 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Space-Time Extension of the MEM Approach for Electromagnetic Neuroimaging
Jul 24, 2018
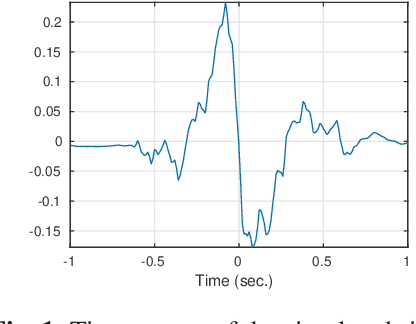
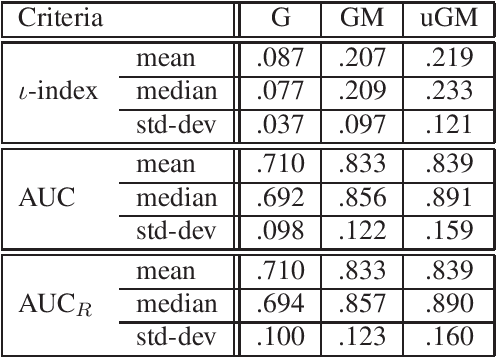
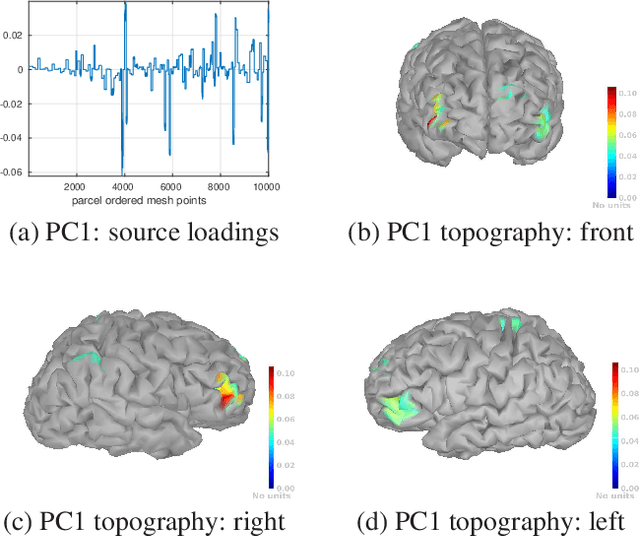
The wavelet Maximum Entropy on the Mean (wMEM) approach to the MEG inverse problem is revisited and extended to infer brain activity from full space-time data. The resulting dimensionality increase is tackled using a collection of techniques , that includes time and space dimension reduction (using respectively wavelet and spatial filter based reductions), Kronecker product modeling for covariance matrices, and numerical manipulation of the free energy directly in matrix form. This leads to a smooth numerical optimization problem of reasonable dimension, solved using standard approaches. The method is applied to the MEG inverse problem. Results of a simulation study in the context of slow wave localization from sleep MEG data are presented and discussed. Index Terms: MEG inverse problem, maximum entropy on the mean, wavelet decomposition, spatial filters, Kronecker covariance factorization, sleep slow waves.
Large-Scale Spatio-Temporal Person Re-identification: Algorithm and Benchmark
Jun 24, 2021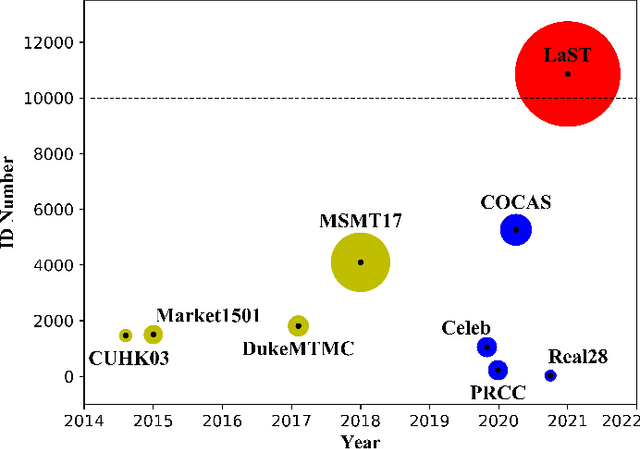
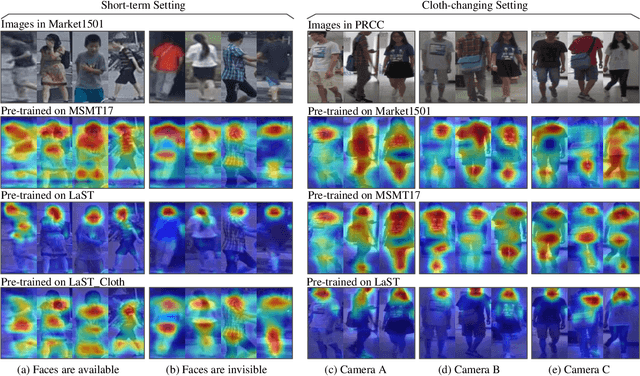
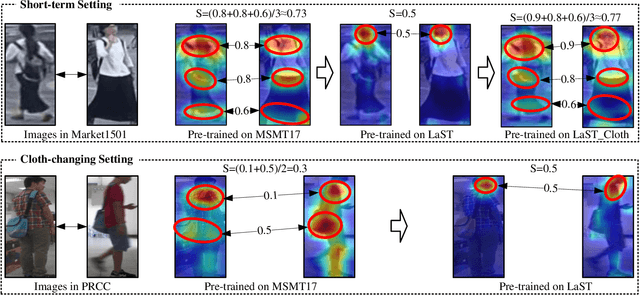

Person re-identification (re-ID) in the scenario with large spatial and temporal spans has not been fully explored. This is partially because that, existing benchmark datasets were mainly collected with limited spatial and temporal ranges, e.g., using videos recorded in a few days by cameras in a specific region of the campus. Such limited spatial and temporal ranges make it hard to simulate the difficulties of person re-ID in real scenarios. In this work, we contribute a novel Large-scale Spatio-Temporal LaST person re-ID dataset, including 10,862 identities with more than 228k images. Compared with existing datasets, LaST presents more challenging and high-diversity re-ID settings, and significantly larger spatial and temporal ranges. For instance, each person can appear in different cities or countries, and in various time slots from daytime to night, and in different seasons from spring to winter. To our best knowledge, LaST is a novel person re-ID dataset with the largest spatio-temporal ranges. Based on LaST, we verified its challenge by conducting a comprehensive performance evaluation of 14 re-ID algorithms. We further propose an easy-to-implement baseline that works well on such challenging re-ID setting. We also verified that models pre-trained on LaST can generalize well on existing datasets with short-term and cloth-changing scenarios. We expect LaST to inspire future works toward more realistic and challenging re-ID tasks. More information about the dataset is available at https://github.com/shuxjweb/last.git.
Combinatorial Multi-armed Bandits for Resource Allocation
May 10, 2021We study the sequential resource allocation problem where a decision maker repeatedly allocates budgets between resources. Motivating examples include allocating limited computing time or wireless spectrum bands to multiple users (i.e., resources). At each timestep, the decision maker should distribute its available budgets among different resources to maximize the expected reward, or equivalently to minimize the cumulative regret. In doing so, the decision maker should learn the value of the resources allocated for each user from feedback on each user's received reward. For example, users may send messages of different urgency over wireless spectrum bands; the reward generated by allocating spectrum to a user then depends on the message's urgency. We assume each user's reward follows a random process that is initially unknown. We design combinatorial multi-armed bandit algorithms to solve this problem with discrete or continuous budgets. We prove the proposed algorithms achieve logarithmic regrets under semi-bandit feedback.
Sparse Training via Boosting Pruning Plasticity with Neuroregeneration
Jun 19, 2021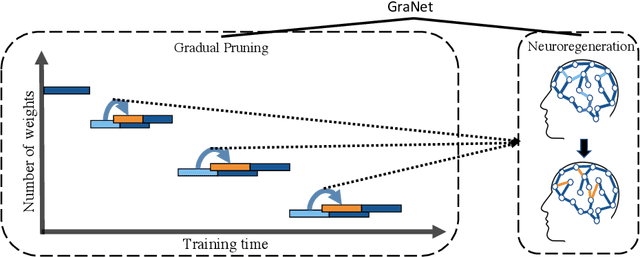
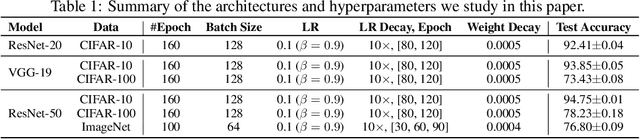
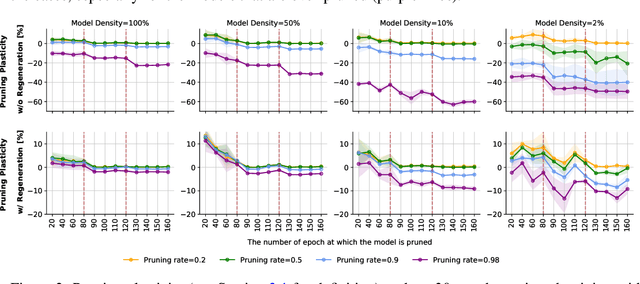
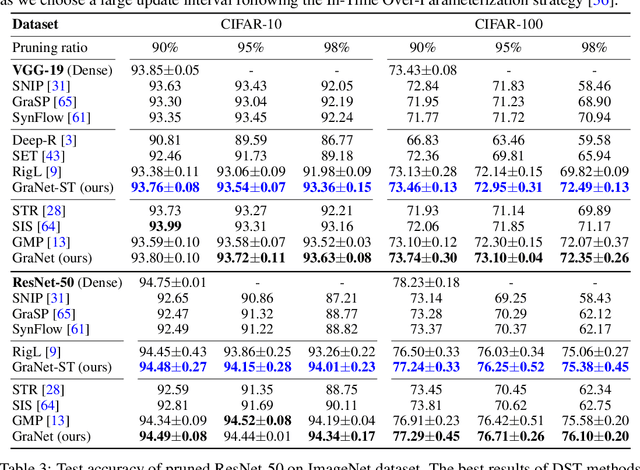
Works on lottery ticket hypothesis (LTH) and single-shot network pruning (SNIP) have raised a lot of attention currently on post-training pruning (iterative magnitude pruning), and before-training pruning (pruning at initialization). The former method suffers from an extremely large computation cost and the latter category of methods usually struggles with insufficient performance. In comparison, during-training pruning, a class of pruning methods that simultaneously enjoys the training/inference efficiency and the comparable performance, temporarily, has been less explored. To better understand during-training pruning, we quantitatively study the effect of pruning throughout training from the perspective of pruning plasticity (the ability of the pruned networks to recover the original performance). Pruning plasticity can help explain several other empirical observations about neural network pruning in literature. We further find that pruning plasticity can be substantially improved by injecting a brain-inspired mechanism called neuroregeneration, i.e., to regenerate the same number of connections as pruned. Based on the insights from pruning plasticity, we design a novel gradual magnitude pruning (GMP) method, named gradual pruning with zero-cost neuroregeneration (GraNet), and its dynamic sparse training (DST) variant (GraNet-ST). Both of them advance state of the art. Perhaps most impressively, the latter for the first time boosts the sparse-to-sparse training performance over various dense-to-sparse methods by a large margin with ResNet-50 on ImageNet. We will release all codes.
Generating Long-term Continuous Multi-type Generation Profiles using Generative Adversarial Network
Dec 22, 2020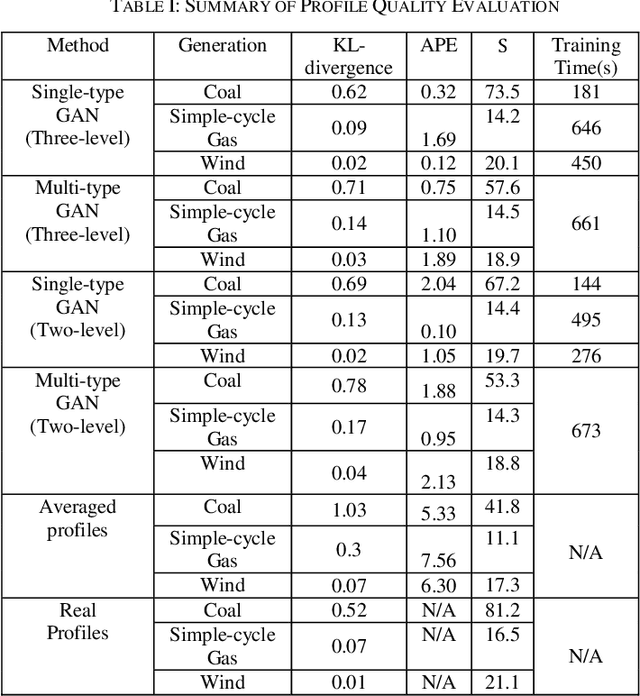
Today, the adoption of new technologies has increased power system dynamics significantly. Traditional long-term planning studies that most utility companies perform based on discrete power levels such as peak or average values cannot reflect system dynamics and often fail to accurately predict system reliability deficiencies. As a result, long-term future continuous profiles such as the 8760 hourly profiles are required to enable time-series based long-term planning studies. However, unlike short-term profiles used for operation studies, generating long-term continuous profiles that can reflect both historical time-varying characteristics and future expected power magnitude is very challenging. Current methods such as average profiling have major drawbacks. To solve this challenge, this paper proposes a completely novel approach to generate such profiles for multiple generation types using Generative Adversarial Networks (GAN). A multi-level profile synthesis process is proposed to capture time-varying characteristics at different time levels. Both Single-type GAN and a modified Conditional GAN systems are developed. Unique profile evaluation metrics are proposed. The proposed approach was evaluated based on a public dataset and demonstrated great performance and application value for generating long-term continuous multi-type generation profiles.
Trialstreamer: Mapping and Browsing Medical Evidence in Real-Time
May 21, 2020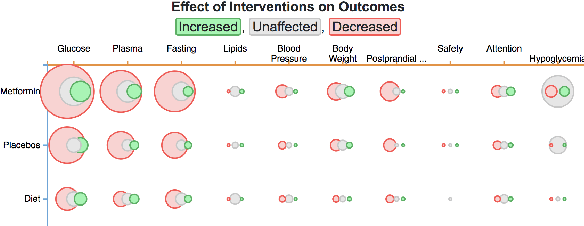
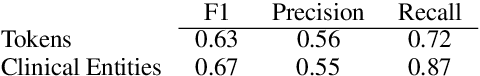
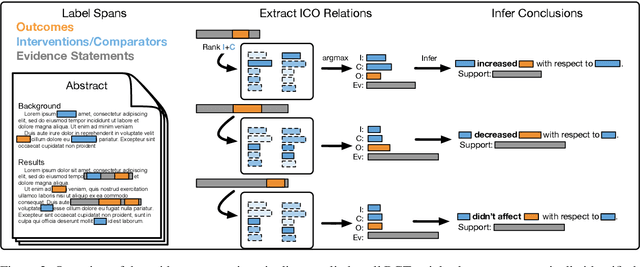
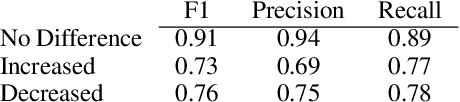
We introduce Trialstreamer, a living database of clinical trial reports. Here we mainly describe the evidence extraction component; this extracts from biomedical abstracts key pieces of information that clinicians need when appraising the literature, and also the relations between these. Specifically, the system extracts descriptions of trial participants, the treatments compared in each arm (the interventions), and which outcomes were measured. The system then attempts to infer which interventions were reported to work best by determining their relationship with identified trial outcome measures. In addition to summarizing individual trials, these extracted data elements allow automatic synthesis of results across many trials on the same topic. We apply the system at scale to all reports of randomized controlled trials indexed in MEDLINE, powering the automatic generation of evidence maps, which provide a global view of the efficacy of different interventions combining data from all relevant clinical trials on a topic. We make all code and models freely available alongside a demonstration of the web interface.
PANTHER: Perception-Aware Trajectory Planner in Dynamic Environments
Mar 10, 2021
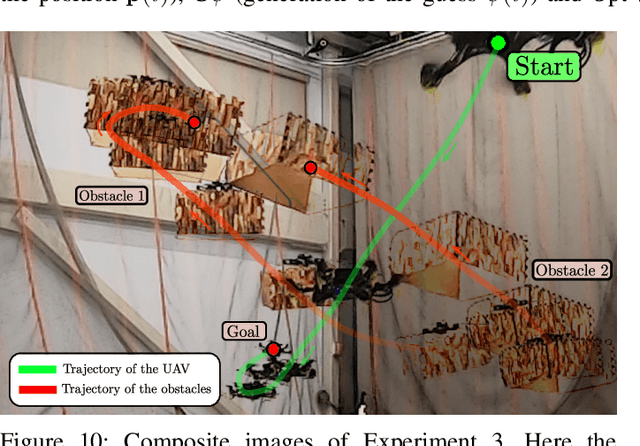
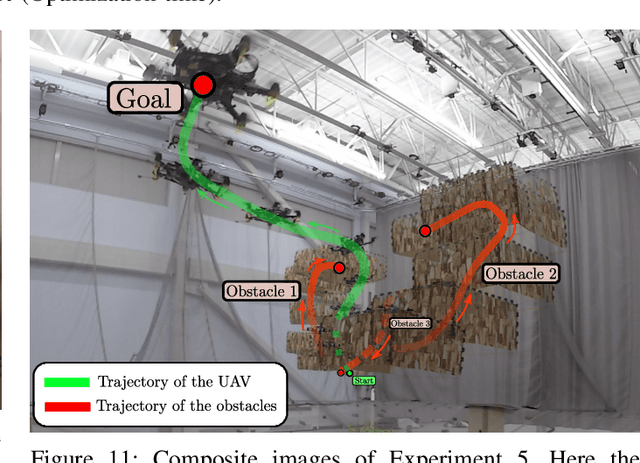
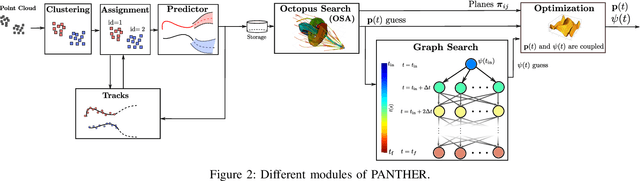
This paper presents PANTHER, a real-time perception-aware (PA) trajectory planner in dynamic environments. PANTHER plans trajectories that avoid dynamic obstacles while also keeping them in the sensor field of view (FOV) and minimizing the blur to aid in object tracking. The rotation and translation of the UAV are jointly optimized, which allows PANTHER to fully exploit the differential flatness of multirotors. Real-time performance is achieved by implicitly imposing this constraint through the Hopf fibration. PANTHER is able to keep the obstacles inside the FOV 7.4 and 1.5 times more than non-PA approaches and PA approaches that decouple translation and yaw, respectively. The projected velocity (and hence the blur) is reduced by 30%. Our recently-derived MINVO basis is used to impose low-conservative collision avoidance constraints in position and velocity space. Finally, extensive hardware experiments in unknown dynamic environments with all the computation running onboard are presented, with velocities of up to 5.8 m/s, and with relative velocities (with respect to the obstacles) of up to 6.3 m/s. The only sensors used are an IMU, a forward-facing depth camera, and a downward-facing monocular camera.
SA-GAN: Structure-Aware Generative Adversarial Network for Shape-Preserving Synthetic CT Generation
May 14, 2021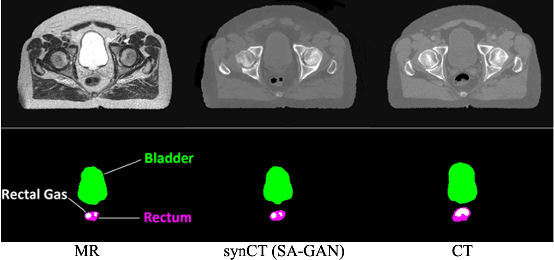

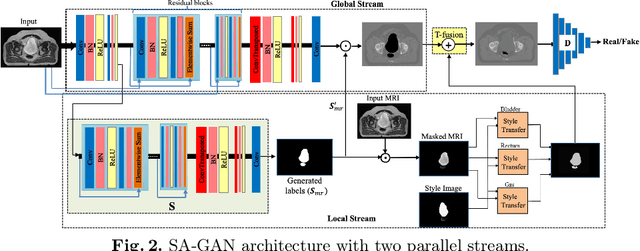
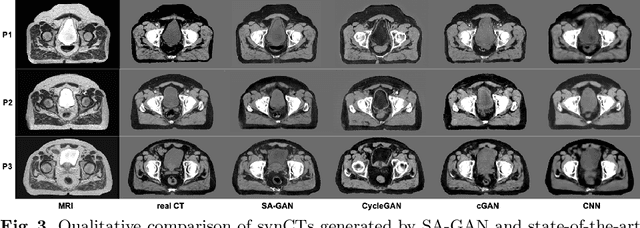
In medical image synthesis, model training could be challenging due to the inconsistencies between images of different modalities even with the same patient, typically caused by internal status/tissue changes as different modalities are usually obtained at a different time. This paper proposes a novel deep learning method, Structure-aware Generative Adversarial Network (SA-GAN), that preserves the shapes and locations of in-consistent structures when generating medical images. SA-GAN is employed to generate synthetic computed tomography (synCT) images from magnetic resonance imaging (MRI) with two parallel streams: the global stream translates the input from the MRI to the CT domain while the local stream automatically segments the inconsistent organs, maintains their locations and shapes in MRI, and translates the organ intensities to CT. Through extensive experiments on a pelvic dataset, we demonstrate that SA-GAN provides clinically acceptable accuracy on both synCTs and organ segmentation and supports MR-only treatment planning in disease sites with internal organ status changes.
Stimuli-Sensitive Hawkes Processes for Personalized Student Procrastination Modeling
Jan 29, 2021
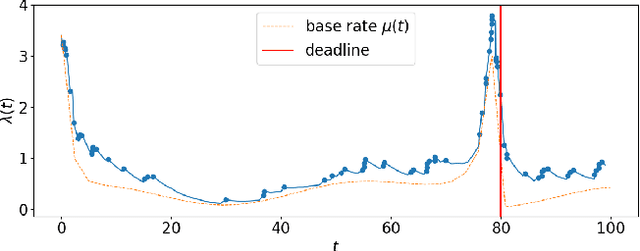
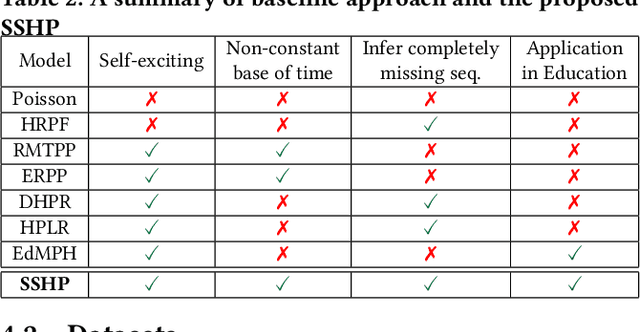
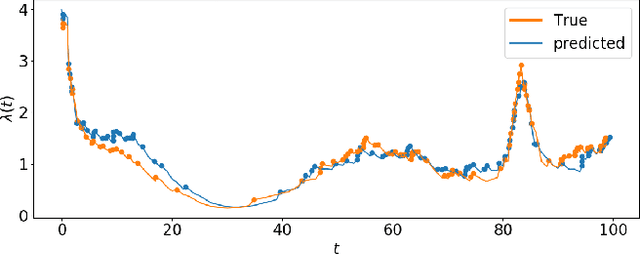
Student procrastination and cramming for deadlines are major challenges in online learning environments, with negative educational and well-being side effects. Modeling student activities in continuous time and predicting their next study time are important problems that can help in creating personalized timely interventions to mitigate these challenges. However, previous attempts on dynamic modeling of student procrastination suffer from major issues: they are unable to predict the next activity times, cannot deal with missing activity history, are not personalized, and disregard important course properties, such as assignment deadlines, that are essential in explaining the cramming behavior. To resolve these problems, we introduce a new personalized stimuli-sensitive Hawkes process model (SSHP), by jointly modeling all student-assignment pairs and utilizing their similarities, to predict students' next activity times even when there are no historical observations. Unlike regular point processes that assume a constant external triggering effect from the environment, we model three dynamic types of external stimuli, according to assignment availabilities, assignment deadlines, and each student's time management habits. Our experiments on two synthetic datasets and two real-world datasets show a superior performance of future activity prediction, comparing with state-of-the-art models. Moreover, we show that our model achieves a flexible and accurate parameterization of activity intensities in students.
Exploring Robustness of Unsupervised Domain Adaptation in Semantic Segmentation
May 23, 2021
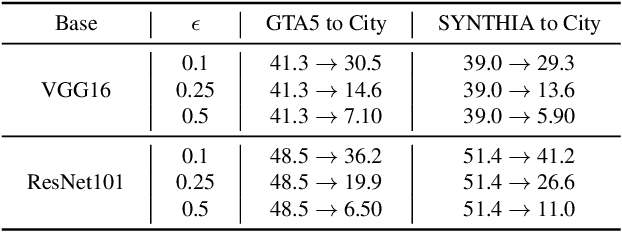
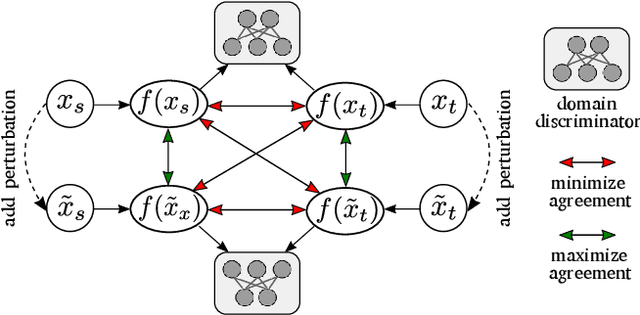
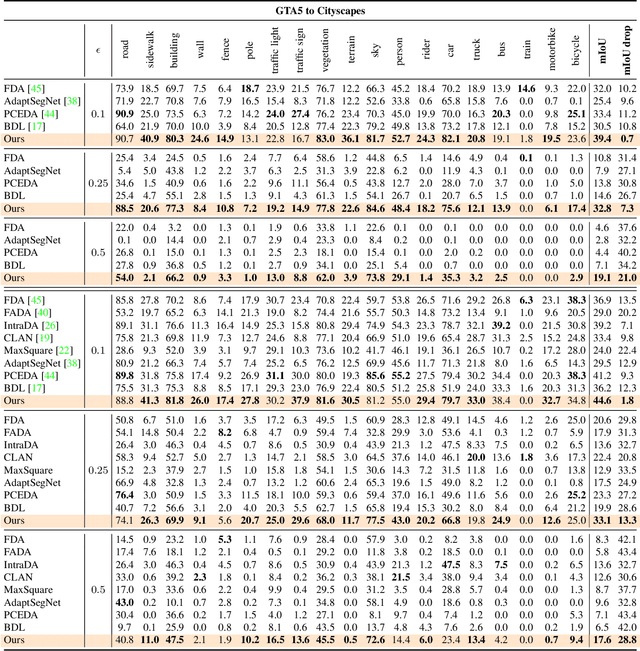
Recent studies imply that deep neural networks are vulnerable to adversarial examples -- inputs with a slight but intentional perturbation are incorrectly classified by the network. Such vulnerability makes it risky for some security-related applications (e.g., semantic segmentation in autonomous cars) and triggers tremendous concerns on the model reliability. For the first time, we comprehensively evaluate the robustness of existing UDA methods and propose a robust UDA approach. It is rooted in two observations: (i) the robustness of UDA methods in semantic segmentation remains unexplored, which pose a security concern in this field; and (ii) although commonly used self-supervision (e.g., rotation and jigsaw) benefits image tasks such as classification and recognition, they fail to provide the critical supervision signals that could learn discriminative representation for segmentation tasks. These observations motivate us to propose adversarial self-supervision UDA (or ASSUDA) that maximizes the agreement between clean images and their adversarial examples by a contrastive loss in the output space. Extensive empirical studies on commonly used benchmarks demonstrate that ASSUDA is resistant to adversarial attacks.