 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-Time Neural Network Scheduling of Emergency Medical Mask Production during COVID-19
Jul 28, 2020

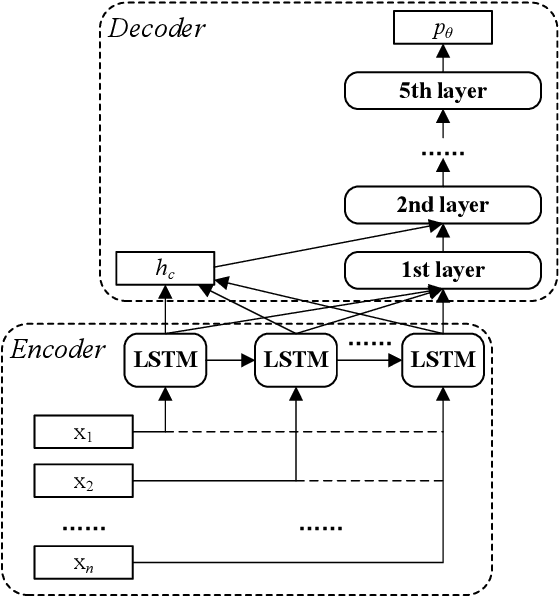
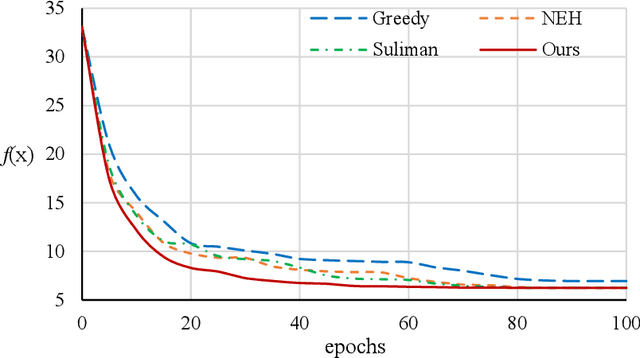
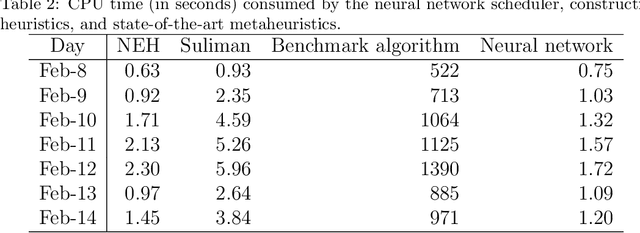
During the outbreak of the novel coronavirus pneumonia (COVID-19), there is a huge demand for medical masks. A mask manufacturer often receives a large amount of orders that are beyond its capability. Therefore, it is of critical importance for the manufacturer to schedule mask production tasks as efficiently as possible. However, existing scheduling methods typically require a considerable amount of computational resources and, therefore, cannot effectively cope with the surge of orders. In this paper, we propose an end-to-end neural network for scheduling real-time production tasks. The neural network takes a sequence of production tasks as inputs to predict a distribution over different schedules, employs reinforcement learning to optimize network parameters using the negative total tardiness as the reward signal, and finally produces a high-quality solution to the scheduling problem. We applied the proposed approach to schedule emergency production tasks for a medical mask manufacturer during the peak of COVID-19 in China. Computational results show that the neural network scheduler can solve problem instances with hundreds of tasks within seconds. The objective function value (i.e., the total weighted tardiness) produced by the neural network scheduler is significantly better than those of existing constructive heuristics, and is very close to those of the state-of-the-art metaheuristics whose computational time is unaffordable in practice.
Deep Learning-based Non-Intrusive Multi-Objective Speech Assessment Model with Cross-Domain Features
Nov 03, 2021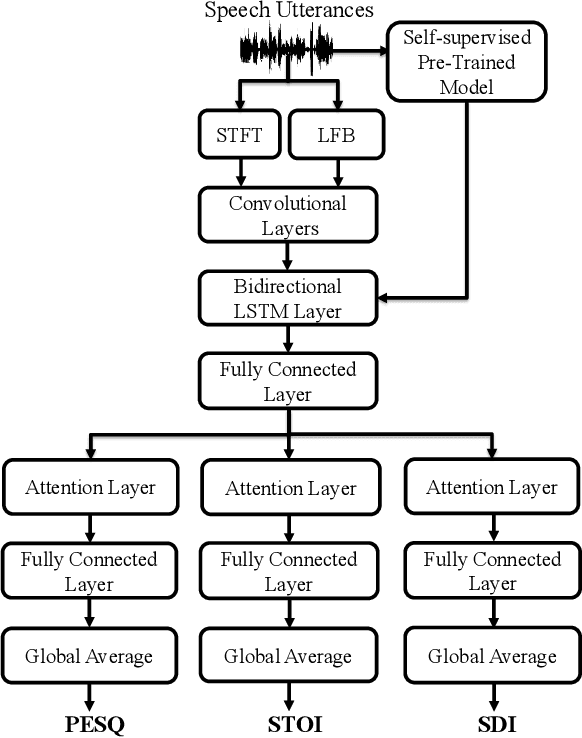
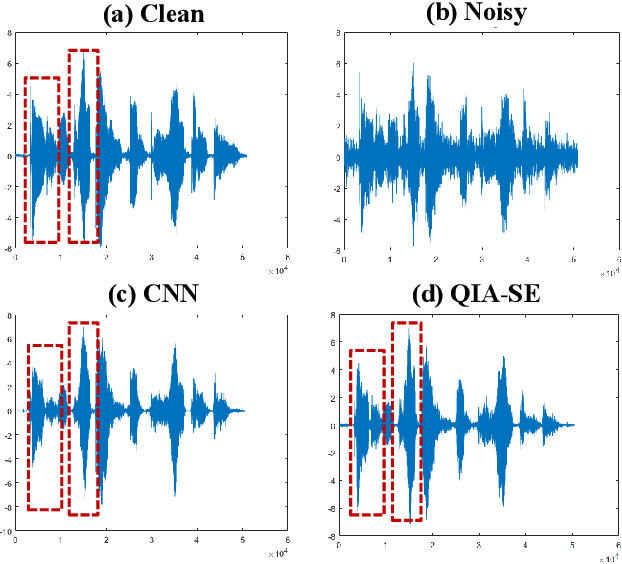
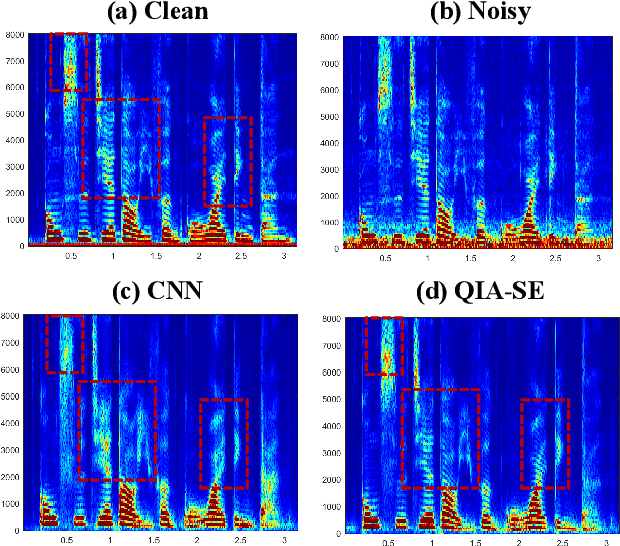
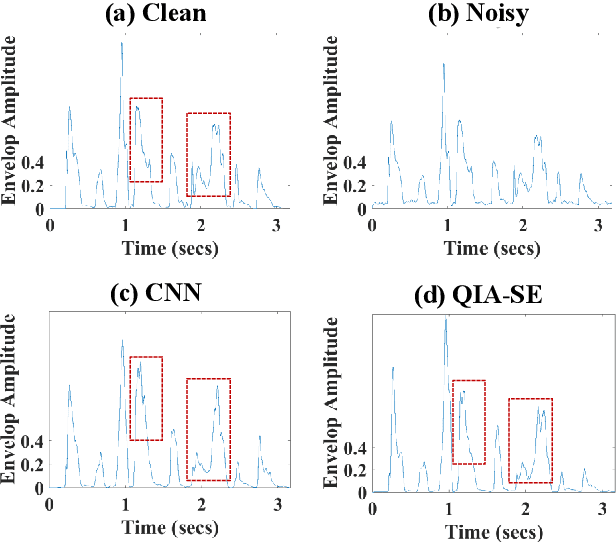
In this study, we propose a cross-domain multi-objective speech assessment model, i.e., the MOSA-Net, which can estimate multiple speech assessment metrics simultaneously. More specifically, the MOSA-Net is designed to estimate speech quality, intelligibility, and distortion assessment scores based on a test speech signal as input. It comprises a convolutional neural network and bidirectional long short-term memory (CNN-BLSTM) architecture for representation extraction, as well as a multiplicative attention layer and a fully-connected layer for each assessment metric. In addition, cross-domain features (spectral and time-domain features) and latent representations from self-supervised learned models are used as inputs to combine rich acoustic information from different speech representations to obtain more accurate assessments. Experimental results reveal that the MOSA-Net can precisely predict perceptual evaluation of speech quality (PESQ), short-time objective intelligibility (STOI), and speech distortion index (SDI) scores when tested on both noisy and enhanced speech utterances under either seen test conditions (where the test speakers and noise types are involved in the training set) or unseen test conditions (where the test speakers and noise types are not involved in the training set). In light of the confirmed prediction capability, we further adopt the latent representations of the MOSA-Net to guide the speech enhancement (SE) process and derive a quality-intelligibility (QI)-aware SE (QIA-SE) approach accordingly. Experimental results show that QIA-SE provides superior enhancement performance compared with the baseline SE system in terms of objective evaluation metrics and qualitative evaluation test.
A Deep Learning Technique using Low Sampling rate for residential Non Intrusive Load Monitoring
Nov 07, 2021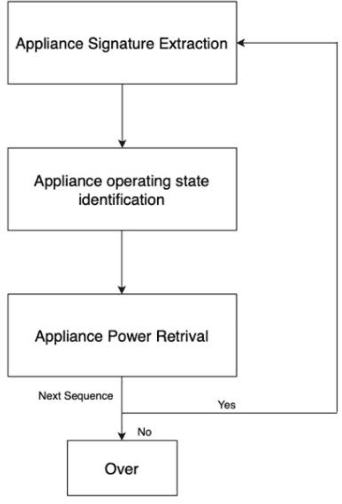
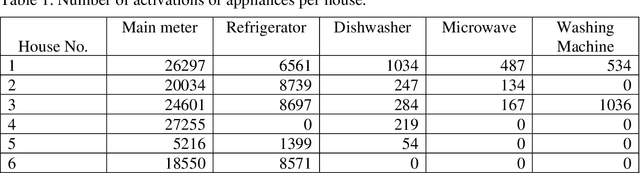


Individual device loads and energy consumption feedback is one of the important approaches for pursuing users to save energy in residences. This can help in identifying faulty devices and wasted energy by devices when left On unused. The main challenge is to identity and estimate the energy consumption of individual devices without intrusive sensors on each device. Non-intrusive load monitoring (NILM) or energy disaggregation, is a blind source separation problem which requires a system to estimate the electricity usage of individual appliances from the aggregated household energy consumption. In this paper, we propose a novel deep neural network-based approach for performing load disaggregation on low frequency power data obtained from residential households. We combine a series of one-dimensional Convolutional Neural Networks and Long Short Term Memory (1D CNN-LSTM) to extract features that can identify active appliances and retrieve their power consumption given the aggregated household power value. We used CNNs to extract features from main readings in a given time frame and then used those features to classify if a given appliance is active at that time period or not. Following that, the extracted features are used to model a generation problem using LSTM. We train the LSTM to generate the disaggregated energy consumption of a particular appliance. Our neural network is capable of generating detailed feedback of demand-side, providing vital insights to the end-user about their electricity consumption. The algorithm was designed for low power offline devices such as ESP32. Empirical calculations show that our model outperforms the state-of-the-art on the Reference Energy Disaggregation Dataset (REDD).
Duality Temporal-channel-frequency Attention Enhanced Speaker Representation Learning
Oct 15, 2021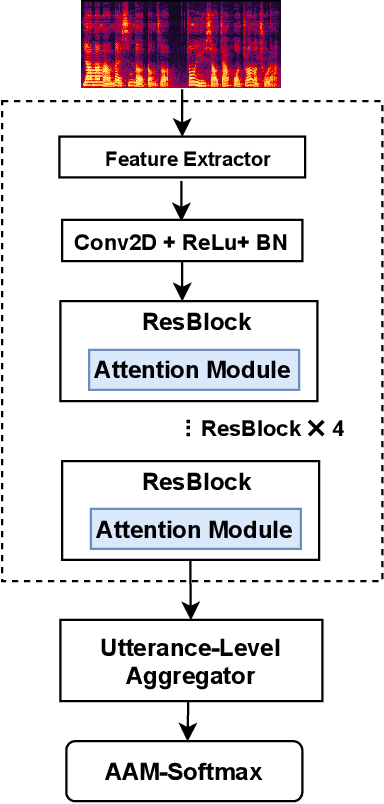
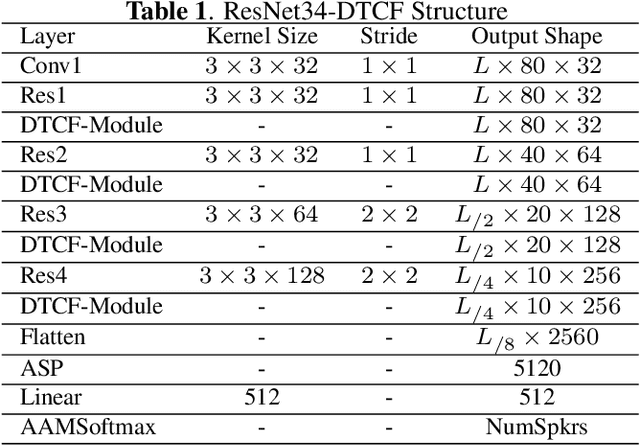
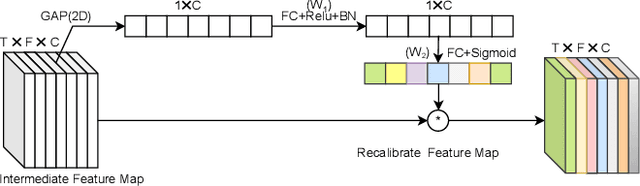
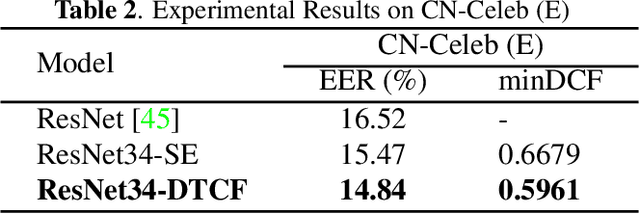
The use of channel-wise attention in CNN based speaker representation networks has achieved remarkable performance in speaker verification (SV). But these approaches do simple averaging on time and frequency feature maps before channel-wise attention learning and ignore the essential mutual interaction among temporal, channel as well as frequency scales. To address this problem, we propose the Duality Temporal-Channel-Frequency (DTCF) attention to re-calibrate the channel-wise features with aggregation of global context on temporal and frequency dimensions. Specifically, the duality attention - time-channel (T-C) attention as well as frequency-channel (F-C) attention - aims to focus on salient regions along the T-C and F-C feature maps that may have more considerable impact on the global context, leading to more discriminative speaker representations. We evaluate the effectiveness of the proposed DTCF attention on the CN-Celeb and VoxCeleb datasets. On the CN-Celeb evaluation set, the EER/minDCF of ResNet34-DTCF are reduced by 0.63%/0.0718 compared with those of ResNet34-SE. On VoxCeleb1-O, VoxCeleb1-E and VoxCeleb1-H evaluation sets, the EER/minDCF of ResNet34-DTCF achieve 0.36%/0.0263, 0.39%/0.0382 and 0.74%/0.0753 reductions compared with those of ResNet34-SE.
Hierarchical Graph-Convolutional Variational AutoEncoding for Generative Modelling of Human Motion
Nov 29, 2021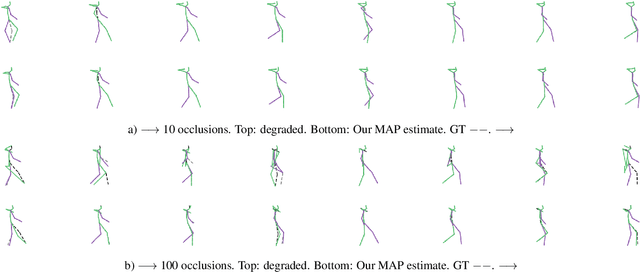
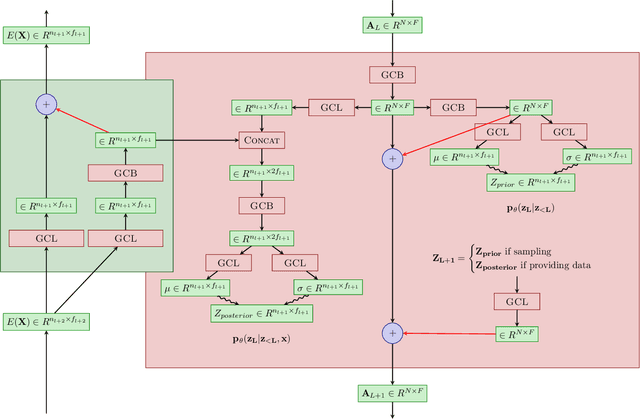
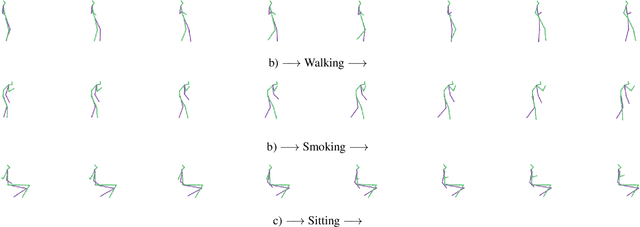
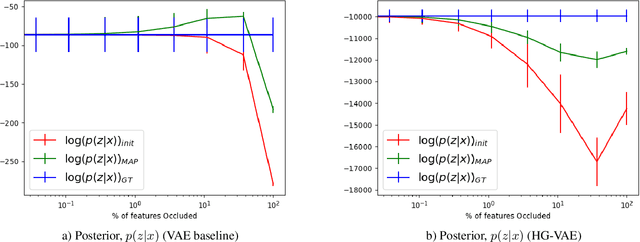
Models of human motion commonly focus either on trajectory prediction or action classification but rarely both. The marked heterogeneity and intricate compositionality of human motion render each task vulnerable to the data degradation and distributional shift common to real-world scenarios. A sufficiently expressive generative model of action could in theory enable data conditioning and distributional resilience within a unified framework applicable to both tasks. Here we propose a novel architecture based on hierarchical variational autoencoders and deep graph convolutional neural networks for generating a holistic model of action over multiple time-scales. We show this Hierarchical Graph-convolutional Variational Autoencoder (HG-VAE) to be capable of generating coherent actions, detecting out-of-distribution data, and imputing missing data by gradient ascent on the model's posterior. Trained and evaluated on H3.6M and the largest collection of open source human motion data, AMASS, we show HG-VAE can facilitate downstream discriminative learning better than baseline models.
UFPMP-Det: Toward Accurate and Efficient Object Detection on Drone Imagery
Dec 20, 2021
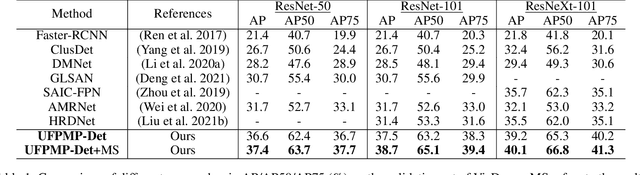
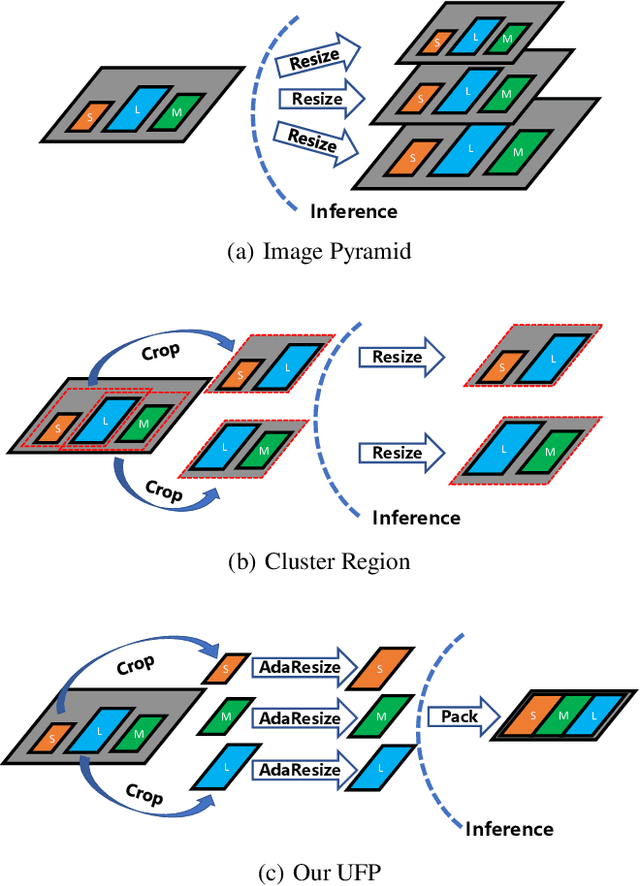
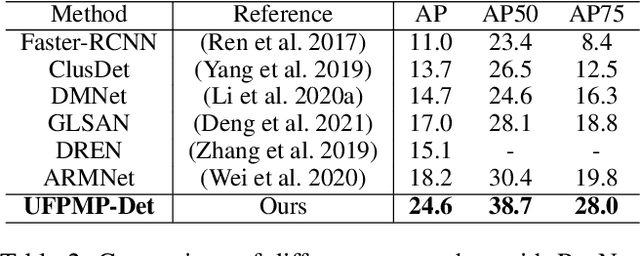
This paper proposes a novel approach to object detection on drone imagery, namely Multi-Proxy Detection Network with Unified Foreground Packing (UFPMP-Det). To deal with the numerous instances of very small scales, different from the common solution that divides the high-resolution input image into quite a number of chips with low foreground ratios to perform detection on them each, the Unified Foreground Packing (UFP) module is designed, where the sub-regions given by a coarse detector are initially merged through clustering to suppress background and the resulting ones are subsequently packed into a mosaic for a single inference, thus significantly reducing overall time cost. Furthermore, to address the more serious confusion between inter-class similarities and intra-class variations of instances, which deteriorates detection performance but is rarely discussed, the Multi-Proxy Detection Network (MP-Det) is presented to model object distributions in a fine-grained manner by employing multiple proxy learning, and the proxies are enforced to be diverse by minimizing a Bag-of-Instance-Words (BoIW) guided optimal transport loss. By such means, UFPMP-Det largely promotes both the detection accuracy and efficiency. Extensive experiments are carried out on the widely used VisDrone and UAVDT datasets, and UFPMP-Det reports new state-of-the-art scores at a much higher speed, highlighting its advantages.
Expert and Crowd-Guided Affect Annotation and Prediction
Dec 15, 2021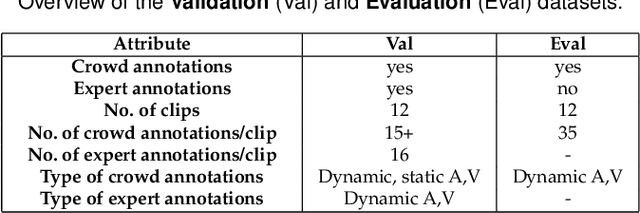
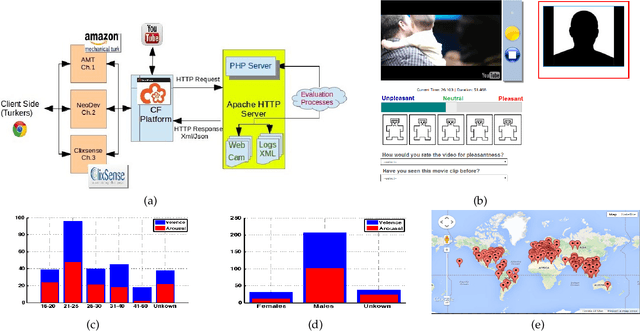

We employ crowdsourcing to acquire time-continuous affective annotations for movie clips, and refine noisy models trained from these crowd annotations incorporating expert information within a Multi-task Learning (MTL) framework. We propose a novel \textbf{e}xpert \textbf{g}uided MTL (EG-MTL) algorithm, which minimizes the loss with respect to both crowd and expert labels to learn a set of weights corresponding to each movie clip for which crowd annotations are acquired. We employ EG-MTL to solve two problems, namely, \textbf{\texttt{P1}}: where dynamic annotations acquired from both experts and crowdworkers for the \textbf{Validation} set are used to train a regression model with audio-visual clip descriptors as features, and predict dynamic arousal and valence levels on 5--15 second snippets derived from the clips; and \textbf{\texttt{P2}}: where a classification model trained on the \textbf{Validation} set using dynamic crowd and expert annotations (as features) and static affective clip labels is used for binary emotion recognition on the \textbf{Evaluation} set for which only dynamic crowd annotations are available. Observed experimental results confirm the effectiveness of the EG-MTL algorithm, which is reflected via improved arousal and valence estimation for \textbf{\texttt{P1}}, and higher recognition accuracy for \textbf{\texttt{P2}}.
Image Segmentation to Identify Safe Landing Zones for Unmanned Aerial Vehicles
Nov 29, 2021

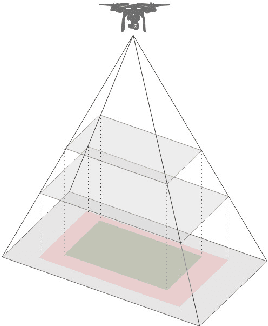
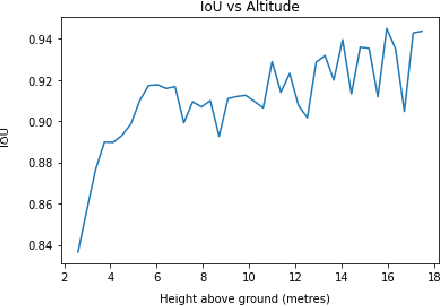
There is a marked increase in delivery services in urban areas, and with Jeff Bezos claiming that 86% of the orders that Amazon ships weigh less than 5 lbs, the time is ripe for investigation into economical methods of automating the final stage of the delivery process. With the advent of semi-autonomous drone delivery services, such as Irish startup `Manna', and Malta's `Skymax', the final step of the delivery journey remains the most difficult to automate. This paper investigates the use of simple images captured by a single RGB camera on a UAV to distinguish between safe and unsafe landing zones. We investigate semantic image segmentation frameworks as a way to identify safe landing zones and demonstrate the accuracy of lightweight models that minimise the number of sensors needed. By working with images rather than video we reduce the amount of energy needed to identify safe landing zones for a drone, without the need for human intervention.
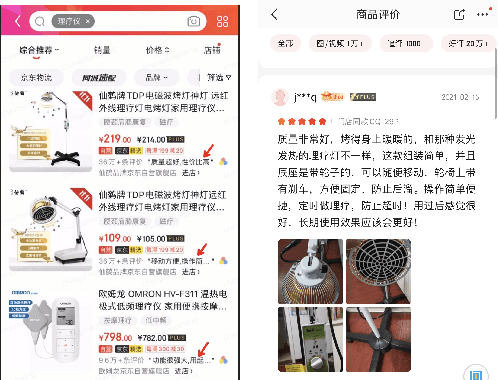
Automatic Product Copywriting for E-Commerce
Dec 15, 2021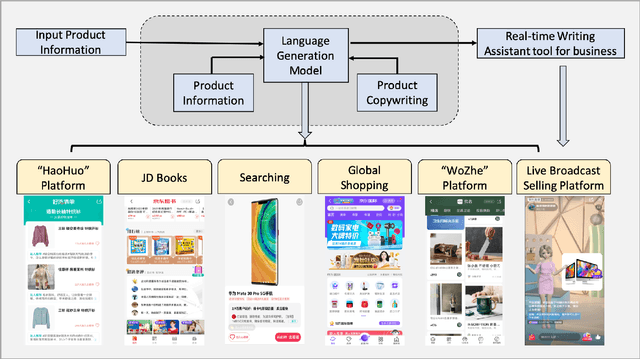

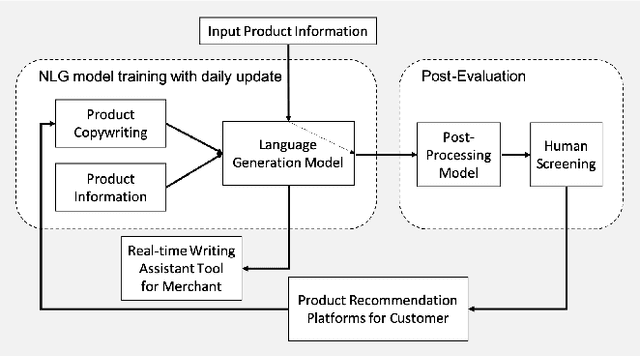
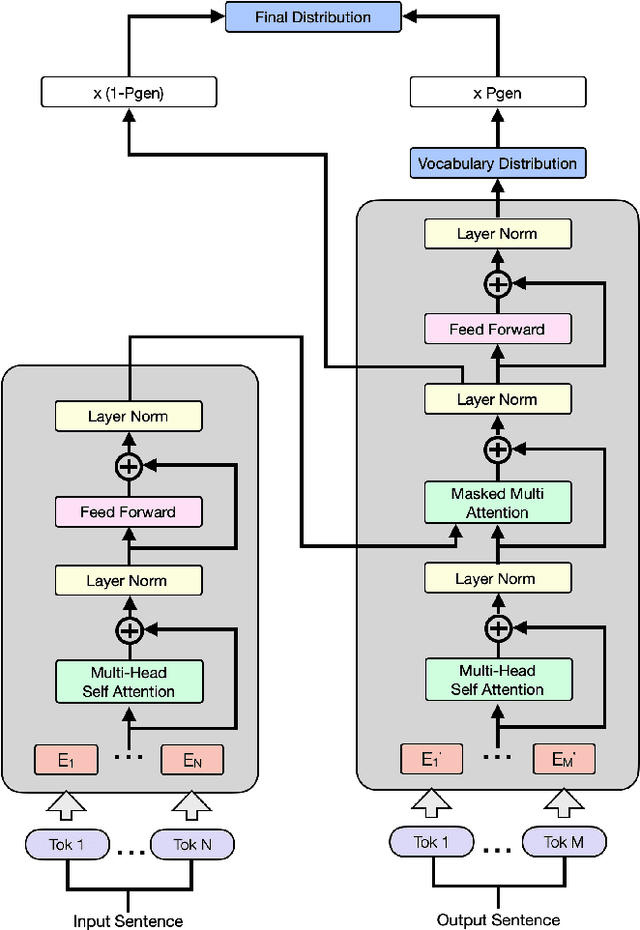
Product copywriting is a critical component of e-commerce recommendation platforms. It aims to attract users' interest and improve user experience by highlighting product characteristics with textual descriptions. In this paper, we report our experience deploying the proposed Automatic Product Copywriting Generation (APCG) system into the JD.com e-commerce product recommendation platform. It consists of two main components: 1) natural language generation, which is built from a transformer-pointer network and a pre-trained sequence-to-sequence model based on millions of training data from our in-house platform; and 2) copywriting quality control, which is based on both automatic evaluation and human screening. For selected domains, the models are trained and updated daily with the updated training data. In addition, the model is also used as a real-time writing assistant tool on our live broadcast platform. The APCG system has been deployed in JD.com since Feb 2021. By Sep 2021, it has generated 2.53 million product descriptions, and improved the overall averaged click-through rate (CTR) and the Conversion Rate (CVR) by 4.22% and 3.61%, compared to baselines, respectively on a year-on-year basis. The accumulated Gross Merchandise Volume (GMV) made by our system is improved by 213.42%, compared to the number in Feb 2021.
DSGPT: Domain-Specific Generative Pre-Training of Transformers for Text Generation in E-commerce Title and Review Summarization
Dec 15, 2021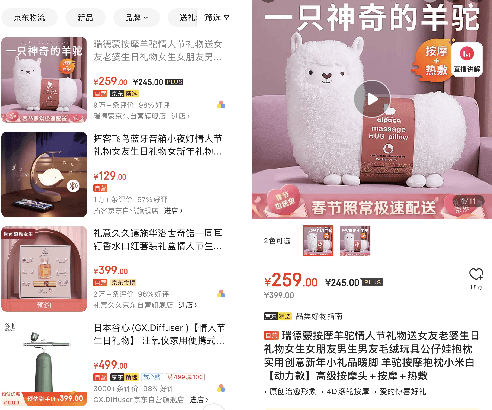
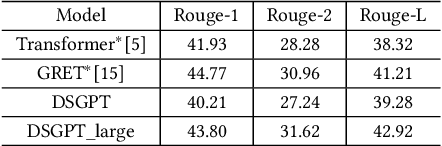
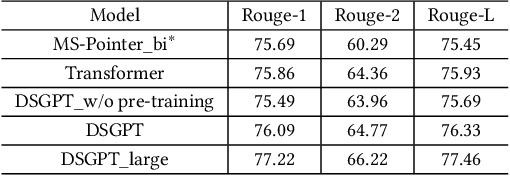
We propose a novel domain-specific generative pre-training (DS-GPT) method for text generation and apply it to the product titleand review summarization problems on E-commerce mobile display.First, we adopt a decoder-only transformer architecture, which fitswell for fine-tuning tasks by combining input and output all to-gether. Second, we demonstrate utilizing only small amount of pre-training data in related domains is powerful. Pre-training a languagemodel from a general corpus such as Wikipedia or the CommonCrawl requires tremendous time and resource commitment, andcan be wasteful if the downstream tasks are limited in variety. OurDSGPT is pre-trained on a limited dataset, the Chinese short textsummarization dataset (LCSTS). Third, our model does not requireproduct-related human-labeled data. For title summarization task,the state of art explicitly uses additional background knowledgein training and predicting stages. In contrast, our model implic-itly captures this knowledge and achieves significant improvementover other methods, after fine-tuning on the public Taobao.comdataset. For review summarization task, we utilize JD.com in-housedataset, and observe similar improvement over standard machinetranslation methods which lack the flexibility of fine-tuning. Ourproposed work can be simply extended to other domains for a widerange of text generation tasks.