 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Leveraging Experience in Lifelong Multi-Agent Pathfinding
Feb 09, 2022
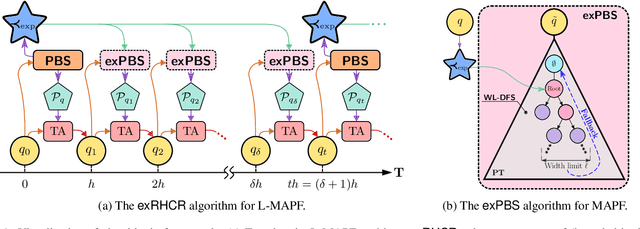
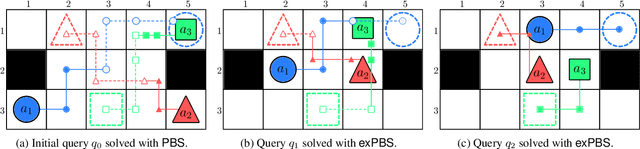
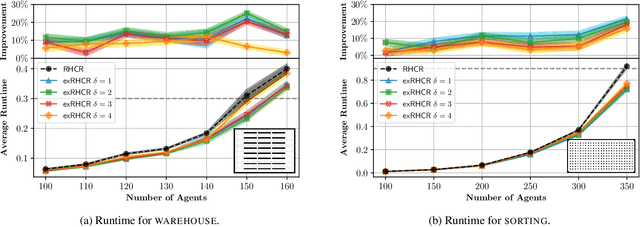
In Lifelong Multi-Agent Path Finding (L-MAPF) a team of agents performs a stream of tasks consisting of multiple locations to be visited by the agents on a shared graph while avoiding collisions with one another. L-MAPF is typically tackled by partitioning it into multiple consecutive, and hence similar, "one-shot" MAPF queries with a single task assigned to each agent, as in the Rolling-Horizon Collision Resolution (RHCR) algorithm. Thus, a solution to one query informs the next query, which leads to similarity with respect to the agents' start and goal positions, and how collisions need to be resolved from one query to the next. Thus, experience from solving one MAPF query can potentially be used to speedup solving the next one. Despite this intuition, current L-MAPF planners solve consecutive MAPF queries from scratch. In this paper, we introduce a new RHCR-inspired approach called exRHCR, which exploits experience in its constituent MAPF queries. In particular, exRHCR employs a new extension of Priority-Based Search (PBS), a state-of-the-art MAPF solver. Our extension, called exPBS, allows to warm-start the search with the priorities between agents used by PBS in the previous MAPF instances. We demonstrate empirically that exRHCR solves L-MAPF up to 25% faster than RHCR, and allows to increase throughput for given task streams by as much as 3%-16% by increasing the number of agents we can cope with for a given time budget.
A Sensorless Control System for an Implantable Heart Pump using a Real-time Deep Convolutional Neural Network
Apr 30, 2021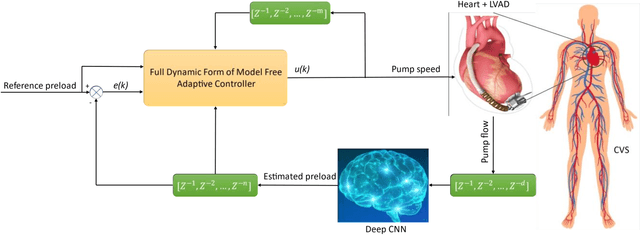
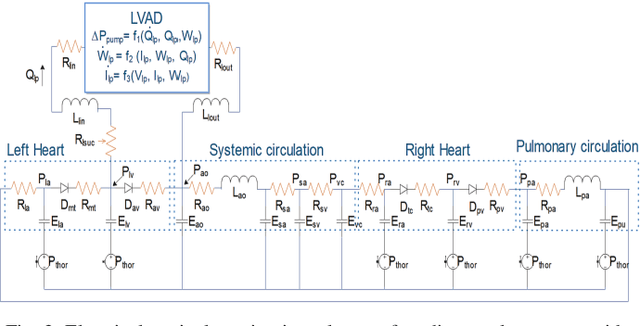
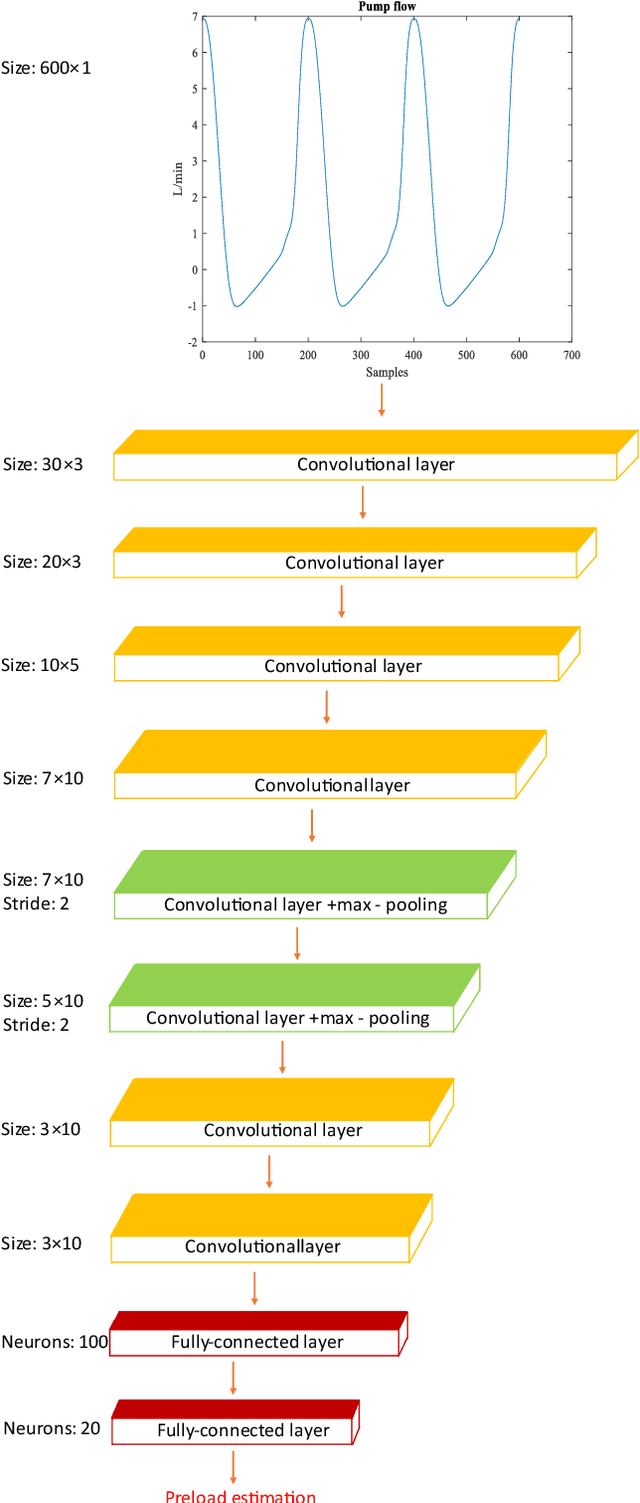
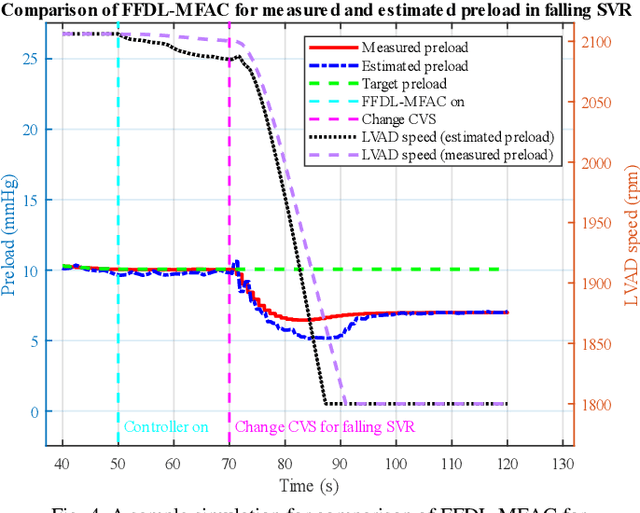
Left ventricular assist devices (LVADs) are mechanical pumps, which can be used to support heart failure (HF) patients as bridge to transplant and destination therapy. To automatically adjust the LVAD speed, a physiological control system needs to be designed to respond to variations of patient hemodynamics across a variety of clinical scenarios. These control systems require pressure feedback signals from the cardiovascular system. However, there are no suitable long-term implantable sensors available. In this study, a novel real-time deep convolutional neural network (CNN) for estimation of preload based on the LVAD flow was proposed. A new sensorless adaptive physiological control system for an LVAD pump was developed using the full dynamic form of model free adaptive control (FFDL-MFAC) and the proposed preload estimator to maintain the patient conditions in safe physiological ranges. The CNN model for preload estimation was trained and evaluated through 10-fold cross validation on 100 different patient conditions and the proposed sensorless control system was assessed on a new testing set of 30 different patient conditions across six different patient scenarios. The proposed preload estimator was extremely accurate with a correlation coefficient of 0.97, root mean squared error of 0.84 mmHg, reproducibility coefficient of 1.56 mmHg, coefficient of variation of 14.44 %, and bias of 0.29 mmHg for the testing dataset. The results also indicate that the proposed sensorless physiological controller works similarly to the preload-based physiological control system for LVAD using measured preload to prevent ventricular suction and pulmonary congestion. This study shows that the LVADs can respond appropriately to changing patient states and physiological demands without the need for additional pressure or flow measurements.
Consolidated learning -- a domain-specific model-free optimization strategy with examples for XGBoost and MIMIC-IV
Jan 27, 2022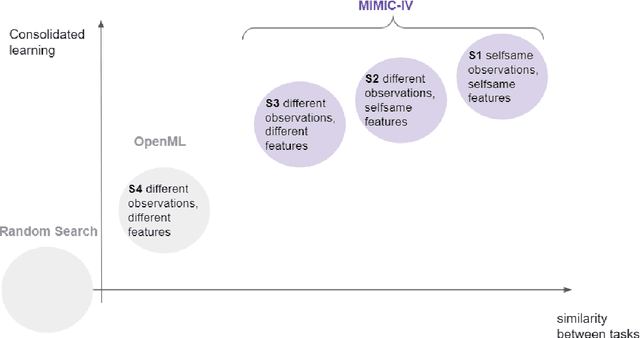
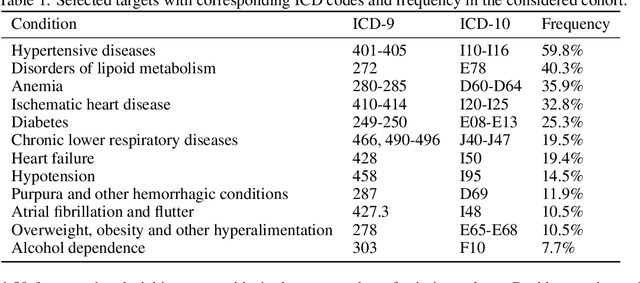
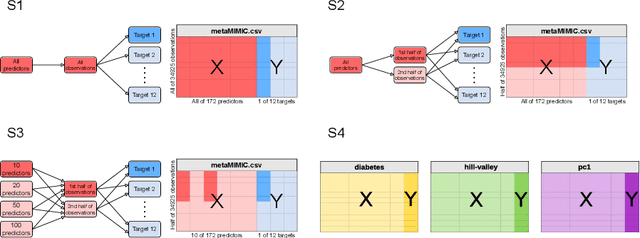
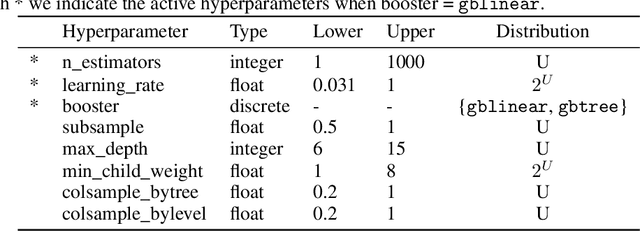
For many machine learning models, a choice of hyperparameters is a crucial step towards achieving high performance. Prevalent meta-learning approaches focus on obtaining good hyperparameters configurations with a limited computational budget for a completely new task based on the results obtained from the prior tasks. This paper proposes a new formulation of the tuning problem, called consolidated learning, more suited to practical challenges faced by model developers, in which a large number of predictive models are created on similar data sets. In such settings, we are interested in the total optimization time rather than tuning for a single task. We show that a carefully selected static portfolio of hyperparameters yields good results for anytime optimization, maintaining ease of use and implementation. Moreover, we point out how to construct such a portfolio for specific domains. The improvement in the optimization is possible due to more efficient transfer of hyperparameter configurations between similar tasks. We demonstrate the effectiveness of this approach through an empirical study for XGBoost algorithm and the collection of predictive tasks extracted from the MIMIC-IV medical database; however, consolidated learning is applicable in many others fields.
Reconstruct Anomaly to Normal: Adversarial Learned and Latent Vector-constrained Autoencoder for Time-series Anomaly Detection
Oct 14, 2020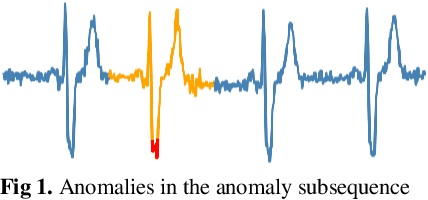
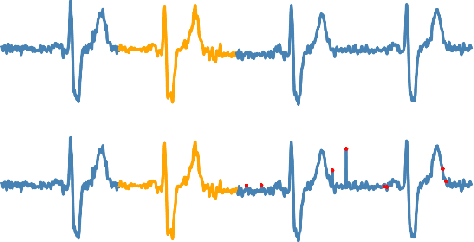
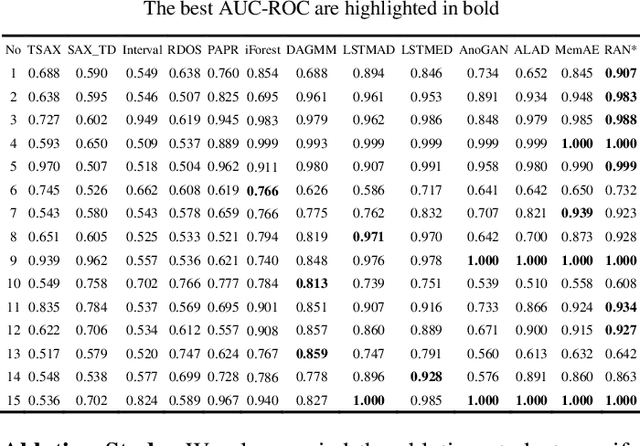
Anomaly detection in time series has been widely researched and has important practical applications. In recent years, anomaly detection algorithms are mostly based on deep-learning generative models and use the reconstruction error to detect anomalies. They try to capture the distribution of normal data by reconstructing normal data in the training phase, then calculate the reconstruction error of test data to do anomaly detection. However, most of them only use the normal data in the training phase and can not ensure the reconstruction process of anomaly data. So, anomaly data can also be well reconstructed sometimes and gets low reconstruction error, which leads to the omission of anomalies. What's more, the neighbor information of data points in time series data has not been fully utilized in these algorithms. In this paper, we propose RAN based on the idea of Reconstruct Anomalies to Normal and apply it for unsupervised time series anomaly detection. To minimize the reconstruction error of normal data and maximize this of anomaly data, we do not just ensure normal data to reconstruct well, but also try to make the reconstruction of anomaly data consistent with the distribution of normal data, then anomalies will get higher reconstruction errors. We implement this idea by introducing the "imitated anomaly data" and combining a specially designed latent vector-constrained Autoencoder with the discriminator to construct an adversary network. Extensive experiments on time-series datasets from different scenes such as ECG diagnosis also show that RAN can detect meaningful anomalies, and it outperforms other algorithms in terms of AUC-ROC.
Control of a Soft Robotic Arm Using a Piecewise Universal Joint Model
Jan 05, 2022
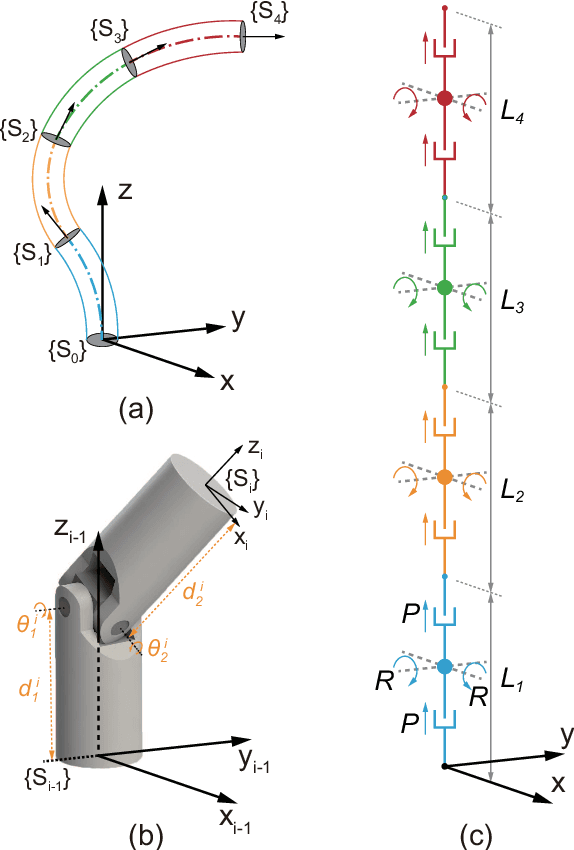


The 'infinite' passive degrees of freedom of soft robotic arms render their control especially challenging. In this paper, we leverage a previously developed model, which drawing equivalence of the soft arm to a series of universal joints, to design two closed-loop controllers: a configuration space controller for trajectory tracking and a task space controller for position control of the end effector. Extensive experiments and simulations on a four-segment soft arm attest to substantial improvement in terms of: a) superior tracking accuracy of the configuration space controller and b) reduced settling time and steady-state error of the task space controller. The task space controller is also verified to be effective in the presence of interactions between the soft arm and the environment.
Efficient Data-Plane Memory Scheduling for In-Network Aggregation
Jan 17, 2022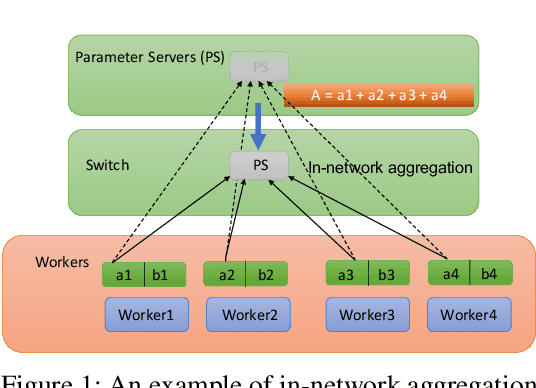

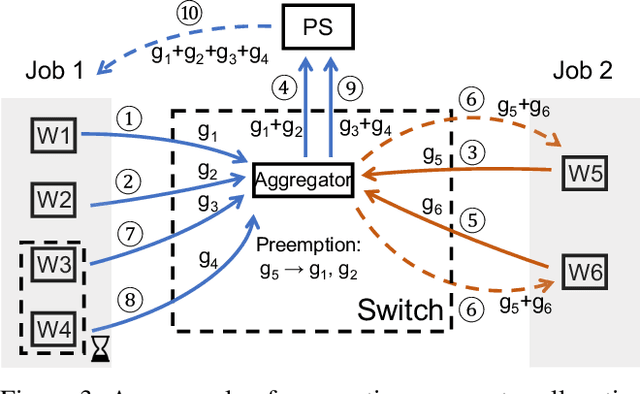
As the scale of distributed training grows, communication becomes a bottleneck. To accelerate the communication, recent works introduce In-Network Aggregation (INA), which moves the gradients summation into network middle-boxes, e.g., programmable switches to reduce the traffic volume. However, switch memory is scarce compared to the volume of gradients transmitted in distributed training. Although literature applies methods like pool-based streaming or dynamic sharing to tackle the mismatch, switch memory is still a potential performance bottleneck. Furthermore, we observe the under-utilization of switch memory due to the synchronization requirement for aggregator deallocation in recent works. To improve the switch memory utilization, we propose ESA, an $\underline{E}$fficient Switch Memory $\underline{S}$cheduler for In-Network $\underline{A}$ggregation. At its cores, ESA enforces the preemptive aggregator allocation primitive and introduces priority scheduling at the data-plane, which improves the switch memory utilization and average job completion time (JCT). Experiments show that ESA can improve the average JCT by up to $1.35\times$.
Relaxed Weight Sharing: Effectively Modeling Time-Varying Relationships in Clinical Time-Series
Jun 07, 2019
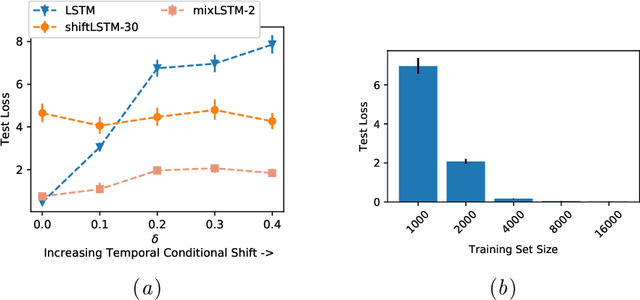
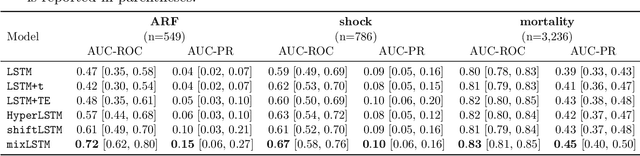
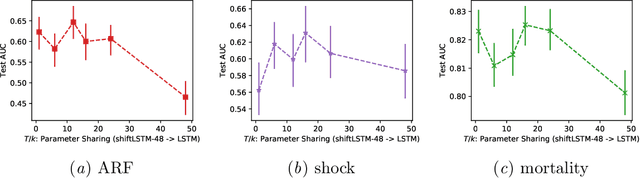
Recurrent neural networks (RNNs) are commonly applied to clinical time-series data with the goal of learning patient risk stratification models. Their effectiveness is due, in part, to their use of parameter sharing over time (i.e., cells are repeated hence the name recurrent). We hypothesize, however, that this trait also contributes to the increased difficulty such models have with learning relationships that change over time. Conditional shift, i.e., changes in the relationship between the input X and the output y, arises if the risk factors for the event of interest change over the course of a patient admission. While in theory, RNNs and gated RNNs (e.g., LSTMs) in particular should be capable of learning time-varying relationships, when training data are limited, such models often fail to accurately capture these dynamics. We illustrate the advantages and disadvantages of complete weight sharing (RNNs) by comparing an LSTM with shared parameters to a sequential architecture with time-varying parameters on three clinically-relevant prediction tasks: acute respiratory failure (ARF), shock, and in-hospital mortality. In experiments using synthetic data, we demonstrate how weight sharing in LSTMs leads to worse performance in the presence of conditional shift. To improve upon the dichotomy between complete weight sharing vs. no weight sharing, we propose a novel RNN formulation based on a mixture model in which we relax weight sharing over time. The proposed method outperforms standard LSTMs and other state-of-the-art baselines across all tasks. In settings with limited data, relaxed weight sharing can lead to improved patient risk stratification performance.
Anomaly Detection And Classification In Time Series With Kervolutional Neural Networks
May 14, 2020

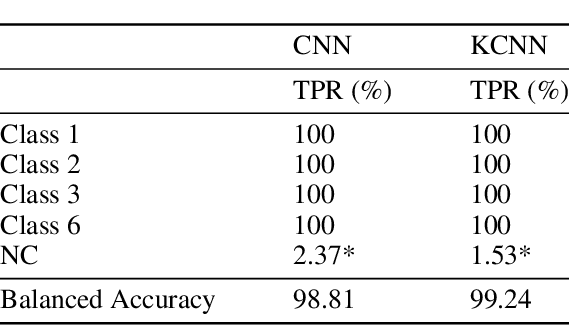
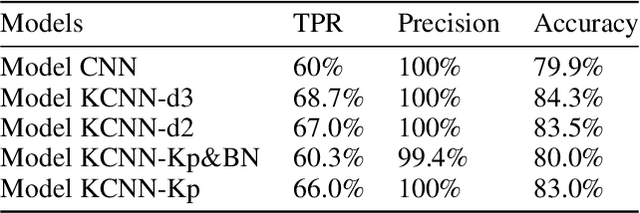
Recently, with the development of deep learning, end-to-end neural network architectures have been increasingly applied to condition monitoring signals. They have demonstrated superior performance for fault detection and classification, in particular using convolutional neural networks. Even more recently, an extension of the concept of convolution to the concept of kervolution has been proposed with some promising results in image classification tasks. In this paper, we explore the potential of kervolutional neural networks applied to time series data. We demonstrate that using a mixture of convolutional and kervolutional layers improves the model performance. The mixed model is first applied to a classification task in time series, as a benchmark dataset. Subsequently, the proposed mixed architecture is used to detect anomalies in time series data recorded by accelerometers on helicopters. We propose a residual-based anomaly detection approach using a temporal auto-encoder. We demonstrate that mixing kervolutional with convolutional layers in the encoder is more sensitive to variations in the input data and is able to detect anomalous time series in a better way.
Interpretable Real-Time Win Prediction for Honor of Kings, a Popular Mobile MOBA Esport
Sep 04, 2020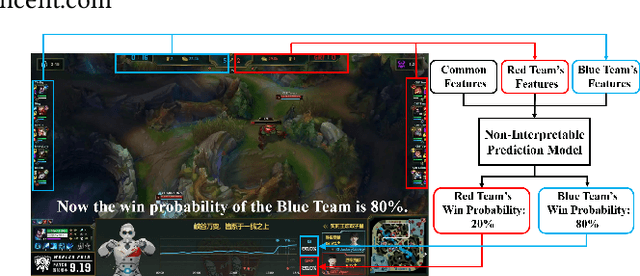

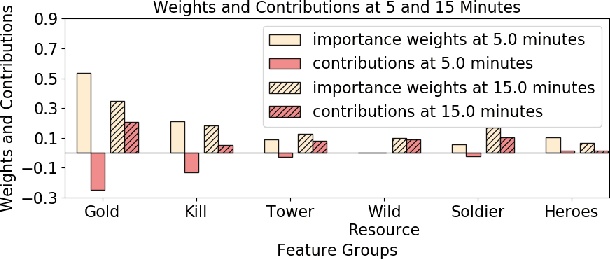
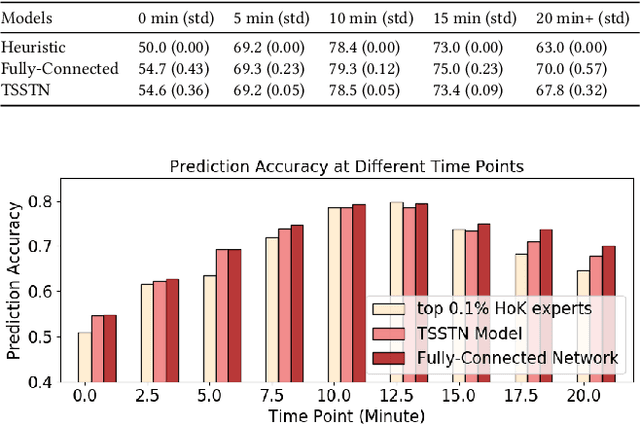
With the rapid prevalence and explosive development of MOBA esports (Multiplayer Online Battle Arena electronic sports), many research efforts have been devoted to automatically predicting the game results (win predictions). While this task has great potential in various applications such as esports live streaming and game commentator AI systems, previous studies suffer from two major limitations: 1) insufficient real-time input features and high-quality training data; 2) non-interpretable inference processes of the black-box prediction models. To mitigate these issues, we collect and release a large-scale dataset that contains real-time game records with rich input features of the popular MOBA game Honor of Kings. For interpretable predictions, we propose a Two-Stage Spatial-Temporal Network (TSSTN) that can not only provide accurate real-time win predictions but also attribute the ultimate prediction results to the contributions of different features for interpretability. Experiment results and applications in real-world live streaming scenarios show that the proposed TSSTN model is effective both in prediction accuracy and interpretability.
Hallucinated Neural Radiance Fields in the Wild
Dec 01, 2021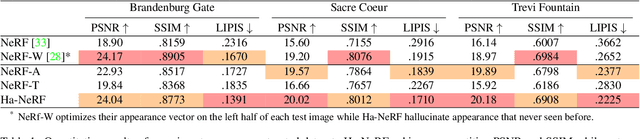
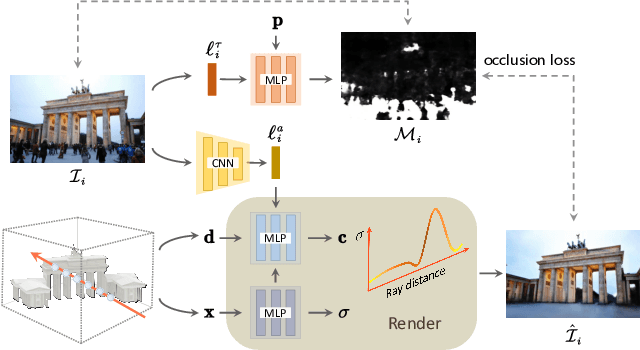
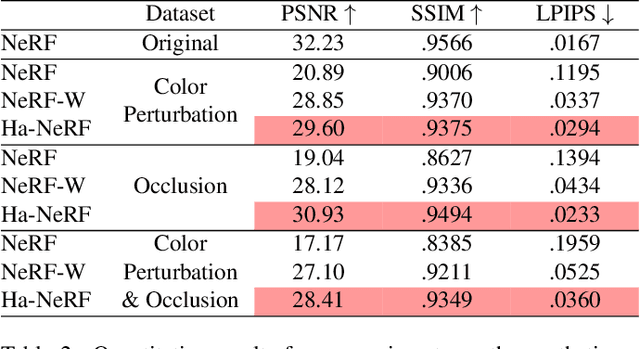
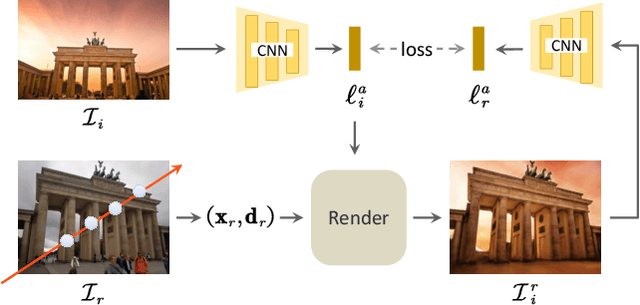
Neural Radiance Fields (NeRF) has recently gained popularity for its impressive novel view synthesis ability. This paper studies the problem of hallucinated NeRF: i.e. recovering a realistic NeRF at a different time of day from a group of tourism images. Existing solutions adopt NeRF with a controllable appearance embedding to render novel views under various conditions, but cannot render view-consistent images with an unseen appearance. To solve this problem, we present an end-to-end framework for constructing a hallucinated NeRF, dubbed as Ha-NeRF. Specifically, we propose an appearance hallucination module to handle time-varying appearances and transfer them to novel views. Considering the complex occlusions of tourism images, an anti-occlusion module is introduced to decompose the static subjects for visibility accurately. Experimental results on synthetic data and real tourism photo collections demonstrate that our method can not only hallucinate the desired appearances, but also render occlusion-free images from different views. The project and supplementary materials are available at https://rover-xingyu.github.io/Ha-NeRF/.