 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-Agent Deep Reinforcement Learning for Cost- and Delay-Sensitive Virtual Network Function Placement and Routing
Jun 24, 2022
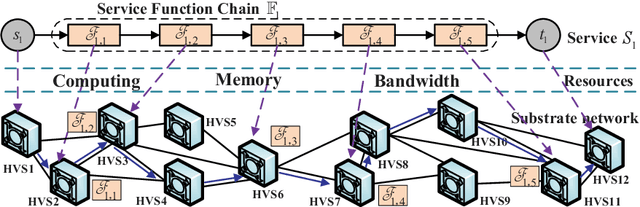
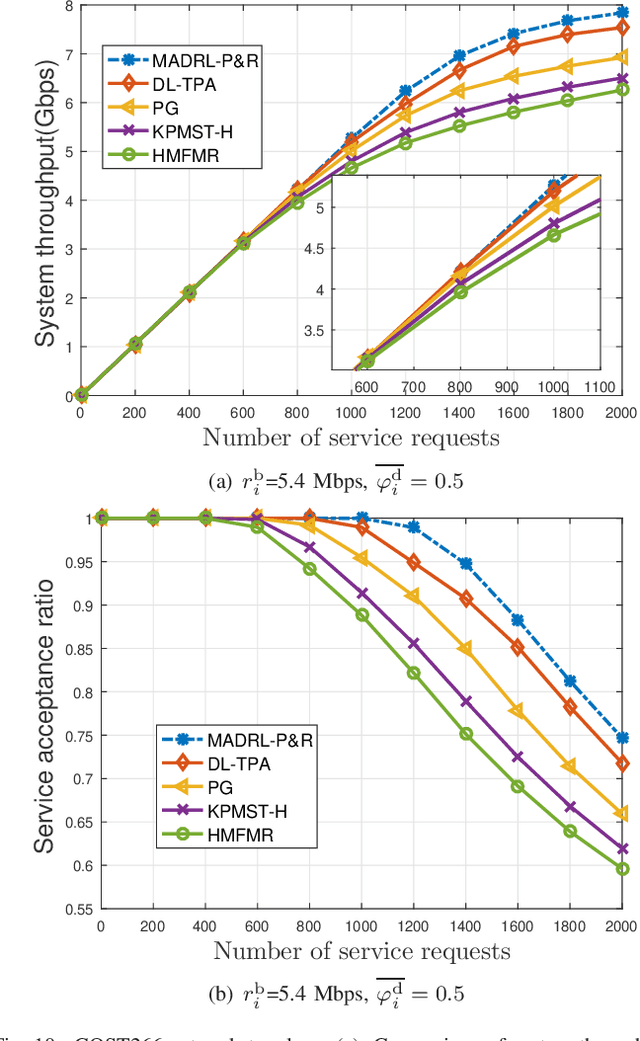
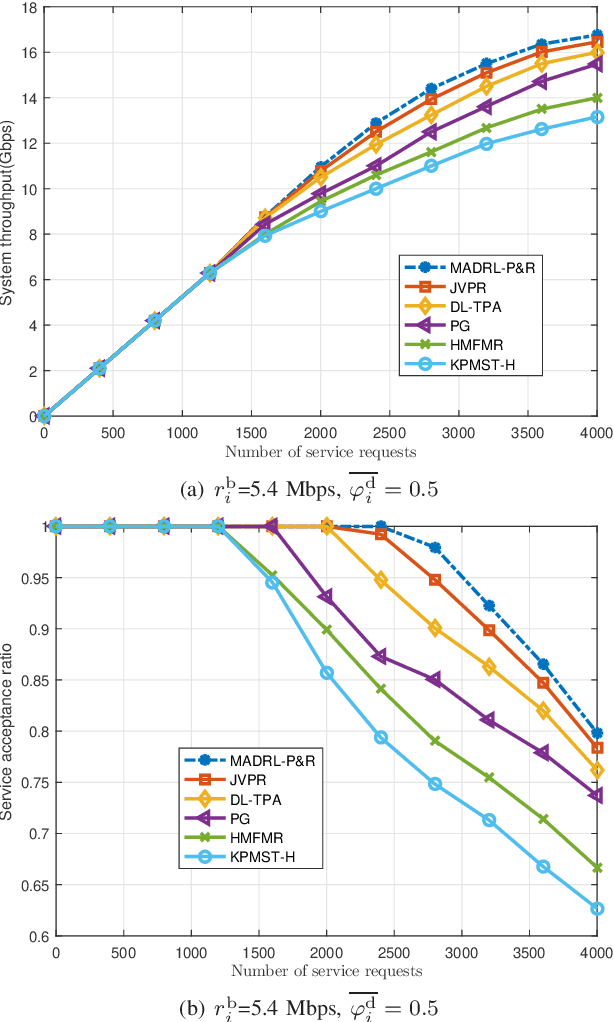
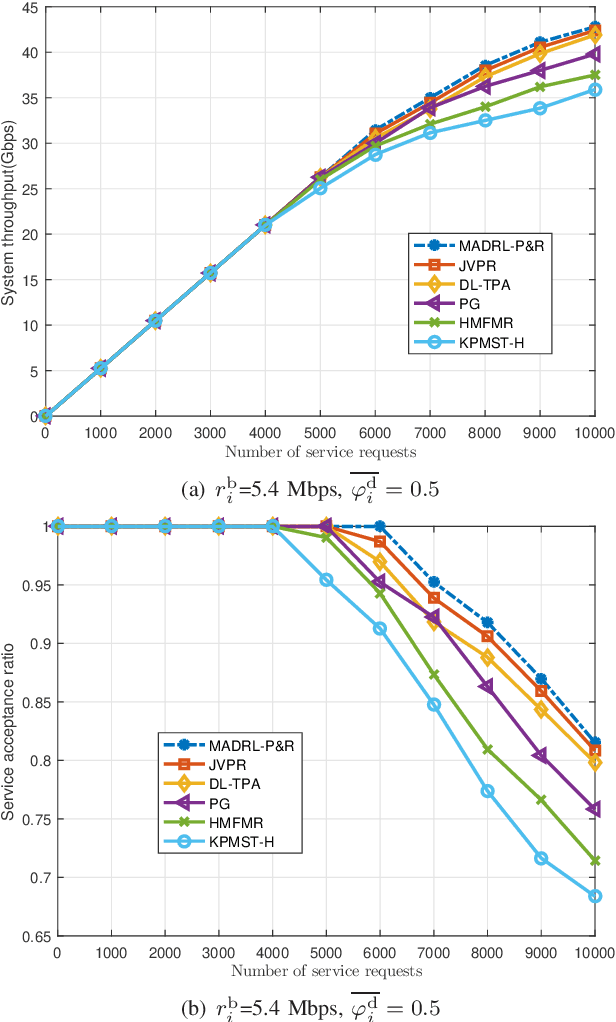
This paper proposes an effective and novel multiagent deep reinforcement learning (MADRL)-based method for solving the joint virtual network function (VNF) placement and routing (P&R), where multiple service requests with differentiated demands are delivered at the same time. The differentiated demands of the service requests are reflected by their delay- and cost-sensitive factors. We first construct a VNF P&R problem to jointly minimize a weighted sum of service delay and resource consumption cost, which is NP-complete. Then, the joint VNF P&R problem is decoupled into two iterative subtasks: placement subtask and routing subtask. Each subtask consists of multiple concurrent parallel sequential decision processes. By invoking the deep deterministic policy gradient method and multi-agent technique, an MADRL-P&R framework is designed to perform the two subtasks. The new joint reward and internal rewards mechanism is proposed to match the goals and constraints of the placement and routing subtasks. We also propose the parameter migration-based model-retraining method to deal with changing network topologies. Corroborated by experiments, the proposed MADRL-P&R framework is superior to its alternatives in terms of service cost and delay, and offers higher flexibility for personalized service demands. The parameter migration-based model-retraining method can efficiently accelerate convergence under moderate network topology changes.
Tracking Urbanization in Developing Regions with Remote Sensing Spatial-Temporal Super-Resolution
Apr 04, 2022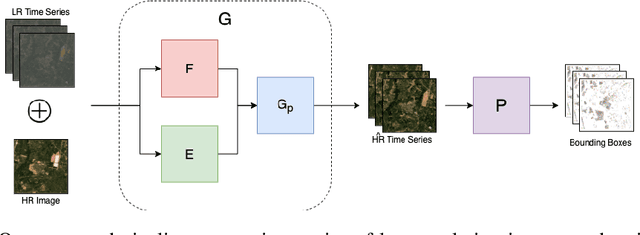
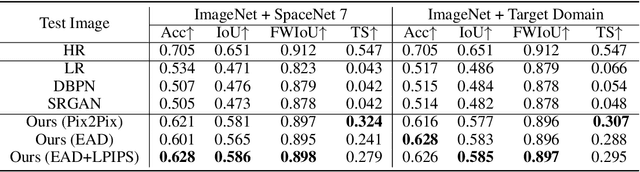

Automated tracking of urban development in areas where construction information is not available became possible with recent advancements in machine learning and remote sensing. Unfortunately, these solutions perform best on high-resolution imagery, which is expensive to acquire and infrequently available, making it difficult to scale over long time spans and across large geographies. In this work, we propose a pipeline that leverages a single high-resolution image and a time series of publicly available low-resolution images to generate accurate high-resolution time series for object tracking in urban construction. Our method achieves significant improvement in comparison to baselines using single image super-resolution, and can assist in extending the accessibility and scalability of building construction tracking across the developing world.
Sort by Structure: Language Model Ranking as Dependency Probing
Jun 10, 2022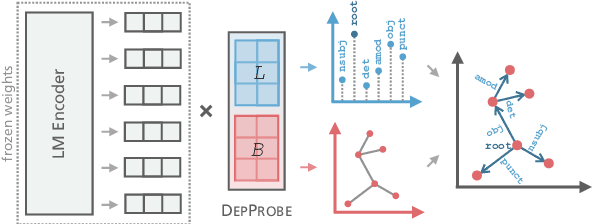
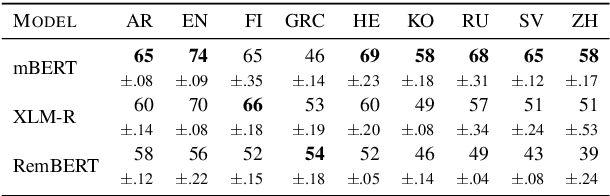
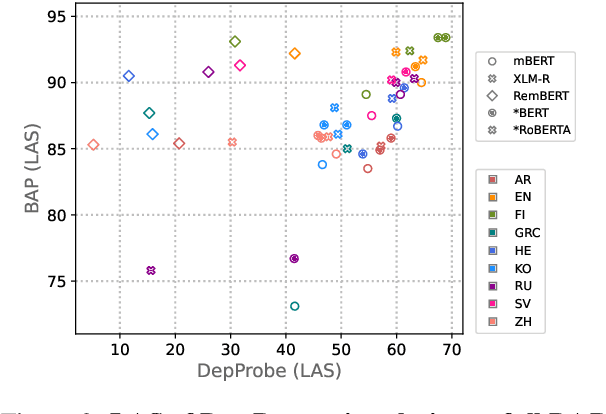
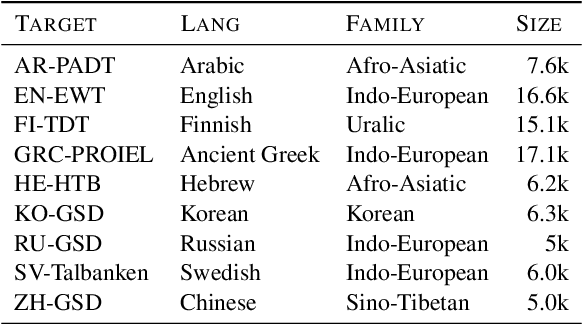
Making an informed choice of pre-trained language model (LM) is critical for performance, yet environmentally costly, and as such widely underexplored. The field of Computer Vision has begun to tackle encoder ranking, with promising forays into Natural Language Processing, however they lack coverage of linguistic tasks such as structured prediction. We propose probing to rank LMs, specifically for parsing dependencies in a given language, by measuring the degree to which labeled trees are recoverable from an LM's contextualized embeddings. Across 46 typologically and architecturally diverse LM-language pairs, our probing approach predicts the best LM choice 79% of the time using orders of magnitude less compute than training a full parser. Within this study, we identify and analyze one recently proposed decoupled LM - RemBERT - and find it strikingly contains less inherent dependency information, but often yields the best parser after full fine-tuning. Without this outlier our approach identifies the best LM in 89% of cases.
Point-Teaching: Weakly Semi-Supervised Object Detection with Point Annotations
Jun 01, 2022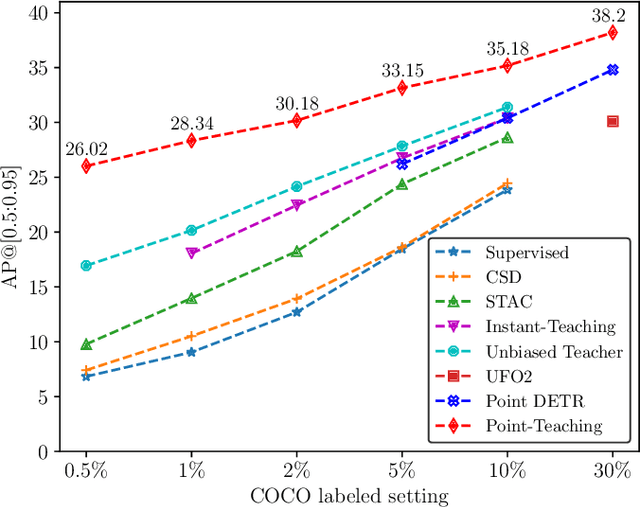
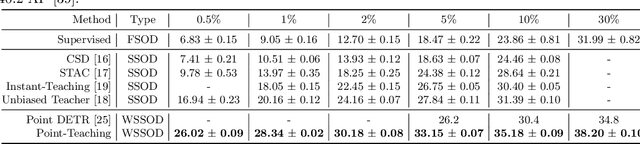
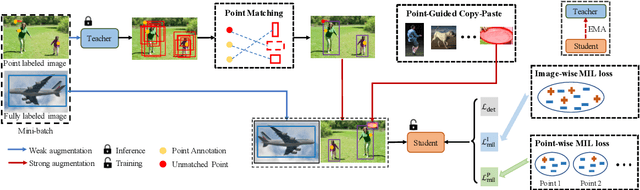

Point annotations are considerably more time-efficient than bounding box annotations. However, how to use cheap point annotations to boost the performance of semi-supervised object detection remains largely unsolved. In this work, we present Point-Teaching, a weakly semi-supervised object detection framework to fully exploit the point annotations. Specifically, we propose a Hungarian-based point matching method to generate pseudo labels for point annotated images. We further propose multiple instance learning (MIL) approaches at the level of images and points to supervise the object detector with point annotations. Finally, we propose a simple-yet-effective data augmentation, termed point-guided copy-paste, to reduce the impact of the unmatched points. Experiments demonstrate the effectiveness of our method on a few datasets and various data regimes.
LORD: Lower-Dimensional Embedding of Log-Signature in Neural Rough Differential Equations
Apr 19, 2022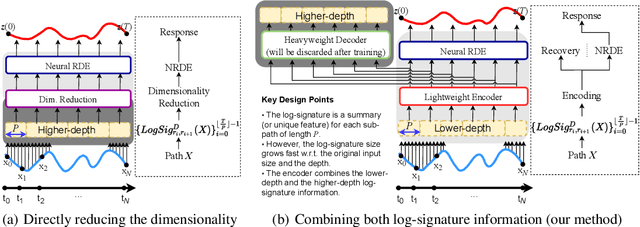

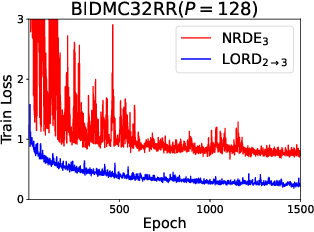
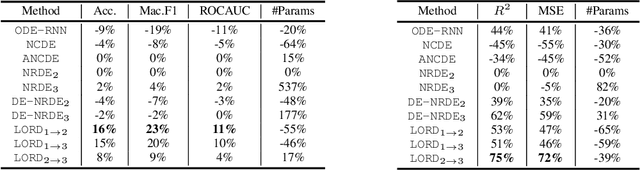
The problem of processing very long time-series data (e.g., a length of more than 10,000) is a long-standing research problem in machine learning. Recently, one breakthrough, called neural rough differential equations (NRDEs), has been proposed and has shown that it is able to process such data. Their main concept is to use the log-signature transform, which is known to be more efficient than the Fourier transform for irregular long time-series, to convert a very long time-series sample into a relatively shorter series of feature vectors. However, the log-signature transform causes non-trivial spatial overheads. To this end, we present the method of LOweR-Dimensional embedding of log-signature (LORD), where we define an NRDE-based autoencoder to implant the higher-depth log-signature knowledge into the lower-depth log-signature. We show that the encoder successfully combines the higher-depth and the lower-depth log-signature knowledge, which greatly stabilizes the training process and increases the model accuracy. In our experiments with benchmark datasets, the improvement ratio by our method is up to 75\% in terms of various classification and forecasting evaluation metrics.
Low power communication signal enhancement method of Internet of things based on nonlocal mean denoising
May 14, 2022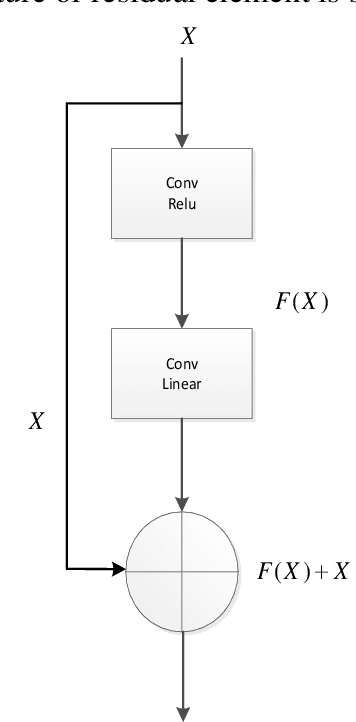
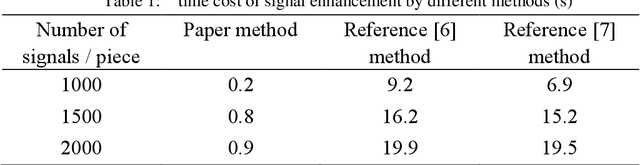
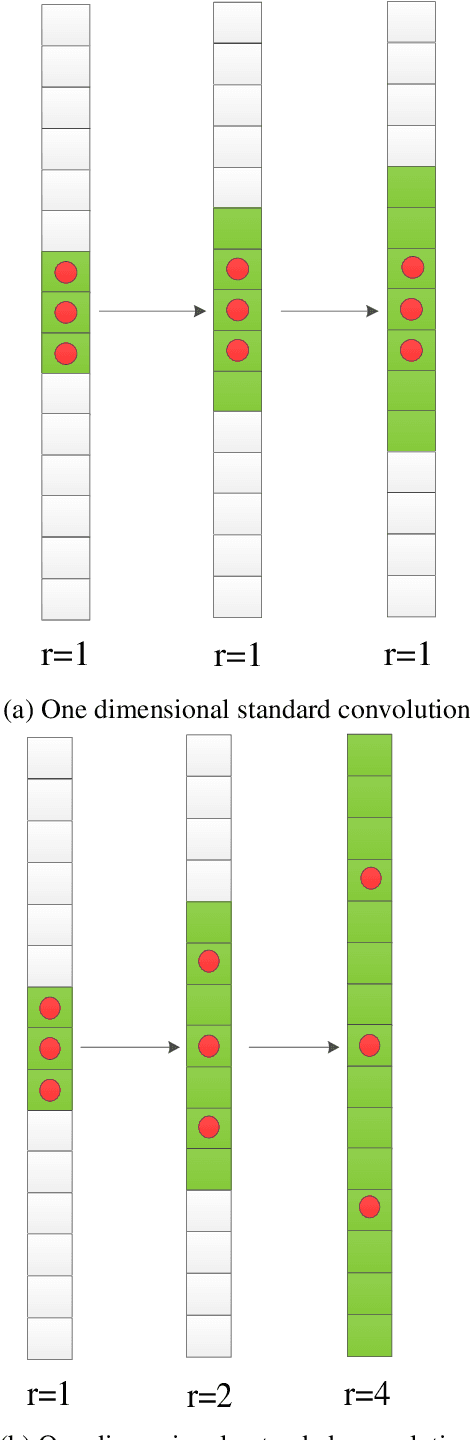
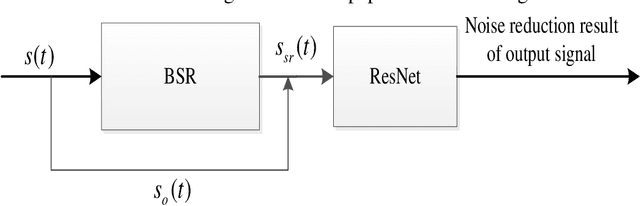
In order to improve the transmission effect of low-power communication signal of Internet of things and compress the enhancement time of low-power communication signal, this paper designs a low-power communication signal enhancement method of Internet of things based on nonlocal mean denoising. Firstly, the residual of one-dimensional communication layer is pre processed by convolution core to obtain the residual of one-dimensional communication layer; Then, according to the two classification recognition method, the noise reduction signal feature recognition of the low-power communication signal of the Internet of things is realized, the non local mean noise reduction algorithm is used to remove the low-power communication signal of the Internet of things, and the weight value between similar blocks is calculated according to the European distance method. Finally, the low-power communication signal enhancement of the Internet of things is realized by the non local mean value denoising method. The experimental results show that the communication signal enhancement time overhead of this method is low, which is always less than 2.6s. The lowest bit error rate after signal enhancement is about 1%, and the signal-to-noise ratio is up to 18 dB, which shows that this method can achieve signal enhancement.
Fairness via In-Processing in the Over-parameterized Regime: A Cautionary Tale
Jun 29, 2022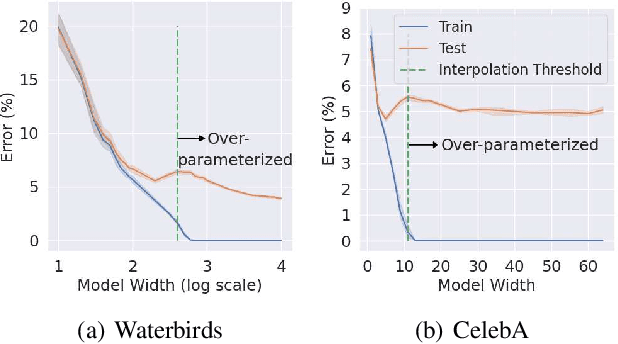
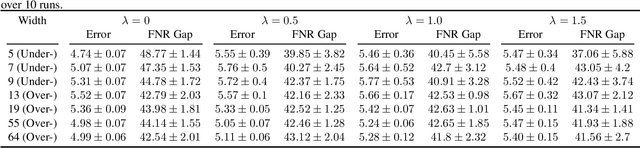
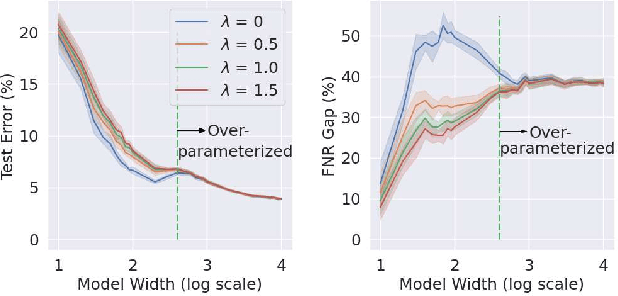

The success of DNNs is driven by the counter-intuitive ability of over-parameterized networks to generalize, even when they perfectly fit the training data. In practice, test error often continues to decrease with increasing over-parameterization, referred to as double descent. This allows practitioners to instantiate large models without having to worry about over-fitting. Despite its benefits, however, prior work has shown that over-parameterization can exacerbate bias against minority subgroups. Several fairness-constrained DNN training methods have been proposed to address this concern. Here, we critically examine MinDiff, a fairness-constrained training procedure implemented within TensorFlow's Responsible AI Toolkit, that aims to achieve Equality of Opportunity. We show that although MinDiff improves fairness for under-parameterized models, it is likely to be ineffective in the over-parameterized regime. This is because an overfit model with zero training loss is trivially group-wise fair on training data, creating an "illusion of fairness," thus turning off the MinDiff optimization (this will apply to any disparity-based measures which care about errors or accuracy. It won't apply to demographic parity). Within specified fairness constraints, under-parameterized MinDiff models can even have lower error compared to their over-parameterized counterparts (despite baseline over-parameterized models having lower error). We further show that MinDiff optimization is very sensitive to choice of batch size in the under-parameterized regime. Thus, fair model training using MinDiff requires time-consuming hyper-parameter searches. Finally, we suggest using previously proposed regularization techniques, viz. L2, early stopping and flooding in conjunction with MinDiff to train fair over-parameterized models.
Susceptibility of Age of Gossip to Timestomping
May 17, 2022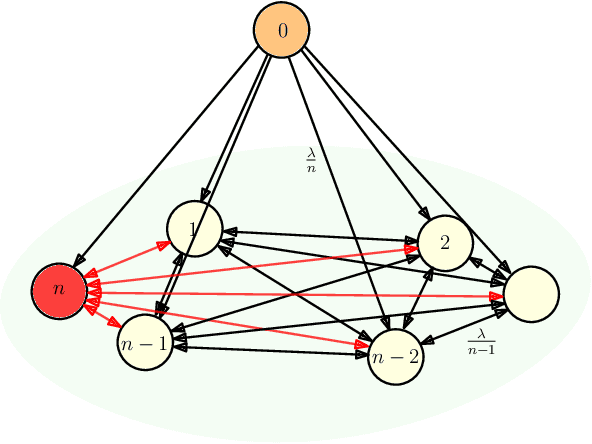
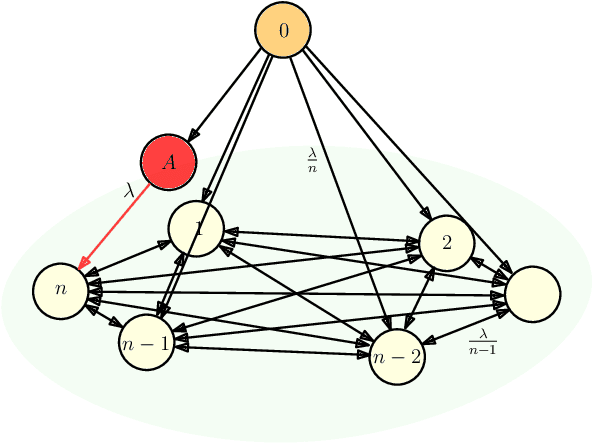
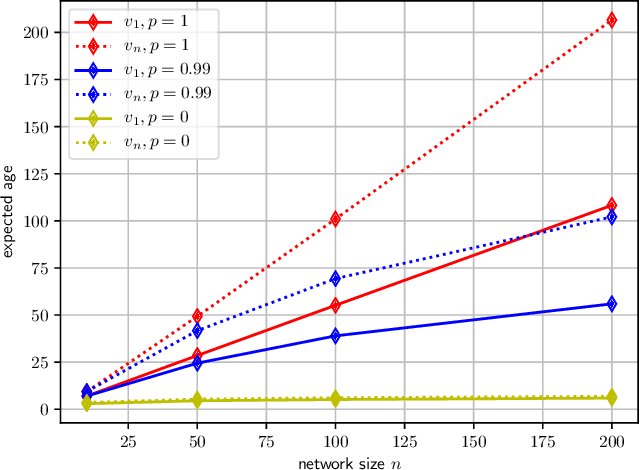
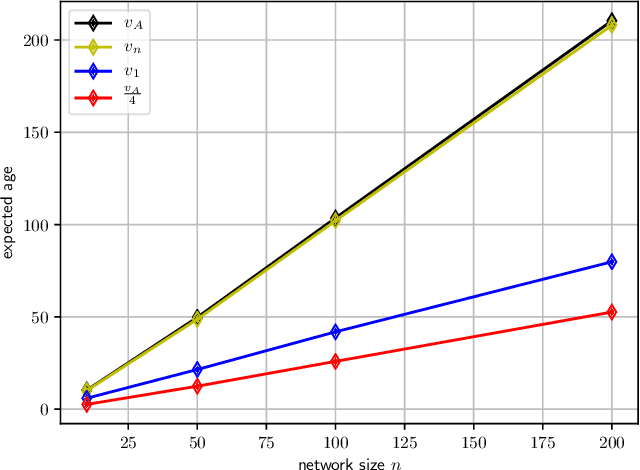
We consider a fully connected network consisting of a source that maintains the current version of a file, $n$ nodes that use asynchronous gossip mechanisms to disseminate fresh information in the network, and an adversary who infects the packets at a target node through data timestamp manipulation, with the intent to replace circulation of fresh packets with outdated packets in the network. We show that a single infected node increases the expected age of a fully connected network from $O(\log n)$ to $O(n)$. Further, we show that the optimal behavior for an adversary is to reset the timestamps of all outgoing packets to the current time and of all incoming packets to an outdated time. Additionally, if the adversary allows the infected node to accept a small fraction of incoming packets from the network, then a large network can manage to curb the spread of stale files coming from the infected node and pull the network age back to $O(\log n)$. Lastly, we show that if an infected node contacts only a single node instead of all nodes of the network, the system age can still be degraded to $O(n)$. These show that fully connected nature of a network can be both a benefit and a detriment for information freshness; full connectivity, while enabling fast dissemination of information, also enables fast dissipation of adversarial inputs.
Multi-scale Super-resolution Magnetic Resonance Spectroscopic Imaging with Adjustable Sharpness
Jun 17, 2022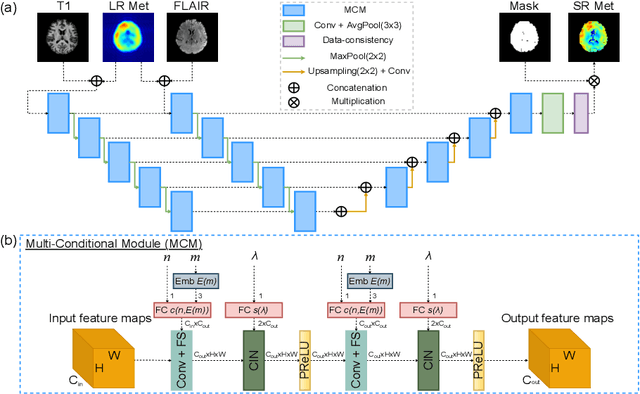
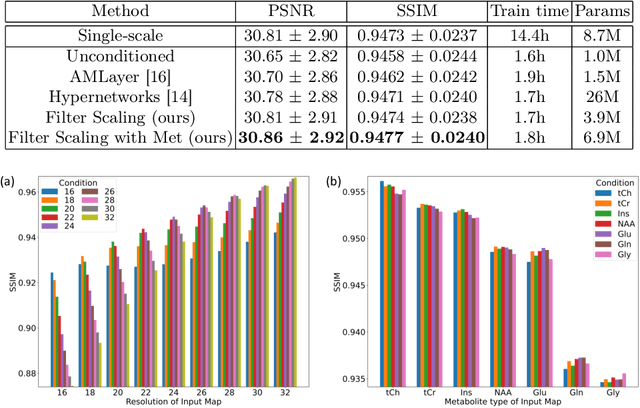
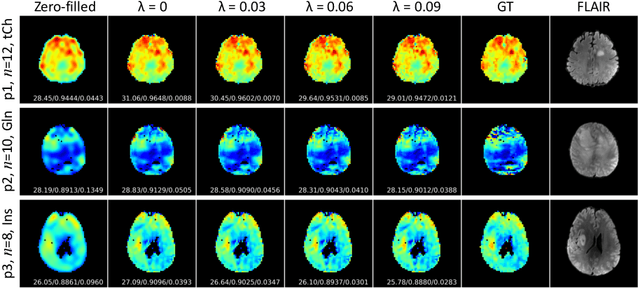
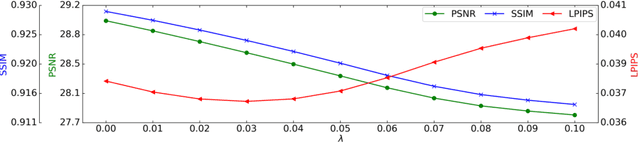
Magnetic Resonance Spectroscopic Imaging (MRSI) is a valuable tool for studying metabolic activities in the human body, but the current applications are limited to low spatial resolutions. The existing deep learning-based MRSI super-resolution methods require training a separate network for each upscaling factor, which is time-consuming and memory inefficient. We tackle this multi-scale super-resolution problem using a Filter Scaling strategy that modulates the convolution filters based on the upscaling factor, such that a single network can be used for various upscaling factors. Observing that each metabolite has distinct spatial characteristics, we also modulate the network based on the specific metabolite. Furthermore, our network is conditioned on the weight of adversarial loss so that the perceptual sharpness of the super-resolved metabolic maps can be adjusted within a single network. We incorporate these network conditionings using a novel Multi-Conditional Module. The experiments were carried out on a 1H-MRSI dataset from 15 high-grade glioma patients. Results indicate that the proposed network achieves the best performance among several multi-scale super-resolution methods and can provide super-resolved metabolic maps with adjustable sharpness.
TAVA: Template-free Animatable Volumetric Actors
Jun 21, 2022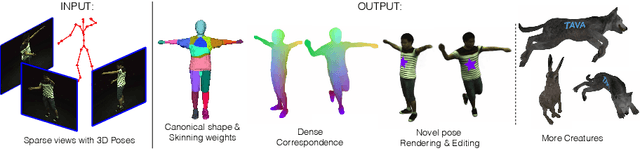

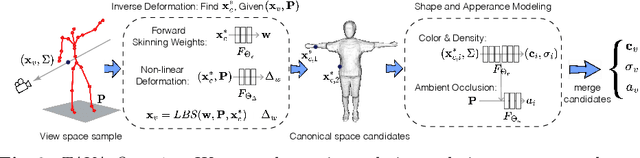
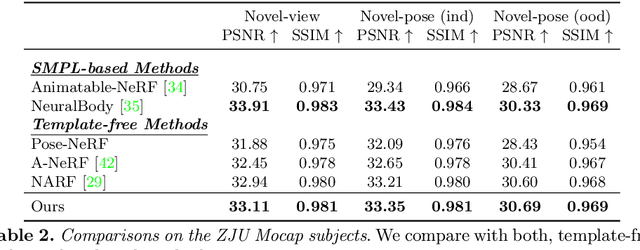
Coordinate-based volumetric representations have the potential to generate photo-realistic virtual avatars from images. However, virtual avatars also need to be controllable even to a novel pose that may not have been observed. Traditional techniques, such as LBS, provide such a function; yet it usually requires a hand-designed body template, 3D scan data, and limited appearance models. On the other hand, neural representation has been shown to be powerful in representing visual details, but are under explored on deforming dynamic articulated actors. In this paper, we propose TAVA, a method to create T emplate-free Animatable Volumetric Actors, based on neural representations. We rely solely on multi-view data and a tracked skeleton to create a volumetric model of an actor, which can be animated at the test time given novel pose. Since TAVA does not require a body template, it is applicable to humans as well as other creatures such as animals. Furthermore, TAVA is designed such that it can recover accurate dense correspondences, making it amenable to content-creation and editing tasks. Through extensive experiments, we demonstrate that the proposed method generalizes well to novel poses as well as unseen views and showcase basic editing capabilities.