 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Guards the Guardians? The Challenges of Evaluating Identifiability of Learned Representations
Feb 27, 2026Identifiability in representation learning is commonly evaluated using standard metrics (e.g., MCC, DCI, R^2) on synthetic benchmarks with known ground-truth factors. These metrics are assumed to reflect recovery up to the equivalence class guaranteed by identifiability theory. We show that this assumption holds only under specific structural conditions: each metric implicitly encodes assumptions about both the data-generating process (DGP) and the encoder. When these assumptions are violated, metrics become misspecified and can produce systematic false positives and false negatives. Such failures occur both within classical identifiability regimes and in post-hoc settings where identifiability is most needed. We introduce a taxonomy separating DGP assumptions from encoder geometry, use it to characterise the validity domains of existing metrics, and release an evaluation suite for reproducible stress testing and comparison.
Causality is Key for Interpretability Claims to Generalise
Feb 18, 2026Interpretability research on large language models (LLMs) has yielded important insights into model behaviour, yet recurring pitfalls persist: findings that do not generalise, and causal interpretations that outrun the evidence. Our position is that causal inference specifies what constitutes a valid mapping from model activations to invariant high-level structures, the data or assumptions needed to achieve it, and the inferences it can support. Specifically, Pearl's causal hierarchy clarifies what an interpretability study can justify. Observations establish associations between model behaviour and internal components. Interventions (e.g., ablations or activation patching) support claims how these edits affect a behavioural metric (\eg, average change in token probabilities) over a set of prompts. However, counterfactual claims -- i.e., asking what the model output would have been for the same prompt under an unobserved intervention -- remain largely unverifiable without controlled supervision. We show how causal representation learning (CRL) operationalises this hierarchy, specifying which variables are recoverable from activations and under what assumptions. Together, these motivate a diagnostic framework that helps practitioners select methods and evaluations matching claims to evidence such that findings generalise.
Low-Pass Filtering Improves Behavioral Alignment of Vision Models
Feb 14, 2026Despite their impressive performance on computer vision benchmarks, Deep Neural Networks (DNNs) still fall short of adequately modeling human visual behavior, as measured by error consistency and shape bias. Recent work hypothesized that behavioral alignment can be drastically improved through \emph{generative} -- rather than \emph{discriminative} -- classifiers, with far-reaching implications for models of human vision. Here, we instead show that the increased alignment of generative models can be largely explained by a seemingly innocuous resizing operation in the generative model which effectively acts as a low-pass filter. In a series of controlled experiments, we show that removing high-frequency spatial information from discriminative models like CLIP drastically increases their behavioral alignment. Simply blurring images at test-time -- rather than training on blurred images -- achieves a new state-of-the-art score on the model-vs-human benchmark, halving the current alignment gap between DNNs and human observers. Furthermore, low-pass filters are likely optimal, which we demonstrate by directly optimizing filters for alignment. To contextualize the performance of optimal filters, we compute the frontier of all possible pareto-optimal solutions to the benchmark, which was formerly unknown. We explain our findings by observing that the frequency spectrum of optimal Gaussian filters roughly matches the spectrum of band-pass filters implemented by the human visual system. We show that the contrast sensitivity function, describing the inverse of the contrast threshold required for humans to detect a sinusoidal grating as a function of spatiotemporal frequency, is approximated well by Gaussian filters of the specific width that also maximizes error consistency.
MentisOculi: Revealing the Limits of Reasoning with Mental Imagery
Feb 02, 2026Frontier models are transitioning from multimodal large language models (MLLMs) that merely ingest visual information to unified multimodal models (UMMs) capable of native interleaved generation. This shift has sparked interest in using intermediate visualizations as a reasoning aid, akin to human mental imagery. Central to this idea is the ability to form, maintain, and manipulate visual representations in a goal-oriented manner. To evaluate and probe this capability, we develop MentisOculi, a procedural, stratified suite of multi-step reasoning problems amenable to visual solution, tuned to challenge frontier models. Evaluating visual strategies ranging from latent tokens to explicit generated imagery, we find they generally fail to improve performance. Analysis of UMMs specifically exposes a critical limitation: While they possess the textual reasoning capacity to solve a task and can sometimes generate correct visuals, they suffer from compounding generation errors and fail to leverage even ground-truth visualizations. Our findings suggest that despite their inherent appeal, visual thoughts do not yet benefit model reasoning. MentisOculi establishes the necessary foundation to analyze and close this gap across diverse model families.
Generation is Required for Data-Efficient Perception
Dec 17, 2025



It has been hypothesized that human-level visual perception requires a generative approach in which internal representations result from inverting a decoder. Yet today's most successful vision models are non-generative, relying on an encoder that maps images to representations without decoder inversion. This raises the question of whether generation is, in fact, necessary for machines to achieve human-level visual perception. To address this, we study whether generative and non-generative methods can achieve compositional generalization, a hallmark of human perception. Under a compositional data generating process, we formalize the inductive biases required to guarantee compositional generalization in decoder-based (generative) and encoder-based (non-generative) methods. We then show theoretically that enforcing these inductive biases on encoders is generally infeasible using regularization or architectural constraints. In contrast, for generative methods, the inductive biases can be enforced straightforwardly, thereby enabling compositional generalization by constraining a decoder and inverting it. We highlight how this inversion can be performed efficiently, either online through gradient-based search or offline through generative replay. We examine the empirical implications of our theory by training a range of generative and non-generative methods on photorealistic image datasets. We find that, without the necessary inductive biases, non-generative methods often fail to generalize compositionally and require large-scale pretraining or added supervision to improve generalization. By comparison, generative methods yield significant improvements in compositional generalization, without requiring additional data, by leveraging suitable inductive biases on a decoder along with search and replay.
VGGSounder: Audio-Visual Evaluations for Foundation Models
Aug 12, 2025The emergence of audio-visual foundation models underscores the importance of reliably assessing their multi-modal understanding. The VGGSound dataset is commonly used as a benchmark for evaluation audio-visual classification. However, our analysis identifies several limitations of VGGSound, including incomplete labelling, partially overlapping classes, and misaligned modalities. These lead to distorted evaluations of auditory and visual capabilities. To address these limitations, we introduce VGGSounder, a comprehensively re-annotated, multi-label test set that extends VGGSound and is specifically designed to evaluate audio-visual foundation models. VGGSounder features detailed modality annotations, enabling precise analyses of modality-specific performance. Furthermore, we reveal model limitations by analysing performance degradation when adding another input modality with our new modality confusion metric.
Estimating Treatment Effects with Independent Component Analysis
Jul 22, 2025The field of causal inference has developed a variety of methods to accurately estimate treatment effects in the presence of nuisance. Meanwhile, the field of identifiability theory has developed methods like Independent Component Analysis (ICA) to identify latent sources and mixing weights from data. While these two research communities have developed largely independently, they aim to achieve similar goals: the accurate and sample-efficient estimation of model parameters. In the partially linear regression (PLR) setting, Mackey et al. (2018) recently found that estimation consistency can be improved with non-Gaussian treatment noise. Non-Gaussianity is also a crucial assumption for identifying latent factors in ICA. We provide the first theoretical and empirical insights into this connection, showing that ICA can be used for causal effect estimation in the PLR model. Surprisingly, we find that linear ICA can accurately estimate multiple treatment effects even in the presence of Gaussian confounders or nonlinear nuisance.
An Empirically Grounded Identifiability Theory Will Accelerate Self-Supervised Learning Research
Apr 17, 2025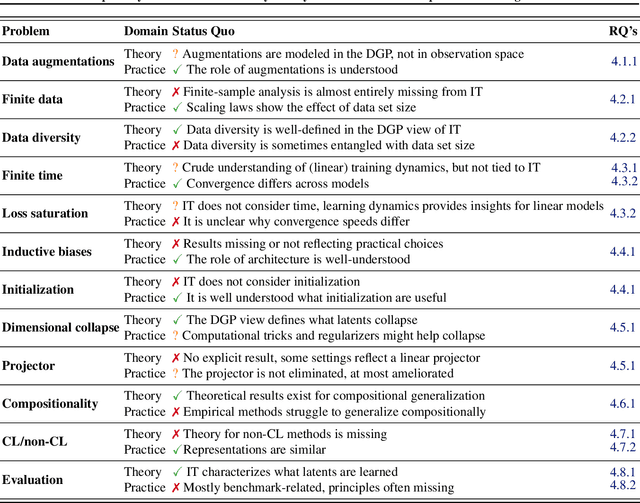
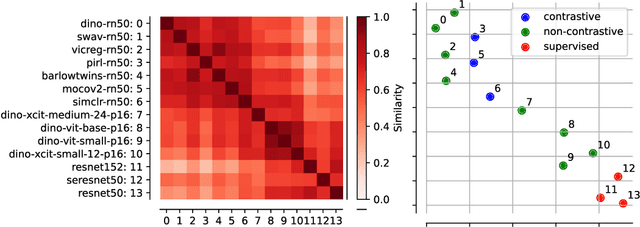
Self-Supervised Learning (SSL) powers many current AI systems. As research interest and investment grow, the SSL design space continues to expand. The Platonic view of SSL, following the Platonic Representation Hypothesis (PRH), suggests that despite different methods and engineering approaches, all representations converge to the same Platonic ideal. However, this phenomenon lacks precise theoretical explanation. By synthesizing evidence from Identifiability Theory (IT), we show that the PRH can emerge in SSL. However, current IT cannot explain SSL's empirical success. To bridge the gap between theory and practice, we propose expanding IT into what we term Singular Identifiability Theory (SITh), a broader theoretical framework encompassing the entire SSL pipeline. SITh would allow deeper insights into the implicit data assumptions in SSL and advance the field towards learning more interpretable and generalizable representations. We highlight three critical directions for future research: 1) training dynamics and convergence properties of SSL; 2) the impact of finite samples, batch size, and data diversity; and 3) the role of inductive biases in architecture, augmentations, initialization schemes, and optimizers.
LLMs on the Line: Data Determines Loss-to-Loss Scaling Laws
Feb 17, 2025Scaling laws guide the development of large language models (LLMs) by offering estimates for the optimal balance of model size, tokens, and compute. More recently, loss-to-loss scaling laws that relate losses across pretraining datasets and downstream tasks have emerged as a powerful tool for understanding and improving LLM performance. In this work, we investigate which factors most strongly influence loss-to-loss scaling. Our experiments reveal that the pretraining data and tokenizer determine the scaling trend. In contrast, model size, optimization hyperparameters, and even significant architectural differences, such as between transformer-based models like Llama and state-space models like Mamba, have limited impact. Consequently, practitioners should carefully curate suitable pretraining datasets for optimal downstream performance, while architectures and other settings can be freely optimized for training efficiency.
Interaction Asymmetry: A General Principle for Learning Composable Abstractions
Nov 12, 2024Learning disentangled representations of concepts and re-composing them in unseen ways is crucial for generalizing to out-of-domain situations. However, the underlying properties of concepts that enable such disentanglement and compositional generalization remain poorly understood. In this work, we propose the principle of interaction asymmetry which states: "Parts of the same concept have more complex interactions than parts of different concepts". We formalize this via block diagonality conditions on the $(n+1)$th order derivatives of the generator mapping concepts to observed data, where different orders of "complexity" correspond to different $n$. Using this formalism, we prove that interaction asymmetry enables both disentanglement and compositional generalization. Our results unify recent theoretical results for learning concepts of objects, which we show are recovered as special cases with $n\!=\!0$ or $1$. We provide results for up to $n\!=\!2$, thus extending these prior works to more flexible generator functions, and conjecture that the same proof strategies generalize to larger $n$. Practically, our theory suggests that, to disentangle concepts, an autoencoder should penalize its latent capacity and the interactions between concepts during decoding. We propose an implementation of these criteria using a flexible Transformer-based VAE, with a novel regularizer on the attention weights of the decoder. On synthetic image datasets consisting of objects, we provide evidence that this model can achieve comparable object disentanglement to existing models that use more explicit object-centric priors.