 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Blind Speech Separation and Dereverberation using Neural Beamforming
Mar 24, 2021
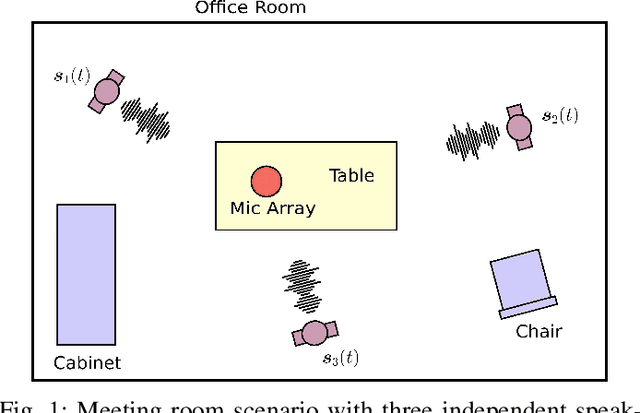
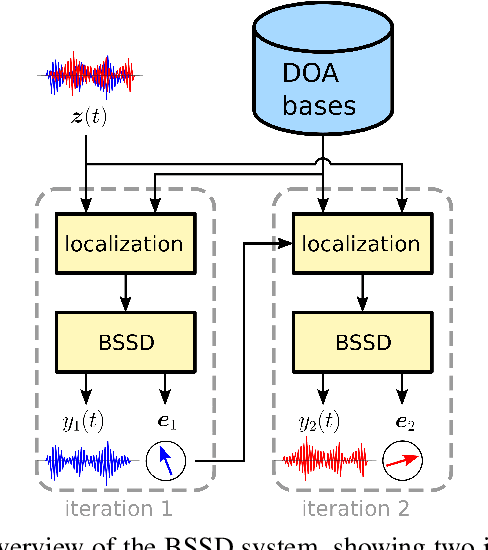
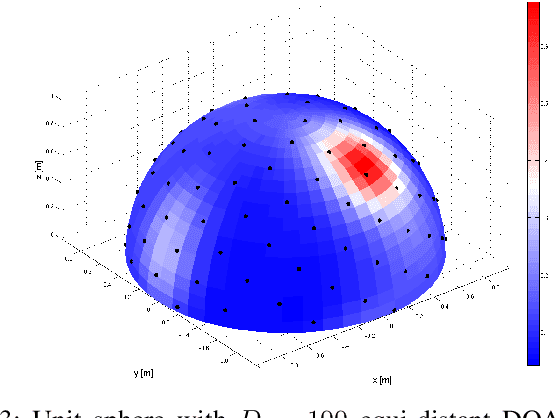
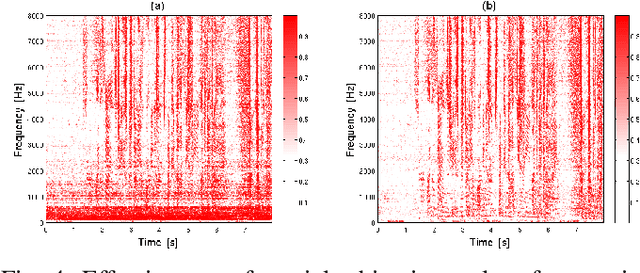
In this paper, we present the Blind Speech Separation and Dereverberation (BSSD) network, which performs simultaneous speaker separation, dereverberation and speaker identification in a single neural network. Speaker separation is guided by a set of predefined spatial cues. Dereverberation is performed by using neural beamforming, and speaker identification is aided by embedding vectors and triplet mining. We introduce a frequency-domain model which uses complex-valued neural networks, and a time-domain variant which performs beamforming in latent space. Further, we propose a block-online mode to process longer audio recordings, as they occur in meeting scenarios. We evaluate our system in terms of Scale Independent Signal to Distortion Ratio (SI-SDR), Word Error Rate (WER) and Equal Error Rate (EER).
StyleKQC: A Style-Variant Paraphrase Corpus for Korean Questions and Commands
Mar 24, 2021
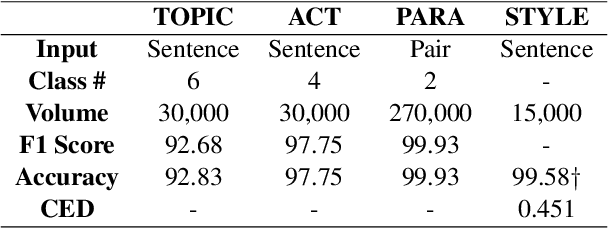
Paraphrasing is often performed with less concern for controlled style conversion. Especially for questions and commands, style-variant paraphrasing can be crucial in tone and manner, which also matters with industrial applications such as dialog system. In this paper, we attack this issue with a corpus construction scheme that simultaneously considers the core content and style of directives, namely intent and formality, for the Korean language. Utilizing manually generated natural language queries on six daily topics, we expand the corpus to formal and informal sentences by human rewriting and transferring. We verify the validity and industrial applicability of our approach by checking the adequate classification and inference performance that fit with the fine-tuning approaches, at the same time proposing a supervised formality transfer task.
Hierarchical Graph Neural Networks
May 07, 2021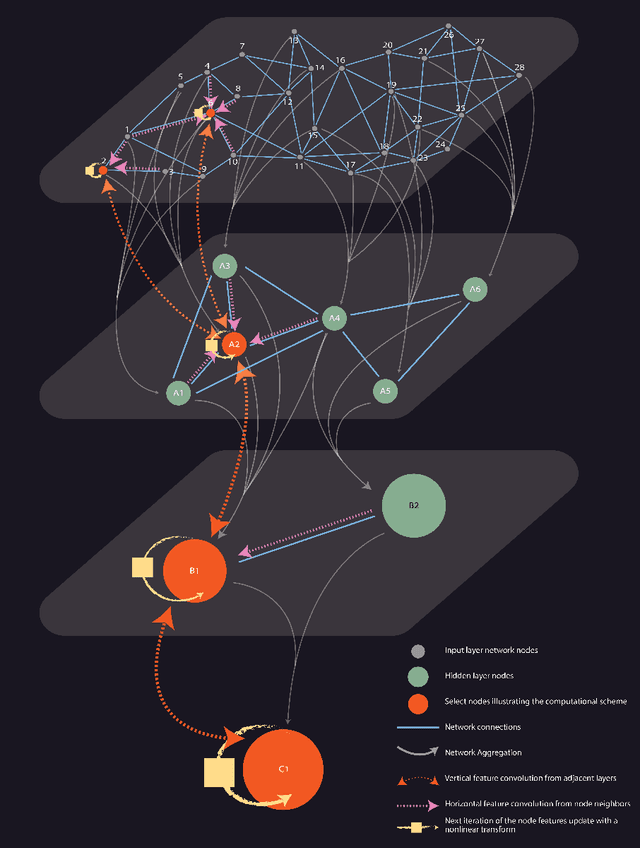
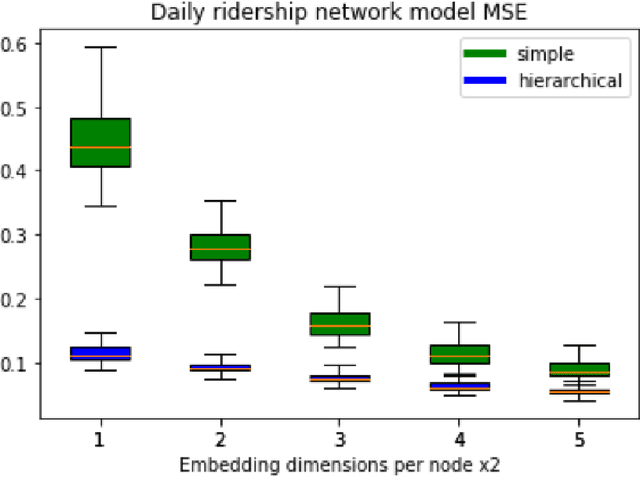
Over the recent years, Graph Neural Networks have become increasingly popular in network analytic and beyond. With that, their architecture noticeable diverges from the classical multi-layered hierarchical organization of the traditional neural networks. At the same time, many conventional approaches in network science efficiently utilize the hierarchical approaches to account for the hierarchical organization of the networks, and recent works emphasize their critical importance. This paper aims to connect the dots between the traditional Neural Network and the Graph Neural Network architectures as well as the network science approaches, harnessing the power of the hierarchical network organization. A Hierarchical Graph Neural Network architecture is proposed, supplementing the original input network layer with the hierarchy of auxiliary network layers and organizing the computational scheme updating the node features through both - horizontal network connections within each layer as well as the vertical connection between the layers. It enables simultaneous learning of the individual node features along with the aggregated network features at variable resolution and uses them to improve the convergence and stability of the individual node feature learning. The proposed Hierarchical Graph Neural network architecture is successfully evaluated on the network embedding and modeling as well as network classification, node labeling, and community tasks and demonstrates increased efficiency in those.
Profiling Visual Dynamic Complexity Using a Bio-Robotic Approach
May 20, 2021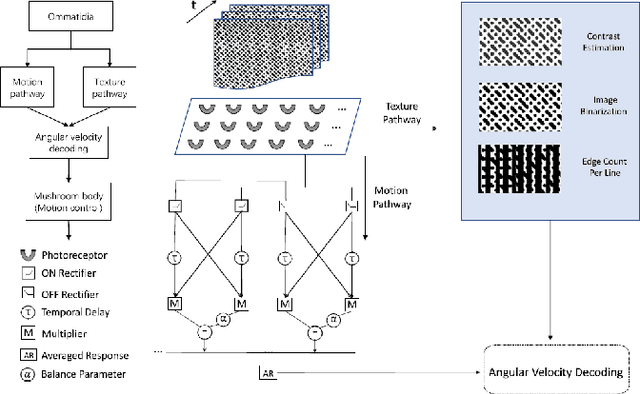
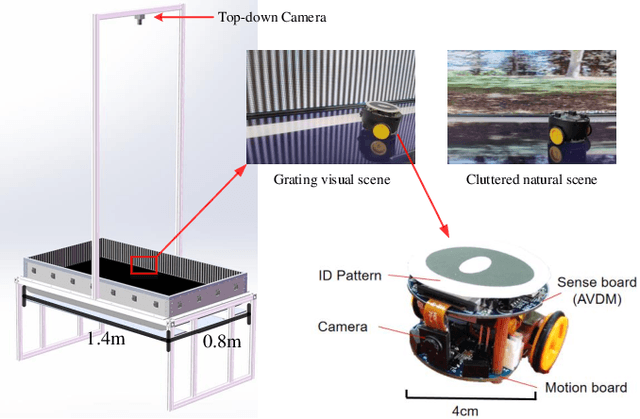
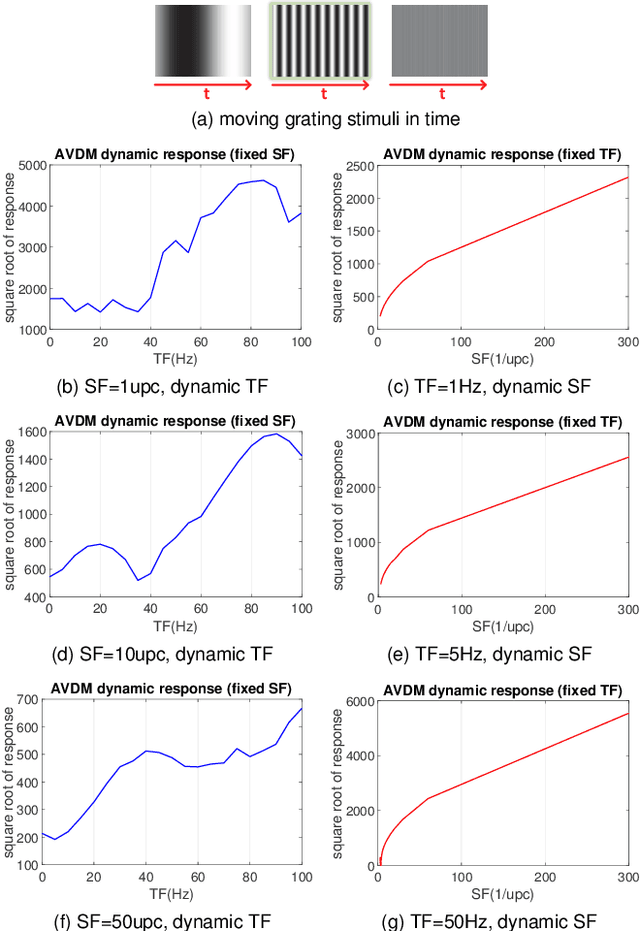
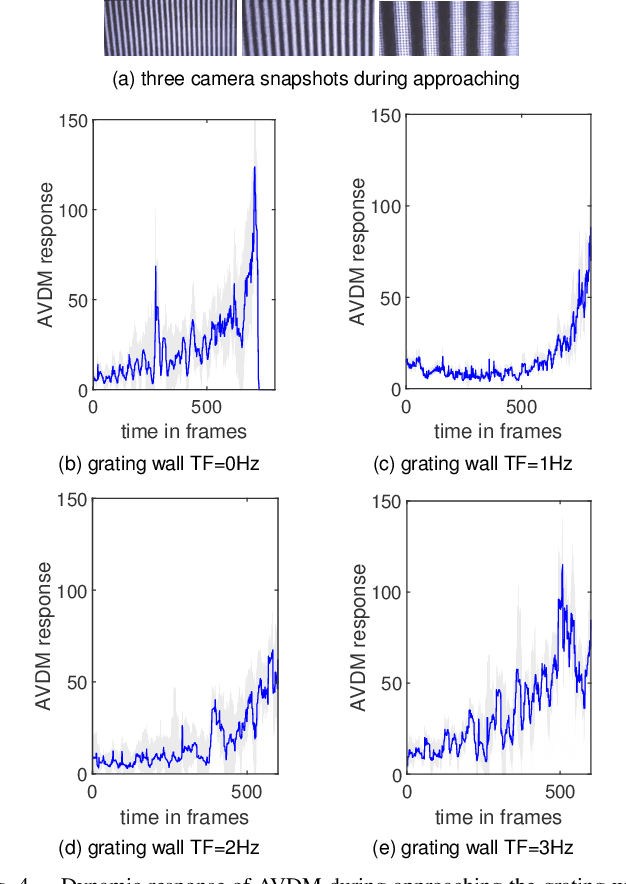
Visual dynamic complexity is a ubiquitous, hidden attribute of the visual world that every dynamic vision system is faced with. However, it is implicit and intractable which has never been quantitatively described due to the difficulty in defending temporal features correlated to spatial image complexity. To fill this vacancy, we propose a novel bio-robotic approach to profile visual dynamic complexity which can be used as a new metric. Here we apply a state-of-the-art brain-inspired motion detection neural network model to explicitly profile such complexity associated with spatial-temporal frequency (SF-TF) of visual scene. This model is for the first time implemented in an autonomous micro-mobile robot which navigates freely in an arena with visual walls displaying moving sine-wave grating or cluttered natural scene. The neural dynamic response can make reasonable prediction on surrounding complexity since it can be mapped monotonically to varying SF-TF of visual scene. The experiments show this approach is flexible to different visual scenes for profiling the dynamic complexity. We also use this metric as a predictor to investigate the boundary of another collision detection visual system performing in changing environment with increasing dynamic complexity. This research demonstrates a new paradigm of using biologically plausible visual processing scheme to estimate dynamic complexity of visual scene from both spatial and temporal perspectives, which could be beneficial to predicting input complexity when evaluating dynamic vision systems.
Certifiably-Robust Federated Adversarial Learning via Randomized Smoothing
Mar 30, 2021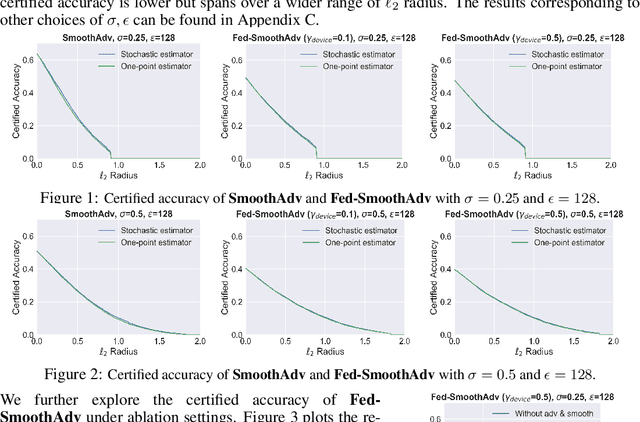
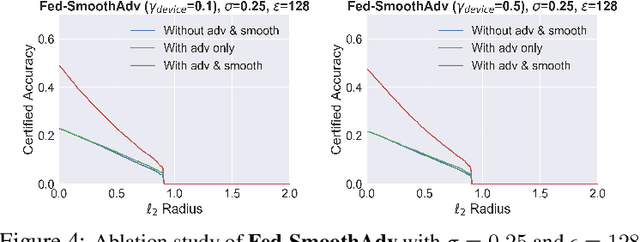
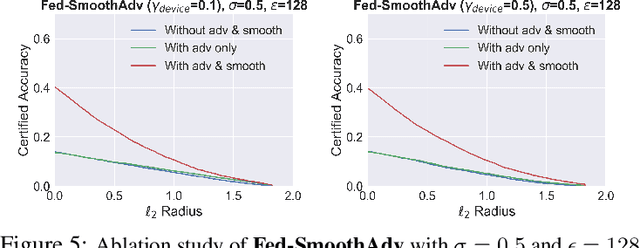
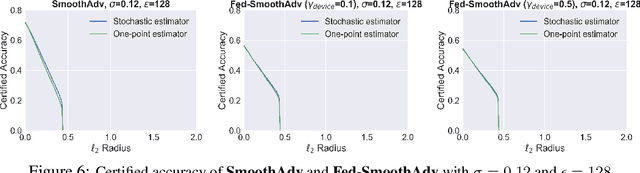
Federated learning is an emerging data-private distributed learning framework, which, however, is vulnerable to adversarial attacks. Although several heuristic defenses are proposed to enhance the robustness of federated learning, they do not provide certifiable robustness guarantees. In this paper, we incorporate randomized smoothing techniques into federated adversarial training to enable data-private distributed learning with certifiable robustness to test-time adversarial perturbations. Our experiments show that such an advanced federated adversarial learning framework can deliver models as robust as those trained by the centralized training. Further, this enables provably-robust classifiers to $\ell_2$-bounded adversarial perturbations in a distributed setup. We also show that one-point gradient estimation based training approach is $2-3\times$ faster than popular stochastic estimator based approach without any noticeable certified robustness differences.
Scaling End-to-End Models for Large-Scale Multilingual ASR
Apr 30, 2021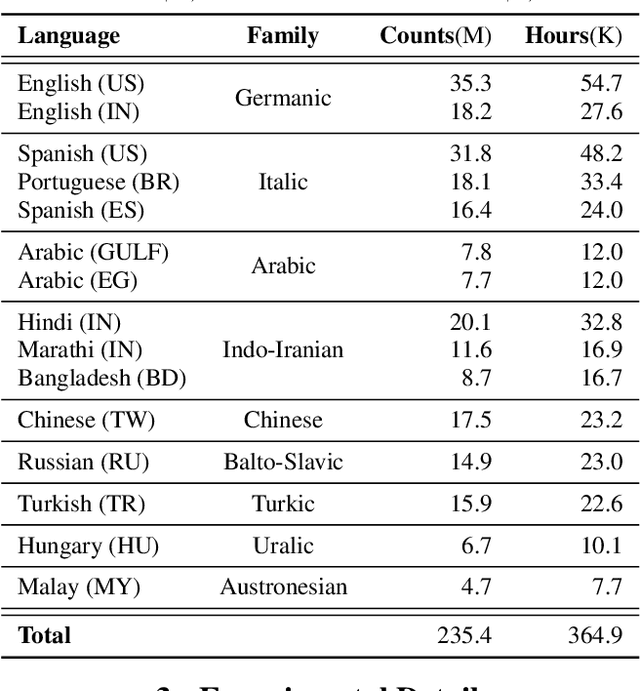
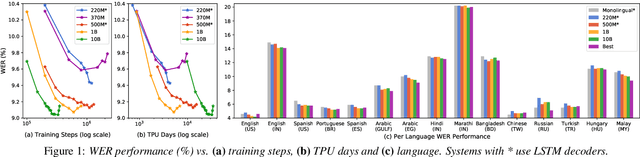
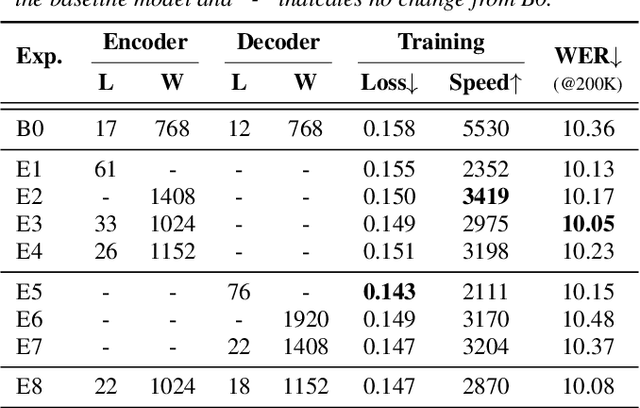
Building ASR models across many language families is a challenging multi-task learning problem due to large language variations and heavily unbalanced data. Existing work has shown positive transfer from high resource to low resource languages. However, degradations on high resource languages are commonly observed due to interference from the heterogeneous multilingual data and reduction in per-language capacity. We conduct a capacity study on a 15-language task, with the amount of data per language varying from 7.7K to 54.7K hours. We adopt GShard [1] to efficiently scale up to 10B parameters. Empirically, we find that (1) scaling the number of model parameters is an effective way to solve the capacity bottleneck - our 500M-param model is already better than monolingual baselines and scaling it to 1B and 10B brought further quality gains; (2) larger models are not only more data efficient, but also more efficient in terms of training cost as measured in TPU days - the 1B-param model reaches the same accuracy at 34% of training time as the 500M-param model; (3) given a fixed capacity budget, adding depth usually works better than width and large encoders tend to do better than large decoders.
Forecasting Using Reservoir Computing: The Role of Generalized Synchronization
Feb 28, 2021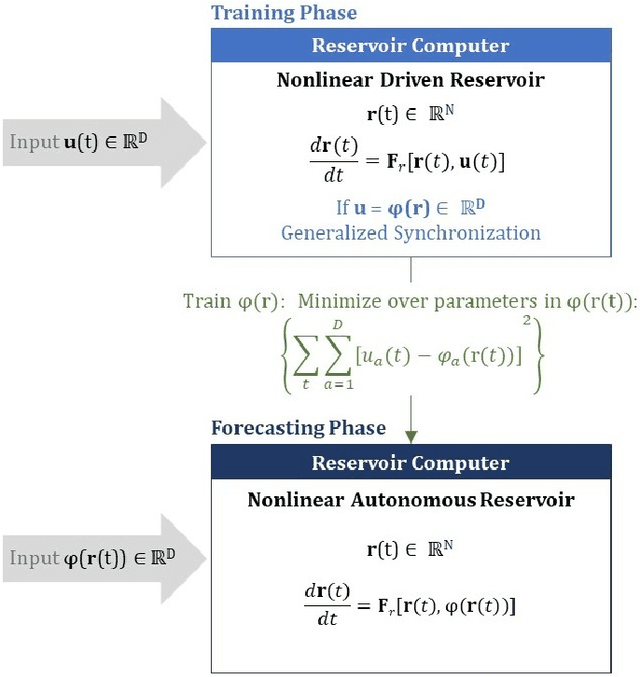
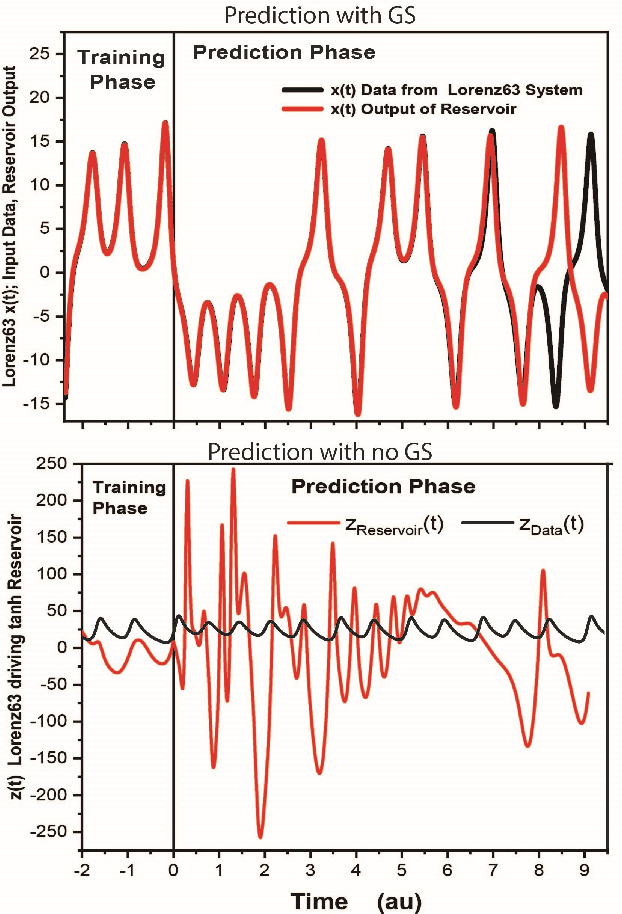
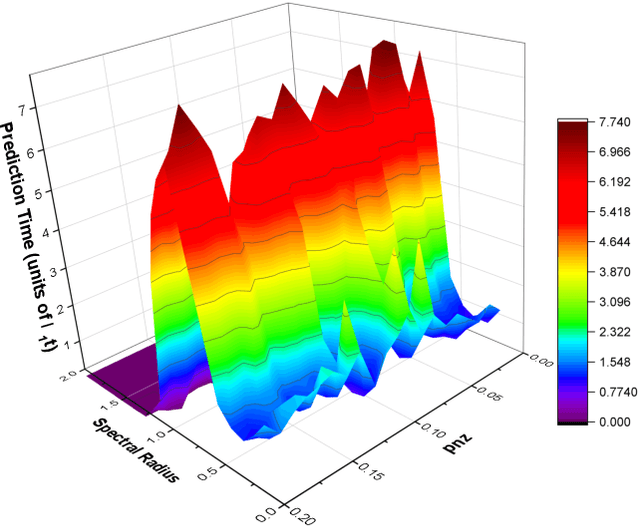
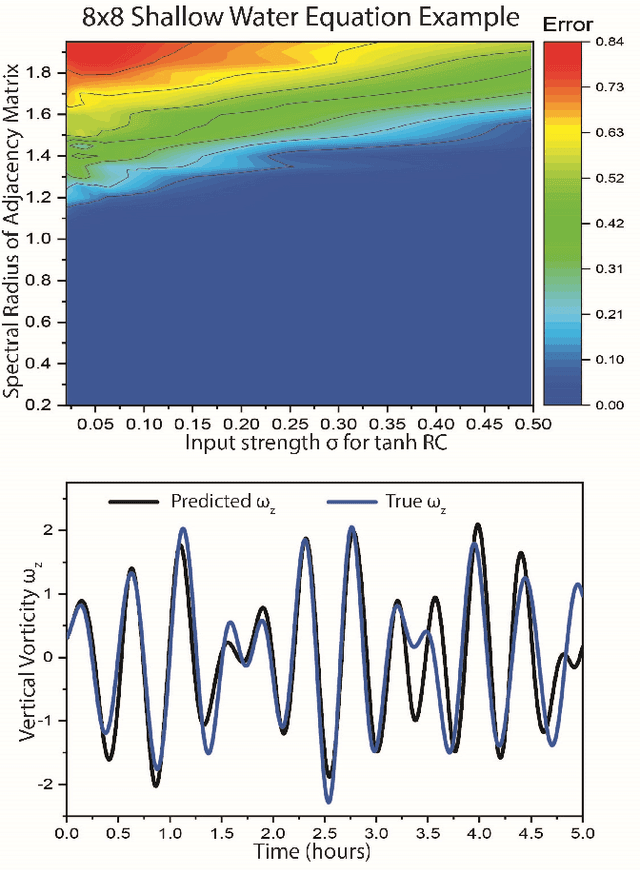
Reservoir computers (RC) are a form of recurrent neural network (RNN) used for forecasting time series data. As with all RNNs, selecting the hyperparameters presents a challenge when training on new inputs. We present a method based on generalized synchronization (GS) that gives direction in designing and evaluating the architecture and hyperparameters of a RC. The 'auxiliary method' for detecting GS provides a pre-training test that guides hyperparameter selection. Furthermore, we provide a metric for a "well trained" RC using the reproduction of the input system's Lyapunov exponents.
Customizable Stochastic High Fidelity Model of the Sensors and Camera onboard a Low SWaP Fixed Wing Autonomous Aircraft
Feb 12, 2021

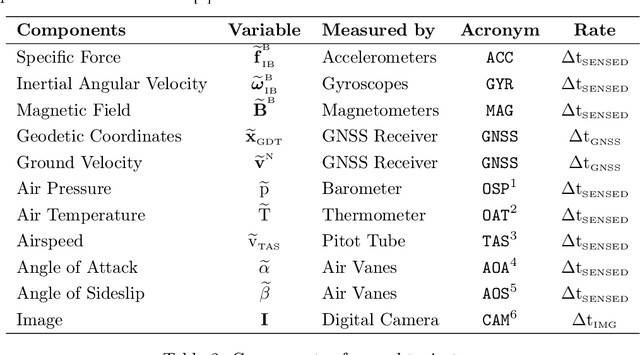
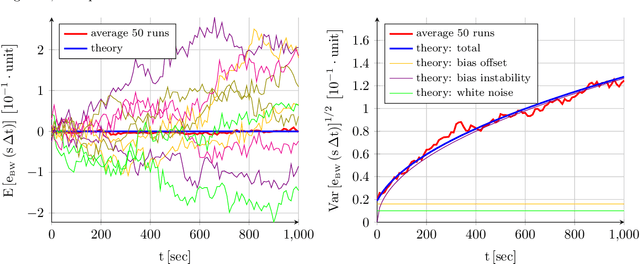
The navigation systems of autonomous aircraft rely on the readings provided by a suite of onboard sensors to estimate the aircraft state. In the case of fixed wing vehicles, the sensor suite is composed by triads of accelerometers, gyroscopes, and magnetometers, a Global Navigation Satellite System (GNSS) receiver, and an air data system (Pitot tube, air vanes, thermometer, and barometer), and is often complemented by one or more digital cameras. An accurate representation of the behavior and error sources of each of these sensors, together with the images generated by the cameras, in indispensable for flight simulation and the evaluation of novel inertial or visual navigation algorithms, and more so in the case of low SWaP (size, weight, and power) aircraft, in which the quality and price of the sensors is limited. This article presents realistic and customizable models for each of these sensors, which have been implemented as an open-source C ++ simulation. Provided with the true variation of the aircraft state with time, the simulation provides a time stamped series of the errors generated by all sensors, as well as realistic images of the Earth surface that resemble those taken from a real camera flying along the indicated state positions and attitudes.
Autonomous Off-road Navigation over Extreme Terrains with Perceptually-challenging Conditions
Jan 26, 2021
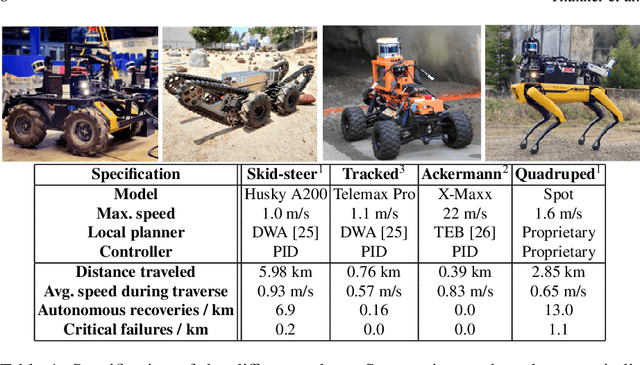
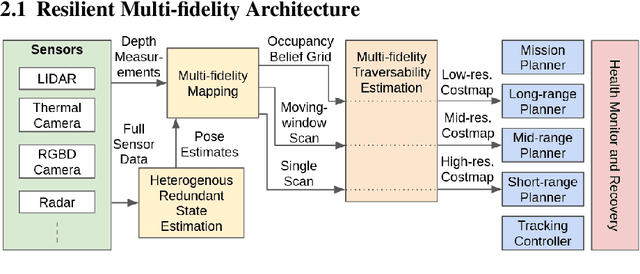
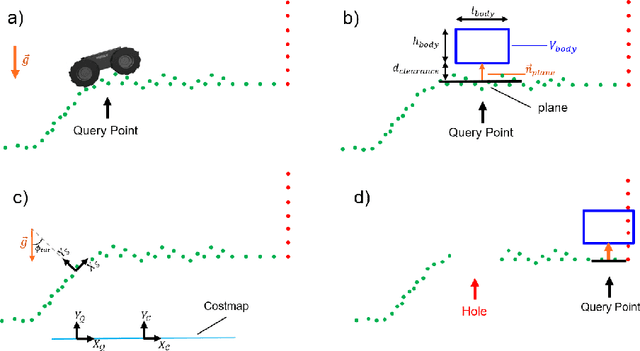
We propose a framework for resilient autonomous navigation in perceptually challenging unknown environments with mobility-stressing elements such as uneven surfaces with rocks and boulders, steep slopes, negative obstacles like cliffs and holes, and narrow passages. Environments are GPS-denied and perceptually-degraded with variable lighting from dark to lit and obscurants (dust, fog, smoke). Lack of prior maps and degraded communication eliminates the possibility of prior or off-board computation or operator intervention. This necessitates real-time on-board computation using noisy sensor data. To address these challenges, we propose a resilient architecture that exploits redundancy and heterogeneity in sensing modalities. Further resilience is achieved by triggering recovery behaviors upon failure. We propose a fast settling algorithm to generate robust multi-fidelity traversability estimates in real-time. The proposed approach was deployed on multiple physical systems including skid-steer and tracked robots, a high-speed RC car and legged robots, as a part of Team CoSTAR's effort to the DARPA Subterranean Challenge, where the team won 2nd and 1st place in the Tunnel and Urban Circuits, respectively.
A Novel GAN-based Fault Diagnosis Approach for Imbalanced Industrial Time Series
Apr 01, 2019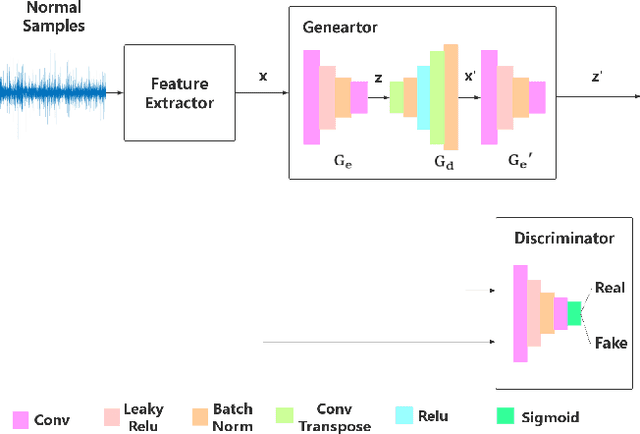
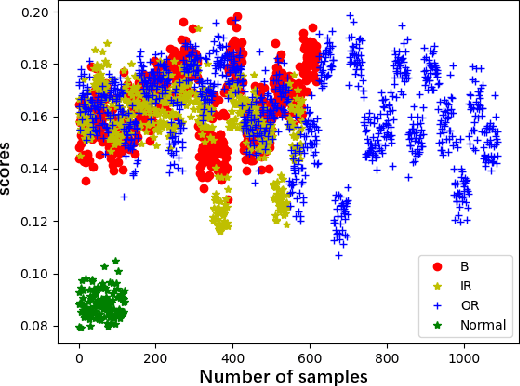
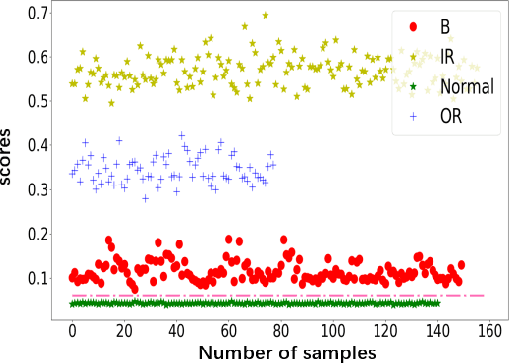
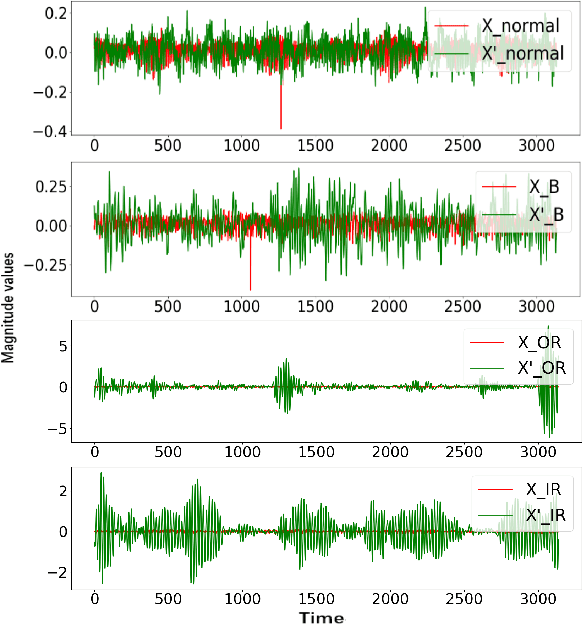
This paper proposes a novel fault diagnosis approach based on generative adversarial networks (GAN) for imbalanced industrial time series where normal samples are much larger than failure cases. We combine a well-designed feature extractor with GAN to help train the whole network. Aimed at obtaining data distribution and hidden pattern in both original distinguishing features and latent space, the encoder-decoder-encoder three-sub-network is employed in GAN, based on Deep Convolution Generative Adversarial Networks (DCGAN) but without Tanh activation layer and only trained on normal samples. In order to verify the validity and feasibility of our approach, we test it on rolling bearing data from Case Western Reserve University and further verify it on data collected from our laboratory. The results show that our proposed approach can achieve excellent performance in detecting faulty by outputting much larger evaluation scores.