 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResilient AI Supercomputer Networking using MRC and SRv6
May 05, 2026Tail latency dominates the performance of synchronous pretraining jobs when running at very large scales. We describe a three-pronged approach: (1) a new RDMA-based transport protocol, MRC, sprays across many paths and actively load-balances between them, eliminating the issue of flow collisions (2) the use of multi-plane Clos topologies to get the benefits of high switch radix and redundancy, allowing training clusters well over 100K GPUs to be built as two-tier topologies while increasing physical redundancy, and (3) the use of static source-routing using SRv6 to allow MRC the freedom to bypass failures by itself. We describe our experiences running MRC and static SRv6 routing in production in OpenAI and Microsoft's largest training clusters, where it has been used to train the latest frontier models. We demonstrate how MRC allows AI training jobs to ride out many network failures that previously would have interrupted training.
Efficient Data-Plane Memory Scheduling for In-Network Aggregation
Jan 17, 2022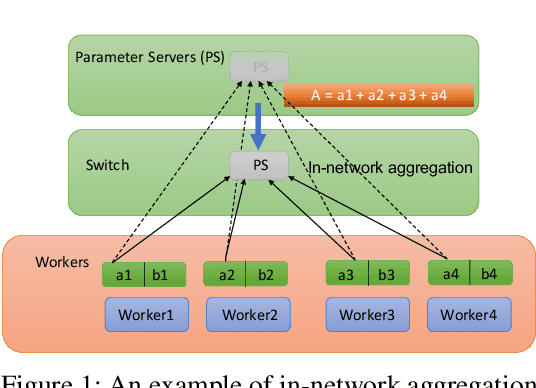

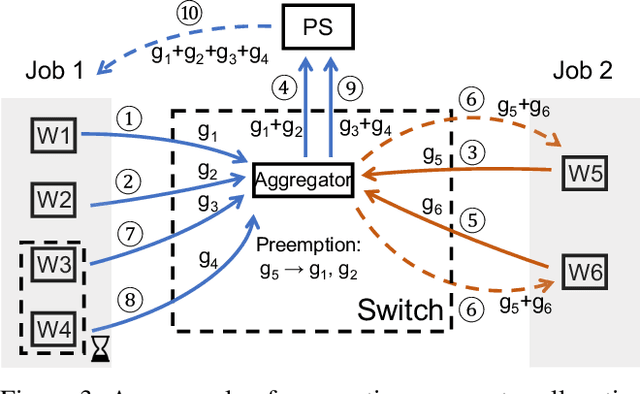
As the scale of distributed training grows, communication becomes a bottleneck. To accelerate the communication, recent works introduce In-Network Aggregation (INA), which moves the gradients summation into network middle-boxes, e.g., programmable switches to reduce the traffic volume. However, switch memory is scarce compared to the volume of gradients transmitted in distributed training. Although literature applies methods like pool-based streaming or dynamic sharing to tackle the mismatch, switch memory is still a potential performance bottleneck. Furthermore, we observe the under-utilization of switch memory due to the synchronization requirement for aggregator deallocation in recent works. To improve the switch memory utilization, we propose ESA, an $\underline{E}$fficient Switch Memory $\underline{S}$cheduler for In-Network $\underline{A}$ggregation. At its cores, ESA enforces the preemptive aggregator allocation primitive and introduces priority scheduling at the data-plane, which improves the switch memory utilization and average job completion time (JCT). Experiments show that ESA can improve the average JCT by up to $1.35\times$.