 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning for Semantic Alignment of Language, Audio, and Visual Modalities
May 20, 2025This paper proposes a single-stage training approach that semantically aligns three modalities - audio, visual, and text using a contrastive learning framework. Contrastive training has gained prominence for multimodal alignment, utilizing large-scale unlabeled data to learn shared representations. Existing deep learning approach for trimodal alignment involves two-stages, that separately align visual-text and audio-text modalities. This approach suffers from mismatched data distributions, resulting in suboptimal alignment. Leveraging the AVCaps dataset, which provides audio, visual and audio-visual captions for video clips, our method jointly optimizes the representation of all the modalities using contrastive training. Our results demonstrate that the single-stage approach outperforms the two-stage method, achieving a two-fold improvement in audio based visual retrieval, highlighting the advantages of unified multimodal representation learning.
DCASE 2024 Task 4: Sound Event Detection with Heterogeneous Data and Missing Labels
Jun 12, 2024


The Detection and Classification of Acoustic Scenes and Events Challenge Task 4 aims to advance sound event detection (SED) systems in domestic environments by leveraging training data with different supervision uncertainty. Participants are challenged in exploring how to best use training data from different domains and with varying annotation granularity (strong/weak temporal resolution, soft/hard labels), to obtain a robust SED system that can generalize across different scenarios. Crucially, annotation across available training datasets can be inconsistent and hence sound labels of one dataset may be present but not annotated in the other one and vice-versa. As such, systems will have to cope with potentially missing target labels during training. Moreover, as an additional novelty, systems will also be evaluated on labels with different granularity in order to assess their robustness for different applications. To lower the entry barrier for participants, we developed an updated baseline system with several caveats to address these aforementioned problems. Results with our baseline system indicate that this research direction is promising and is possible to obtain a stronger SED system by using diverse domain training data with missing labels compared to training a SED system for each domain separately.
Data-Efficient Low-Complexity Acoustic Scene Classification in the DCASE 2024 Challenge
May 16, 2024

This article describes the Data-Efficient Low-Complexity Acoustic Scene Classification Task in the DCASE 2024 Challenge and the corresponding baseline system. The task setup is a continuation of previous editions (2022 and 2023), which focused on recording device mismatches and low-complexity constraints. This year's edition introduces an additional real-world problem: participants must develop data-efficient systems for five scenarios, which progressively limit the available training data. The provided baseline system is based on an efficient, factorized CNN architecture constructed from inverted residual blocks and uses Freq-MixStyle to tackle the device mismatch problem. The baseline system's accuracy ranges from 42.40% on the smallest to 56.99% on the largest training set.
Training sound event detection with soft labels from crowdsourced annotations
Feb 28, 2023



In this paper, we study the use of soft labels to train a system for sound event detection (SED). Soft labels can result from annotations which account for human uncertainty about categories, or emerge as a natural representation of multiple opinions in annotation. Converting annotations to hard labels results in unambiguous categories for training, at the cost of losing the details about the labels distribution. This work investigates how soft labels can be used, and what benefits they bring in training a SED system. The results show that the system is capable of learning information about the activity of the sounds which is reflected in the soft labels and is able to detect sounds that are missed in the typical binary target training setup. We also release a new dataset produced through crowdsourcing, containing temporally strong labels for sound events in real-life recordings, with both soft and hard labels.
Low-complexity acoustic scene classification in DCASE 2022 Challenge
Jun 08, 2022

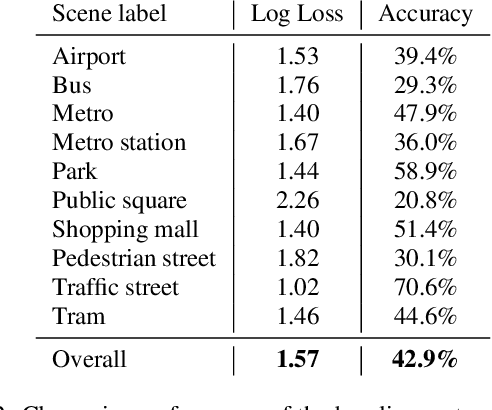
This paper analyzes the outcome of the Low-Complexity Acoustic Scene Classification task in DCASE 2022 Challenge. The task is a continuation from the previous years. In this edition, the requirement for low-complexity solutions were modified including: a limit of 128 K on the number of parameters, including the zero-valued ones, imposed INT8 numerical format, and a limit of 30 million multiply-accumulate operations at inference time. The provided baseline system is a convolutional neural network which employs post-training quantization of parameters, resulting in 46512 parameters, and 29.23 million multiply-and-accumulate operations, well under the set limits of 128K and 30 million, respectively. The baseline system has a 42.9% accuracy and a log-loss of 1.575 on the development data consisting of audio from 9 different devices. An analysis of the submitted systems will be provided after the challenge deadline.
Crowdsourcing strong labels for sound event detection
Jul 26, 2021
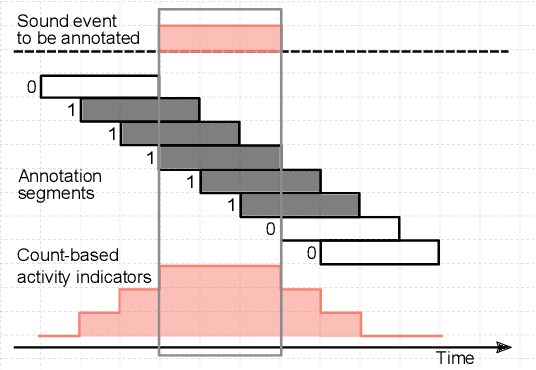
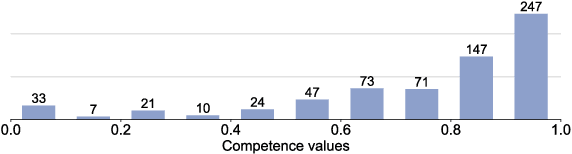

Strong labels are a necessity for evaluation of sound event detection methods, but often scarcely available due to the high resources required by the annotation task. We present a method for estimating strong labels using crowdsourced weak labels, through a process that divides the annotation task into simple unit tasks. Based on estimations of annotators' competence, aggregation and processing of the weak labels results in a set of objective strong labels. The experiment uses synthetic audio in order to verify the quality of the resulting annotations through comparison with ground truth. The proposed method produces labels with high precision, though not all event instances are recalled. Detection metrics comparing the produced annotations with the ground truth show 80% F-score in 1 s segments, and up to 89.5% intersection-based F1-score calculated according to the polyphonic sound detection score metrics.
Low-complexity acoustic scene classification for multi-device audio: analysis of DCASE 2021 Challenge systems
May 28, 2021

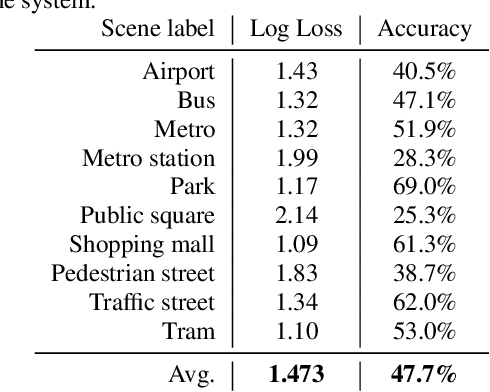
This paper presents the details of Task 1A Acoustic Scene Classification in the DCASE 2021 Challenge. The task consisted of classification of data from multiple devices, requiring good generalization properties, using low-complexity solutions. The provided baseline system is based on a CNN architecture and post-training parameters quantization. The system is trained using all the available training data, without any specific technique for handling device mismatch, and obtains an overall accuracy of 47.7%, with a log loss of 1.473. Details on the challenge results will be added after the challenge deadline.