 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum Learning for Safety Alignment
May 25, 2026Direct Preference Optimisation (DPO) is widely used for safety alignment in large language models. However, prior work shows it is brittle and exhibits poor out-of-distribution (OOD) generalisation. In this paper, we investigate whether Curriculum Learning can improve the robustness of DPO-based safety alignment. We propose Staged-Competence, a curriculum-based framework that organises preference data by difficulty, employs competence-based sampling, and progressively updates the reference model during training. Averaged across three model families, Staged-Competence reduces OOD harmful response rates by 16% and jailbreak attack success rates by 20%, while preserving general capabilities with near-zero over-refusal. We further show that Staged-Competence (1) matches baseline safety with only 75% of the training data and (2) yields better separation between safe and unsafe responses. Staged-Competence is agnostic to the policy optimisation loss and can extend to other DPO variants and alignment domains. Our code and data are available at https://github.com/Sandeep5500/curriculum-learning-for-safety.
When Reviews Disagree: Fine-Grained Contradiction Analysis in Scientific Peer Reviews
May 11, 2026Scientific peer reviews frequently contain conflicting expert judgments, and the increasing scale of conference submissions makes it challenging for Area Chairs and editors to reliably identify and interpret such disagreements. Existing approaches typically frame reviewer disagreement as binary contradiction detection over isolated sentence pairs, abstracting away the review-level context and obscuring differences in the severity of evaluative conflict. In this work, we introduce a fine-grained formulation of reviewer contradiction analysis that operates over full peer reviews by explicitly identifying contradiction evidence spans and assigning graded disagreement intensity scores. To support this task, we present RevCI, an expert-annotated benchmark of peer-review pairs with evidence-level contradiction annotations with graded intensity labels. We further propose IMPACT, a structured multi-agent framework that integrates aspect-conditioned evidence extraction, deliberative reasoning, and adjudication to model reviewer contradictions and their intensity. To support efficient deployment, we distill IMPACT into TIDE, a small language model that predicts contradiction evidence and intensity in a single forward pass. Experimental results show that IMPACT substantially outperforms strong single-agent and generic multi-agent baselines in both evidence identification and intensity agreement, while TIDE achieves competitive performance at significantly lower inference cost.
Robust Visual SLAM for UAV Navigation in GPS-Denied and Degraded Environments: A Multi-Paradigm Evaluation and Deployment Study
May 05, 2026Reliable localization in GPS-denied, visually degraded environments is critical for autonomous UAV opera- tions. This paper presents a systematic comparative evaluation of five V-SLAM systems ORB-SLAM3, DPVO, DROID-SLAM, DUSt3R, and MASt3R spanning classical, deep learning, recurrent, and Vision Transformer (ViT) paradigms. Experiments are conducted on curated sequences from four public benchmarks (TUM RGB-D, EuRoC MAV, UMA-VI, SubT-MRS) and a custom monocular indoor dataset under five controlled degradation conditions (normal, low light, dust haze, motion blur, and combined), with sub-millimeter Vicon ground truth. Results show that ORB-SLAM3 fails critically under severe degradation (62.4% overall TSR; 0% under dense haze), while learning-based methods remain robust: MASt3R achieves the lowest degraded ATE (0.027 m) and DUSt3R the highest tracking success (96.5%). DPVO offers the best efficiency robustness trade-off (18.6 FPS, 3.1 GB GPU memory, 86.1% TSR), making it the preferred choice for memory-constrained embedded platforms. Embedded deployment analysis across NVIDIA Jetson platforms provides actionable guidelines for SLAM selection under SWaP-constrained UAV scenarios.
Factual and Edit-Sensitive Graph-to-Sequence Generation via Graph-Aware Adaptive Noising
Apr 27, 2026Fine-tuned autoregressive models for graph-to-sequence generation (G2S) often struggle with factual grounding and edit sensitivity. To tackle these issues, we propose a non-autoregressive diffusion framework that generates text by iterative refinement conditioned on an input graph, named as Diffusion Language Model for Graphs (DLM4G). By aligning graph components (entities/relations) with their corresponding sequence tokens, DLM4G employs an adaptive noising strategy. The proposed strategy uses per-token denoising error as a signal to adaptively modulate noise on entity and relation tokens, improving preservation of graph structure and enabling localized updates under graph edits. Evaluated on three datasets, DLM4G consistently outperforms competitive G2S diffusion baselines trained on identical splits across both surface-form and embedding-based metrics. DLM4G further exceeds fine-tuned autoregressive baselines up to 12x larger (e.g., T5-Large) and is competitive with zero-shot LLM transfer baselines up to 127x larger. Relative to the strongest fine-tuned PLM baseline, DLM4G improves factual grounding (FGT@0.5) by +5.16% and edit sensitivity (ESR) by +7.9%; compared to the best diffusion baseline, it yields gains of +3.75% in FGT@0.5 and +23.6% in ESR. We additionally demonstrate applicability beyond textual graphs through experiments on molecule captioning, indicating the method's generality for scientific G2S generation.
BiMol-Diff: A Unified Diffusion Framework for Molecular Generation and Captioning
Apr 27, 2026Bridging molecular structures and natural language is essential for controllable design. Autoregressive models struggle with long-range dependencies, while standard diffusion processes apply uniform corruption across positions, which can distort structurally informative tokens. We present BiMol-Diff, a unified diffusion framework for the paired tasks of text-conditioned molecule generation and molecule captioning. Our key component is a token-aware noise schedule that assigns position-dependent corruption based on token recovery difficulty, preserving harder-to-recover substructures during the forward process. On ChEBI-20 and M3-20M, BiMol-Diff improves molecule reconstruction with a 15.4% relative gain in Exact Match and achieves strong captioning results, attaining best BLEU and BERTScore among compared baselines. These results indicate token-aware noising improves fidelity in molecular structure-language modelling.
Quantum walk inspired JPEG compression of images
Feb 12, 2026This work proposes a quantum inspired adaptive quantization framework that enhances the classical JPEG compression by introducing a learned, optimized Qtable derived using a Quantum Walk Inspired Optimization (QWIO) search strategy. The optimizer searches a continuous parameter space of frequency band scaling factors under a unified rate distortion objective that jointly considers reconstruction fidelity and compression efficiency. The proposed framework is evaluated on MNIST, CIFAR10, and ImageNet subsets, using Peak Signal to Noise Ratio (PSNR), Structural Similarity Index (SSIM), Bits Per Pixel (BPP), and error heatmap visual analysis as evaluation metrics. Experimental results show average gains ranging from 3 to 6 dB PSNR, along with better structural preservation of edges, contours, and luminance transitions, without modifying decoder compatibility. The structure remains JPEG compliant and can be implemented using accessible scientific packages making it ideal for deployment and practical research use.
CrossMed: A Multimodal Cross-Task Benchmark for Compositional Generalization in Medical Imaging
Nov 14, 2025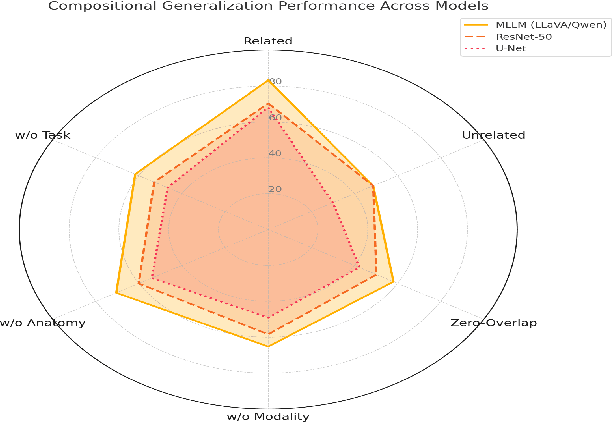
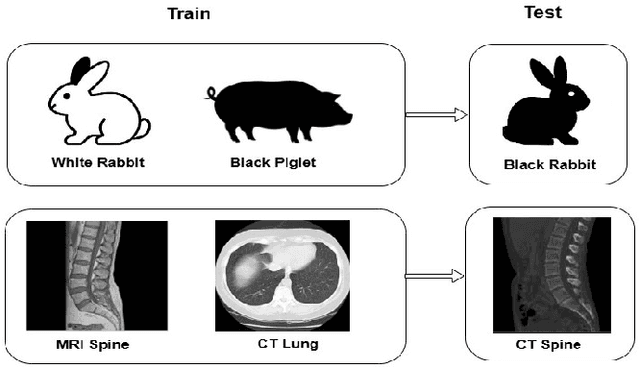
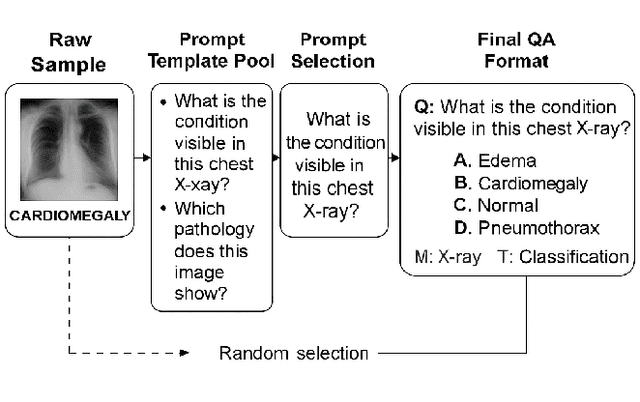
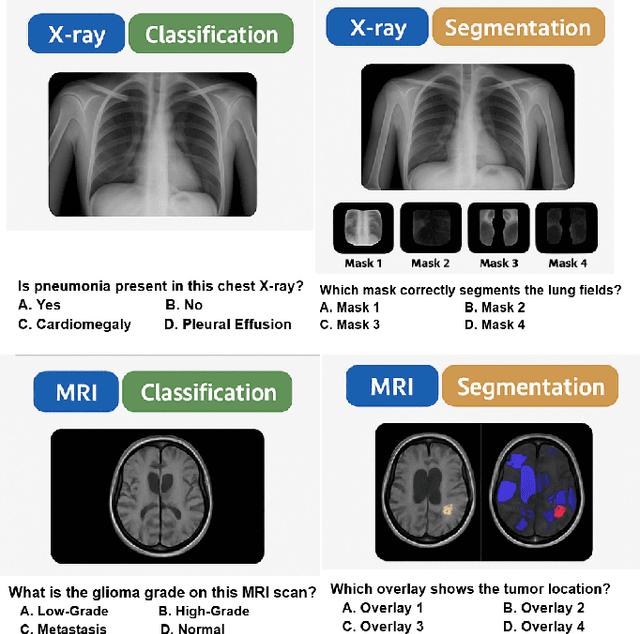
Recent advances in multimodal large language models have enabled unified processing of visual and textual inputs, offering promising applications in general-purpose medical AI. However, their ability to generalize compositionally across unseen combinations of imaging modality, anatomy, and task type remains underexplored. We introduce CrossMed, a benchmark designed to evaluate compositional generalization (CG) in medical multimodal LLMs using a structured Modality-Anatomy-Task (MAT) schema. CrossMed reformulates four public datasets, CheXpert (X-ray classification), SIIM-ACR (X-ray segmentation), BraTS 2020 (MRI classification and segmentation), and MosMedData (CT classification) into a unified visual question answering (VQA) format, resulting in 20,200 multiple-choice QA instances. We evaluate two open-source multimodal LLMs, LLaVA-Vicuna-7B and Qwen2-VL-7B, on both Related and Unrelated MAT splits, as well as a zero-overlap setting where test triplets share no Modality, Anatomy, or Task with the training data. Models trained on Related splits achieve 83.2 percent classification accuracy and 0.75 segmentation cIoU, while performance drops significantly under Unrelated and zero-overlap conditions, demonstrating the benchmark difficulty. We also show cross-task transfer, where segmentation performance improves by 7 percent cIoU even when trained using classification-only data. Traditional models (ResNet-50 and U-Net) show modest gains, confirming the broad utility of the MAT framework, while multimodal LLMs uniquely excel at compositional generalization. CrossMed provides a rigorous testbed for evaluating zero-shot, cross-task, and modality-agnostic generalization in medical vision-language models.
Quantum Fourier Transform Based Denoising: Unitary Filtering for Enhanced Speech Clarity
Sep 05, 2025This paper introduces a quantum-inspired denoising framework that integrates the Quantum Fourier Transform (QFT) into classical audio enhancement pipelines. Unlike conventional Fast Fourier Transform (FFT) based methods, QFT provides a unitary transformation with global phase coherence and energy preservation, enabling improved discrimination between speech and noise. The proposed approach replaces FFT in Wiener and spectral subtraction filters with a QFT operator, ensuring consistent hyperparameter settings for fair comparison. Experiments on clean speech, synthetic tones, and noisy mixtures across diverse signal to noise ratio (SNR) conditions, demonstrate statistically significant gains in SNR, with up to 15 dB improvement and reduced artifact generation. Results confirm that QFT based denoising offers robustness under low SNR and nonstationary noise scenarios without additional computational overhead, highlighting its potential as a scalable pathway toward quantum-enhanced speech processing.
Histogram Driven Amplitude Embedding for Qubit Efficient Quantum Image Compression
Sep 05, 2025This work introduces a compact and hardware efficient method for compressing color images using near term quantum devices. The approach segments the image into fixed size blocks called bixels, and computes the total intensity within each block. A global histogram with B bins is then constructed from these block intensities, and the normalized square roots of the bin counts are encoded as amplitudes into an n qubit quantum state. Amplitude embedding is performed using PennyLane and executed on real IBM Quantum hardware. The resulting state is measured to reconstruct the histogram, enabling approximate recovery of block intensities and full image reassembly. The method maintains a constant qubit requirement based solely on the number of histogram bins, independent of the resolution of the image. By adjusting B, users can control the trade off between fidelity and resource usage. Empirical results demonstrate high quality reconstructions using as few as 5 to 7 qubits, significantly outperforming conventional pixel level encodings in terms of qubit efficiency and validating the practical application of the method for current NISQ era quantum systems.
A Hybrid Ensemble Learning Framework for Image-Based Solar Panel Classification
Jul 02, 2025The installation of solar energy systems is on the rise, and therefore, appropriate maintenance techniques are required to be used in order to maintain maximum performance levels. One of the major challenges is the automated discrimination between clean and dirty solar panels. This paper presents a novel Dual Ensemble Neural Network (DENN) to classify solar panels using image-based features. The suggested approach utilizes the advantages offered by various ensemble models by integrating them into a dual framework, aimed at improving both classification accuracy and robustness. The DENN model is evaluated in comparison to current ensemble methods, showcasing its superior performance across a range of assessment metrics. The proposed approach performs the best compared to other methods and reaches state-of-the-art accuracy on experimental results for the Deep Solar Eye dataset, effectively serving predictive maintenance purposes in solar energy systems. It reveals the potential of hybrid ensemble learning techniques to further advance the prospects of automated solar panel inspections as a scalable solution to real-world challenges.