 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARETE: an R package for Automated REtrieval from TExt with large language models
Nov 06, 20251. A hard stop for the implementation of rigorous conservation initiatives is our lack of key species data, especially occurrence data. Furthermore, researchers have to contend with an accelerated speed at which new information must be collected and processed due to anthropogenic activity. Publications ranging from scientific papers to gray literature contain this crucial information but their data are often not machine-readable, requiring extensive human work to be retrieved. 2. We present the ARETE R package, an open-source software aiming to automate data extraction of species occurrences powered by large language models, namely using the chatGPT Application Programming Interface. This R package integrates all steps of the data extraction and validation process, from Optical Character Recognition to detection of outliers and output in tabular format. Furthermore, we validate ARETE through systematic comparison between what is modelled and the work of human annotators. 3. We demonstrate the usefulness of the approach by comparing range maps produced using GBIF data and with those automatically extracted for 100 species of spiders. Newly extracted data allowed to expand the known Extent of Occurrence by a mean three orders of magnitude, revealing new areas where the species were found in the past, which mayhave important implications for spatial conservation planning and extinction risk assessments. 4. ARETE allows faster access to hitherto untapped occurrence data, a potential game changer in projects requiring such data. Researchers will be able to better prioritize resources, manually verifying selected species while maintaining automated extraction for the majority. This workflow also allows predicting available bibliographic data during project planning.
Lightweight Automated Feature Monitoring for Data Streams
Jul 19, 2022
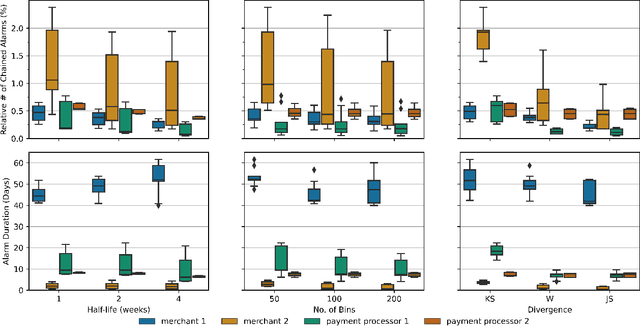
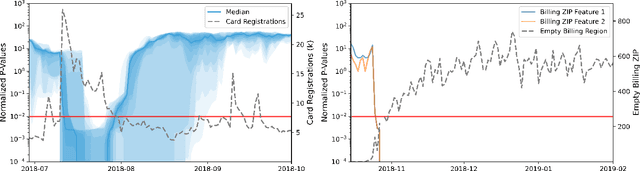
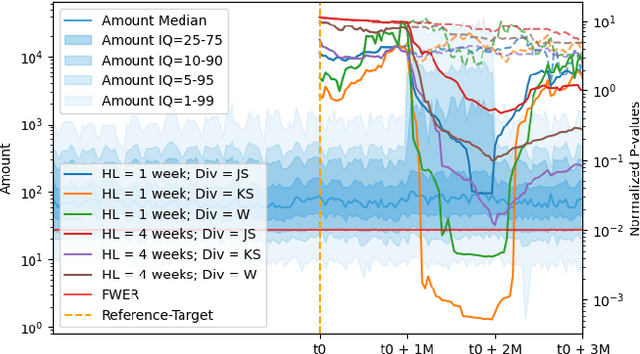
Monitoring the behavior of automated real-time stream processing systems has become one of the most relevant problems in real world applications. Such systems have grown in complexity relying heavily on high dimensional input data, and data hungry Machine Learning (ML) algorithms. We propose a flexible system, Feature Monitoring (FM), that detects data drifts in such data sets, with a small and constant memory footprint and a small computational cost in streaming applications. The method is based on a multi-variate statistical test and is data driven by design (full reference distributions are estimated from the data). It monitors all features that are used by the system, while providing an interpretable features ranking whenever an alarm occurs (to aid in root cause analysis). The computational and memory lightness of the system results from the use of Exponential Moving Histograms. In our experimental study, we analyze the system's behavior with its parameters and, more importantly, show examples where it detects problems that are not directly related to a single feature. This illustrates how FM eliminates the need to add custom signals to detect specific types of problems and that monitoring the available space of features is often enough.