 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Domain Adaptive YOLO for One-Stage Cross-Domain Detection
Jun 26, 2021
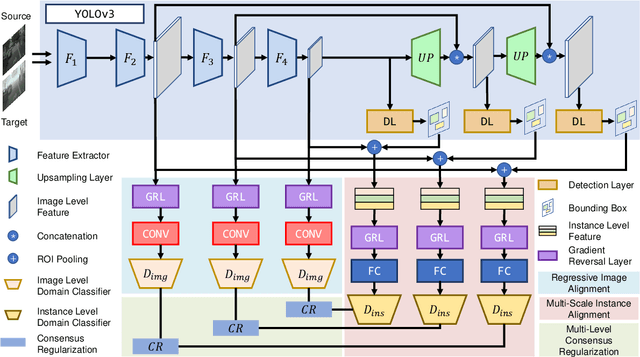
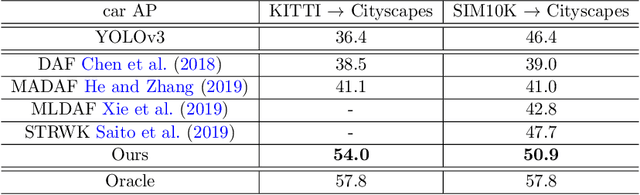


Domain shift is a major challenge for object detectors to generalize well to real world applications. Emerging techniques of domain adaptation for two-stage detectors help to tackle this problem. However, two-stage detectors are not the first choice for industrial applications due to its long time consumption. In this paper, a novel Domain Adaptive YOLO (DA-YOLO) is proposed to improve cross-domain performance for one-stage detectors. Image level features alignment is used to strictly match for local features like texture, and loosely match for global features like illumination. Multi-scale instance level features alignment is presented to reduce instance domain shift effectively , such as variations in object appearance and viewpoint. A consensus regularization to these domain classifiers is employed to help the network generate domain-invariant detections. We evaluate our proposed method on popular datasets like Cityscapes, KITTI, SIM10K and etc.. The results demonstrate significant improvement when tested under different cross-domain scenarios.
Towards Real-Time Automatic Portrait Matting on Mobile Devices
Apr 08, 2019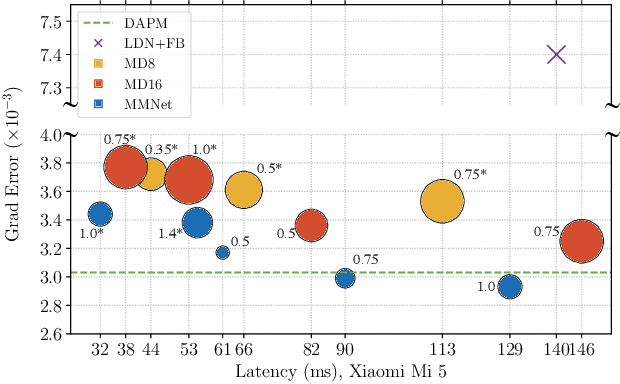
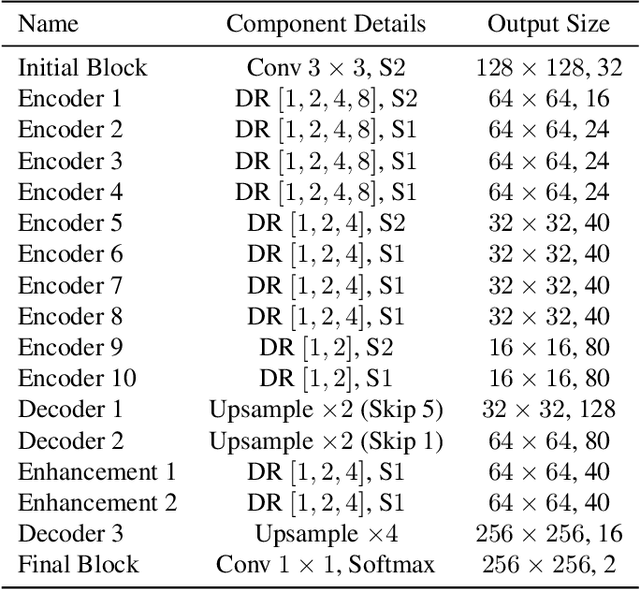

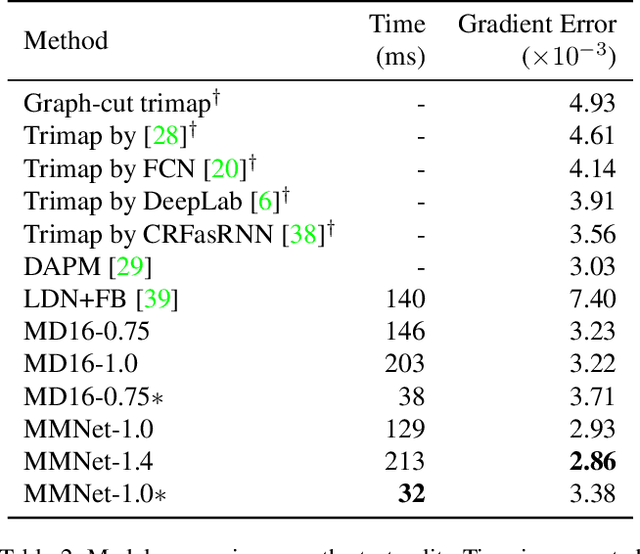
We tackle the problem of automatic portrait matting on mobile devices. The proposed model is aimed at attaining real-time inference on mobile devices with minimal degradation of model performance. Our model MMNet, based on multi-branch dilated convolution with linear bottleneck blocks, outperforms the state-of-the-art model and is orders of magnitude faster. The model can be accelerated four times to attain 30 FPS on Xiaomi Mi 5 device with moderate increase in the gradient error. Under the same conditions, our model has an order of magnitude less number of parameters and is faster than Mobile DeepLabv3 while maintaining comparable performance. The accompanied implementation can be found at \url{https://github.com/hyperconnect/MMNet}.
Byzantine-robust Federated Learning through Spatial-temporal Analysis of Local Model Updates
Jul 03, 2021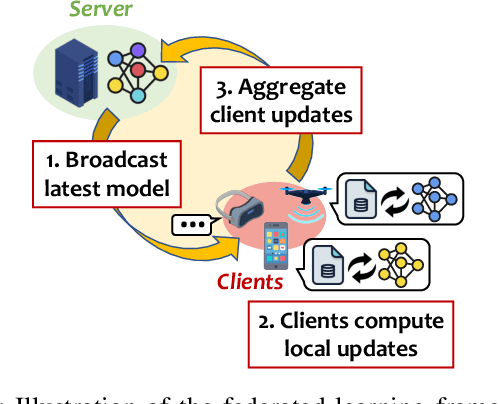
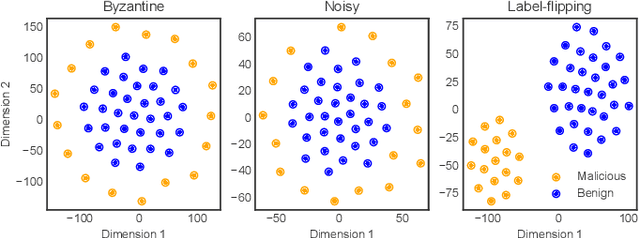
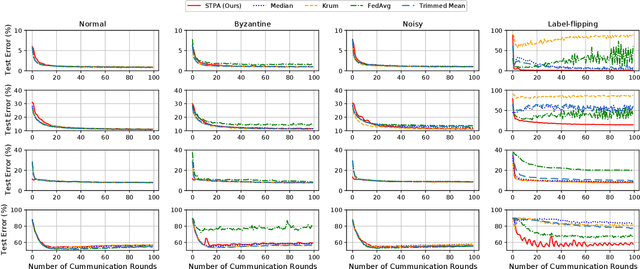
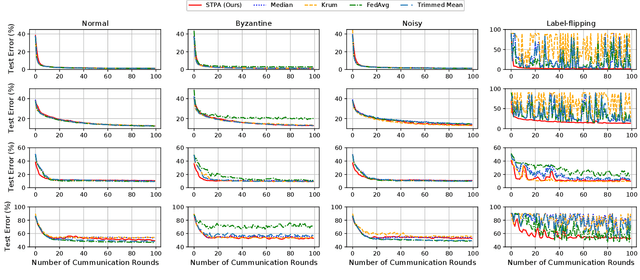
Federated Learning (FL) enables multiple distributed clients (e.g., mobile devices) to collaboratively train a centralized model while keeping the training data locally on the client. Compared to traditional centralized machine learning, FL offers many favorable features such as offloading operations which would usually be performed by a central server and reducing risks of serious privacy leakage. However, Byzantine clients that send incorrect or disruptive updates due to system failures or adversarial attacks may disturb the joint learning process, consequently degrading the performance of the resulting model. In this paper, we propose to mitigate these failures and attacks from a spatial-temporal perspective. Specifically, we use a clustering-based method to detect and exclude incorrect updates by leveraging their geometric properties in the parameter space. Moreover, to further handle malicious clients with time-varying behaviors, we propose to adaptively adjust the learning rate according to momentum-based update speculation. Extensive experiments on 4 public datasets demonstrate that our algorithm achieves enhanced robustness comparing to existing methods under both cross-silo and cross-device FL settings with faulty/malicious clients.
Visual Representation Learning Does Not Generalize Strongly Within the Same Domain
Jul 23, 2021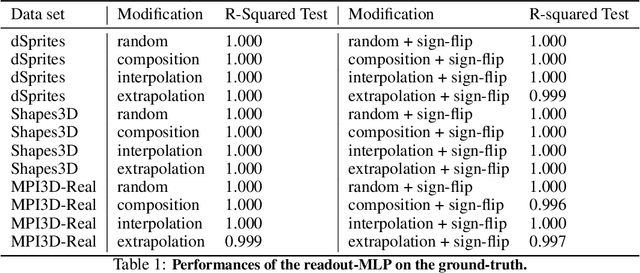



An important component for generalization in machine learning is to uncover underlying latent factors of variation as well as the mechanism through which each factor acts in the world. In this paper, we test whether 17 unsupervised, weakly supervised, and fully supervised representation learning approaches correctly infer the generative factors of variation in simple datasets (dSprites, Shapes3D, MPI3D). In contrast to prior robustness work that introduces novel factors of variation during test time, such as blur or other (un)structured noise, we here recompose, interpolate, or extrapolate only existing factors of variation from the training data set (e.g., small and medium-sized objects during training and large objects during testing). Models that learn the correct mechanism should be able to generalize to this benchmark. In total, we train and test 2000+ models and observe that all of them struggle to learn the underlying mechanism regardless of supervision signal and architectural bias. Moreover, the generalization capabilities of all tested models drop significantly as we move from artificial datasets towards more realistic real-world datasets. Despite their inability to identify the correct mechanism, the models are quite modular as their ability to infer other in-distribution factors remains fairly stable, providing only a single factor is out-of-distribution. These results point to an important yet understudied problem of learning mechanistic models of observations that can facilitate generalization.
CRIL: Continual Robot Imitation Learning via Generative and Prediction Model
Jun 17, 2021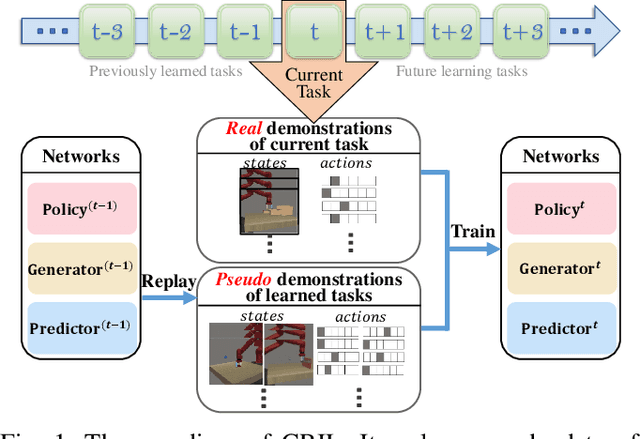
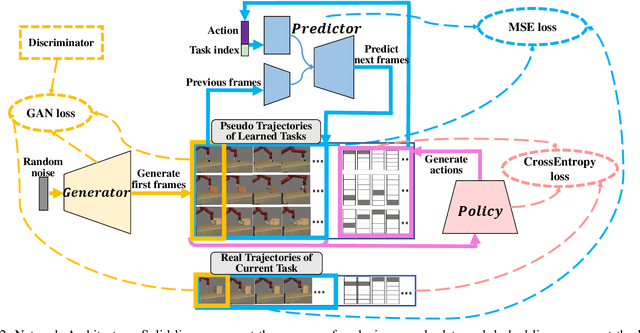
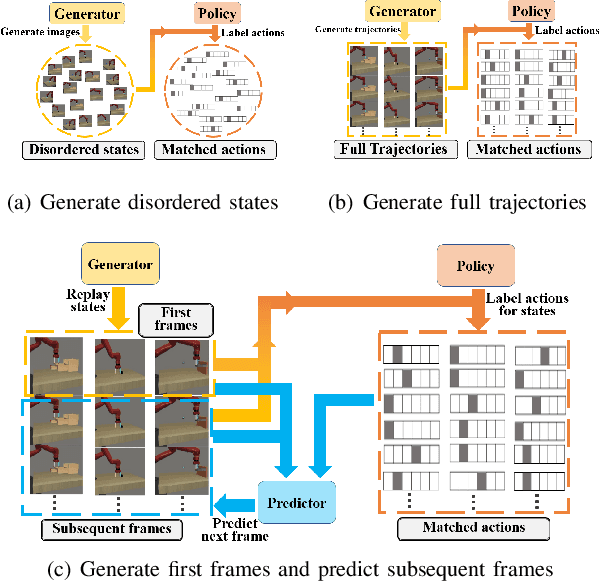

Imitation learning (IL) algorithms have shown promising results for robots to learn skills from expert demonstrations. However, for versatile robots nowadays that need to learn diverse tasks, providing and learning the multi-task demonstrations all at once are both difficult. To solve this problem, in this work we study how to realize continual imitation learning ability that empowers robots to continually learn new tasks one by one, thus reducing the burden of multi-task IL and accelerating the process of new task learning at the same time. We propose a novel trajectory generation model that employs both a generative adversarial network and a dynamics prediction model to generate pseudo trajectories from all learned tasks in the new task learning process to achieve continual imitation learning ability. Our experiments on both simulation and real world manipulation tasks demonstrate the effectiveness of our method.
Multi-step Time Series Forecasting Using Ridge Polynomial Neural Network with Error-Output Feedbacks
Nov 28, 2018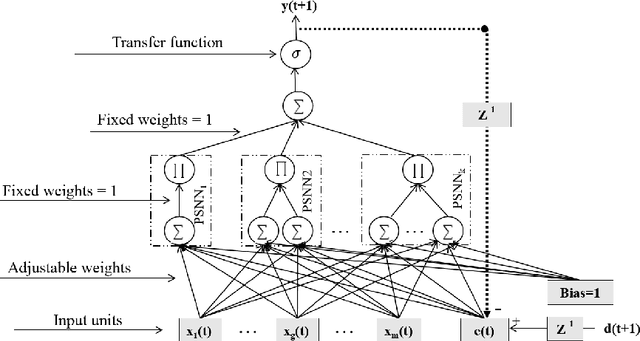
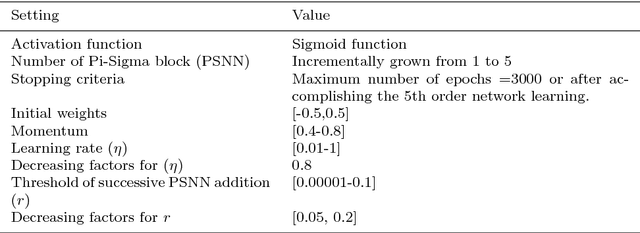
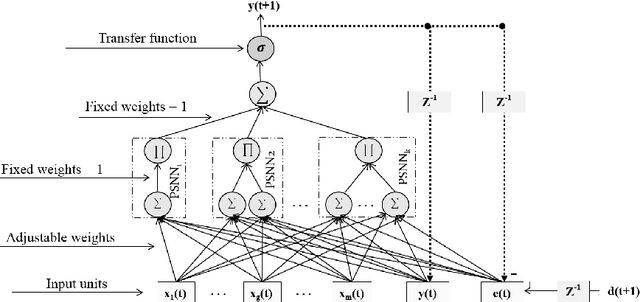

Time series forecasting gets much attention due to its impact on many practical applications. Higher-order neural network with recurrent feedback is a powerful technique which used successfully for forecasting. It maintains fast learning and the ability to learn the dynamics of the series over time. For that, in this paper, we propose a novel model which is called Ridge Polynomial Neural Network with Error-Output Feedbacks (RPNN-EOFs) that combines the properties of higher order and error-output feedbacks. The well-known Mackey-Glass time series is used to test the forecasting capability of RPNN-EOFS. Simulation results showed that the proposed RPNN-EOFs provides better understanding for the Mackey-Glass time series with root mean square error equal to 0.00416. This result is smaller than other models in the literature. Therefore, we can conclude that the RPNN-EOFs can be applied successfully for time series forecasting.
The Multi-Temporal Urban Development SpaceNet Dataset
Feb 08, 2021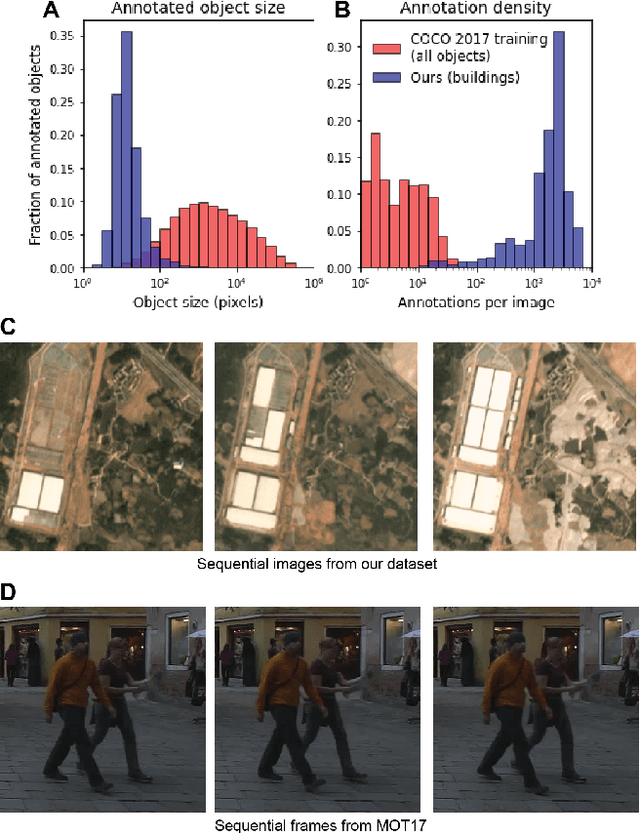
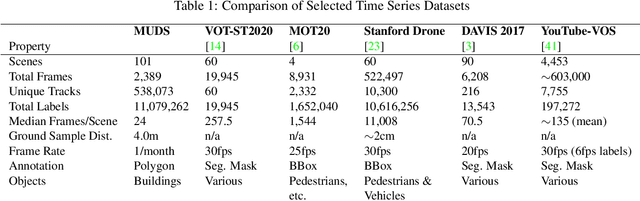
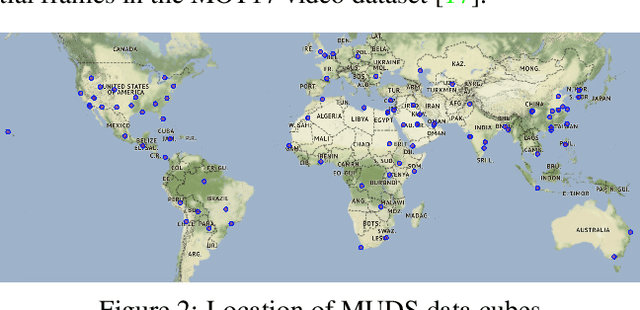

Satellite imagery analytics have numerous human development and disaster response applications, particularly when time series methods are involved. For example, quantifying population statistics is fundamental to 67 of the 231 United Nations Sustainable Development Goals Indicators, but the World Bank estimates that over 100 countries currently lack effective Civil Registration systems. To help address this deficit and develop novel computer vision methods for time series data, we present the Multi-Temporal Urban Development SpaceNet (MUDS, also known as SpaceNet 7) dataset. This open source dataset consists of medium resolution (4.0m) satellite imagery mosaics, which includes 24 images (one per month) covering >100 unique geographies, and comprises >40,000 km2 of imagery and exhaustive polygon labels of building footprints therein, totaling over 11M individual annotations. Each building is assigned a unique identifier (i.e. address), which permits tracking of individual objects over time. Label fidelity exceeds image resolution; this "omniscient labeling" is a unique feature of the dataset, and enables surprisingly precise algorithmic models to be crafted. We demonstrate methods to track building footprint construction (or demolition) over time, thereby directly assessing urbanization. Performance is measured with the newly developed SpaceNet Change and Object Tracking (SCOT) metric, which quantifies both object tracking as well as change detection. We demonstrate that despite the moderate resolution of the data, we are able to track individual building identifiers over time. This task has broad implications for disaster preparedness, the environment, infrastructure development, and epidemic prevention.
Identifiability of AMP chain graph models
Jun 17, 2021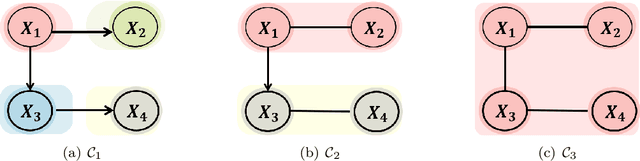
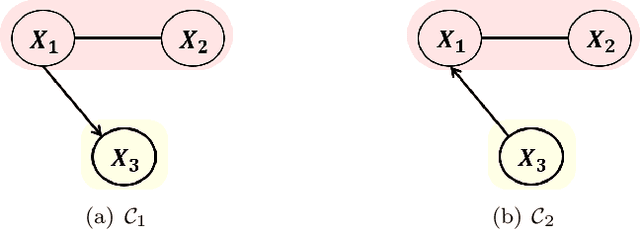
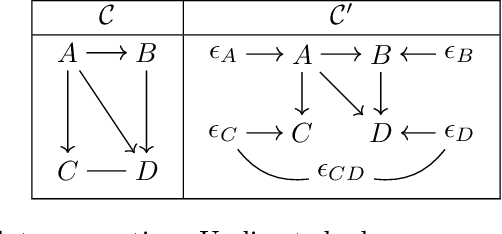
We study identifiability of Andersson-Madigan-Perlman (AMP) chain graph models, which are a common generalization of linear structural equation models and Gaussian graphical models. AMP models are described by DAGs on chain components which themselves are undirected graphs. For a known chain component decomposition, we show that the DAG on the chain components is identifiable if the determinants of the residual covariance matrices of the chain components are monotone non-decreasing in topological order. This condition extends the equal variance identifiability criterion for Bayes nets, and it can be generalized from determinants to any super-additive function on positive semidefinite matrices. When the component decomposition is unknown, we describe conditions that allow recovery of the full structure using a polynomial time algorithm based on submodular function minimization. We also conduct experiments comparing our algorithm's performance against existing baselines.
AOSLO-net: A deep learning-based method for automatic segmentation of retinal microaneurysms from adaptive optics scanning laser ophthalmoscope images
Jun 25, 2021

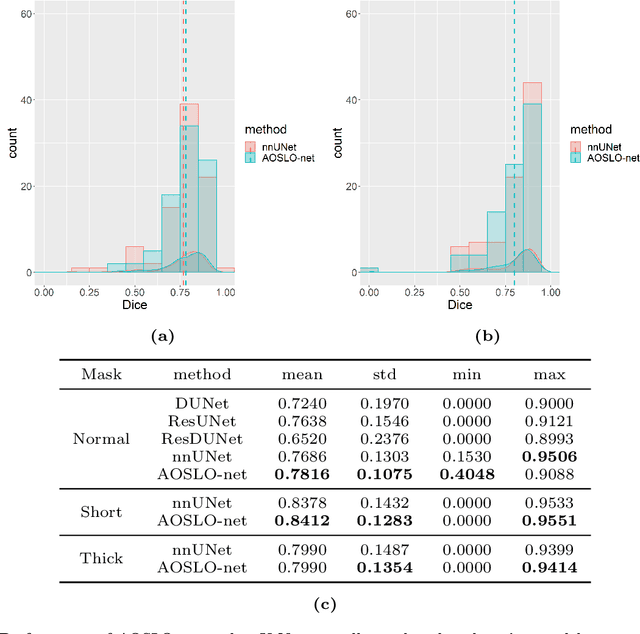
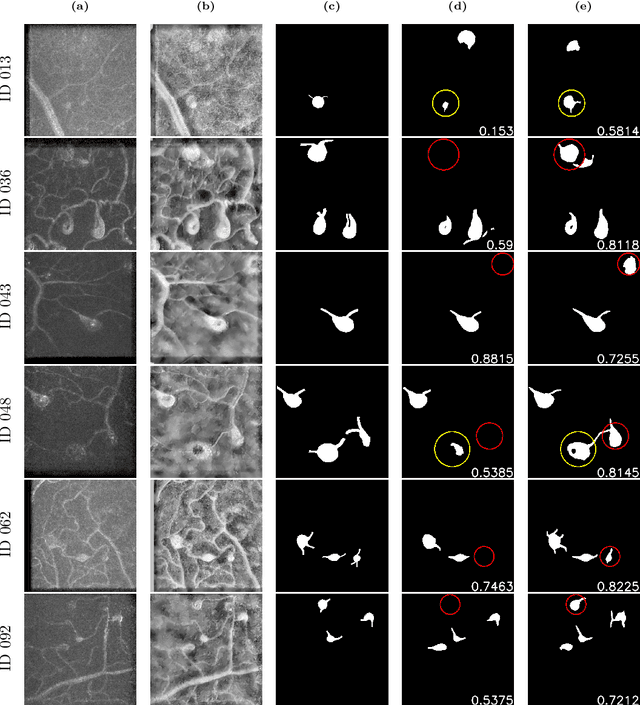
Microaneurysms (MAs) are one of the earliest signs of diabetic retinopathy (DR), a frequent complication of diabetes that can lead to visual impairment and blindness. Adaptive optics scanning laser ophthalmoscopy (AOSLO) provides real-time retinal images with resolution down to 2 $\mu m$ and thus allows detection of the morphologies of individual MAs, a potential marker that might dictate MA pathology and affect the progression of DR. In contrast to the numerous automatic models developed for assessing the number of MAs on fundus photographs, currently there is no high throughput image protocol available for automatic analysis of AOSLO photographs. To address this urgency, we introduce AOSLO-net, a deep neural network framework with customized training policies to automatically segment MAs from AOSLO images. We evaluate the performance of AOSLO-net using 87 DR AOSLO images and our results demonstrate that the proposed model outperforms the state-of-the-art segmentation model both in accuracy and cost and enables correct MA morphological classification.
Basic principles and concept design of a real-time clinical decision support system for autonomous medical care on missions to Mars based on adaptive deep learning
Sep 29, 2020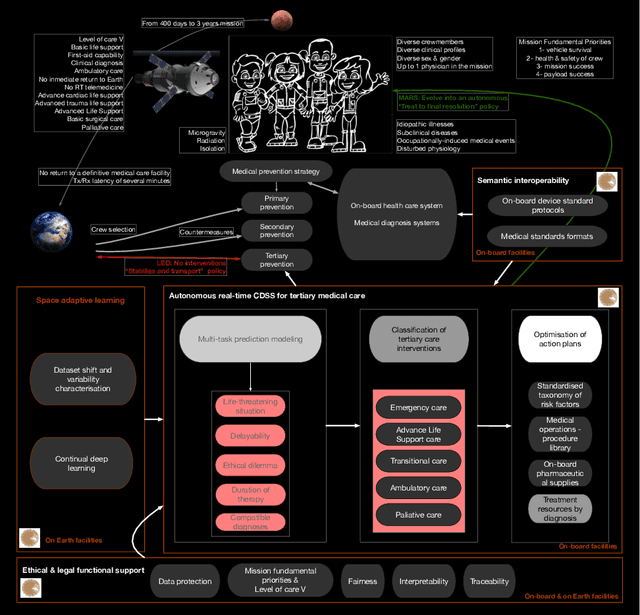
Space agencies and private companies prepare the beginning of the human space exploration for the 2030s with missions to put the first human on the Mars surface. The absence of gravity and radiation, along with distance, isolation and hostile environment are expected to increase medical events with unidentified manifestations along the crewmembers. The current healthcare strategy based on telemedicine and the possibility to stabilise and transport the injured crewmember to a terrestrial definitive medical facility is not applicable in exploration class missions. Therefore, full autonomous capability to solve medical situations will guide design of future healthcare systems on-board. This study presents ten basic principles and the concept design of MEDEA, an on-board clinical decision support system to help crewmembers to deal with medical conditions, with special attention to emergency care situations and critical monitoring. Therefore, MEDEA is conceptually designed as a software suite of four interconnected modules. The main of them is responsible to give direct advice to the crew by means of a deep learning multitask neural network to predict the characters of the medical event, a classifier of the tertiary medical intervention and an optimiser of medical action plans. This module is continuously evaluate and re-trained with changing physiological data from the crew by an adaptive deep learning module, ensuring fairness, interpretability and traceability of decision making during the full operational time of MEDEA. Finally, MEDEA would be semantically interoperable with health information systems on-board by a FHIR module. The deployment of MEDEA on-board of future missions to Mars will facilitate the deployment of a comprehensive preventive medical strategy, future quantitative medicine on Earth and on the expansion of humans throughout the solar system.