 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximation Methods for Partially Observed Markov Decision Processes (POMDPs)
Aug 31, 2021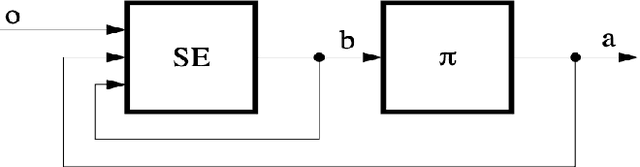
POMDPs are useful models for systems where the true underlying state is not known completely to an outside observer; the outside observer incompletely knows the true state of the system, and observes a noisy version of the true system state. When the number of system states is large in a POMDP that often necessitates the use of approximation methods to obtain near optimal solutions for control. This survey is centered around the origins, theory, and approximations of finite-state POMDPs. In order to understand POMDPs, it is required to have an understanding of finite-state Markov Decision Processes (MDPs) in \autoref{mdp} and Hidden Markov Models (HMMs) in \autoref{hmm}. For this background theory, I provide only essential details on MDPs and HMMs and leave longer expositions to textbook treatments before diving into the main topics of POMDPs. Once the required background is covered, the POMDP is introduced in \autoref{pomdp}. The origins of the POMDP are explained in the classical papers section \autoref{classical}. Once the high computational requirements are understood from the exact methodological point of view, the main approximation methods are surveyed in \autoref{approximations}. Then, I end the survey with some new research directions in \autoref{conclusion}.
Improving Generalization in Mountain Car Through the Partitioned Parameterized Policy Approach via Quasi-Stochastic Gradient Descent
May 28, 2021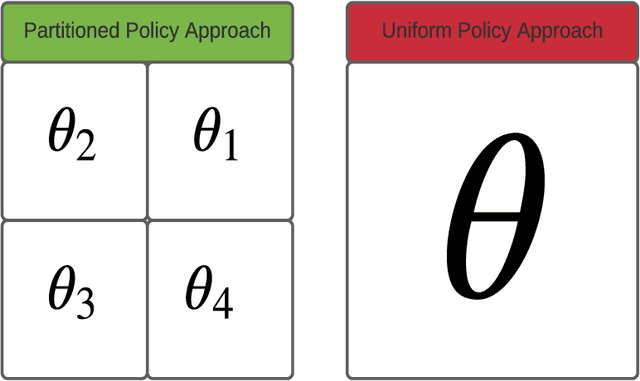
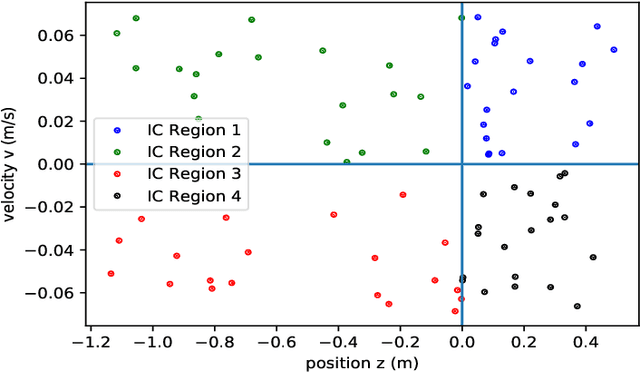
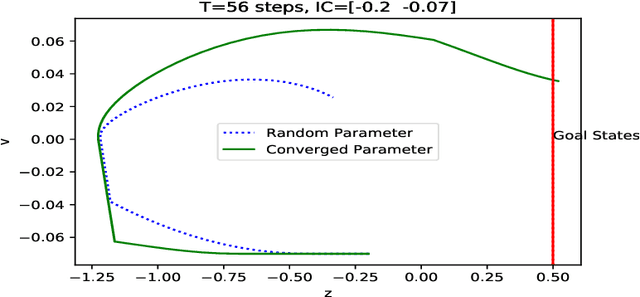
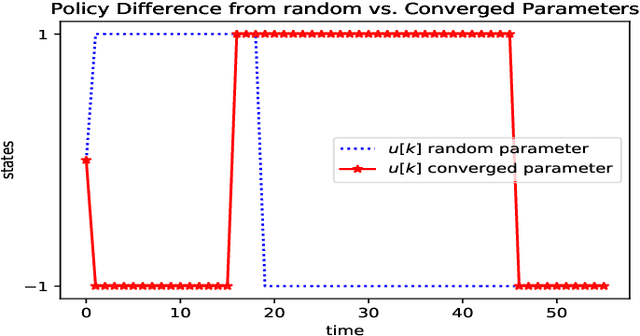
The reinforcement learning problem of finding a control policy that minimizes the minimum time objective for the Mountain Car environment is considered. Particularly, a class of parameterized nonlinear feedback policies is optimized over to reach the top of the highest mountain peak in minimum time. The optimization is carried out using quasi-Stochastic Gradient Descent (qSGD) methods. In attempting to find the optimal minimum time policy, a new parameterized policy approach is considered that seeks to learn an optimal policy parameter for different regions of the state space, rather than rely on a single macroscopic policy parameter for the entire state space. This partitioned parameterized policy approach is shown to outperform the uniform parameterized policy approach and lead to greater generalization than prior methods, where the Mountain Car became trapped in circular trajectories in the state space.