 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Object Scene Representation Transformer
Jun 14, 2022
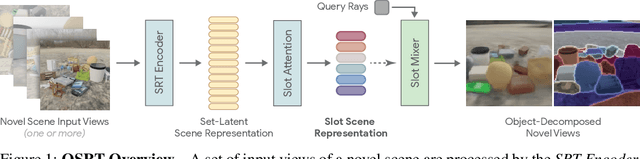

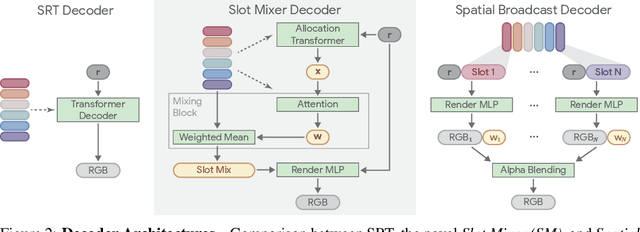
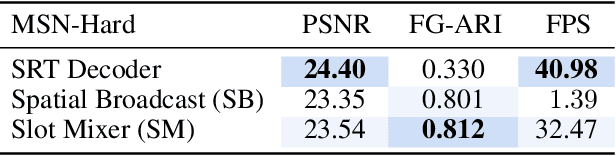
A compositional understanding of the world in terms of objects and their geometry in 3D space is considered a cornerstone of human cognition. Facilitating the learning of such a representation in neural networks holds promise for substantially improving labeled data efficiency. As a key step in this direction, we make progress on the problem of learning 3D-consistent decompositions of complex scenes into individual objects in an unsupervised fashion. We introduce Object Scene Representation Transformer (OSRT), a 3D-centric model in which individual object representations naturally emerge through novel view synthesis. OSRT scales to significantly more complex scenes with larger diversity of objects and backgrounds than existing methods. At the same time, it is multiple orders of magnitude faster at compositional rendering thanks to its light field parametrization and the novel Slot Mixer decoder. We believe this work will not only accelerate future architecture exploration and scaling efforts, but it will also serve as a useful tool for both object-centric as well as neural scene representation learning communities.
Zero Day Threat Detection Using Graph and Flow Based Security Telemetry
May 04, 2022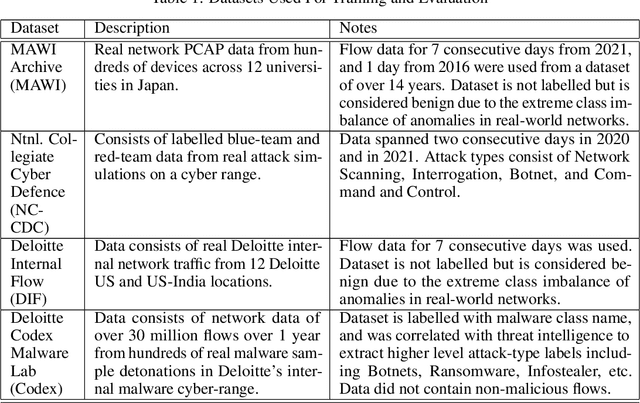
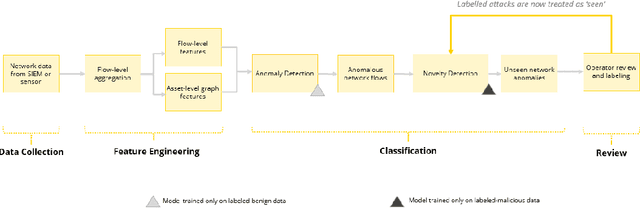
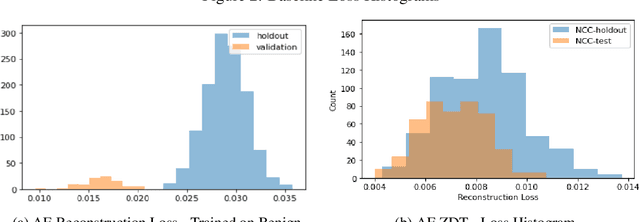

Zero Day Threats (ZDT) are novel methods used by malicious actors to attack and exploit information technology (IT) networks or infrastructure. In the past few years, the number of these threats has been increasing at an alarming rate and have been costing organizations millions of dollars to remediate. The increasing expansion of network attack surfaces and the exponentially growing number of assets on these networks necessitate the need for a robust AI-based Zero Day Threat detection model that can quickly analyze petabyte-scale data for potentially malicious and novel activity. In this paper, the authors introduce a deep learning based approach to Zero Day Threat detection that can generalize, scale, and effectively identify threats in near real-time. The methodology utilizes network flow telemetry augmented with asset-level graph features, which are passed through a dual-autoencoder structure for anomaly and novelty detection respectively. The models have been trained and tested on four large scale datasets that are representative of real-world organizational networks and they produce strong results with high precision and recall values. The models provide a novel methodology to detect complex threats with low false-positive rates that allow security operators to avoid alert fatigue while drastically reducing their mean time to response with near-real-time detection. Furthermore, the authors also provide a novel, labelled, cyber attack dataset generated from adversarial activity that can be used for validation or training of other models. With this paper, the authors' overarching goal is to provide a novel architecture and training methodology for cyber anomaly detectors that can generalize to multiple IT networks with minimal to no retraining while still maintaining strong performance.
GraphFramEx: Towards Systematic Evaluation of Explainability Methods for Graph Neural Networks
Jun 30, 2022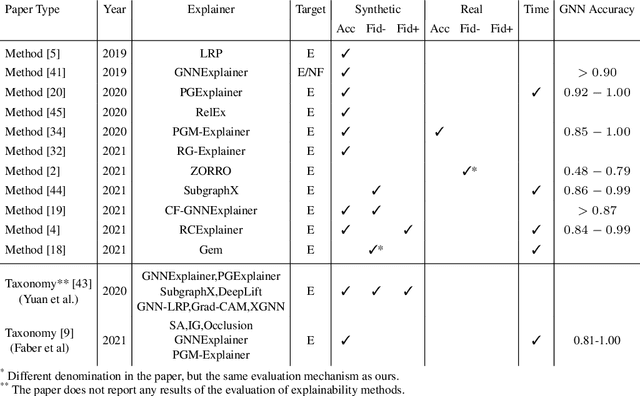
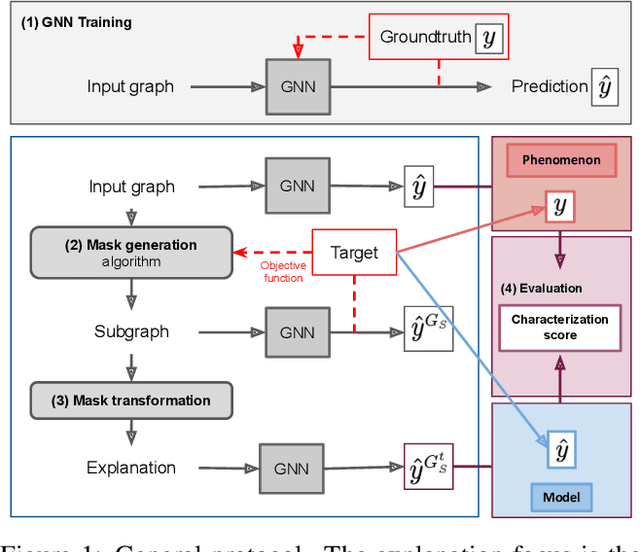
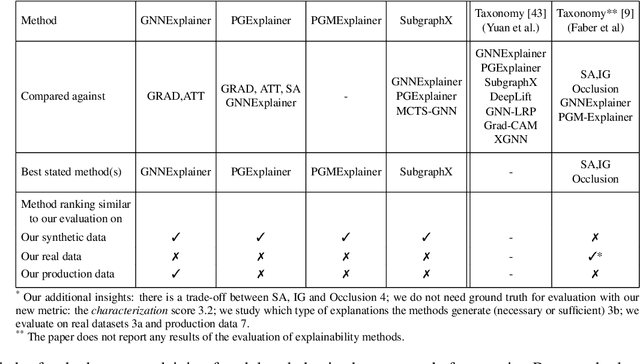
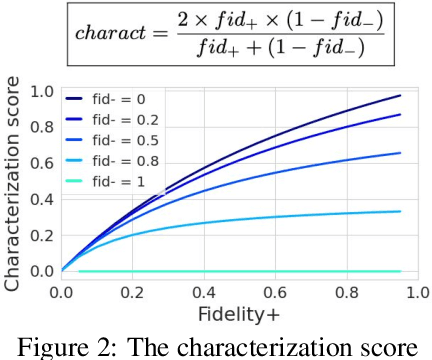
As one of the most popular machine learning models today, graph neural networks (GNNs) have attracted intense interest recently, and so does their explainability. Users are increasingly interested in a better understanding of GNN models and their outcomes. Unfortunately, today's evaluation frameworks for GNN explainability often rely on synthetic datasets, leading to conclusions of limited scope due to a lack of complexity in the problem instances. As GNN models are deployed to more mission-critical applications, we are in dire need for a common evaluation protocol of explainability methods of GNNs. In this paper, we propose, to our best knowledge, the first systematic evaluation framework for GNN explainability, considering explainability on three different "user needs:" explanation focus, mask nature, and mask transformation. We propose a unique metric that combines the fidelity measures and classify explanations based on their quality of being sufficient or necessary. We scope ourselves to node classification tasks and compare the most representative techniques in the field of input-level explainability for GNNs. For the widely used synthetic benchmarks, surprisingly shallow techniques such as personalized PageRank have the best performance for a minimum computation time. But when the graph structure is more complex and nodes have meaningful features, gradient-based methods, in particular Saliency, are the best according to our evaluation criteria. However, none dominates the others on all evaluation dimensions and there is always a trade-off. We further apply our evaluation protocol in a case study on eBay graphs to reflect the production environment.
Lookback for Learning to Branch
Jun 30, 2022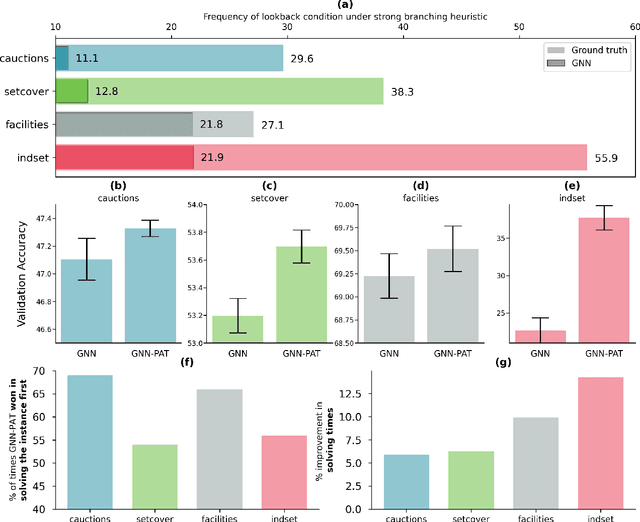

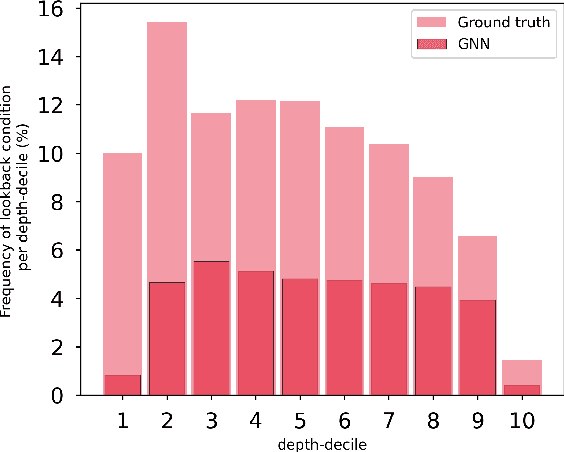
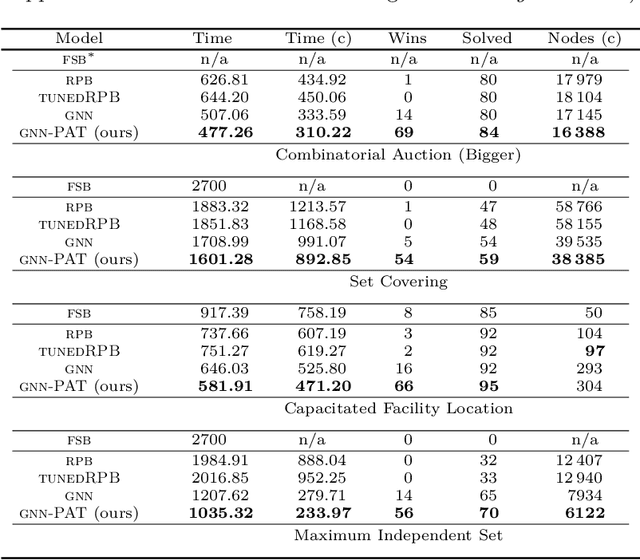
The expressive and computationally inexpensive bipartite Graph Neural Networks (GNN) have been shown to be an important component of deep learning based Mixed-Integer Linear Program (MILP) solvers. Recent works have demonstrated the effectiveness of such GNNs in replacing the branching (variable selection) heuristic in branch-and-bound (B&B) solvers. These GNNs are trained, offline and on a collection of MILPs, to imitate a very good but computationally expensive branching heuristic, strong branching. Given that B&B results in a tree of sub-MILPs, we ask (a) whether there are strong dependencies exhibited by the target heuristic among the neighboring nodes of the B&B tree, and (b) if so, whether we can incorporate them in our training procedure. Specifically, we find that with the strong branching heuristic, a child node's best choice was often the parent's second-best choice. We call this the "lookback" phenomenon. Surprisingly, the typical branching GNN of Gasse et al. (2019) often misses this simple "answer". To imitate the target behavior more closely by incorporating the lookback phenomenon in GNNs, we propose two methods: (a) target smoothing for the standard cross-entropy loss function, and (b) adding a Parent-as-Target (PAT) Lookback regularizer term. Finally, we propose a model selection framework to incorporate harder-to-formulate objectives such as solving time in the final models. Through extensive experimentation on standard benchmark instances, we show that our proposal results in up to 22% decrease in the size of the B&B tree and up to 15% improvement in the solving times.
Low-complexity acoustic scene classification in DCASE 2022 Challenge
Jun 08, 2022

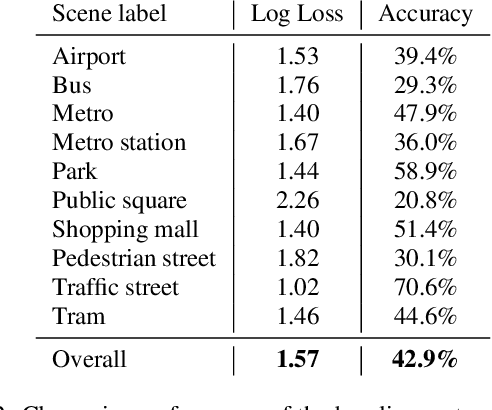
This paper analyzes the outcome of the Low-Complexity Acoustic Scene Classification task in DCASE 2022 Challenge. The task is a continuation from the previous years. In this edition, the requirement for low-complexity solutions were modified including: a limit of 128 K on the number of parameters, including the zero-valued ones, imposed INT8 numerical format, and a limit of 30 million multiply-accumulate operations at inference time. The provided baseline system is a convolutional neural network which employs post-training quantization of parameters, resulting in 46512 parameters, and 29.23 million multiply-and-accumulate operations, well under the set limits of 128K and 30 million, respectively. The baseline system has a 42.9% accuracy and a log-loss of 1.575 on the development data consisting of audio from 9 different devices. An analysis of the submitted systems will be provided after the challenge deadline.
Embodied Scene-aware Human Pose Estimation
Jun 18, 2022
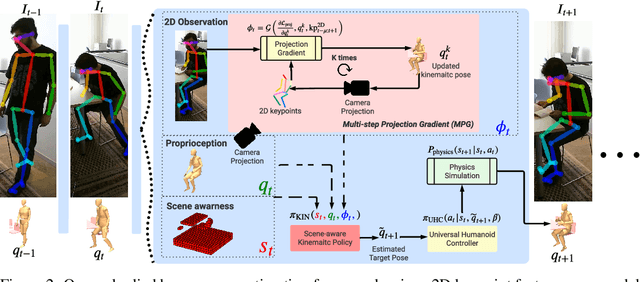
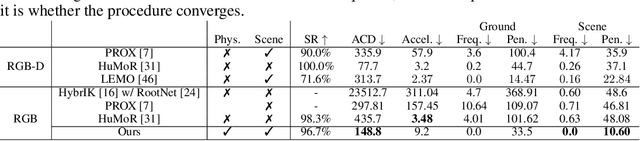

We propose embodied scene-aware human pose estimation where we estimate 3D poses based on a simulated agent's proprioception and scene awareness, along with external third-person observations. Unlike prior methods that often resort to multistage optimization, non-causal inference, and complex contact modeling to estimate human pose and human scene interactions, our method is one stage, causal, and recovers global 3D human poses in a simulated environment. Since 2D third-person observations are coupled with the camera pose, we propose to disentangle the camera pose and use a multi-step projection gradient defined in the global coordinate frame as the movement cue for our embodied agent. Leveraging a physics simulation and prescanned scenes (e.g., 3D mesh), we simulate our agent in everyday environments (libraries, offices, bedrooms, etc.) and equip our agent with environmental sensors to intelligently navigate and interact with scene geometries. Our method also relies only on 2D keypoints and can be trained on synthetic datasets derived from popular human motion databases. To evaluate, we use the popular H36M and PROX datasets and, for the first time, achieve a success rate of 96.7% on the challenging PROX dataset without ever using PROX motion sequences for training.
Residual Graph Convolutional Recurrent Networks For Multi-step Traffic Flow Forecasting
May 03, 2022

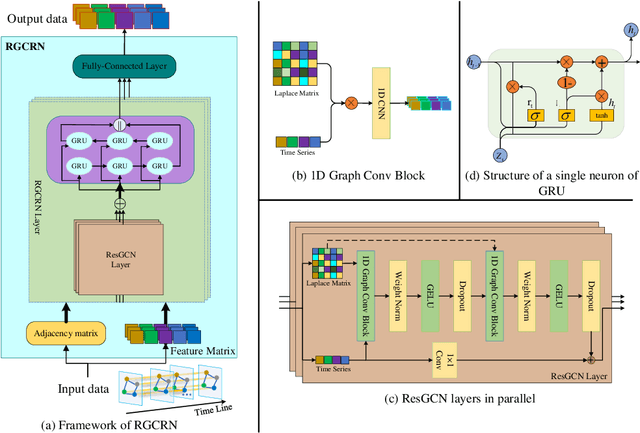
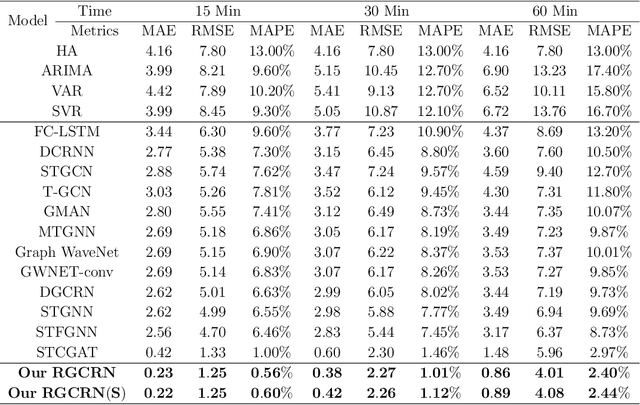
Traffic flow forecasting is essential for traffic planning, control and management. The main challenge of traffic forecasting tasks is accurately capturing traffic networks' spatial and temporal correlation. Although there are many traffic forecasting methods, most of them still have limitations in capturing spatial and temporal correlations. To improve traffic forecasting accuracy, we propose a new Spatial-temporal forecasting model, namely the Residual Graph Convolutional Recurrent Network (RGCRN). The model uses our proposed Residual Graph Convolutional Network (ResGCN) to capture the fine-grained spatial correlation of the traffic road network and then uses a Bi-directional Gated Recurrent Unit (BiGRU) to model time series with spatial information and obtains the temporal correlation by analysing the change in information transfer between the forward and reverse neurons of the time series data. Our comparative experimental results on two real datasets show that RGCRN improves on average by 20.66% compared to the best baseline model. You can get our source code and data through https://github.com/zhangshqii/RGCRN.
Deep Semi-Supervised Learning for Time Series Classification
Feb 06, 2021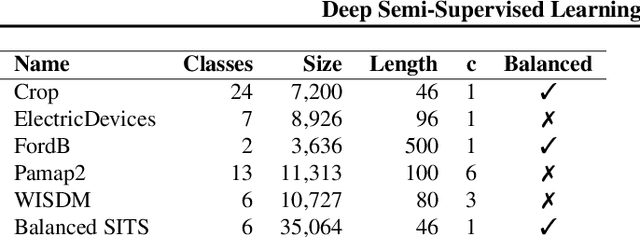
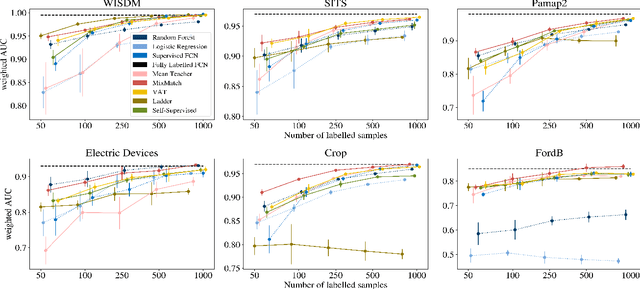
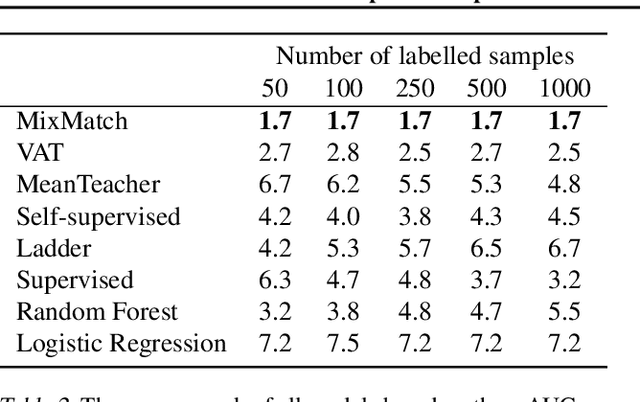
While Semi-supervised learning has gained much attention in computer vision on image data, yet limited research exists on its applicability in the time series domain. In this work, we investigate the transferability of state-of-the-art deep semi-supervised models from image to time series classification. We discuss the necessary model adaptations, in particular an appropriate model backbone architecture and the use of tailored data augmentation strategies. Based on these adaptations, we explore the potential of deep semi-supervised learning in the context of time series classification by evaluating our methods on large public time series classification problems with varying amounts of labelled samples. We perform extensive comparisons under a decidedly realistic and appropriate evaluation scheme with a unified reimplementation of all algorithms considered, which is yet lacking in the field. We find that these transferred semi-supervised models show significant performance gains over strong supervised, semi-supervised and self-supervised alternatives, especially for scenarios with very few labelled samples.
Joint Beam Hopping and Carrier Aggregation in High Throughput Multi-Beam Satellite Systems
Jun 24, 2022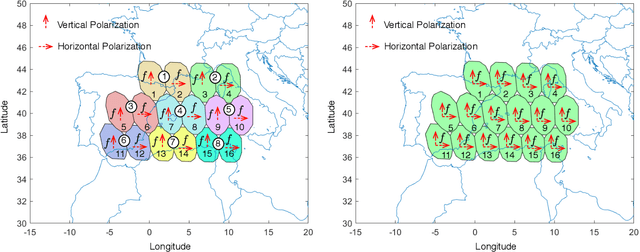
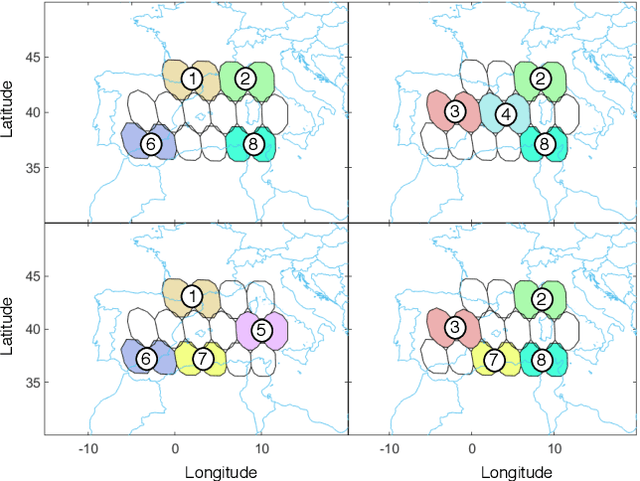
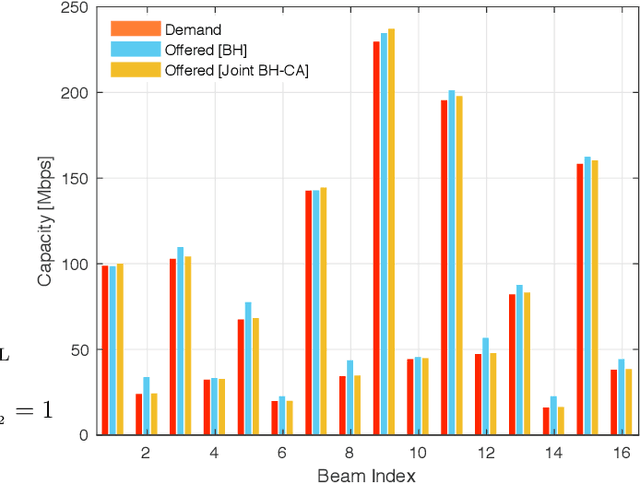
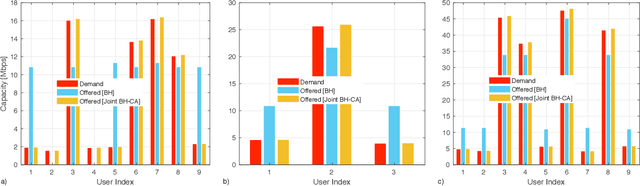
Beam hopping (BH) and carrier aggregation (CA) are two promising technologies for the next generation satellite communication systems to achieve several orders of magnitude increase in system capacity and to significantly improve the spectral efficiency. While BH allows a great flexibility in adapting the offered capacity to the heterogeneous demand, CA further enhances the user quality-of-service (QoS) by allowing it to pool resources from multiple adjacent beams. In this paper, we consider a multi-beam high throughput satellite (HTS) system that employs BH in conjunction with CA to capitalize on the mutual interplay between both techniques. Particularly, an innovative joint BH-CA scheme is proposed and analyzed in this work to utilize their individual competencies. This includes designing an efficient joint time-space beam illumination pattern for BH and multi-user aggregation strategy for CA. Through this, user-carrier assignment, transponder filling-rates, beams hopping pattern, and illumination duration are all simultaneously optimized by formulating a joint optimization problem as a multi-objective mixed integer linear programming problem (MINLP). Simulation results are provided to corroborate our analysis, demonstrate the design tradeoffs, and point out the potentials of the proposed joint BH-CA concept. Advantages of our BH-CA scheme versus the conventional BH method without employing CA are investigated and presented under the same system circumstances.
Near-Exact Recovery for Tomographic Inverse Problems via Deep Learning
Jun 14, 2022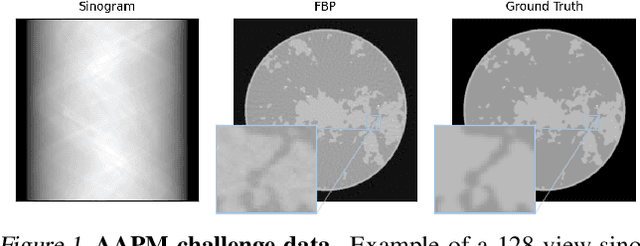
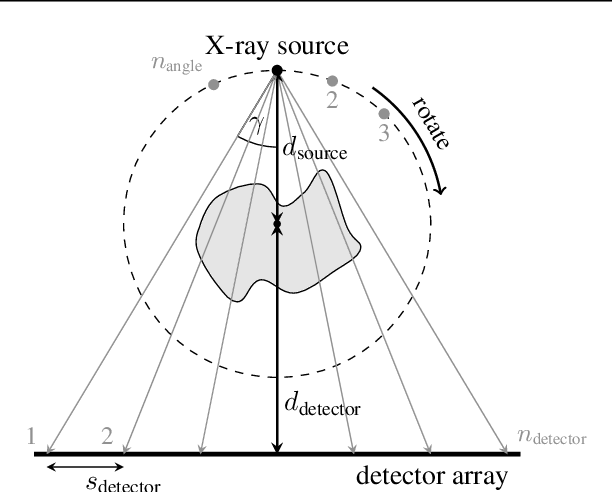
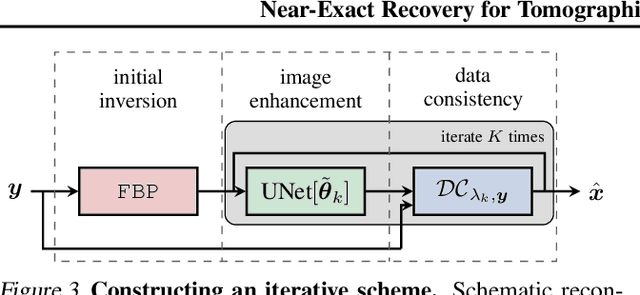

This work is concerned with the following fundamental question in scientific machine learning: Can deep-learning-based methods solve noise-free inverse problems to near-perfect accuracy? Positive evidence is provided for the first time, focusing on a prototypical computed tomography (CT) setup. We demonstrate that an iterative end-to-end network scheme enables reconstructions close to numerical precision, comparable to classical compressed sensing strategies. Our results build on our winning submission to the recent AAPM DL-Sparse-View CT Challenge. Its goal was to identify the state-of-the-art in solving the sparse-view CT inverse problem with data-driven techniques. A specific difficulty of the challenge setup was that the precise forward model remained unknown to the participants. Therefore, a key feature of our approach was to initially estimate the unknown fanbeam geometry in a data-driven calibration step. Apart from an in-depth analysis of our methodology, we also demonstrate its state-of-the-art performance on the open-access real-world dataset LoDoPaB CT.