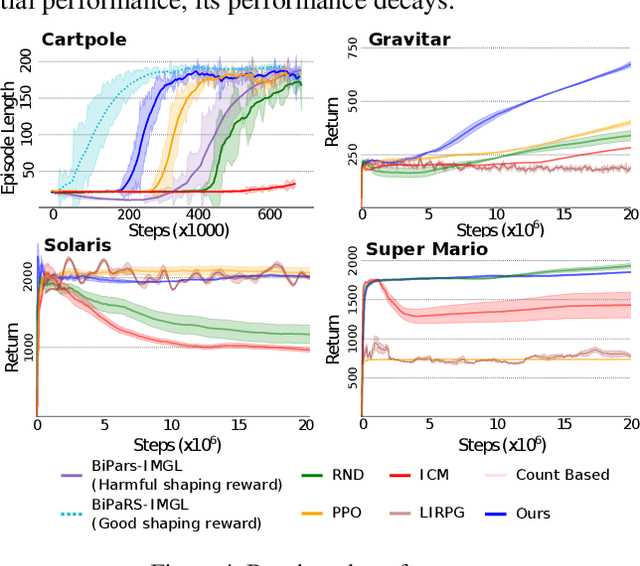
Reward shaping (RS) is a powerful method in reinforcement learning (RL) for overcoming the problem of sparse and uninformative rewards. However, RS relies on manually engineered shaping-reward functions whose construction is typically time-consuming and error-prone. It also requires domain knowledge which runs contrary to the goal of autonomous learning. In this paper, we introduce an automated RS framework in which the shaping-reward function is constructed in a novel stochastic game between two agents. One agent learns both which states to add shaping rewards and their optimal magnitudes and the other agent learns the optimal policy for the task using the shaped rewards. We prove theoretically that our framework, which easily adopts existing RL algorithms, learns to construct a shaping-reward function that is tailored to the task and ensures convergence to higher performing policies for the given task. We demonstrate the superior performance of our method against state-of-the-art RS algorithms in Cartpole and the challenging console games Gravitar, Solaris and Super Mario.