 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnintended memorisation of unique features in neural networks
May 20, 2022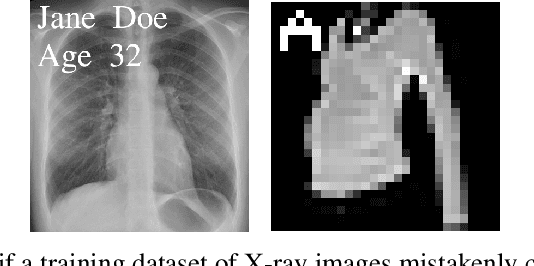
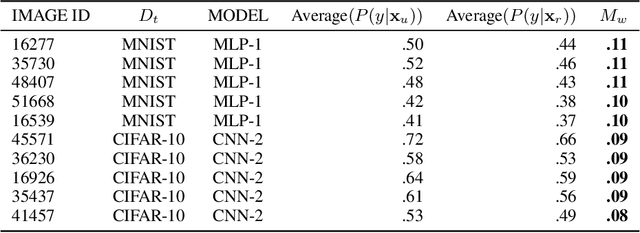

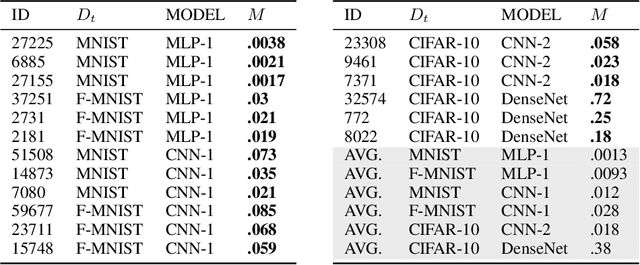
Neural networks pose a privacy risk due to their propensity to memorise and leak training data. We show that unique features occurring only once in training data are memorised by discriminative multi-layer perceptrons and convolutional neural networks trained on benchmark imaging datasets. We design our method for settings where sensitive training data is not available, for example medical imaging. Our setting knows the unique feature, but not the training data, model weights or the unique feature's label. We develop a score estimating a model's sensitivity to a unique feature by comparing the KL divergences of the model's output distributions given modified out-of-distribution images. We find that typical strategies to prevent overfitting do not prevent unique feature memorisation. And that images containing a unique feature are highly influential, regardless of the influence the images's other features. We also find a significant variation in memorisation with training seed. These results imply that neural networks pose a privacy risk to rarely occurring private information. This risk is more pronounced in healthcare applications since sensitive patient information can be memorised when it remains in training data due to an imperfect data sanitisation process.
Measuring Unintended Memorisation of Unique Private Features in Neural Networks
Feb 16, 2022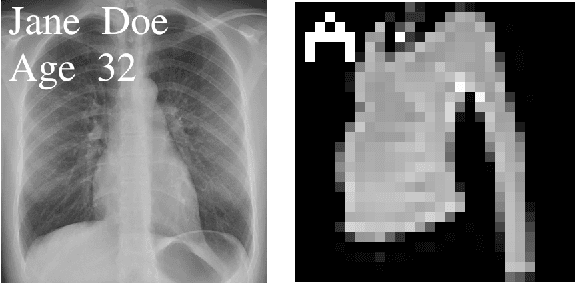
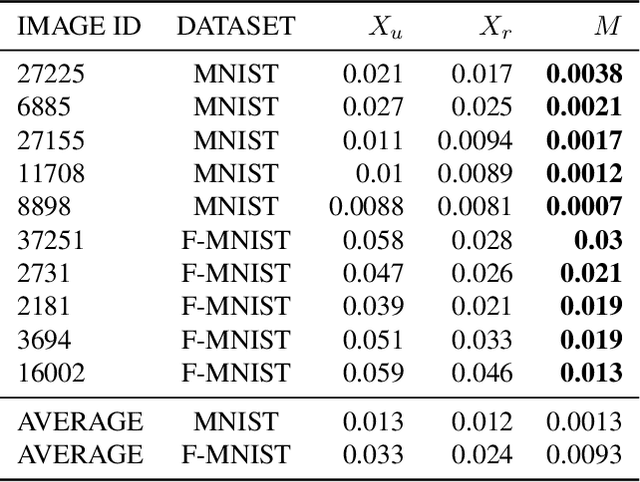

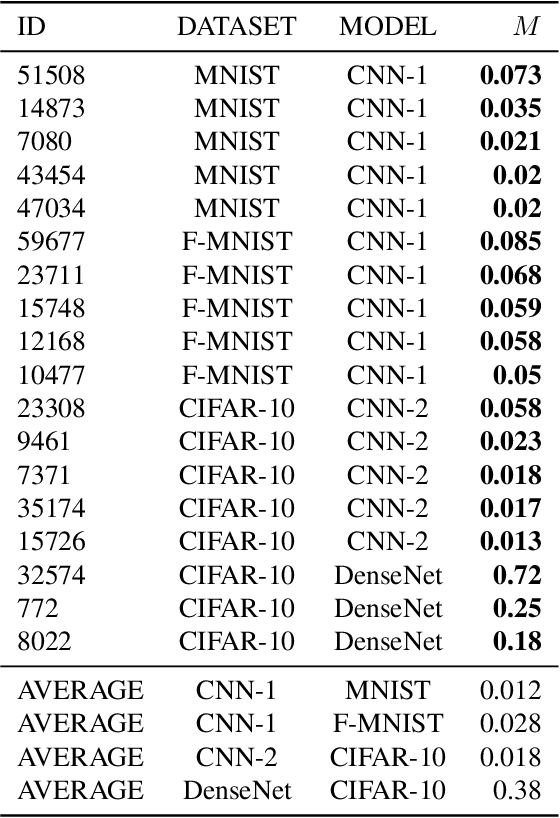
Neural networks pose a privacy risk to training data due to their propensity to memorise and leak information. Focusing on image classification, we show that neural networks also unintentionally memorise unique features even when they occur only once in training data. An example of a unique feature is a person's name that is accidentally present on a training image. Assuming access to the inputs and outputs of a trained model, the domain of the training data, and knowledge of unique features, we develop a score estimating the model's sensitivity to a unique feature by comparing the KL divergences of the model's output distributions given modified out-of-distribution images. Our results suggest that unique features are memorised by multi-layer perceptrons and convolutional neural networks trained on benchmark datasets, such as MNIST, Fashion-MNIST and CIFAR-10. We find that strategies to prevent overfitting (e.g.\ early stopping, regularisation, batch normalisation) do not prevent memorisation of unique features. These results imply that neural networks pose a privacy risk to rarely occurring private information. These risks can be more pronounced in healthcare applications if patient information is present in the training data.
Formation Control for UAVs Using a Flux Guided Approach
Mar 16, 2021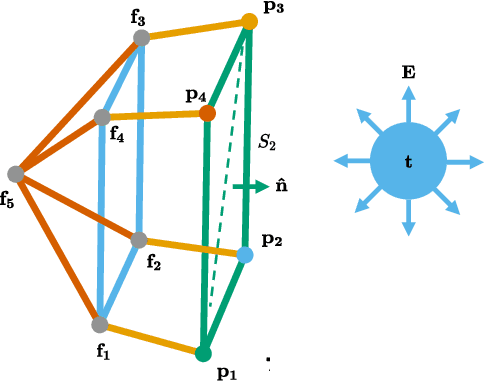
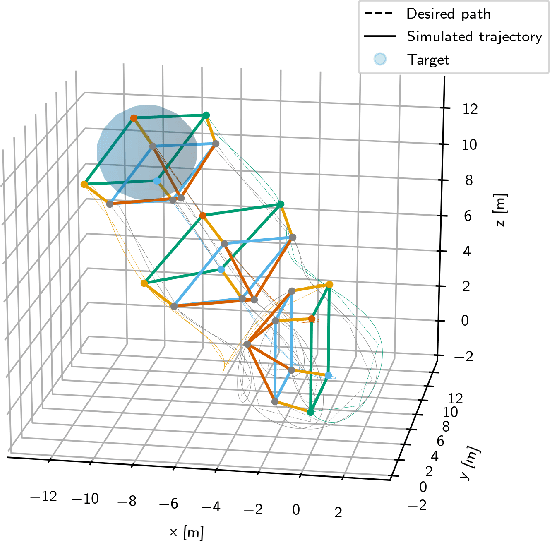
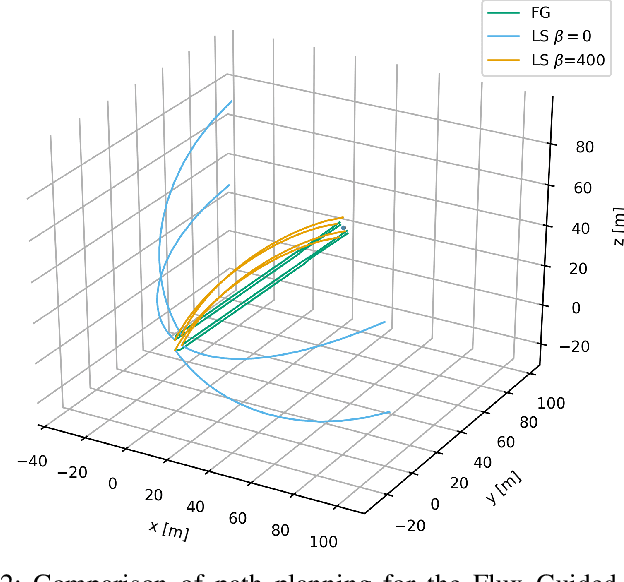
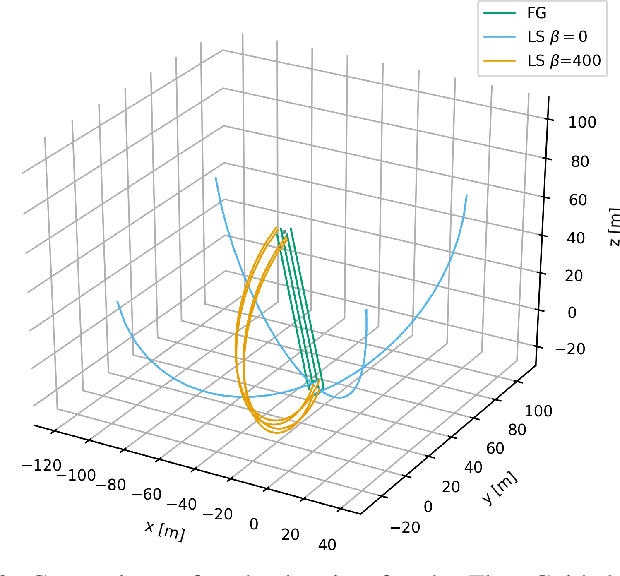
While multiple studies have proposed methods for the formation control of unmanned aerial vehicles (UAV), the trajectories generated are generally unsuitable for tracking targets where the optimum coverage of the target by the formation is required at all times. We propose a path planning approach called the Flux Guided (FG) method, which generates collision-free trajectories while maximising the coverage of one or more targets. We show that by reformulating an existing least-squares flux minimisation problem as a constrained optimisation problem, the paths obtained are $1.5 \times$ shorter and track directly toward the target. Also, we demonstrate that the scale of the formation can be controlled during flight, and that this feature can be used to track multiple scattered targets. The method is highly scalable since the planning algorithm is only required for a sub-set of UAVs on the open boundary of the formation's surface. Finally, through simulating a 3d dynamic particle system that tracks the desired trajectories using a PID controller, we show that the resulting trajectories after time-optimal parameterisation are suitable for robotic controls.