 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Discretization and Stabilization of Energy-Based Controller for Period Switching Control and Flexible Scheduling
Jun 13, 2022
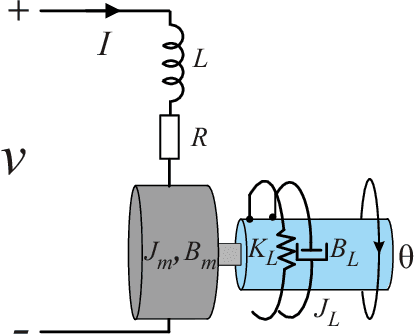
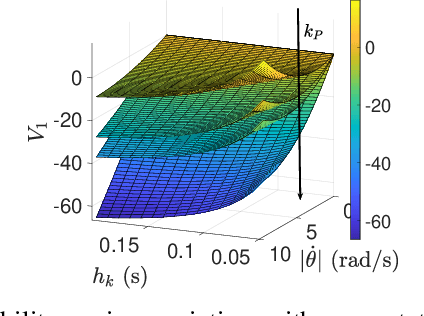
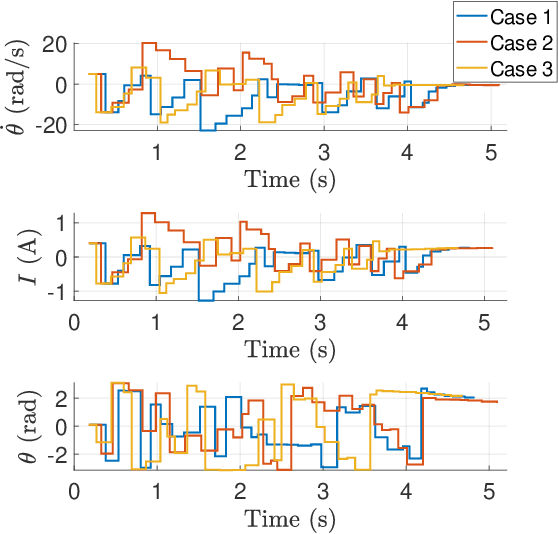
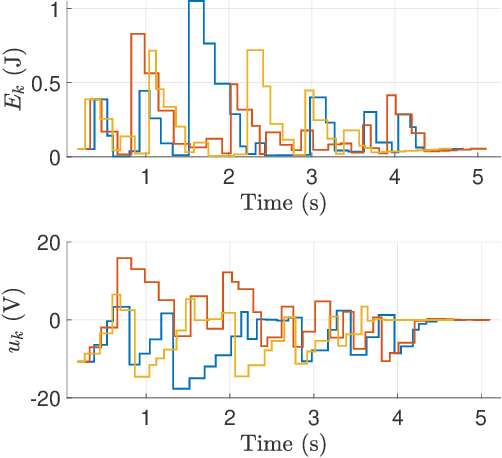
Emerging advanced control applications, with increased complexity in software but limited computing resources, suggest that real-time controllers should have adaptable designs. These control strategies also should be designed with consideration of the run-time behavior of the system. One of such research attempts is to design the controller along with the task scheduler, known as control-scheduling co-design, for more predictable timing behavior as well as surviving system overloads. Unlike traditional controller designs, which have equal-distance sampling periods, the co-design approach increases the system flexibility and resilience by explicitly considering timing properties, for example using an event-based controller or with multiple sampling times (non-uniform sampling and control). Within this context, we introduce the first work on the discretization of an energy-based controller that can switch arbitrarily between multiple periods and adjust the control parameters accordingly without destabilizing the system. A digital controller design based on this paradigm for a DC motor with an elastic load as an example is introduced and the stability condition is given based on the proposed Lyapunov function. The method is evaluated with various computer-based simulations which demonstrate its effectiveness.
Lightweight Automated Feature Monitoring for Data Streams
Jul 18, 2022
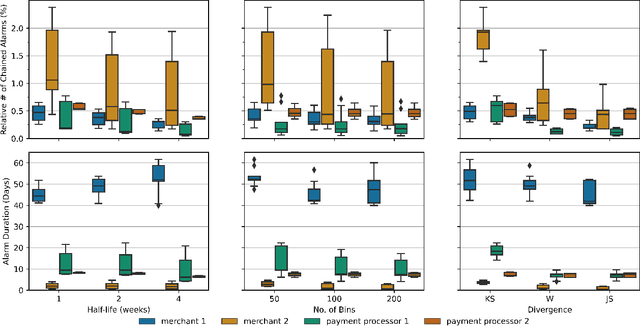
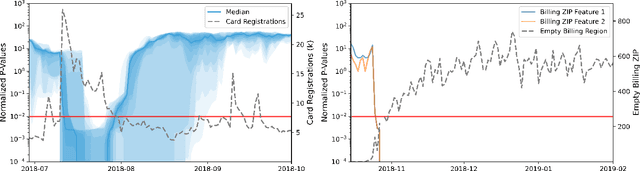
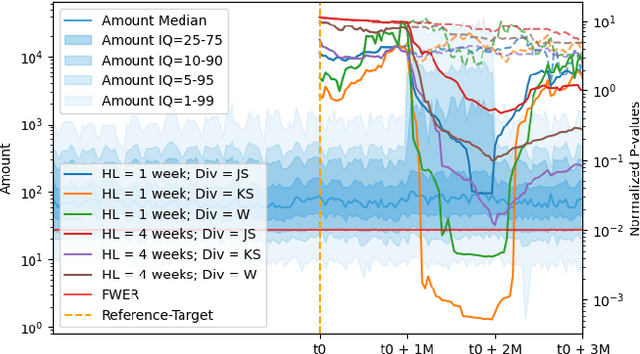
Monitoring the behavior of automated real-time stream processing systems has become one of the most relevant problems in real world applications. Such systems have grown in complexity relying heavily on high dimensional input data, and data hungry Machine Learning (ML) algorithms. We propose a flexible system, Feature Monitoring (FM), that detects data drifts in such data sets, with a small and constant memory footprint and a small computational cost in streaming applications. The method is based on a multi-variate statistical test and is data driven by design (full reference distributions are estimated from the data). It monitors all features that are used by the system, while providing an interpretable features ranking whenever an alarm occurs (to aid in root cause analysis). The computational and memory lightness of the system results from the use of Exponential Moving Histograms. In our experimental study, we analyze the system's behavior with its parameters and, more importantly, show examples where it detects problems that are not directly related to a single feature. This illustrates how FM eliminates the need to add custom signals to detect specific types of problems and that monitoring the available space of features is often enough.
SNN2ANN: A Fast and Memory-Efficient Training Framework for Spiking Neural Networks
Jun 19, 2022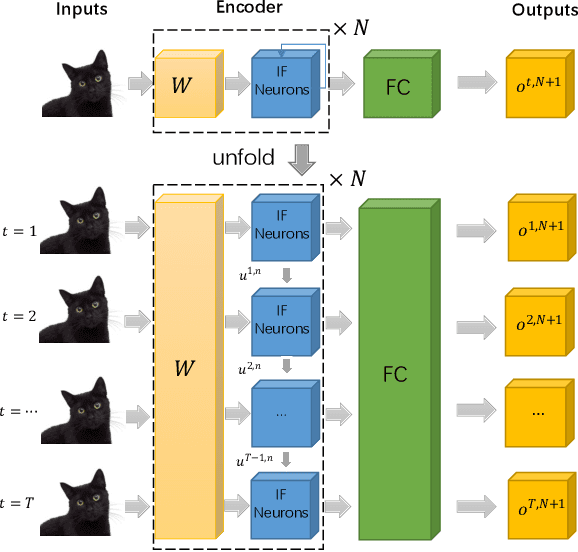
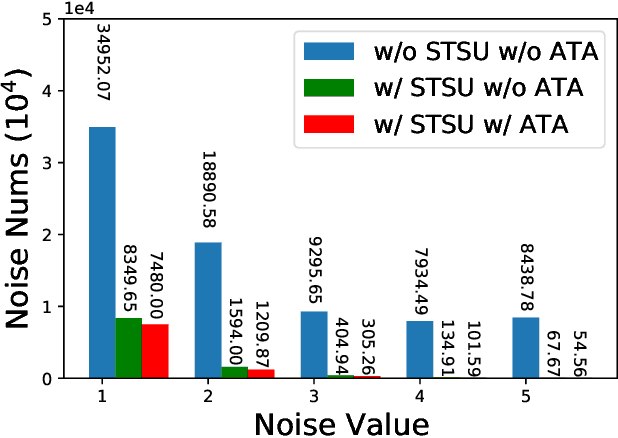
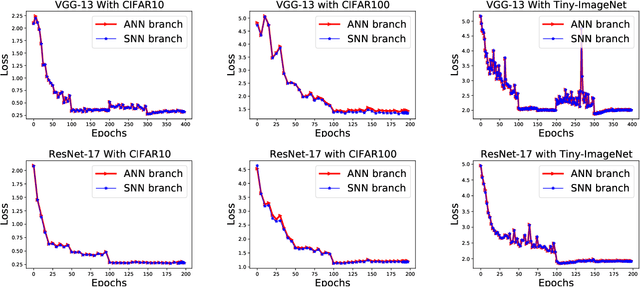
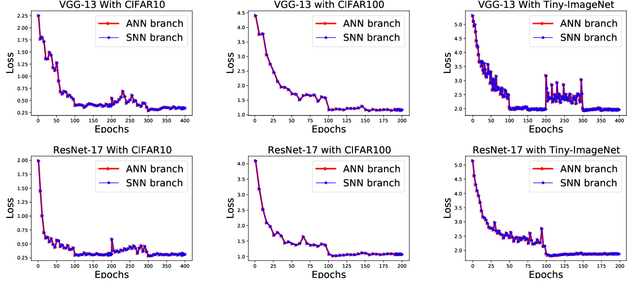
Spiking neural networks are efficient computation models for low-power environments. Spike-based BP algorithms and ANN-to-SNN (ANN2SNN) conversions are successful techniques for SNN training. Nevertheless, the spike-base BP training is slow and requires large memory costs. Though ANN2NN provides a low-cost way to train SNNs, it requires many inference steps to mimic the well-trained ANN for good performance. In this paper, we propose a SNN-to-ANN (SNN2ANN) framework to train the SNN in a fast and memory-efficient way. The SNN2ANN consists of 2 components: a) a weight sharing architecture between ANN and SNN and b) spiking mapping units. Firstly, the architecture trains the weight-sharing parameters on the ANN branch, resulting in fast training and low memory costs for SNN. Secondly, the spiking mapping units ensure that the activation values of the ANN are the spiking features. As a result, the classification error of the SNN can be optimized by training the ANN branch. Besides, we design an adaptive threshold adjustment (ATA) algorithm to address the noisy spike problem. Experiment results show that our SNN2ANN-based models perform well on the benchmark datasets (CIFAR10, CIFAR100, and Tiny-ImageNet). Moreover, the SNN2ANN can achieve comparable accuracy under 0.625x time steps, 0.377x training time, 0.27x GPU memory costs, and 0.33x spike activities of the Spike-based BP model.
Gaussian Process Regression in Logarithmic Time
Feb 22, 2021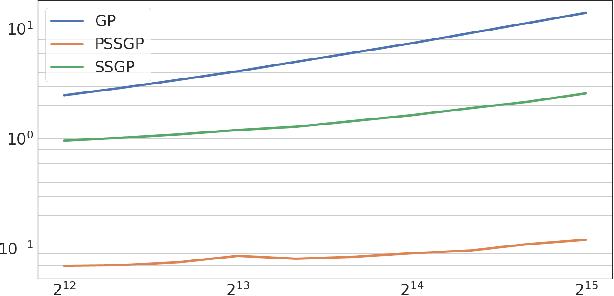
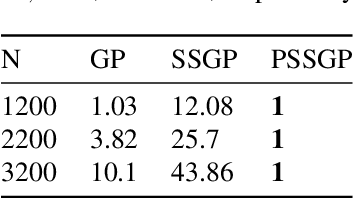
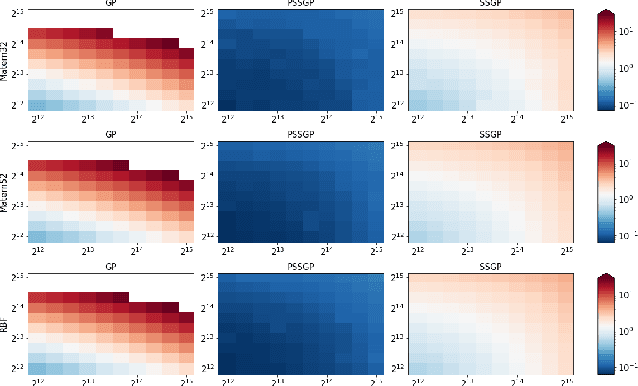
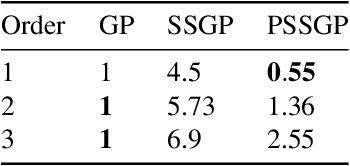
The aim of this article is to present a novel parallelization method for temporal Gaussian process (GP) regression problems. The method allows for solving GP regression problems in logarithmic $O(\log N)$ time, where $N$ is the number of time steps. Our approach uses the state-space representation of GPs which in its original form allows for linear $O(N)$ time GP regression by leveraging the Kalman filtering and smoothing methods. By using a recently proposed parallelization method for Bayesian filters and smoothers, we are able to reduce the linear computational complexity of the Kalman filter and smoother solutions to the GP regression problems into logarithmic span complexity, which transforms into logarithm time complexity when implemented in parallel hardware such as a graphics processing unit (GPU). We experimentally demonstrate the computational benefits one simulated and real datasets via our open-source implementation leveraging the GPflow framework.
Event Collapse in Contrast Maximization Frameworks
Jul 11, 2022
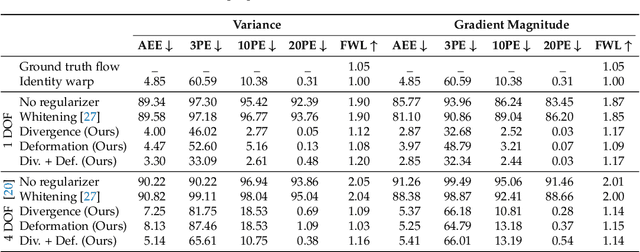
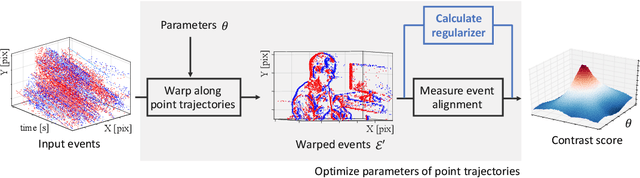
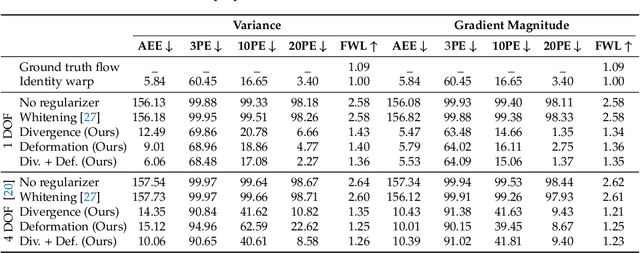
Contrast maximization (CMax) is a framework that provides state-of-the-art results on several event-based computer vision tasks, such as ego-motion or optical flow estimation. However, it may suffer from a problem called event collapse, which is an undesired solution where events are warped into too few pixels. As prior works have largely ignored the issue or proposed workarounds, it is imperative to analyze this phenomenon in detail. Our work demonstrates event collapse in its simplest form and proposes collapse metrics by using first principles of space-time deformation based on differential geometry and physics. We experimentally show on publicly available datasets that the proposed metrics mitigate event collapse and do not harm well-posed warps. To the best of our knowledge, regularizers based on the proposed metrics are the only effective solution against event collapse in the experimental settings considered, compared with other methods. We hope that this work inspires further research to tackle more complex warp models.
Direction-Aware Joint Adaptation of Neural Speech Enhancement and Recognition in Real Multiparty Conversational Environments
Jul 15, 2022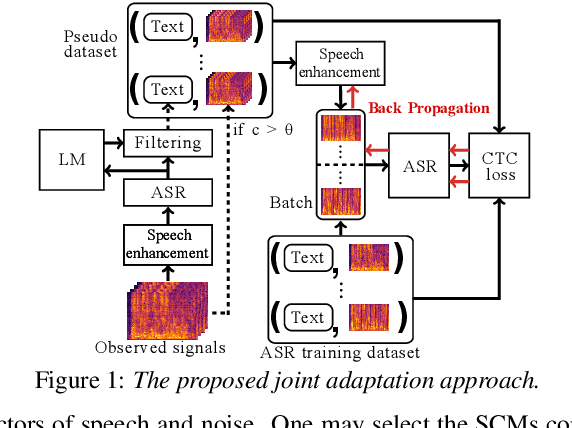
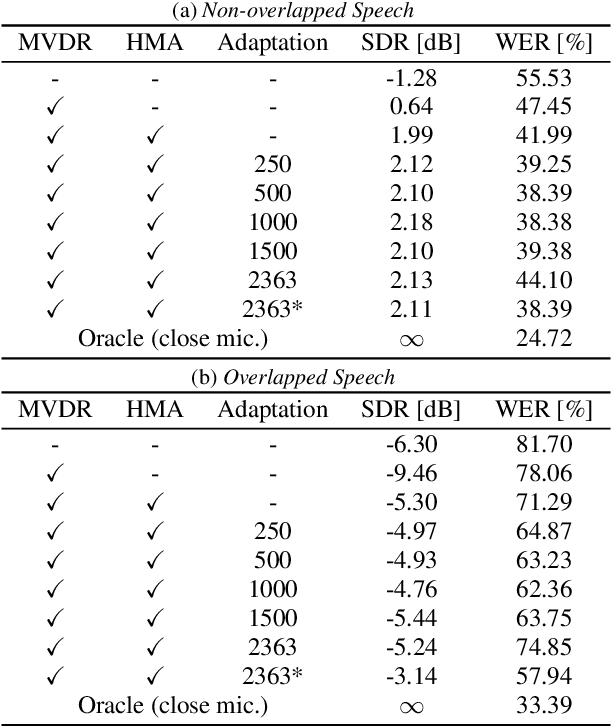
This paper describes noisy speech recognition for an augmented reality headset that helps verbal communication within real multiparty conversational environments. A major approach that has actively been studied in simulated environments is to sequentially perform speech enhancement and automatic speech recognition (ASR) based on deep neural networks (DNNs) trained in a supervised manner. In our task, however, such a pretrained system fails to work due to the mismatch between the training and test conditions and the head movements of the user. To enhance only the utterances of a target speaker, we use beamforming based on a DNN-based speech mask estimator that can adaptively extract the speech components corresponding to a head-relative particular direction. We propose a semi-supervised adaptation method that jointly updates the mask estimator and the ASR model at run-time using clean speech signals with ground-truth transcriptions and noisy speech signals with highly-confident estimated transcriptions. Comparative experiments using the state-of-the-art distant speech recognition system show that the proposed method significantly improves the ASR performance.
Hardware-agnostic Computation for Large-scale Knowledge Graph Embeddings
Jul 18, 2022
Knowledge graph embedding research has mainly focused on learning continuous representations of knowledge graphs towards the link prediction problem. Recently developed frameworks can be effectively applied in research related applications. Yet, these frameworks do not fulfill many requirements of real-world applications. As the size of the knowledge graph grows, moving computation from a commodity computer to a cluster of computers in these frameworks becomes more challenging. Finding suitable hyperparameter settings w.r.t. time and computational budgets are left to practitioners. In addition, the continual learning aspect in knowledge graph embedding frameworks is often ignored, although continual learning plays an important role in many real-world (deep) learning-driven applications. Arguably, these limitations explain the lack of publicly available knowledge graph embedding models for large knowledge graphs. We developed a framework based on the frameworks DASK, Pytorch Lightning and Hugging Face to compute embeddings for large-scale knowledge graphs in a hardware-agnostic manner, which is able to address real-world challenges pertaining to the scale of real application. We provide an open-source version of our framework along with a hub of pre-trained models having more than 11.4 B parameters.
Solving Learn-to-Race Autonomous Racing Challenge by Planning in Latent Space
Jul 05, 2022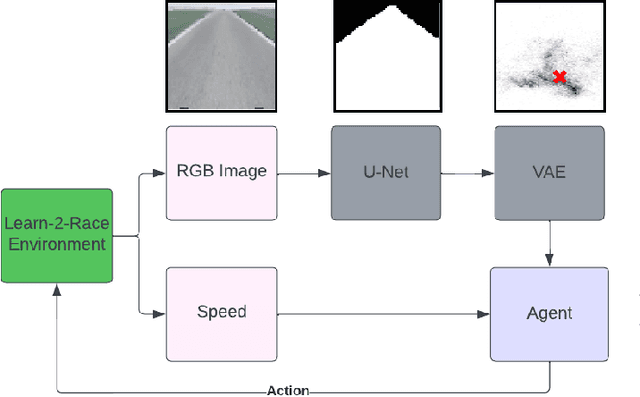
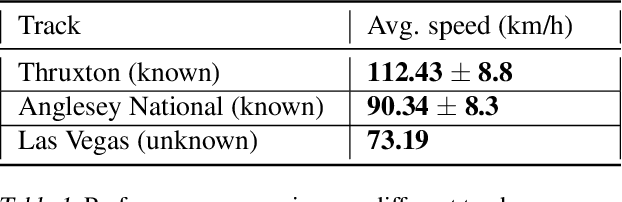

Learn-to-Race Autonomous Racing Virtual Challenge hosted on www<dot>aicrowd<dot>com platform consisted of two tracks: Single and Multi Camera. Our UniTeam team was among the final winners in the Single Camera track. The agent is required to pass the previously unknown F1-style track in the minimum time with the least amount of off-road driving violations. In our approach, we used the U-Net architecture for road segmentation, variational autocoder for encoding a road binary mask, and a nearest-neighbor search strategy that selects the best action for a given state. Our agent achieved an average speed of 105 km/h on stage 1 (known track) and 73 km/h on stage 2 (unknown track) without any off-road driving violations. Here we present our solution and results.
Parallel and real-time post-processing for quantum random number generators
Jul 29, 2021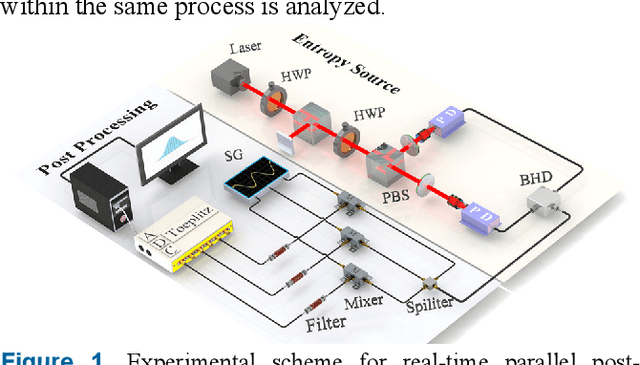

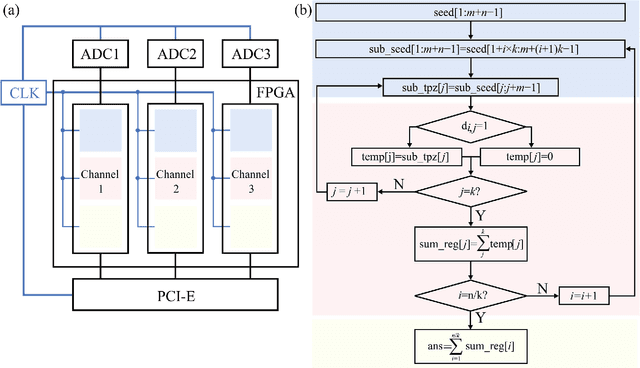

Quantum random number generators (QRNG) based on continuous variable (CV) quantum fluctuations offer great potential for their advantages in measurement bandwidth, stability and integrability. More importantly, it provides an efficient and extensible path for significant promotion of QRNG generation rate. During this process, real-time randomness extraction using information theoretically secure randomness extractors is vital, because it plays critical role in the limit of throughput rate and implementation cost of QRNGs. In this work, we investigate parallel and real-time realization of several Toeplitz-hashing extractors within one field-programmable gate array (FPGA) for parallel QRNG. Elaborate layout of Toeplitz matrixes and efficient utilization of hardware computing resource in the FPGA are emphatically studied. Logic source occupation for different scale and quantity of Toeplitz matrices is analyzed and two-layer parallel pipeline algorithm is delicately designed to fully exploit the parallel algorithm advantage and hardware source of the FPGA. This work finally achieves a real-time post-processing rate of QRNG above 8 Gbps. Matching up with integrated circuit for parallel extraction of multiple quantum sideband modes of vacuum state, our demonstration shows an important step towards chip-based parallel QRNG, which could effectively improve the practicality of CV QRNGs, including device trusted, device-independent, and semi-device-independent schemes.
Dynamic Complementarity Conditions and Whole-Body Trajectory Optimization for Humanoid Robot Locomotion
Jul 07, 2022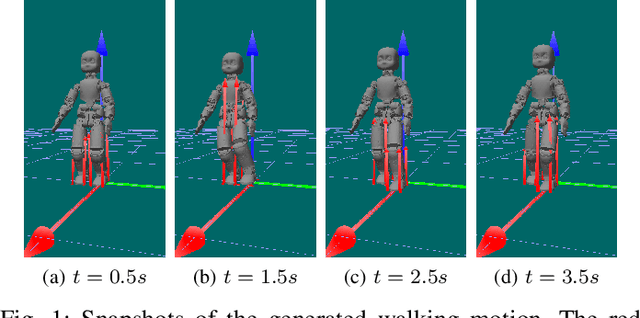
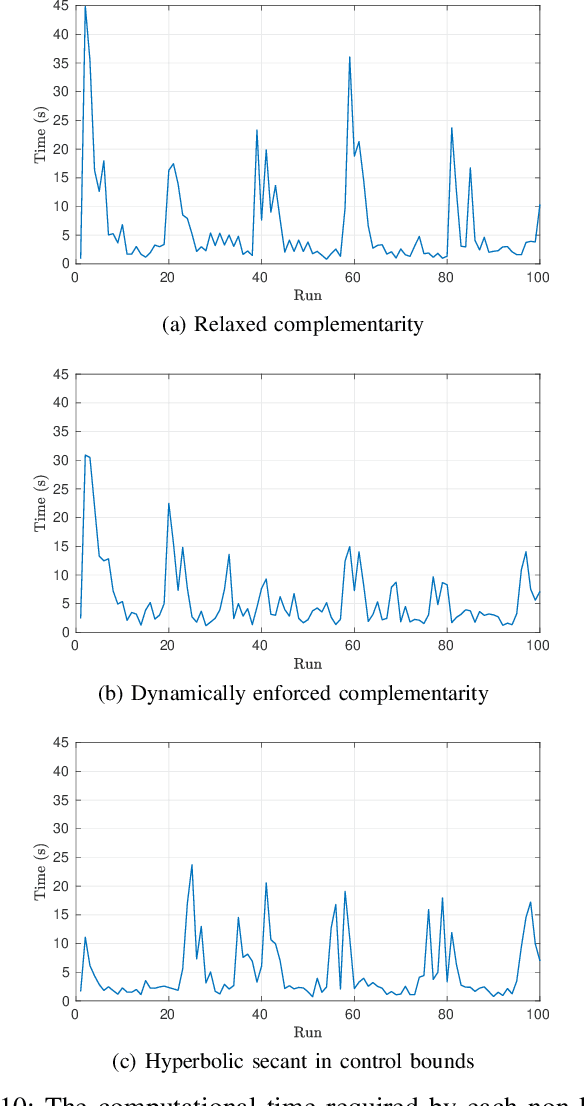
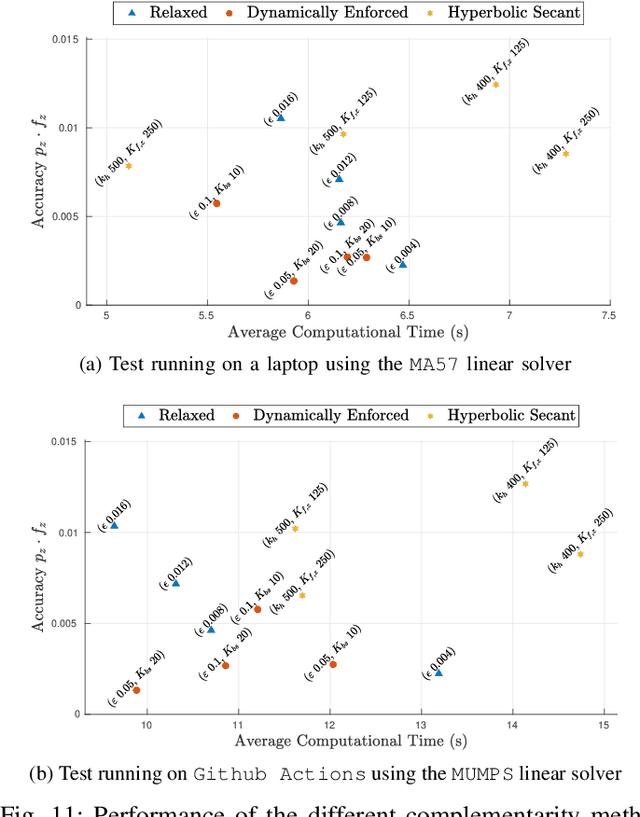
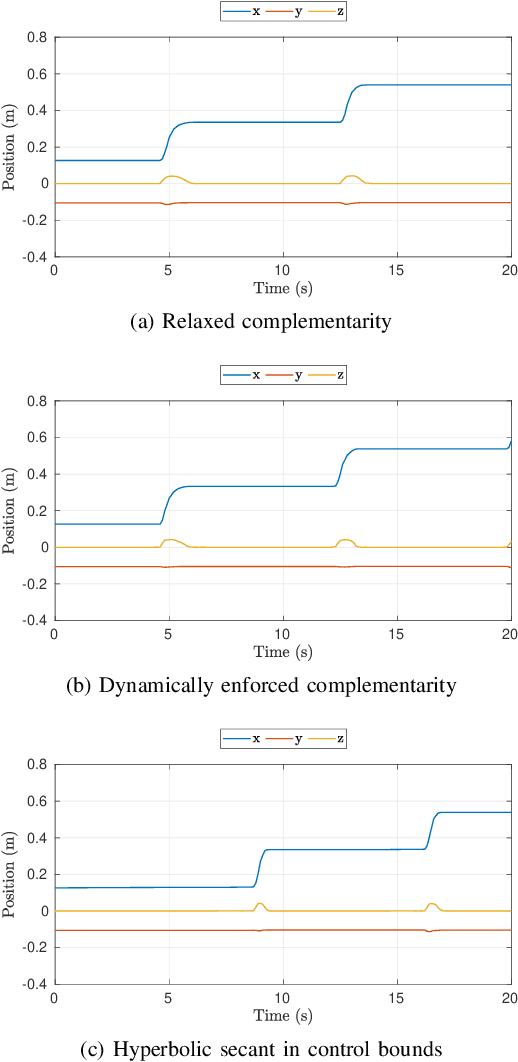
The paper presents a planner to generate walking trajectories by using the centroidal dynamics and the full kinematics of a humanoid robot. The interaction between the robot and the walking surface is modeled explicitly via new conditions, the \emph{Dynamical Complementarity Constraints}. The approach does not require a predefined contact sequence and generates the footsteps automatically. We characterize the robot control objective via a set of tasks, and we address it by solving an optimal control problem. We show that it is possible to achieve walking motions automatically by specifying a minimal set of references, such as a constant desired center of mass velocity and a reference point on the ground. Furthermore, we analyze how the contact modelling choices affect the computational time. We validate the approach by generating and testing walking trajectories for the humanoid robot iCub.