 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Actors and Learners: A Framework for Generating Scalable RL Implementations
Oct 03, 2021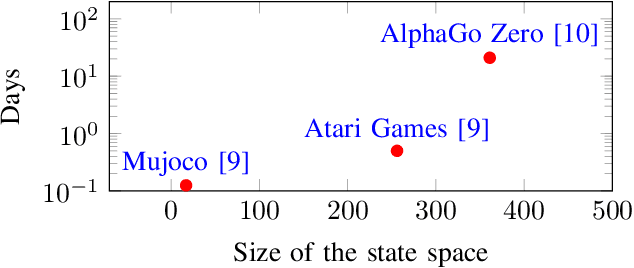
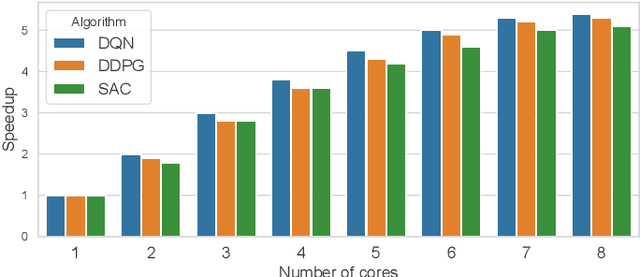
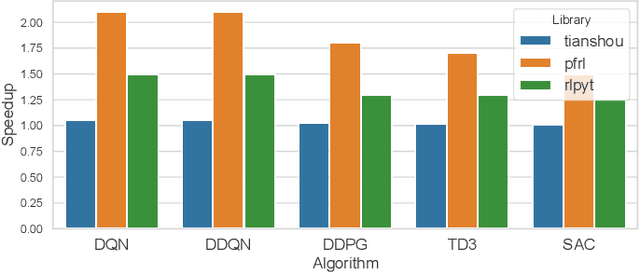
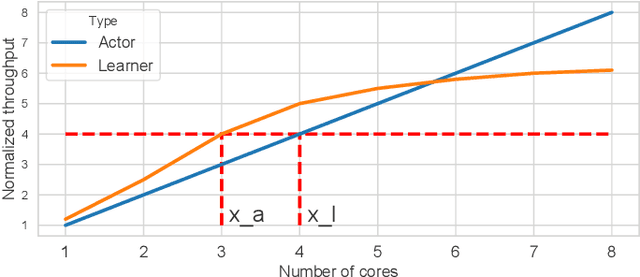
Reinforcement Learning (RL) has achieved significant success in application domains such as robotics, games, health care and others. However, training RL agents is very time consuming. Current implementations exhibit poor performance due to challenges such as irregular memory accesses and synchronization overheads. In this work, we propose a framework for generating scalable reinforcement learning implementations on multicore systems. Replay Buffer is a key component of RL algorithms which facilitates storage of samples obtained from environmental interactions and their sampling for the learning process. We define a new data structure for prioritized replay buffer based on $K$-ary sum tree that supports asynchronous parallel insertions, sampling, and priority updates. To address the challenge of irregular memory accesses, we propose a novel data layout to store the nodes of the sum tree that reduces the number of cache misses. Additionally, we propose \textit{lazy writing} mechanism to reduce synchronization overheads of the replay buffer. Our framework employs parallel actors to concurrently collect data via environmental interactions, and parallel learners to perform stochastic gradient descent using the collected data. Our framework supports a wide range of reinforcement learning algorithms including DQN, DDPG, TD3, SAC, etc. We demonstrate the effectiveness of our framework in accelerating RL algorithms by performing experiments on CPU + GPU platform using OpenAI benchmarks. Our results show that the performance of our approach scales linearly with the number of cores. Compared with the baseline approaches, we reduce the convergence time by 3.1x$\sim$10.8x. By plugging our replay buffer implementation into existing open source reinforcement learning frameworks, we achieve 1.1x$\sim$2.1x speedup for sequential executions.
BRAC+: Improved Behavior Regularized Actor Critic for Offline Reinforcement Learning
Oct 02, 2021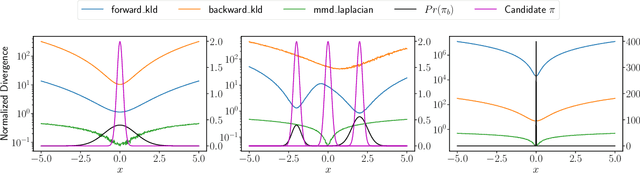
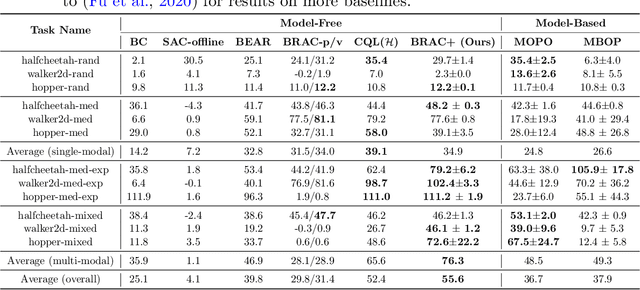
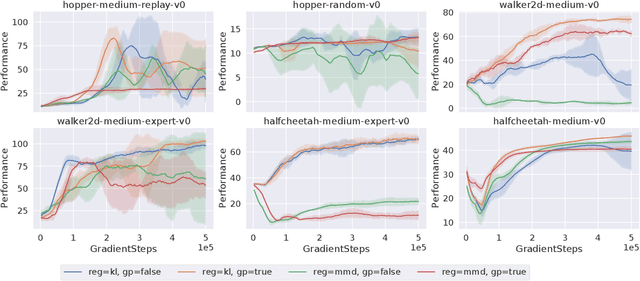
Online interactions with the environment to collect data samples for training a Reinforcement Learning (RL) agent is not always feasible due to economic and safety concerns. The goal of Offline Reinforcement Learning is to address this problem by learning effective policies using previously collected datasets. Standard off-policy RL algorithms are prone to overestimations of the values of out-of-distribution (less explored) actions and are hence unsuitable for Offline RL. Behavior regularization, which constraints the learned policy within the support set of the dataset, has been proposed to tackle the limitations of standard off-policy algorithms. In this paper, we improve the behavior regularized offline reinforcement learning and propose BRAC+. First, we propose quantification of the out-of-distribution actions and conduct comparisons between using Kullback-Leibler divergence versus using Maximum Mean Discrepancy as the regularization protocol. We propose an analytical upper bound on the KL divergence as the behavior regularizer to reduce variance associated with sample based estimations. Second, we mathematically show that the learned Q values can diverge even using behavior regularized policy update under mild assumptions. This leads to large overestimations of the Q values and performance deterioration of the learned policy. To mitigate this issue, we add a gradient penalty term to the policy evaluation objective. By doing so, the Q values are guaranteed to converge. On challenging offline RL benchmarks, BRAC+ outperforms the baseline behavior regularized approaches by 40%~87% and the state-of-the-art approach by 6%.
Maximum Entropy Model Rollouts: Fast Model Based Policy Optimization without Compounding Errors
Jun 29, 2020

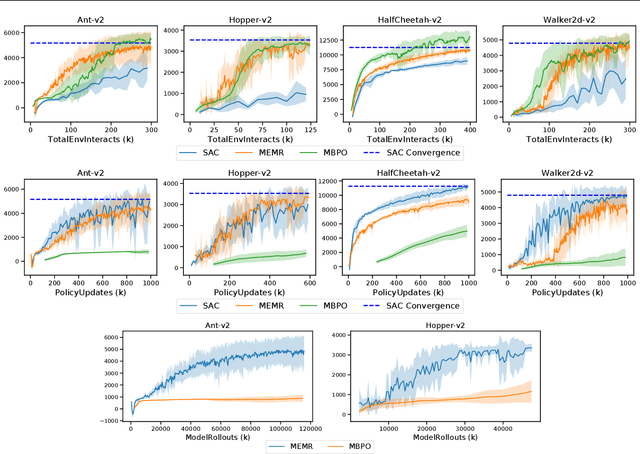
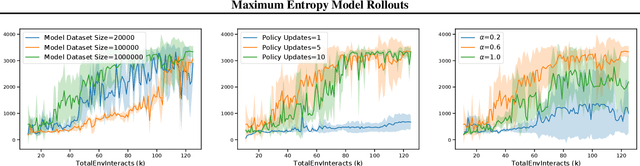
Model usage is the central challenge of model-based reinforcement learning. Although dynamics model based on deep neural networks provide good generalization for single step prediction, such ability is over exploited when it is used to predict long horizon trajectories due to compounding errors. In this work, we propose a Dyna-style model-based reinforcement learning algorithm, which we called Maximum Entropy Model Rollouts (MEMR). To eliminate the compounding errors, we only use our model to generate single-step rollouts. Furthermore, we propose to generate \emph{diverse} model rollouts by non-uniform sampling of the environment states such that the entropy of the model rollouts is maximized. We mathematically derived the maximum entropy sampling criteria for one data case under Gaussian prior. To accomplish this criteria, we propose to utilize a prioritized experience replay. Our preliminary experiments in challenging locomotion benchmarks show that our approach achieves the same sample efficiency of the best model-based algorithms, matches the asymptotic performance of the best model-free algorithms, and significantly reduces the computation requirements of other model-based methods.