 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiConStruct: Causal Concept-based Explanations through Black-Box Distillation
Jan 26, 2024



Model interpretability plays a central role in human-AI decision-making systems. Ideally, explanations should be expressed using human-interpretable semantic concepts. Moreover, the causal relations between these concepts should be captured by the explainer to allow for reasoning about the explanations. Lastly, explanation methods should be efficient and not compromise the performance of the predictive task. Despite the rapid advances in AI explainability in recent years, as far as we know to date, no method fulfills these three properties. Indeed, mainstream methods for local concept explainability do not produce causal explanations and incur a trade-off between explainability and prediction performance. We present DiConStruct, an explanation method that is both concept-based and causal, with the goal of creating more interpretable local explanations in the form of structural causal models and concept attributions. Our explainer works as a distillation model to any black-box machine learning model by approximating its predictions while producing the respective explanations. Because of this, DiConStruct generates explanations efficiently while not impacting the black-box prediction task. We validate our method on an image dataset and a tabular dataset, showing that DiConStruct approximates the black-box models with higher fidelity than other concept explainability baselines, while providing explanations that include the causal relations between the concepts.
Lightweight Automated Feature Monitoring for Data Streams
Jul 19, 2022
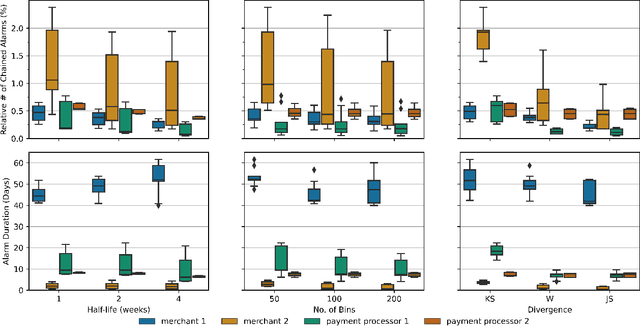
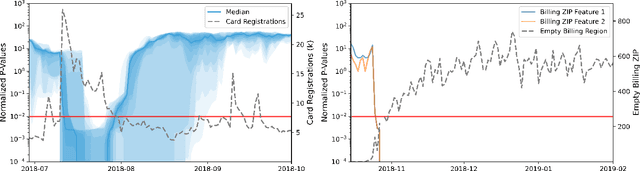
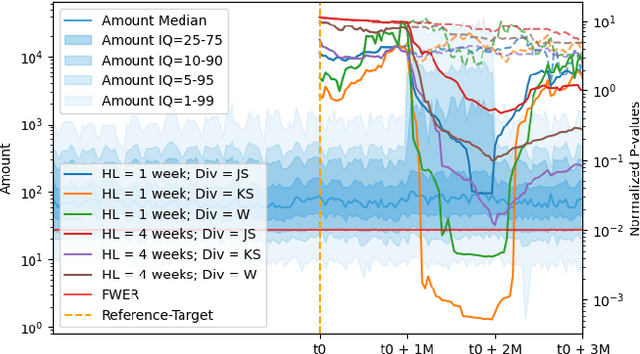
Monitoring the behavior of automated real-time stream processing systems has become one of the most relevant problems in real world applications. Such systems have grown in complexity relying heavily on high dimensional input data, and data hungry Machine Learning (ML) algorithms. We propose a flexible system, Feature Monitoring (FM), that detects data drifts in such data sets, with a small and constant memory footprint and a small computational cost in streaming applications. The method is based on a multi-variate statistical test and is data driven by design (full reference distributions are estimated from the data). It monitors all features that are used by the system, while providing an interpretable features ranking whenever an alarm occurs (to aid in root cause analysis). The computational and memory lightness of the system results from the use of Exponential Moving Histograms. In our experimental study, we analyze the system's behavior with its parameters and, more importantly, show examples where it detects problems that are not directly related to a single feature. This illustrates how FM eliminates the need to add custom signals to detect specific types of problems and that monitoring the available space of features is often enough.
ConceptDistil: Model-Agnostic Distillation of Concept Explanations
May 07, 2022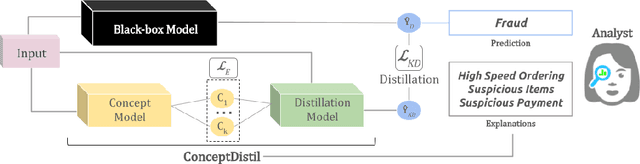
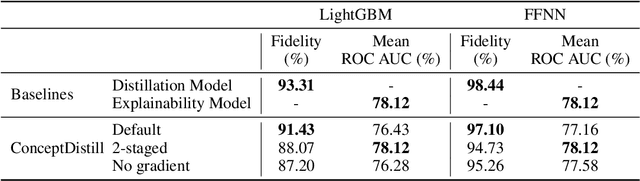
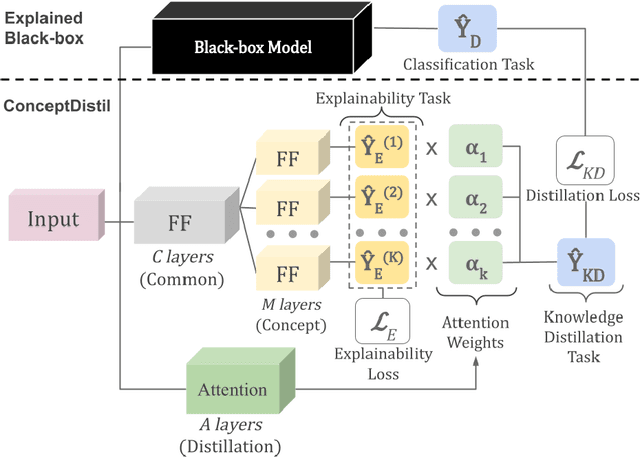

Concept-based explanations aims to fill the model interpretability gap for non-technical humans-in-the-loop. Previous work has focused on providing concepts for specific models (eg, neural networks) or data types (eg, images), and by either trying to extract concepts from an already trained network or training self-explainable models through multi-task learning. In this work, we propose ConceptDistil, a method to bring concept explanations to any black-box classifier using knowledge distillation. ConceptDistil is decomposed into two components:(1) a concept model that predicts which domain concepts are present in a given instance, and (2) a distillation model that tries to mimic the predictions of a black-box model using the concept model predictions. We validate ConceptDistil in a real world use-case, showing that it is able to optimize both tasks, bringing concept-explainability to any black-box model.
Data+Shift: Supporting visual investigation of data distribution shifts by data scientists
Apr 29, 2022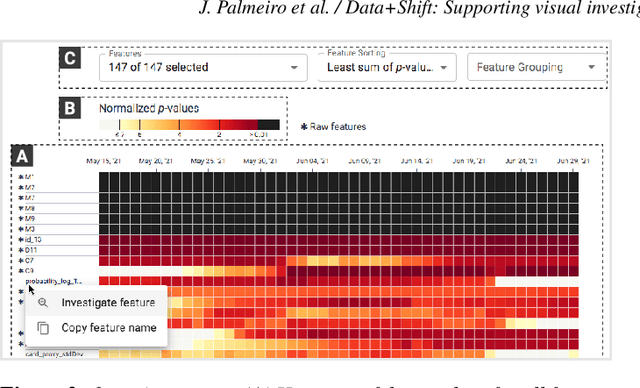
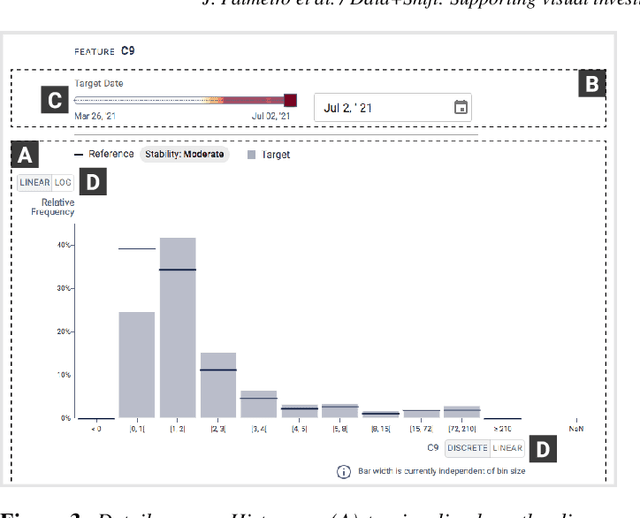
Machine learning on data streams is increasingly more present in multiple domains. However, there is often data distribution shift that can lead machine learning models to make incorrect decisions. While there are automatic methods to detect when drift is happening, human analysis, often by data scientists, is essential to diagnose the causes of the problem and adjust the system. We propose Data+Shift, a visual analytics tool to support data scientists in the task of investigating the underlying factors of shift in data features in the context of fraud detection. Design requirements were derived from interviews with data scientists. Data+Shift is integrated with JupyterLab and can be used alongside other data science tools. We validated our approach with a think-aloud experiment where a data scientist used the tool for a fraud detection use case.