 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcademiClaw: When Students Set Challenges for AI Agents
May 04, 2026Benchmarks within the OpenClaw ecosystem have thus far evaluated exclusively assistant-level tasks, leaving the academic-level capabilities of OpenClaw largely unexamined. We introduce AcademiClaw, a bilingual benchmark of 80 complex, long-horizon tasks sourced directly from university students' real academic workflows -- homework, research projects, competitions, and personal projects -- that they found current AI agents unable to solve effectively. Curated from 230 student-submitted candidates through rigorous expert review, the final task set spans 25+ professional domains, ranging from olympiad-level mathematics and linguistics problems to GPU-intensive reinforcement learning and full-stack system debugging, with 16 tasks requiring CUDA GPU execution. Each task executes in an isolated Docker sandbox and is scored on task completion by multi-dimensional rubrics combining six complementary techniques, with an independent five-category safety audit providing additional behavioral analysis. Experiments on six frontier models show that even the best achieves only a 55\% pass rate. Further analysis uncovers sharp capability boundaries across task domains, divergent behavioral strategies among models, and a disconnect between token consumption and output quality, providing fine-grained diagnostic signals beyond what aggregate metrics reveal. We hope that AcademiClaw and its open-sourced data and code can serve as a useful resource for the OpenClaw community, driving progress toward agents that are more capable and versatile across the full breadth of real-world academic demands. All data and code are available at https://github.com/GAIR-NLP/AcademiClaw.
Efficient Data-Plane Memory Scheduling for In-Network Aggregation
Jan 17, 2022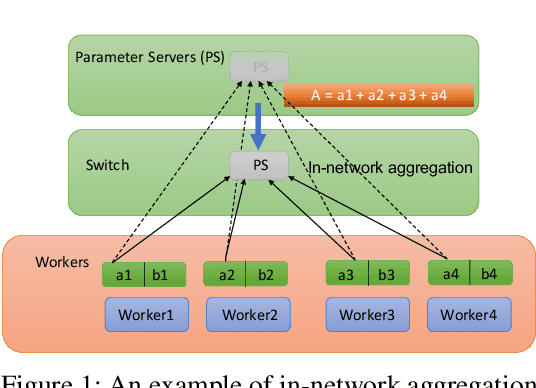

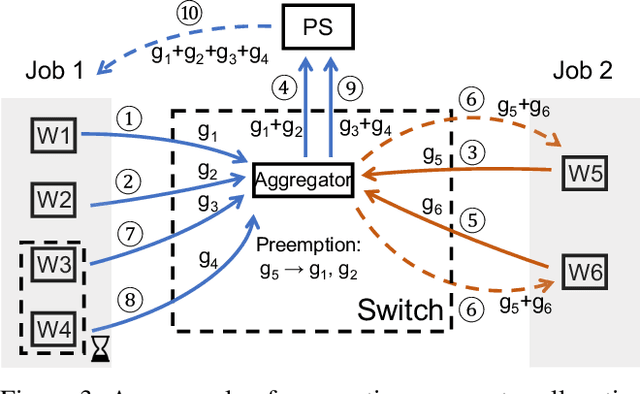
As the scale of distributed training grows, communication becomes a bottleneck. To accelerate the communication, recent works introduce In-Network Aggregation (INA), which moves the gradients summation into network middle-boxes, e.g., programmable switches to reduce the traffic volume. However, switch memory is scarce compared to the volume of gradients transmitted in distributed training. Although literature applies methods like pool-based streaming or dynamic sharing to tackle the mismatch, switch memory is still a potential performance bottleneck. Furthermore, we observe the under-utilization of switch memory due to the synchronization requirement for aggregator deallocation in recent works. To improve the switch memory utilization, we propose ESA, an $\underline{E}$fficient Switch Memory $\underline{S}$cheduler for In-Network $\underline{A}$ggregation. At its cores, ESA enforces the preemptive aggregator allocation primitive and introduces priority scheduling at the data-plane, which improves the switch memory utilization and average job completion time (JCT). Experiments show that ESA can improve the average JCT by up to $1.35\times$.