 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Combining Context Awareness and Planning to Learn Behavior Trees from Demonstration
Sep 15, 2021
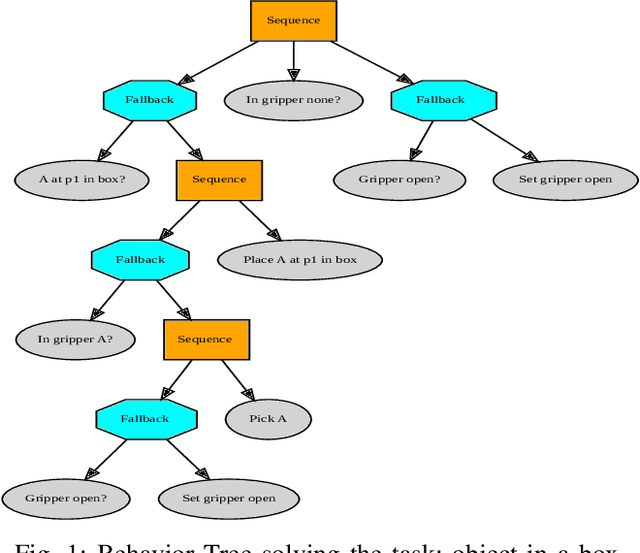
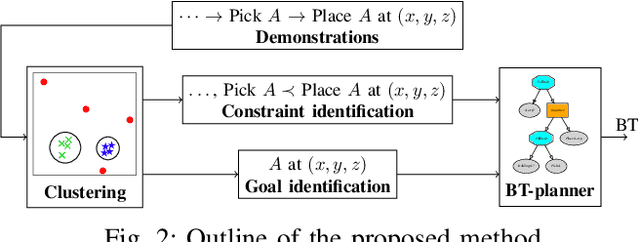
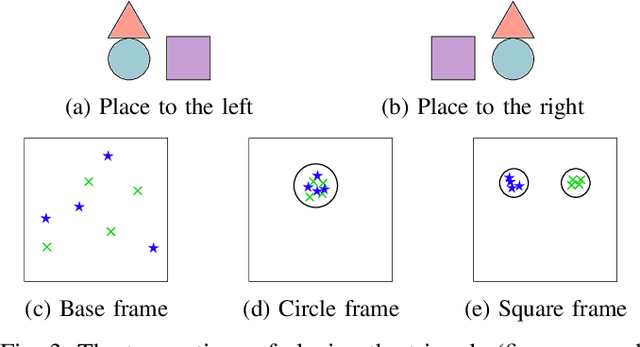

Fast changing tasks in unpredictable, collaborative environments are typical for medium-small companies, where robotised applications are increasing. Thus, robot programs should be generated in short time with small effort, and the robot able to react dynamically to the environment. To address this we propose a method that combines context awareness and planning to learn Behavior Trees (BTs), a reactive policy representation that is becoming more popular in robotics and has been used successfully in many collaborative scenarios. Context awareness allows to infer from the demonstration the frames in which actions are executed and to capture relevant aspects of the task, while a planner is used to automatically generate the BT from the sequence of actions from the demonstration. The learned BT is shown to solve non-trivial manipulation tasks where learning the context is fundamental to achieve the goal. Moreover, we collected non-expert demonstrations to study the performances of the algorithm in industrial scenarios.
Cross-Region Building Counting in Satellite Imagery using Counting Consistency
Oct 26, 2021
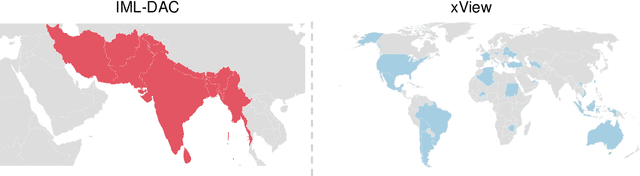
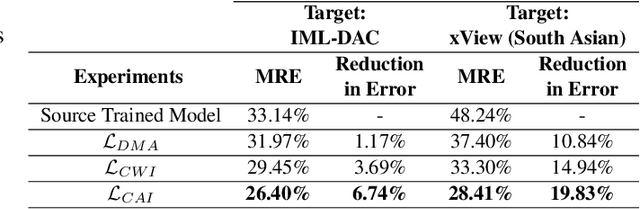
Estimating the number of buildings in any geographical region is a vital component of urban analysis, disaster management, and public policy decision. Deep learning methods for building localization and counting in satellite imagery, can serve as a viable and cheap alternative. However, these algorithms suffer performance degradation when applied to the regions on which they have not been trained. Current large datasets mostly cover the developed regions and collecting such datasets for every region is a costly, time-consuming, and difficult endeavor. In this paper, we propose an unsupervised domain adaptation method for counting buildings where we use a labeled source domain (developed regions) and adapt the trained model on an unlabeled target domain (developing regions). We initially align distribution maps across domains by aligning the output space distribution through adversarial loss. We then exploit counting consistency constraints, within-image count consistency, and across-image count consistency, to decrease the domain shift. Within-image consistency enforces that building count in the whole image should be greater than or equal to count in any of its sub-image. Across-image consistency constraint enforces that if an image contains considerably more buildings than the other image, then their sub-images shall also have the same order. These two constraints encourage the behavior to be consistent across and within the images, regardless of the scale. To evaluate the performance of our proposed approach, we collected and annotated a large-scale dataset consisting of challenging South Asian regions having higher building densities and irregular structures as compared to existing datasets. We perform extensive experiments to verify the efficacy of our approach and report improvements of approximately 7% to 20% over the competitive baseline methods.
Improving Generalization in Mountain Car Through the Partitioned Parameterized Policy Approach via Quasi-Stochastic Gradient Descent
May 28, 2021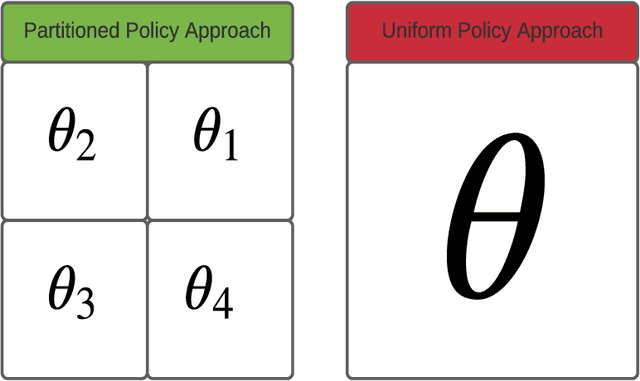
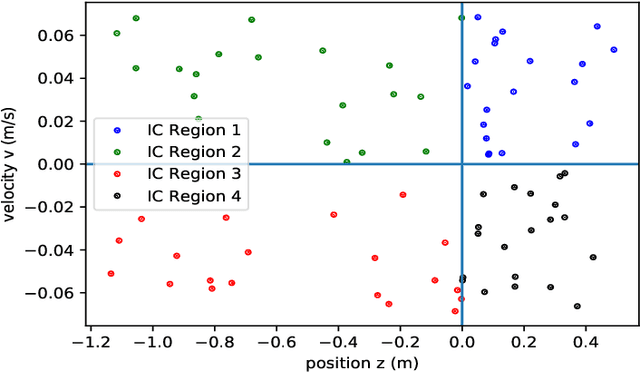
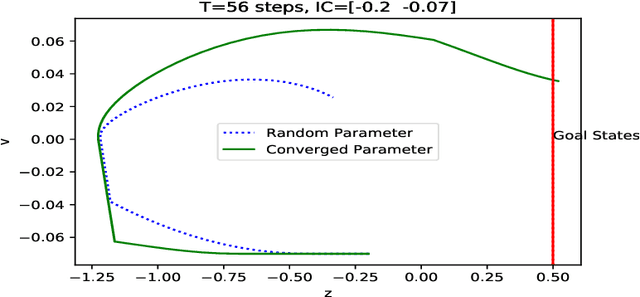
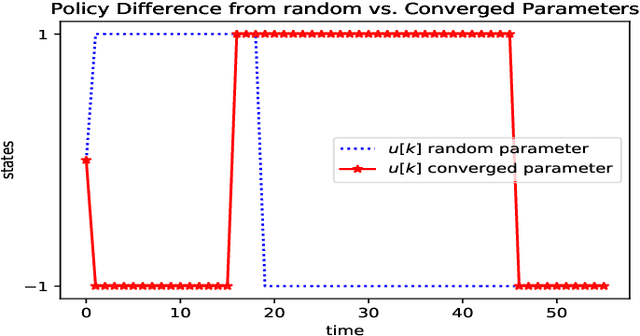
The reinforcement learning problem of finding a control policy that minimizes the minimum time objective for the Mountain Car environment is considered. Particularly, a class of parameterized nonlinear feedback policies is optimized over to reach the top of the highest mountain peak in minimum time. The optimization is carried out using quasi-Stochastic Gradient Descent (qSGD) methods. In attempting to find the optimal minimum time policy, a new parameterized policy approach is considered that seeks to learn an optimal policy parameter for different regions of the state space, rather than rely on a single macroscopic policy parameter for the entire state space. This partitioned parameterized policy approach is shown to outperform the uniform parameterized policy approach and lead to greater generalization than prior methods, where the Mountain Car became trapped in circular trajectories in the state space.
Intensity Prediction of Tropical Cyclones using Long Short-Term Memory Network
Jul 07, 2021
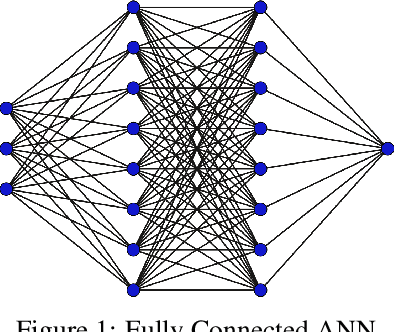
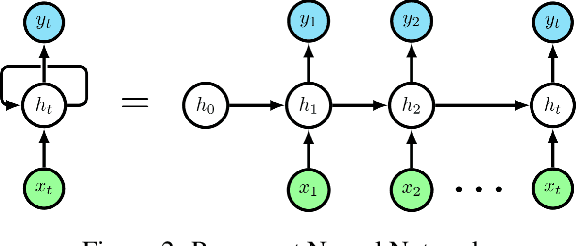
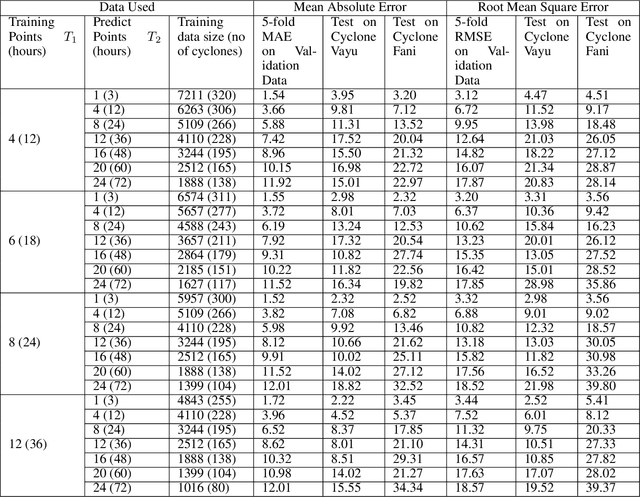
Tropical cyclones can be of varied intensity and cause a huge loss of lives and property if the intensity is high enough. Therefore, the prediction of the intensity of tropical cyclones advance in time is of utmost importance. We propose a novel stacked bidirectional long short-term memory network (BiLSTM) based model architecture to predict the intensity of a tropical cyclone in terms of Maximum surface sustained wind speed (MSWS). The proposed model can predict MSWS well advance in time (up to 72 h) with very high accuracy. We have applied the model on tropical cyclones in the North Indian Ocean from 1982 to 2018 and checked its performance on two recent tropical cyclones, namely, Fani and Vayu. The model predicts MSWS (in knots) for the next 3, 12, 24, 36, 48, 60, and 72 hours with a mean absolute error of 1.52, 3.66, 5.88, 7.42, 8.96, 10.15, and 11.92, respectively.
Real-Time, Environmentally-Robust 3D LiDAR Localization
Oct 28, 2019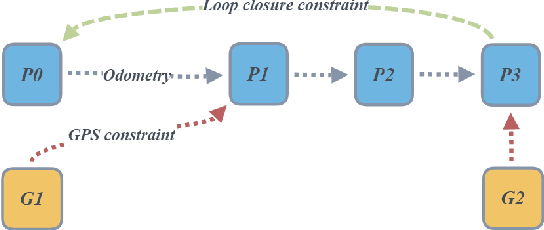
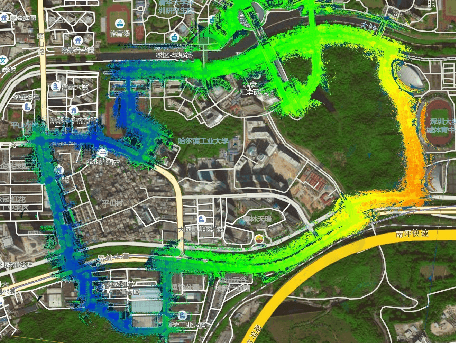

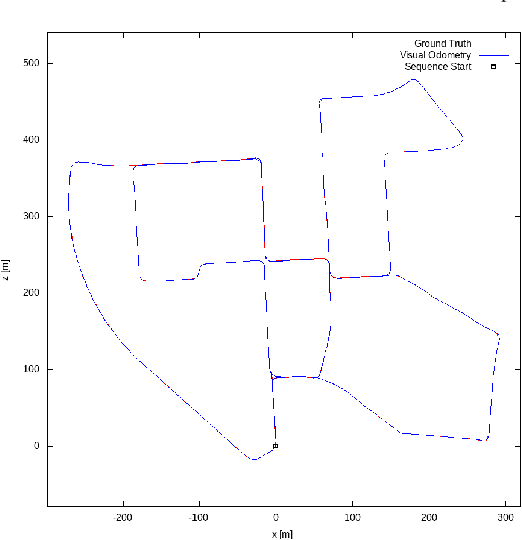
Localization, or position fixing, is an important problem in robotics research. In this paper, we propose a novel approach for long-term localization in a changing environment using 3D LiDAR. We first create the map of a real environment using GPS and LiDAR. Then, we divide the map into several small parts as the targets for cloud registration, which can not only improve the robustness but also reduce the registration time. PointLocalization allows us to fuse different kinds of odometers, which can optimize the accuracy and frequency of localization results. We evaluate our algorithm on an unmanned ground vehicle (UGV) using LiDAR and a wheel encoder, and obtain the localization results at more than 20 Hz after fusion. The algorithm can also localize the UGV in a 180-degree field of view (FOV). Using an outdated map captured six months ago, this algorithm shows great robustness, and the test results show that it can achieve an accuracy of 10 cm. PointLocalization has been tested for a period of more than six months in a crowded factory and has operated successfully over a distance of more than 2000 km.
A Novel Clustering-Based Algorithm for Continuous and Non-invasive Cuff-Less Blood Pressure Estimation
Oct 13, 2021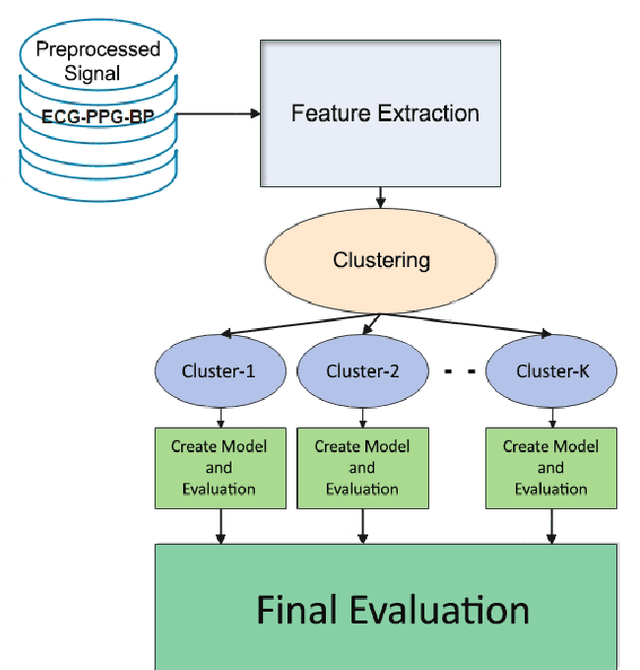
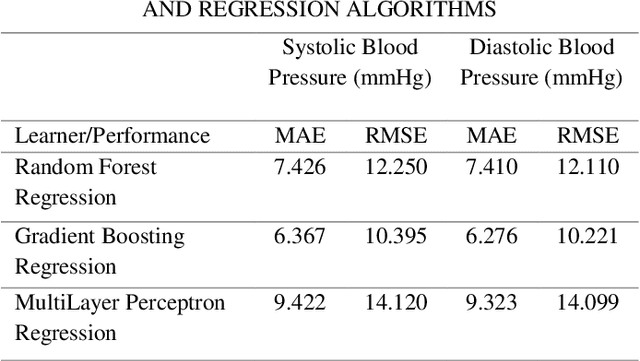
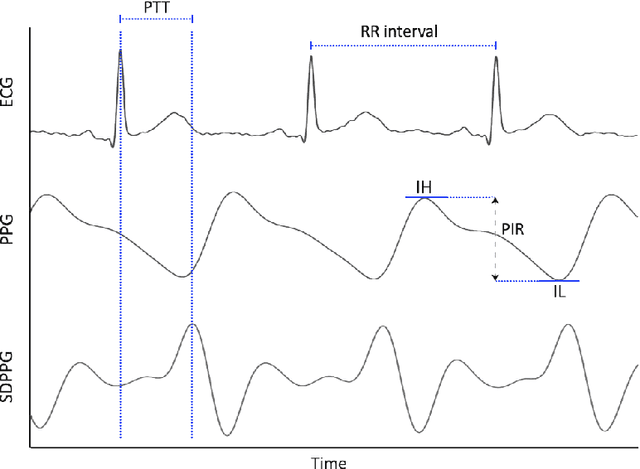
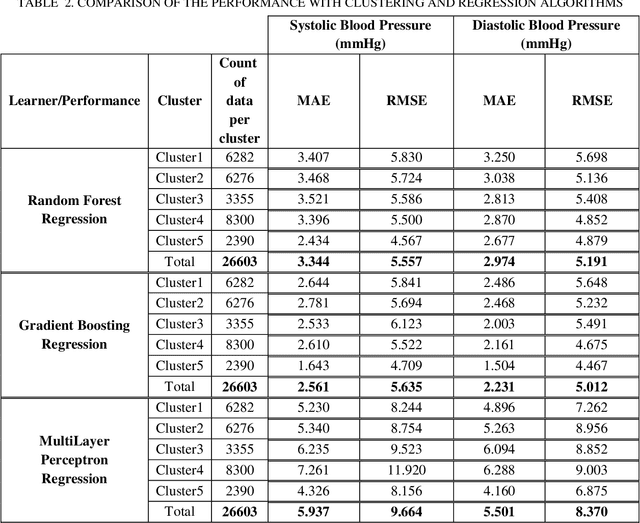
Continuous blood pressure (BP) measurements can reflect a bodys response to diseases and serve as a predictor of cardiovascular and other health conditions. While current cuff-based BP measurement methods are incapable of providing continuous BP readings, invasive BP monitoring methods also tend to cause patient dissatisfaction and can potentially cause infection. In this research, we developed a method for estimating blood pressure based on the features extracted from Electrocardiogram (ECG) and Photoplethysmogram (PPG) signals and the Arterial Blood Pressure (ABP) data. The vector of features extracted from the preprocessed ECG and PPG signals is used in this approach, which include Pulse Transit Time (PTT), PPG Intensity Ratio (PIR), and Heart Rate (HR), as the input of a clustering algorithm and then developing separate regression models like Random Forest Regression, Gradient Boosting Regression, and Multilayer Perceptron Regression algorithms for each resulting cluster. We evaluated and compared the findings to create the model with the highest accuracy by applying the clustering approach and identifying the optimal number of clusters, and eventually the acceptable prediction model. The paper compares the results obtained with and without this clustering. The results show that the proposed clustering approach helps obtain more accurate estimates of Systolic Blood Pressure (SBP) and Diastolic Blood Pressure (DBP). Given the inconsistency, high dispersion, and multitude of trends in the datasets for different features, using the clustering approach improved the estimation accuracy by 50-60%.
UniCon: Unified Context Network for Robust Active Speaker Detection
Aug 05, 2021
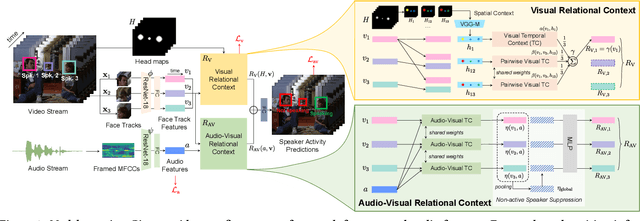
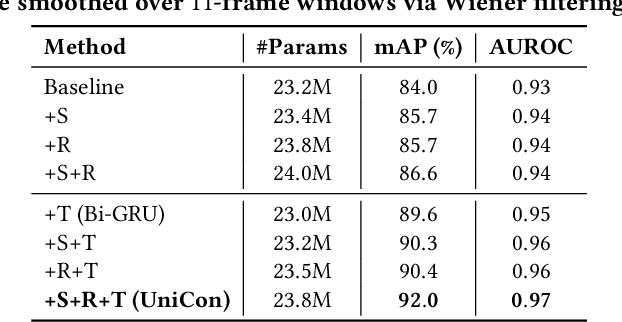

We introduce a new efficient framework, the Unified Context Network (UniCon), for robust active speaker detection (ASD). Traditional methods for ASD usually operate on each candidate's pre-cropped face track separately and do not sufficiently consider the relationships among the candidates. This potentially limits performance, especially in challenging scenarios with low-resolution faces, multiple candidates, etc. Our solution is a novel, unified framework that focuses on jointly modeling multiple types of contextual information: spatial context to indicate the position and scale of each candidate's face, relational context to capture the visual relationships among the candidates and contrast audio-visual affinities with each other, and temporal context to aggregate long-term information and smooth out local uncertainties. Based on such information, our model optimizes all candidates in a unified process for robust and reliable ASD. A thorough ablation study is performed on several challenging ASD benchmarks under different settings. In particular, our method outperforms the state-of-the-art by a large margin of about 15% mean Average Precision (mAP) absolute on two challenging subsets: one with three candidate speakers, and the other with faces smaller than 64 pixels. Together, our UniCon achieves 92.0% mAP on the AVA-ActiveSpeaker validation set, surpassing 90% for the first time on this challenging dataset at the time of submission. Project website: https://unicon-asd.github.io/.
Towards More Generalizable One-shot Visual Imitation Learning
Oct 26, 2021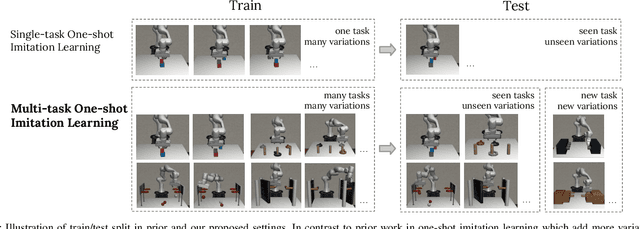

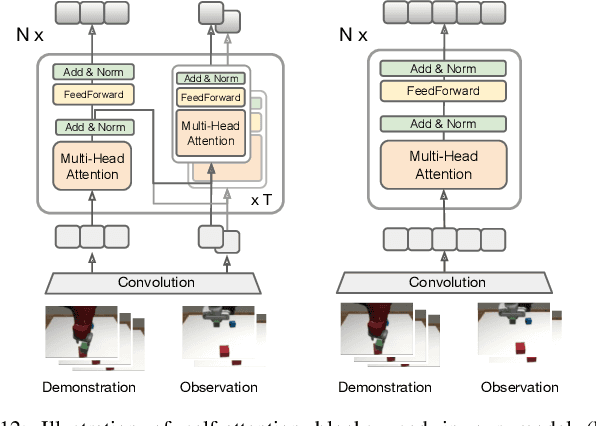
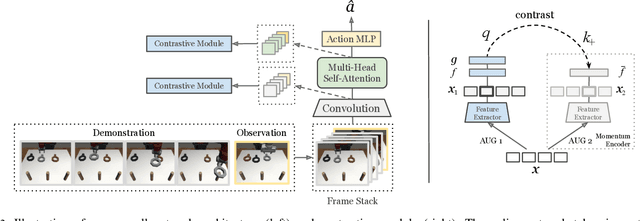
A general-purpose robot should be able to master a wide range of tasks and quickly learn a novel one by leveraging past experiences. One-shot imitation learning (OSIL) approaches this goal by training an agent with (pairs of) expert demonstrations, such that at test time, it can directly execute a new task from just one demonstration. However, so far this framework has been limited to training on many variations of one task, and testing on other unseen but similar variations of the same task. In this work, we push for a higher level of generalization ability by investigating a more ambitious multi-task setup. We introduce a diverse suite of vision-based robot manipulation tasks, consisting of 7 tasks, a total of 61 variations, and a continuum of instances within each variation. For consistency and comparison purposes, we first train and evaluate single-task agents (as done in prior few-shot imitation work). We then study the multi-task setting, where multi-task training is followed by (i) one-shot imitation on variations within the training tasks, (ii) one-shot imitation on new tasks, and (iii) fine-tuning on new tasks. Prior state-of-the-art, while performing well within some single tasks, struggles in these harder multi-task settings. To address these limitations, we propose MOSAIC (Multi-task One-Shot Imitation with self-Attention and Contrastive learning), which integrates a self-attention model architecture and a temporal contrastive module to enable better task disambiguation and more robust representation learning. Our experiments show that MOSAIC outperforms prior state of the art in learning efficiency, final performance, and learns a multi-task policy with promising generalization ability via fine-tuning on novel tasks.
SubTab: Subsetting Features of Tabular Data for Self-Supervised Representation Learning
Oct 08, 2021
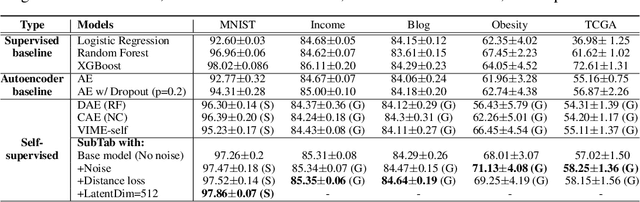
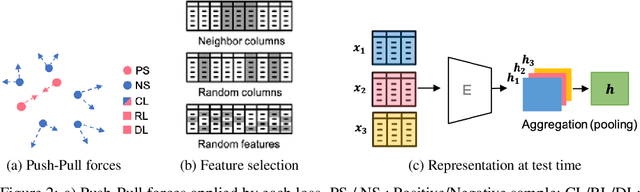
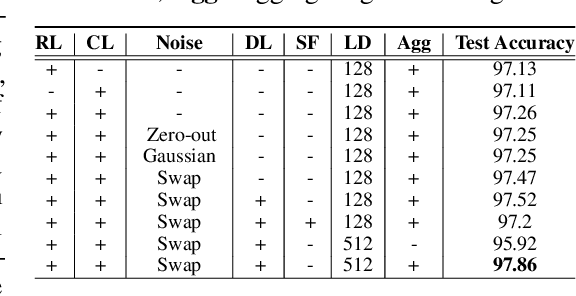
Self-supervised learning has been shown to be very effective in learning useful representations, and yet much of the success is achieved in data types such as images, audio, and text. The success is mainly enabled by taking advantage of spatial, temporal, or semantic structure in the data through augmentation. However, such structure may not exist in tabular datasets commonly used in fields such as healthcare, making it difficult to design an effective augmentation method, and hindering a similar progress in tabular data setting. In this paper, we introduce a new framework, Subsetting features of Tabular data (SubTab), that turns the task of learning from tabular data into a multi-view representation learning problem by dividing the input features to multiple subsets. We argue that reconstructing the data from the subset of its features rather than its corrupted version in an autoencoder setting can better capture its underlying latent representation. In this framework, the joint representation can be expressed as the aggregate of latent variables of the subsets at test time, which we refer to as collaborative inference. Our experiments show that the SubTab achieves the state of the art (SOTA) performance of 98.31% on MNIST in tabular setting, on par with CNN-based SOTA models, and surpasses existing baselines on three other real-world datasets by a significant margin.
On the Cryptographic Hardness of Learning Single Periodic Neurons
Jun 20, 2021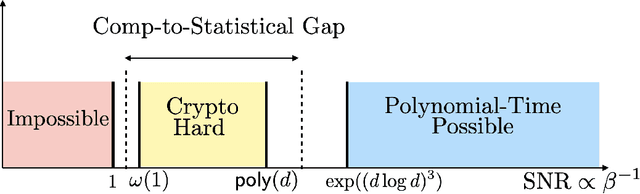
We show a simple reduction which demonstrates the cryptographic hardness of learning a single periodic neuron over isotropic Gaussian distributions in the presence of noise. More precisely, our reduction shows that any polynomial-time algorithm (not necessarily gradient-based) for learning such functions under small noise implies a polynomial-time quantum algorithm for solving worst-case lattice problems, whose hardness form the foundation of lattice-based cryptography. Our core hard family of functions, which are well-approximated by one-layer neural networks, take the general form of a univariate periodic function applied to an affine projection of the data. These functions have appeared in previous seminal works which demonstrate their hardness against gradient-based (Shamir'18), and Statistical Query (SQ) algorithms (Song et al.'17). We show that if (polynomially) small noise is added to the labels, the intractability of learning these functions applies to all polynomial-time algorithms under the aforementioned cryptographic assumptions. Moreover, we demonstrate the necessity of noise in the hardness result by designing a polynomial-time algorithm for learning certain families of such functions under exponentially small adversarial noise. Our proposed algorithm is not a gradient-based or an SQ algorithm, but is rather based on the celebrated Lenstra-Lenstra-Lov\'asz (LLL) lattice basis reduction algorithm. Furthermore, in the absence of noise, this algorithm can be directly applied to solve CLWE detection (Bruna et al.'21) and phase retrieval with an optimal sample complexity of $d+1$ samples. In the former case, this improves upon the quadratic-in-$d$ sample complexity required in (Bruna et al.'21). In the latter case, this improves upon the state-of-the-art AMP-based algorithm, which requires approximately $1.128d$ samples (Barbier et al.'19).