 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ARISE: ApeRIodic SEmi-parametric Process for Efficient Markets without Periodogram and Gaussianity Assumptions
Nov 08, 2021
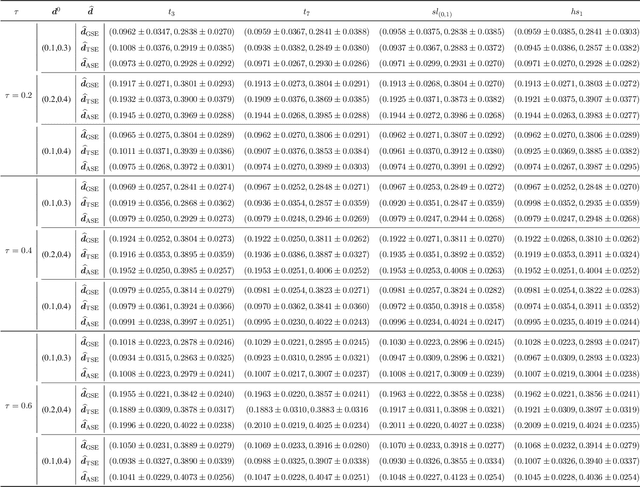
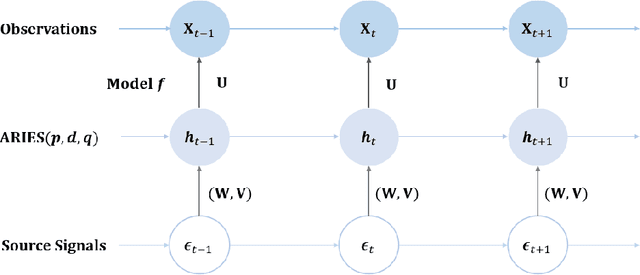
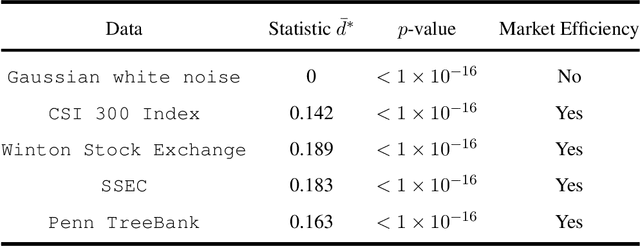
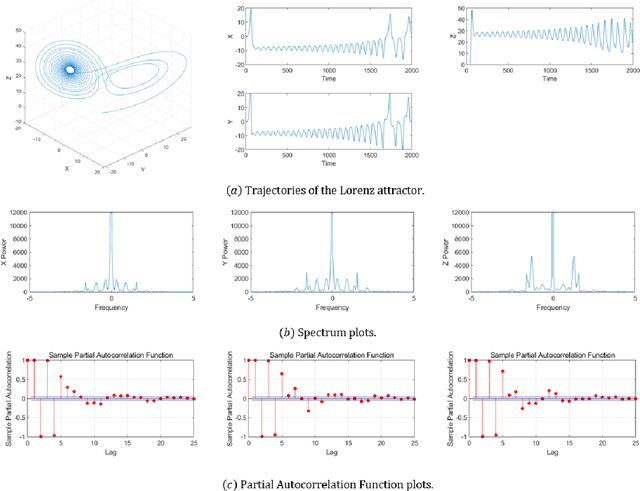
Mimicking and learning the long-term memory of efficient markets is a fundamental problem in the interaction between machine learning and financial economics to sequential data. Despite the prominence of this issue, current treatments either remain largely limited to heuristic techniques or rely significantly on periodogram or Gaussianty assumptions. In this paper, we present the ApeRIodic SEmi-parametric (ARISE) process for investigating efficient markets. The ARISE process is formulated as an infinite-sum function of some known processes and employs the aperiodic spectrum estimation to determine the key hyper-parameters, thus possessing the power and potential of modeling the price data with long-term memory, non-stationarity, and aperiodic spectrum. We further theoretically show that the ARISE process has the mean-square convergence, consistency, and asymptotic normality without periodogram and Gaussianity assumptions. In practice, we apply the ARISE process to identify the efficiency of real-world markets. Besides, we also provide two alternative ARISE applications: studying the long-term memorability of various machine-learning models and developing a latent state-space model for inference and forecasting of time series. The numerical experiments confirm the superiority of our proposed approaches.
Learning to Equalize OTFS
Jul 17, 2021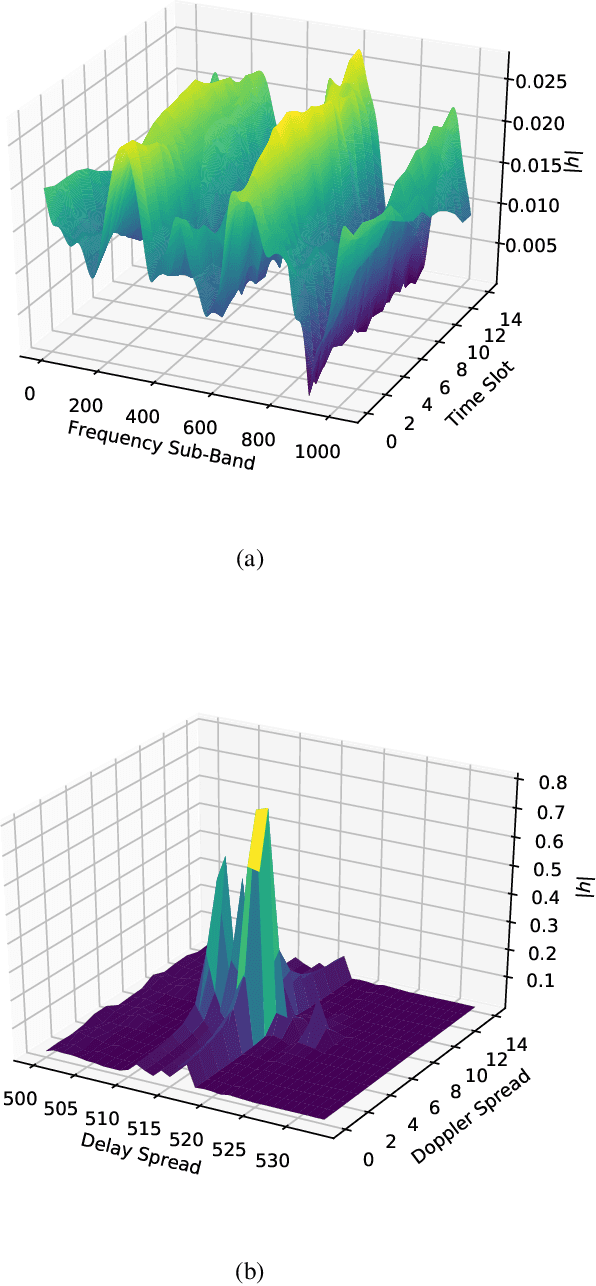
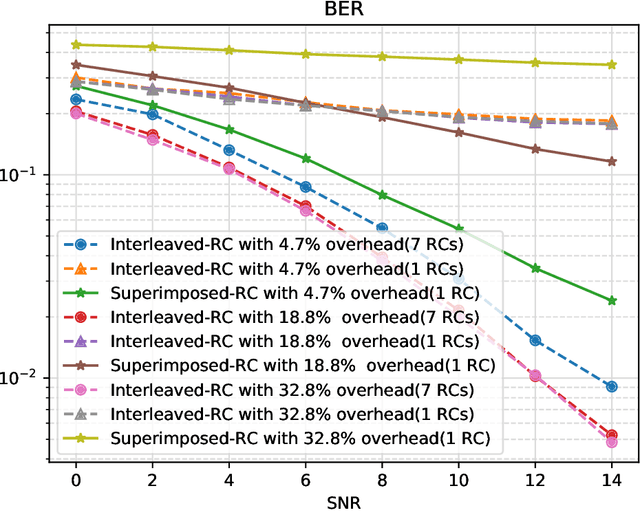
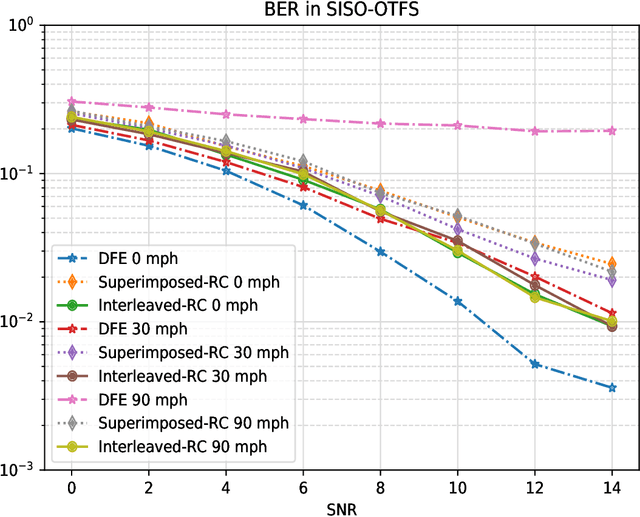
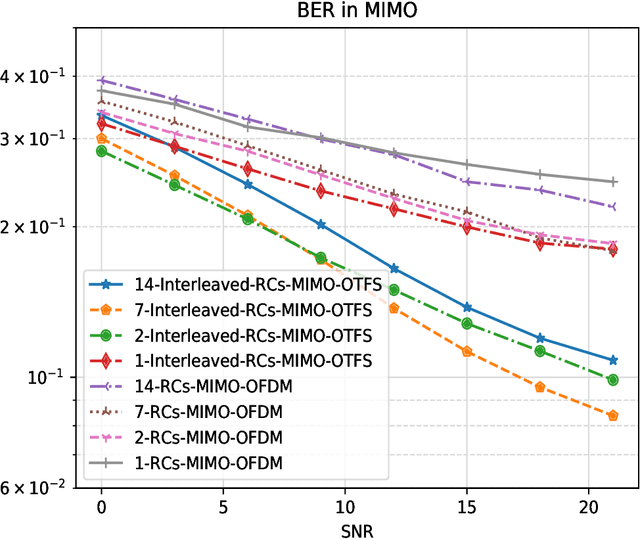
Orthogonal Time Frequency Space (OTFS) is a novel framework that processes modulation symbols via a time-independent channel characterized by the delay-Doppler domain. The conventional waveform, orthogonal frequency division multiplexing (OFDM), requires tracking frequency selective fading channels over the time, whereas OTFS benefits from full time-frequency diversity by leveraging appropriate equalization techniques. In this paper, we consider a neural network-based supervised learning framework for OTFS equalization. Learning of the introduced neural network is conducted in each OTFS frame fulfilling an online learning framework: the training and testing datasets are within the same OTFS-frame over the air. Utilizing reservoir computing, a special recurrent neural network, the resulting one-shot online learning is sufficiently flexible to cope with channel variations among different OTFS frames (e.g., due to the link/rank adaptation and user scheduling in cellular networks). The proposed method does not require explicit channel state information (CSI) and simulation results demonstrate a lower bit error rate (BER) than conventional equalization methods in the low signal-to-noise (SNR) regime under large Doppler spreads. When compared with its neural network-based counterparts for OFDM, the introduced approach for OTFS will lead to a better tradeoff between the processing complexity and the equalization performance.
DeepSleepNet-Lite: A Simplified Automatic Sleep Stage Scoring Model with Uncertainty Estimates
Aug 24, 2021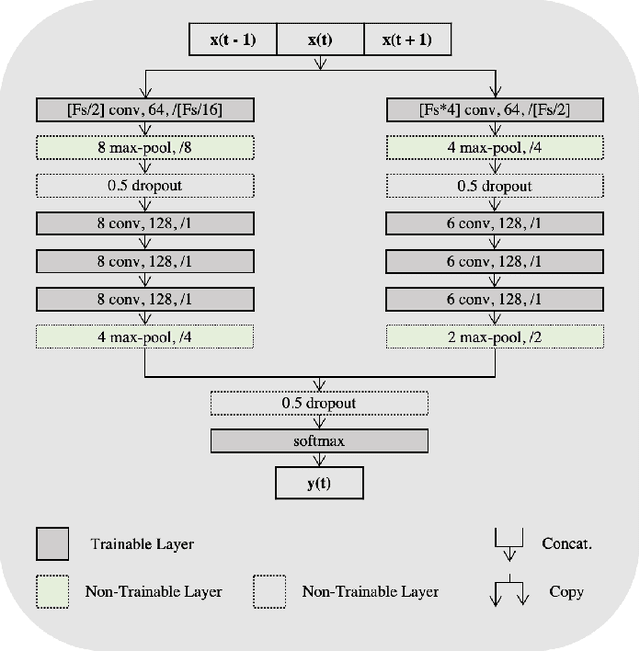
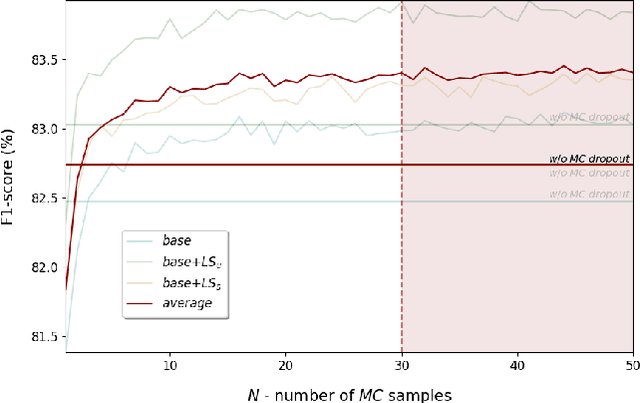
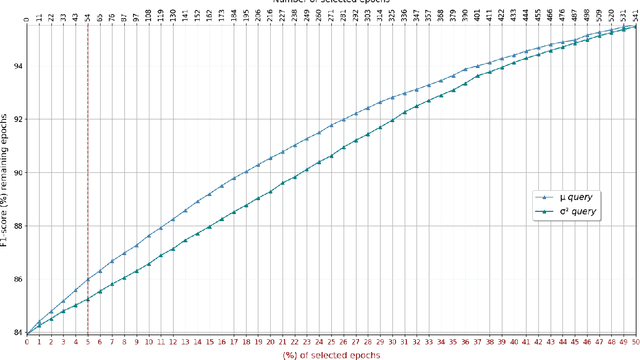
Deep learning is widely used in the most recent automatic sleep scoring algorithms. Its popularity stems from its excellent performance and from its ability to directly process raw signals and to learn feature from the data. Most of the existing scoring algorithms exploit very computationally demanding architectures, due to their high number of training parameters, and process lengthy time sequences in input (up to 12 minutes). Only few of these architectures provide an estimate of the model uncertainty. In this study we propose DeepSleepNet-Lite, a simplified and lightweight scoring architecture, processing only 90-seconds EEG input sequences. We exploit, for the first time in sleep scoring, the Monte Carlo dropout technique to enhance the performance of the architecture and to also detect the uncertain instances. The evaluation is performed on a single-channel EEG Fpz-Cz from the open source Sleep-EDF expanded database. DeepSleepNet-Lite achieves slightly lower performance, if not on par, compared to the existing state-of-the-art architectures, in overall accuracy, macro F1-score and Cohen's kappa (on Sleep-EDF v1-2013 +/-30mins: 84.0%, 78.0%, 0.78; on Sleep-EDF v2-2018 +/-30mins: 80.3%, 75.2%, 0.73). Monte Carlo dropout enables the estimate of the uncertain predictions. By rejecting the uncertain instances, the model achieves higher performance on both versions of the database (on Sleep-EDF v1-2013 +/-30mins: 86.1.0%, 79.6%, 0.81; on Sleep-EDF v2-2018 +/-30mins: 82.3%, 76.7%, 0.76). Our lighter sleep scoring approach paves the way to the application of scoring algorithms for sleep analysis in real-time.
Deformed2Self: Self-Supervised Denoising for Dynamic Medical Imaging
Jun 23, 2021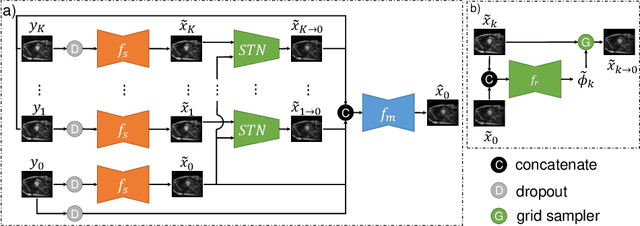
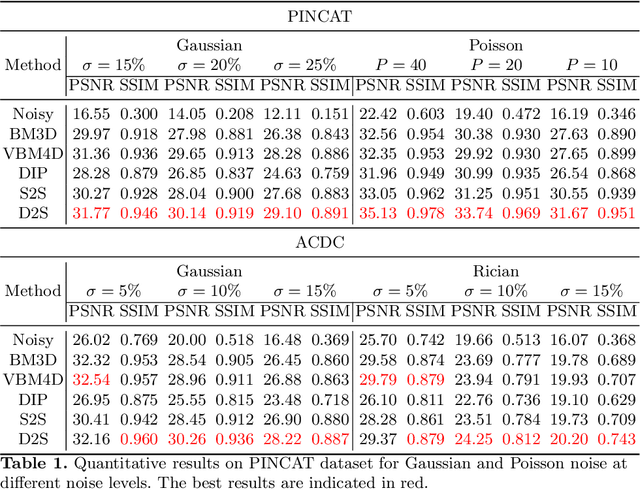
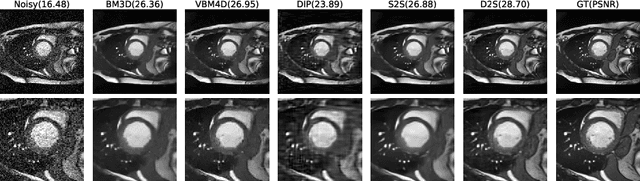
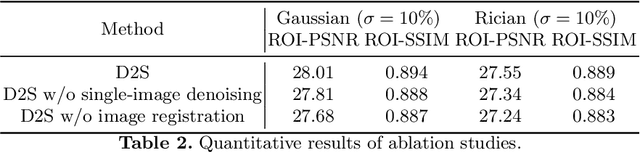
Image denoising is of great importance for medical imaging system, since it can improve image quality for disease diagnosis and downstream image analyses. In a variety of applications, dynamic imaging techniques are utilized to capture the time-varying features of the subject, where multiple images are acquired for the same subject at different time points. Although signal-to-noise ratio of each time frame is usually limited by the short acquisition time, the correlation among different time frames can be exploited to improve denoising results with shared information across time frames. With the success of neural networks in computer vision, supervised deep learning methods show prominent performance in single-image denoising, which rely on large datasets with clean-vs-noisy image pairs. Recently, several self-supervised deep denoising models have been proposed, achieving promising results without needing the pairwise ground truth of clean images. In the field of multi-image denoising, however, very few works have been done on extracting correlated information from multiple slices for denoising using self-supervised deep learning methods. In this work, we propose Deformed2Self, an end-to-end self-supervised deep learning framework for dynamic imaging denoising. It combines single-image and multi-image denoising to improve image quality and use a spatial transformer network to model motion between different slices. Further, it only requires a single noisy image with a few auxiliary observations at different time frames for training and inference. Evaluations on phantom and in vivo data with different noise statistics show that our method has comparable performance to other state-of-the-art unsupervised or self-supervised denoising methods and outperforms under high noise levels.
Parallel Actors and Learners: A Framework for Generating Scalable RL Implementations
Oct 03, 2021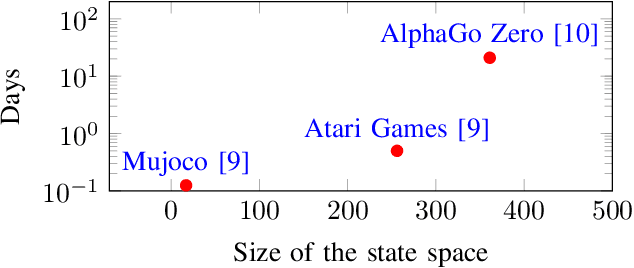
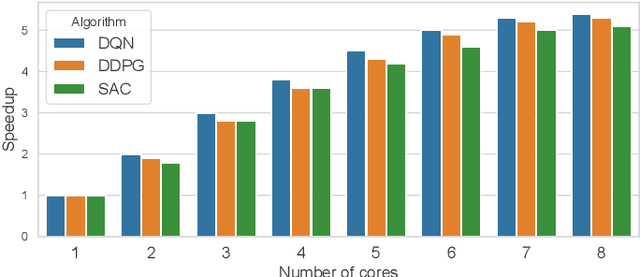
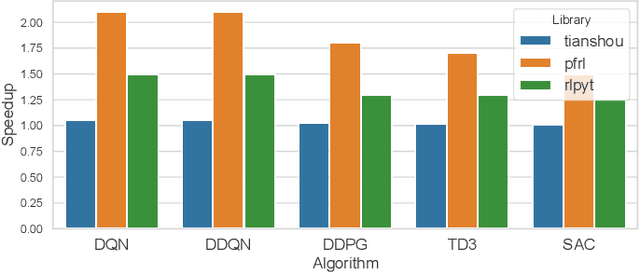
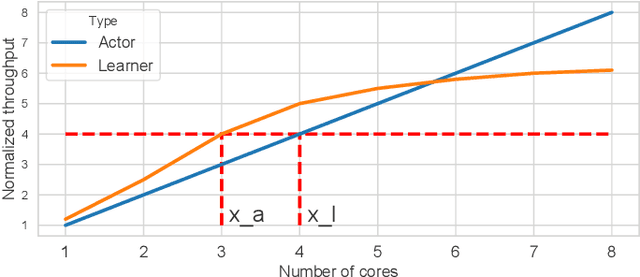
Reinforcement Learning (RL) has achieved significant success in application domains such as robotics, games, health care and others. However, training RL agents is very time consuming. Current implementations exhibit poor performance due to challenges such as irregular memory accesses and synchronization overheads. In this work, we propose a framework for generating scalable reinforcement learning implementations on multicore systems. Replay Buffer is a key component of RL algorithms which facilitates storage of samples obtained from environmental interactions and their sampling for the learning process. We define a new data structure for prioritized replay buffer based on $K$-ary sum tree that supports asynchronous parallel insertions, sampling, and priority updates. To address the challenge of irregular memory accesses, we propose a novel data layout to store the nodes of the sum tree that reduces the number of cache misses. Additionally, we propose \textit{lazy writing} mechanism to reduce synchronization overheads of the replay buffer. Our framework employs parallel actors to concurrently collect data via environmental interactions, and parallel learners to perform stochastic gradient descent using the collected data. Our framework supports a wide range of reinforcement learning algorithms including DQN, DDPG, TD3, SAC, etc. We demonstrate the effectiveness of our framework in accelerating RL algorithms by performing experiments on CPU + GPU platform using OpenAI benchmarks. Our results show that the performance of our approach scales linearly with the number of cores. Compared with the baseline approaches, we reduce the convergence time by 3.1x$\sim$10.8x. By plugging our replay buffer implementation into existing open source reinforcement learning frameworks, we achieve 1.1x$\sim$2.1x speedup for sequential executions.
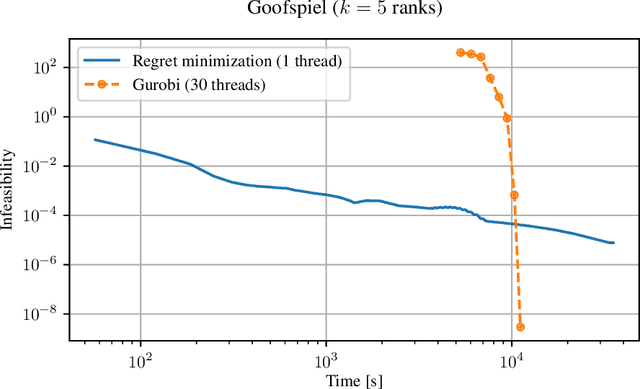
Polynomial-Time Computation of Optimal Correlated Equilibria in Two-Player Extensive-Form Games with Public Chance Moves and Beyond
Sep 09, 2020
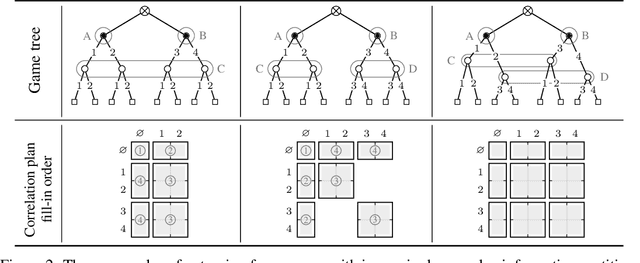

Unlike normal-form games, where correlated equilibria have been studied for more than 45 years, extensive-form correlation is still generally not well understood. Part of the reason for this gap is that the sequential nature of extensive-form games allows for a richness of behaviors and incentives that are not possible in normal-form settings. This richness translates to a significantly different complexity landscape surrounding extensive-form correlated equilibria. As of today, it is known that finding an optimal extensive-form correlated equilibrium (EFCE), extensive-form coarse correlated equilibrium (EFCCE), or normal-form coarse correlated equilibrium (NFCCE) in a two-player extensive-form game is computationally tractable when the game does not include chance moves, and intractable when the game involves chance moves. In this paper we significantly refine this complexity threshold by showing that, in two-player games, an optimal correlated equilibrium can be computed in polynomial time, provided that a certain condition is satisfied. We show that the condition holds, for example, when all chance moves are public, that is, both players observe all chance moves. This implies that an optimal EFCE, EFCCE and NFCCE can be computed in polynomial time in the game size in two-player games with public chance moves, providing the biggest positive complexity result surrounding extensive-form correlation in more than a decade.
RepNAS: Searching for Efficient Re-parameterizing Blocks
Sep 08, 2021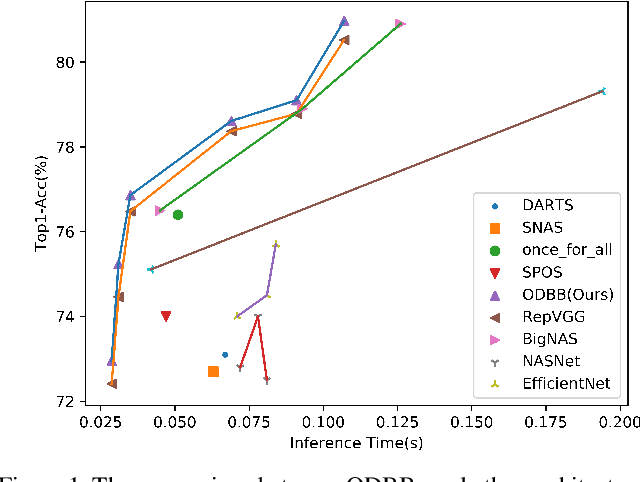

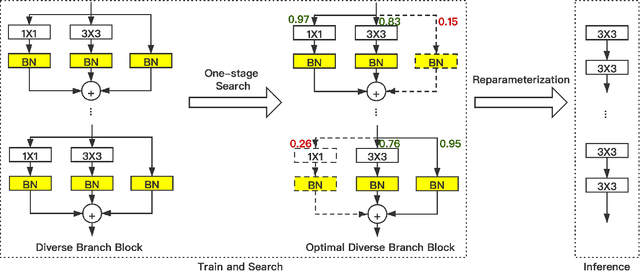
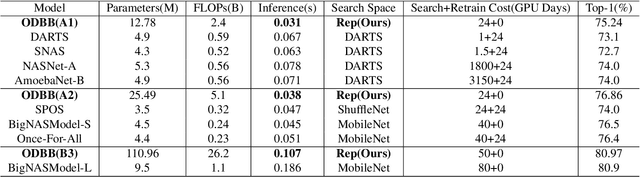
In the past years, significant improvements in the field of neural architecture search(NAS) have been made. However, it is still challenging to search for efficient networks due to the gap between the searched constraint and real inference time exists. To search for a high-performance network with low inference time, several previous works set a computational complexity constraint for the search algorithm. However, many factors affect the speed of inference(e.g., FLOPs, MACs). The correlation between a single indicator and the latency is not strong. Currently, some re-parameterization(Rep) techniques are proposed to convert multi-branch to single-path architecture which is inference-friendly. Nevertheless, multi-branch architectures are still human-defined and inefficient. In this work, we propose a new search space that is suitable for structural re-parameterization techniques. RepNAS, a one-stage NAS approach, is present to efficiently search the optimal diverse branch block(ODBB) for each layer under the branch number constraint. Our experimental results show the searched ODBB can easily surpass the manual diverse branch block(DBB) with efficient training. Code and models will be available sooner.
JRMOT: A Real-Time 3D Multi-Object Tracker and a New Large-Scale Dataset
Mar 18, 2020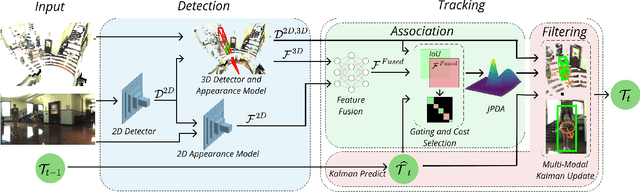
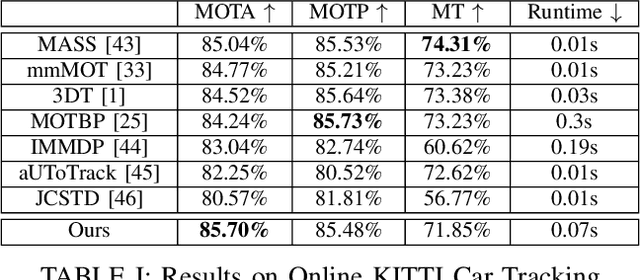
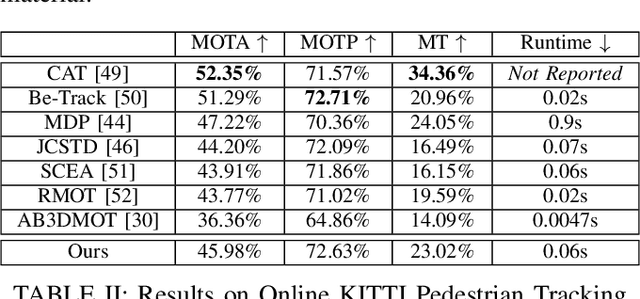
An autonomous navigating agent needs to perceive and track the motion of objects and other agents in its surroundings to achieve robust and safe motion planning and execution. While autonomous navigation requires a multi-object tracking (MOT) system to provide 3D information, most research has been done in 2D MOT from RGB videos. In this work we present JRMOT, a novel 3D MOT system that integrates information from 2D RGB images and 3D point clouds into a real-time performing framework. Our system leverages advancements in neural-network based re-identification as well as 2D and 3D detection and descriptors. We incorporate this into a joint probabilistic data-association framework within a multi-modal recursive Kalman architecture to achieve online, real-time 3D MOT. As part of our work, we release the JRDB dataset, a novel large scale 2D+3D dataset and benchmark annotated with over 2 million boxes and 3500 time consistent 2D+3D trajectories across 54 indoor and outdoor scenes. The dataset contains over 60 minutes of data including 360 degree cylindrical RGB video and 3D pointclouds. The presented 3D MOT system demonstrates state-of-the-art performance against competing methods on the popular 2D tracking KITTI benchmark and serves as a competitive 3D tracking baseline for our dataset and benchmark.
Terahertz-Band Non-Orthogonal Multiple Access: System- and Link-Level Considerations
Nov 02, 2021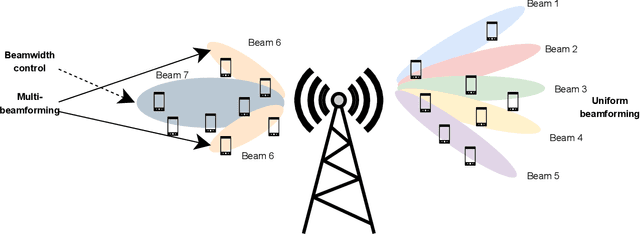
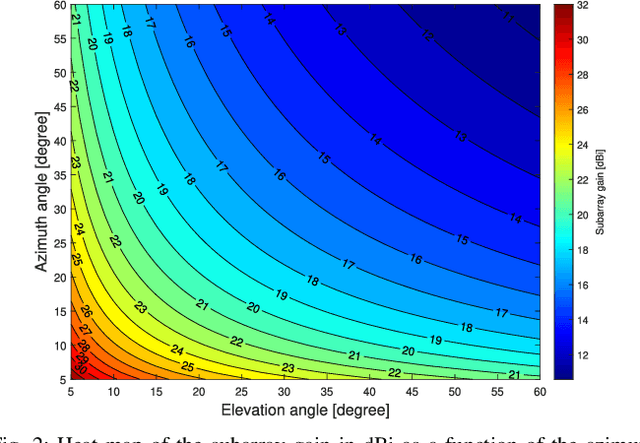
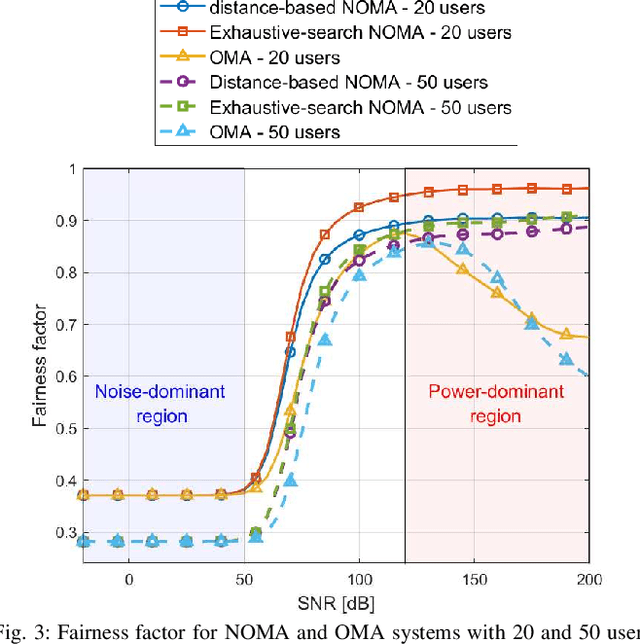
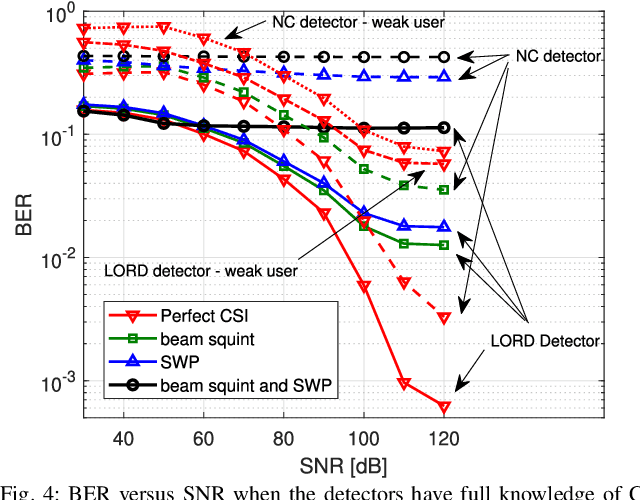
Non-orthogonal multiple access (NOMA) communications promise high spectral efficiency and massive connectivity, serving multiple users over the same time-frequency-code resources. Higher data rates and massive connectivity are also achieved by leveraging wider bandwidths at higher frequencies, especially in the terahertz (THz) band. This work investigates the prospects and challenges of combining these algorithmic and spectrum enablers in THz-band NOMA communications. We consider power-domain NOMA coupled with successive interference cancellation at the receiver, focusing on multiple-input multiple-output (MIMO) systems as antenna arrays are crucial for THz communications. On the system level, we study the scalability of THz-NOMA beamforming, clustering, and spectrum/power allocation algorithms and motivate stochastic geometry techniques for performance analysis and system modeling. On the link level, we highlight the challenges in channel estimation and data detection and the constraints on computational complexity. We further illustrate future research directions. When properly configured and given sufficient densification, THz-band NOMA communications can significantly improve the performance and capacity of future wireless networks.
Learning and Dynamical Models for Sub-seasonal Climate Forecasting: Comparison and Collaboration
Sep 29, 2021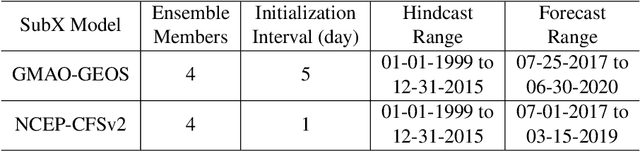
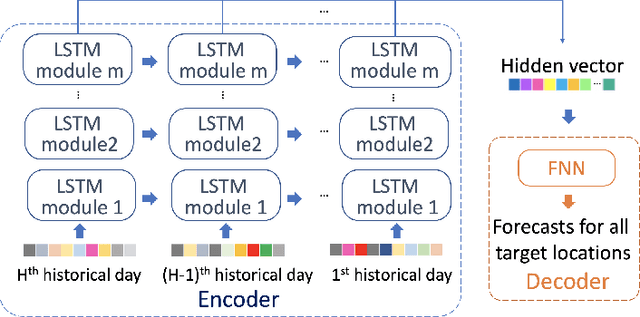
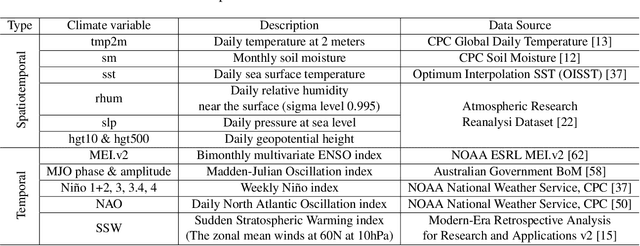
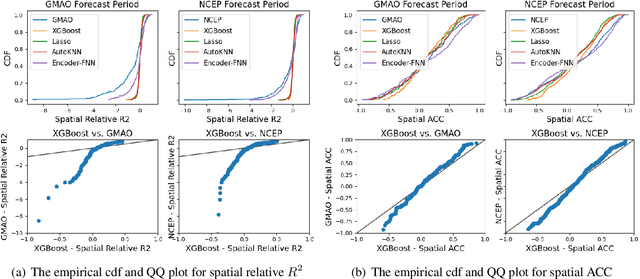
Sub-seasonal climate forecasting (SSF) is the prediction of key climate variables such as temperature and precipitation on the 2-week to 2-month time horizon. Skillful SSF would have substantial societal value in areas such as agricultural productivity, hydrology and water resource management, and emergency planning for extreme events such as droughts and wildfires. Despite its societal importance, SSF has stayed a challenging problem compared to both short-term weather forecasting and long-term seasonal forecasting. Recent studies have shown the potential of machine learning (ML) models to advance SSF. In this paper, for the first time, we perform a fine-grained comparison of a suite of modern ML models with start-of-the-art physics-based dynamical models from the Subseasonal Experiment (SubX) project for SSF in the western contiguous United States. Additionally, we explore mechanisms to enhance the ML models by using forecasts from dynamical models. Empirical results illustrate that, on average, ML models outperform dynamical models while the ML models tend to be conservatives in their forecasts compared to the SubX models. Further, we illustrate that ML models make forecasting errors under extreme weather conditions, e.g., cold waves due to the polar vortex, highlighting the need for separate models for extreme events. Finally, we show that suitably incorporating dynamical model forecasts as inputs to ML models can substantially improve the forecasting performance of the ML models. The SSF dataset constructed for the work, dynamical model predictions, and code for the ML models are released along with the paper for the benefit of the broader machine learning community.