 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MultiStream: A Simple and Fast Multiple Cameras Visual Monitor and Directly Streaming
Jul 13, 2022

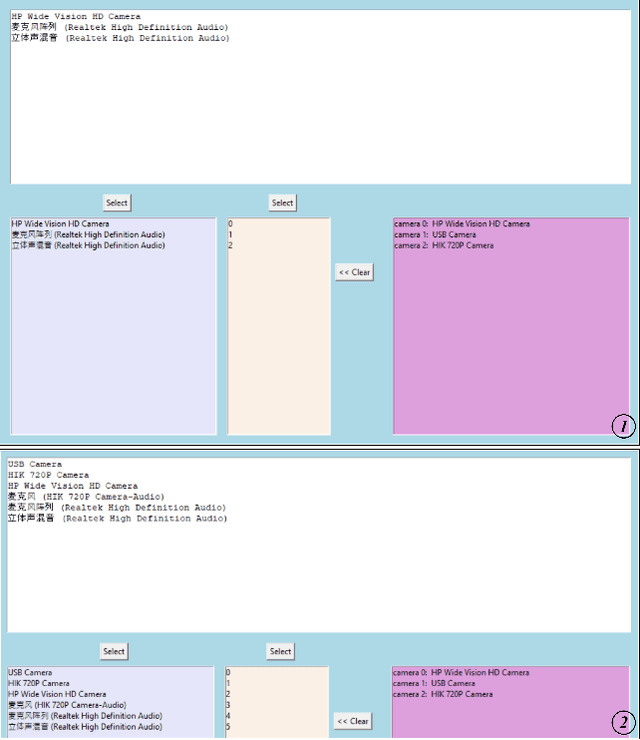
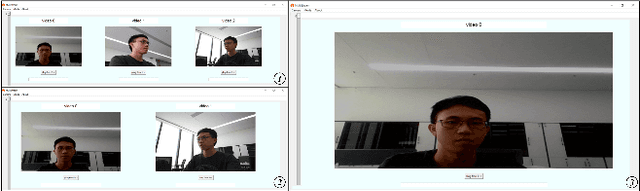
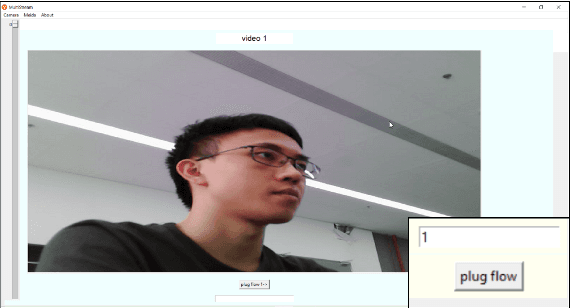
Monitoring and streaming is one of the most important applications for the real time cameras. The research of this has provided a novel design idea that uses the FFmpeg and Tkinter, combining with the libraries: OpenCV and PIL to develop a simple but fast streaming toolkit MultiSteam that can achieve the function of visible monitoring streaming for multiple simultaneously. MultiStream is able to automatically arrange the layout of the displays of multiple camera windows and intelligently analyze the input streaming URL to select the correct corresponding streaming communication protocol. Multiple cameras can be streamed with different communication protocols or the same protocol. Besides, the paper has tested the different streaming speeds for different protocols in camera streaming. MultiStream is able to gain the information of media equipment on the computer. The configuration information for media-id selection and multiple cameras streaming can be saved as json files.
Structure PLP-SLAM: Efficient Sparse Mapping and Localization using Point, Line and Plane for Monocular, RGB-D and Stereo Cameras
Jul 13, 2022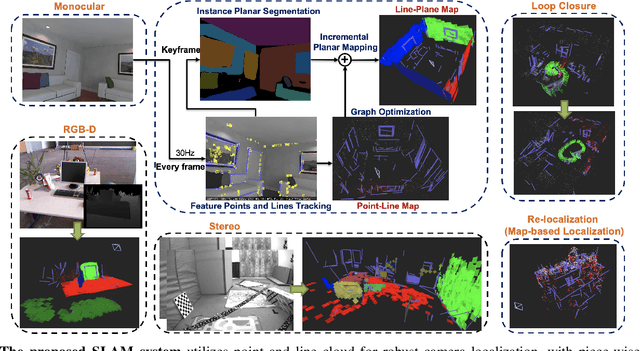
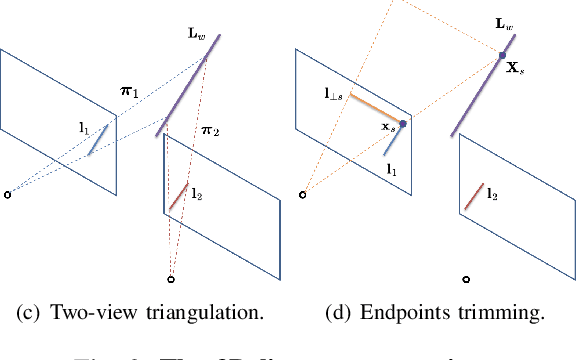
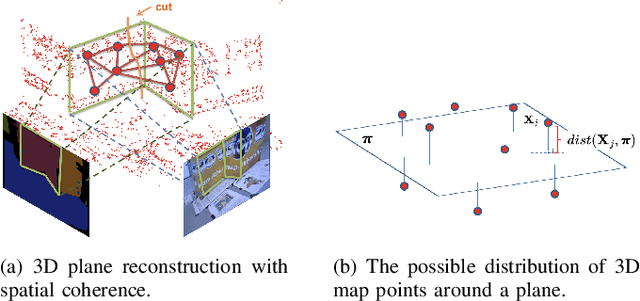

This paper demonstrates a visual SLAM system that utilizes point and line cloud for robust camera localization, simultaneously, with an embedded piece-wise planar reconstruction (PPR) module which in all provides a structural map. To build a scale consistent map in parallel with tracking, such as employing a single camera brings the challenge of reconstructing geometric primitives with scale ambiguity, and further introduces the difficulty in graph optimization of bundle adjustment (BA). We address these problems by proposing several run-time optimizations on the reconstructed lines and planes. The system is then extended with depth and stereo sensors based on the design of the monocular framework. The results show that our proposed SLAM tightly incorporates the semantic features to boost both frontend tracking as well as backend optimization. We evaluate our system exhaustively on various datasets, and open-source our code for the community (https://github.com/PeterFWS/Structure-PLP-SLAM).
A Hybrid Modelling Approach for Aerial Manipulators
Jun 17, 2022Aerial manipulators (AM) exhibit particularly challenging, non-linear dynamics; the UAV and the manipulator it is carrying form a tightly coupled dynamic system, mutually impacting each other. The mathematical model describing these dynamics forms the core of many solutions in non-linear control and deep reinforcement learning. Traditionally, the formulation of the dynamics involves Euler angle parametrization in the Lagrangian framework or quaternion parametrization in the Newton-Euler framework. The former has the disadvantage of giving birth to singularities and the latter being algorithmically complex. This work presents a hybrid solution, combining the benefits of both, namely a quaternion approach leveraging the Lagrangian framework, connecting the singularity-free parameterization with the algorithmic simplicity of the Lagrangian approach. We do so by offering detailed insights into the kinematic modeling process and the formulation of the dynamics of a general aerial manipulator. The obtained dynamics model is validated experimentally against a real-time physics engine. A practical application of the obtained dynamics model is shown in the context of a computed torque feedback controller (feedback linearization), where we analyze its real-time capability with increasingly complex models.
Approximate Vanishing Ideal Computations at Scale
Jul 04, 2022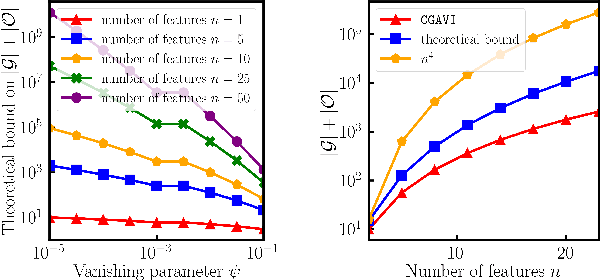

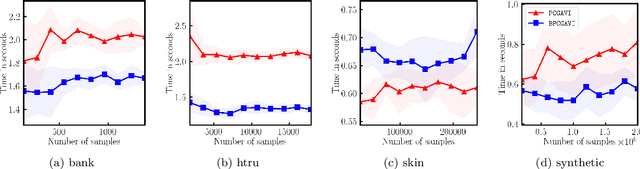

The approximate vanishing ideal of a set of points $X = \{\mathbf{x}_1, \ldots, \mathbf{x}_m\}\subseteq [0,1]^n$ is the set of polynomials that approximately evaluate to $0$ over all points $\mathbf{x} \in X$ and admits an efficient representation by a finite set of polynomials called generators. Algorithms that construct this set of generators are extensively studied but ultimately find little practical application because their computational complexities are thought to be superlinear in the number of samples $m$. In this paper, we focus on scaling up the Oracle Approximate Vanishing Ideal algorithm (OAVI), one of the most powerful of these methods. We prove that the computational complexity of OAVI is not superlinear but linear in the number of samples $m$ and polynomial in the number of features $n$, making OAVI an attractive preprocessing technique for large-scale machine learning. To further accelerate OAVI's training time, we propose two changes: First, as the name suggests, OAVI makes repeated oracle calls to convex solvers throughout its execution. By replacing the Pairwise Conditional Gradients algorithm, one of the standard solvers used in OAVI, with the faster Blended Pairwise Conditional Gradients algorithm, we illustrate how OAVI directly benefits from advancements in the study of convex solvers. Second, we propose Inverse Hessian Boosting (IHB): IHB exploits the fact that OAVI repeatedly solves quadratic convex optimization problems that differ only by very little and whose solutions can be written in closed form using inverse Hessian information. By efficiently updating the inverse of the Hessian matrix, the convex optimization problems can be solved almost instantly, accelerating OAVI's training time by up to multiple orders of magnitude. We complement our theoretical analysis with extensive numerical experiments on data sets whose sample numbers are in the millions.
ARShoe: Real-Time Augmented Reality Shoe Try-on System on Smartphones
Aug 24, 2021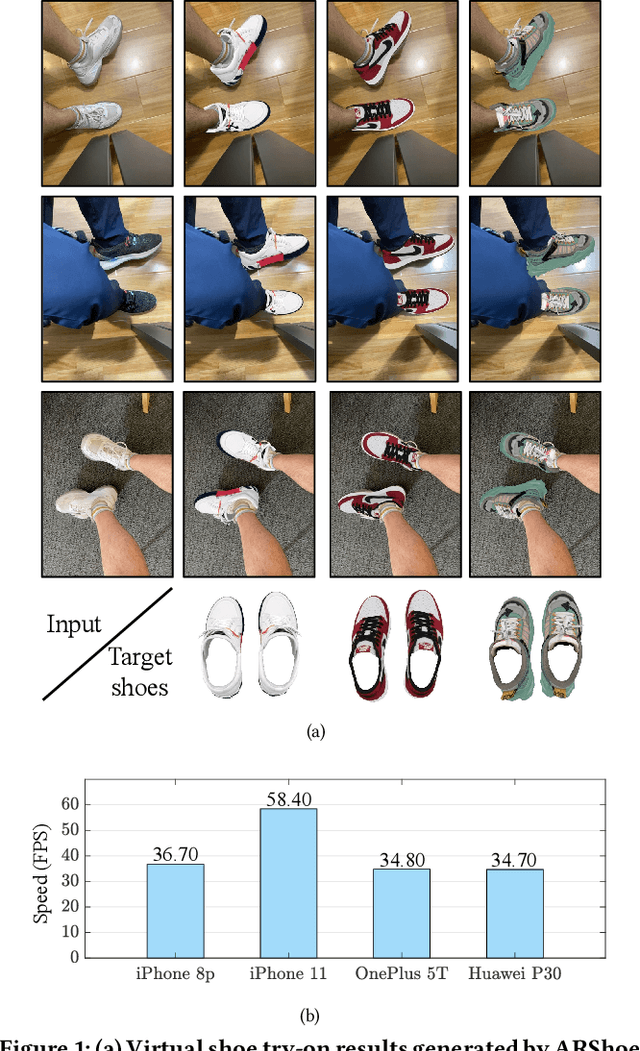
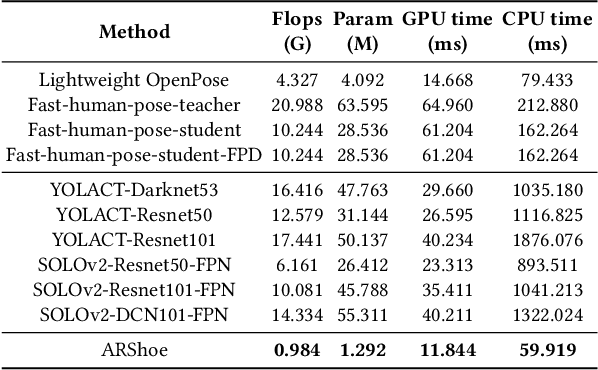
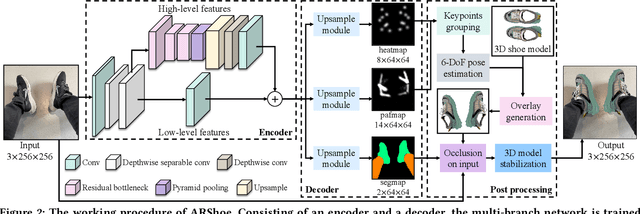
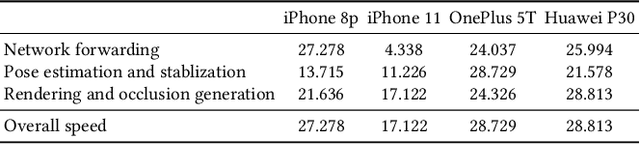
Virtual try-on technology enables users to try various fashion items using augmented reality and provides a convenient online shopping experience. However, most previous works focus on the virtual try-on for clothes while neglecting that for shoes, which is also a promising task. To this concern, this work proposes a real-time augmented reality virtual shoe try-on system for smartphones, namely ARShoe. Specifically, ARShoe adopts a novel multi-branch network to realize pose estimation and segmentation simultaneously. A solution to generate realistic 3D shoe model occlusion during the try-on process is presented. To achieve a smooth and stable try-on effect, this work further develop a novel stabilization method. Moreover, for training and evaluation, we construct the very first large-scale foot benchmark with multiple virtual shoe try-on task-related labels annotated. Exhaustive experiments on our newly constructed benchmark demonstrate the satisfying performance of ARShoe. Practical tests on common smartphones validate the real-time performance and stabilization of the proposed approach.
Prototype-Guided Continual Adaptation for Class-Incremental Unsupervised Domain Adaptation
Jul 22, 2022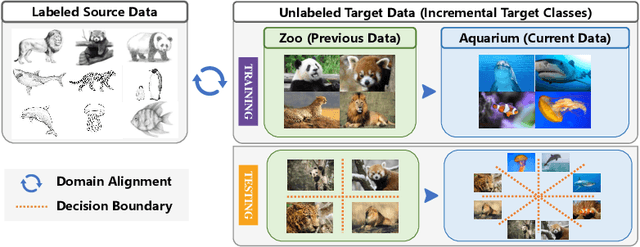

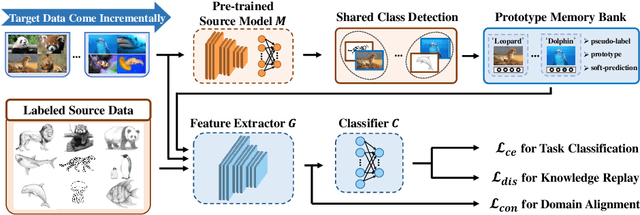

This paper studies a new, practical but challenging problem, called Class-Incremental Unsupervised Domain Adaptation (CI-UDA), where the labeled source domain contains all classes, but the classes in the unlabeled target domain increase sequentially. This problem is challenging due to two difficulties. First, source and target label sets are inconsistent at each time step, which makes it difficult to conduct accurate domain alignment. Second, previous target classes are unavailable in the current step, resulting in the forgetting of previous knowledge. To address this problem, we propose a novel Prototype-guided Continual Adaptation (ProCA) method, consisting of two solution strategies. 1) Label prototype identification: we identify target label prototypes by detecting shared classes with cumulative prediction probabilities of target samples. 2) Prototype-based alignment and replay: based on the identified label prototypes, we align both domains and enforce the model to retain previous knowledge. With these two strategies, ProCA is able to adapt the source model to a class-incremental unlabeled target domain effectively. Extensive experiments demonstrate the effectiveness and superiority of ProCA in resolving CI-UDA. The source code is available at https://github.com/Hongbin98/ProCA.git
A Relative Church-Turing-Deutsch Thesis from Special Relativity and Undecidability
Jun 13, 2022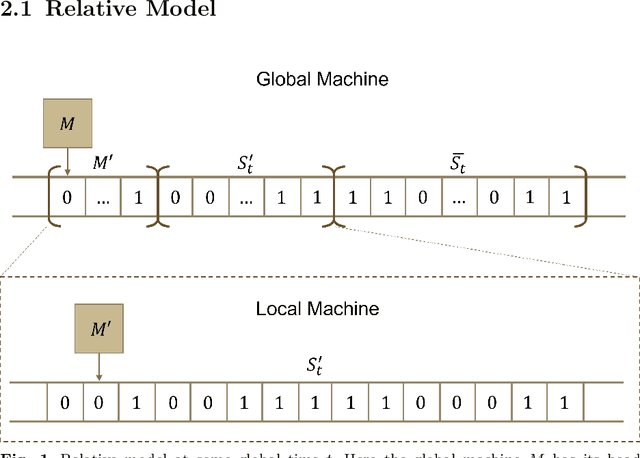
Beginning with Turing's seminal work in 1950, artificial intelligence proposes that consciousness can be simulated by a Turing machine. This implies a potential theory of everything where the universe is a simulation on a computer, which begs the question of whether we can prove we exist in a simulation. In this work, we construct a relative model of computation where a computable \textit{local} machine is simulated by a \textit{global}, classical Turing machine. We show that the problem of the local machine computing \textbf{simulation properties} of its global simulator is undecidable in the same sense as the Halting problem. Then, we show that computing the time, space, or error accumulated by the global simulator are simulation properties and therefore are undecidable. These simulation properties give rise to special relativistic effects in the relative model which we use to construct a relative Church-Turing-Deutsch thesis where a global, classical Turing machine computes quantum mechanics for a local machine with the same constant-time local computational complexity as experienced in our universe.
Metadata-enhanced contrastive learning from retinal optical coherence tomography images
Aug 04, 2022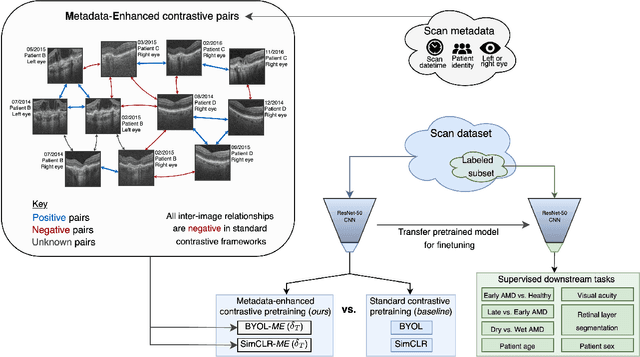
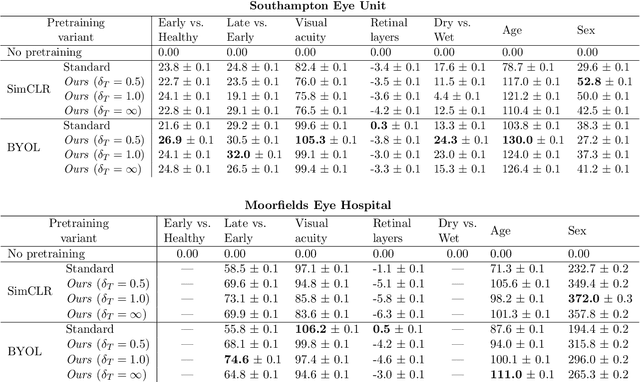
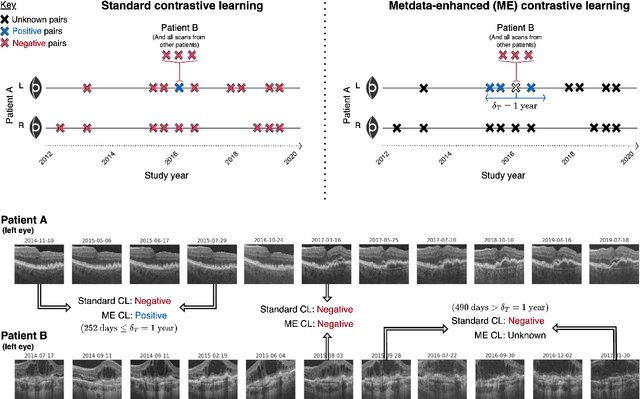
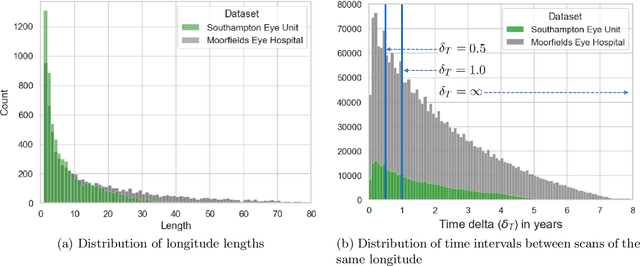
Supervised deep learning algorithms hold great potential to automate screening, monitoring and grading of medical images. However, training performant models has typically required vast quantities of labelled data, which is scarcely available in the medical domain. Self-supervised contrastive frameworks relax this dependency by first learning from unlabelled images. In this work we show that pretraining with two contrastive methods, SimCLR and BYOL, improves the utility of deep learning with regard to the clinical assessment of age-related macular degeneration (AMD). In experiments using two large clinical datasets containing 170,427 optical coherence tomography (OCT) images of 7,912 patients, we evaluate benefits attributed to pretraining across seven downstream tasks ranging from AMD stage and type classification to prediction of functional endpoints to segmentation of retinal layers, finding performance significantly increased in six out of seven tasks with fewer labels. However, standard contrastive frameworks have two known weaknesses that are detrimental to pretraining in the medical domain. Several of the image transformations used to create positive contrastive pairs are not applicable to greyscale medical scans. Furthermore, medical images often depict the same anatomical region and disease severity, resulting in numerous misleading negative pairs. To address these issues we develop a novel metadata-enhanced approach that exploits the rich set of inherently available patient information. To this end we employ records for patient identity, eye position (i.e. left or right) and time series data to indicate the typically unknowable set of inter-image contrastive relationships. By leveraging this often neglected information our metadata-enhanced contrastive pretraining leads to further benefits and outperforms conventional contrastive methods in five out of seven downstream tasks.
Texture Generation Using Graph Generative Adversarial Network And Differentiable Rendering
Jun 17, 2022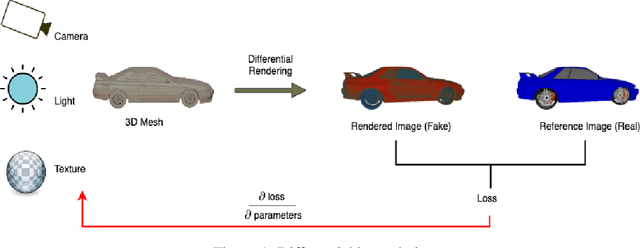
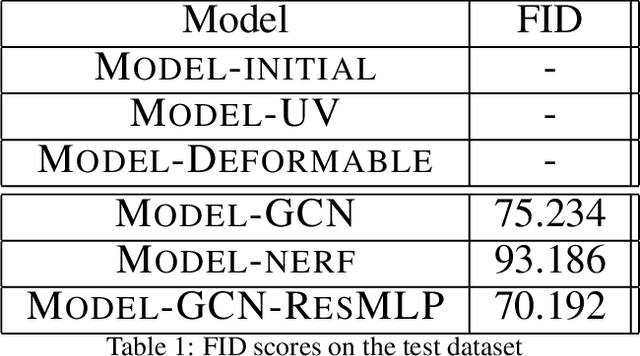
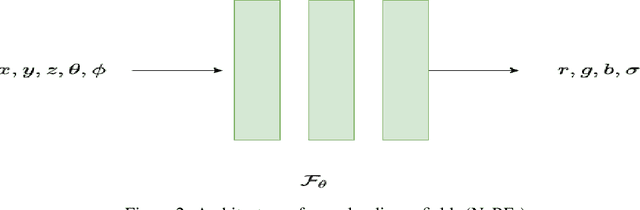
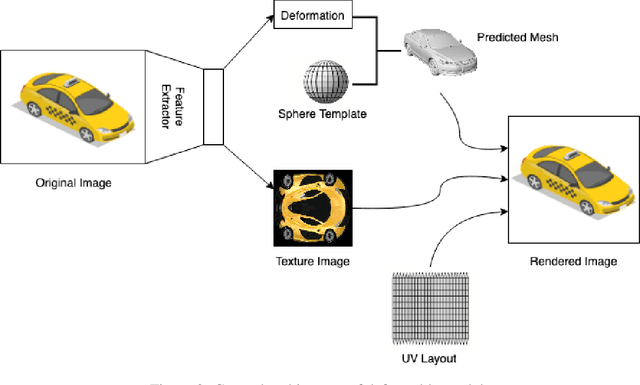
Novel texture synthesis for existing 3D mesh models is an important step towards photo realistic asset generation for existing simulators. But existing methods inherently work in the 2D image space which is the projection of the 3D space from a given camera perspective. These methods take camera angle, 3D model information, lighting information and generate photorealistic 2D image. To generate a photorealistic image from another perspective or lighting, we need to make a computationally expensive forward pass each time we change the parameters. Also, it is hard to generate such images for a simulator that can satisfy the temporal constraints the sequences of images should be similar but only need to change the viewpoint of lighting as desired. The solution can not be directly integrated with existing tools like Blender and Unreal Engine. Manual solution is expensive and time consuming. We thus present a new system called a graph generative adversarial network (GGAN) that can generate textures which can be directly integrated into a given 3D mesh models with tools like Blender and Unreal Engine and can be simulated from any perspective and lighting condition easily.
Bio-inspired Intelligence with Applications to Robotics: A Survey
Jun 17, 2022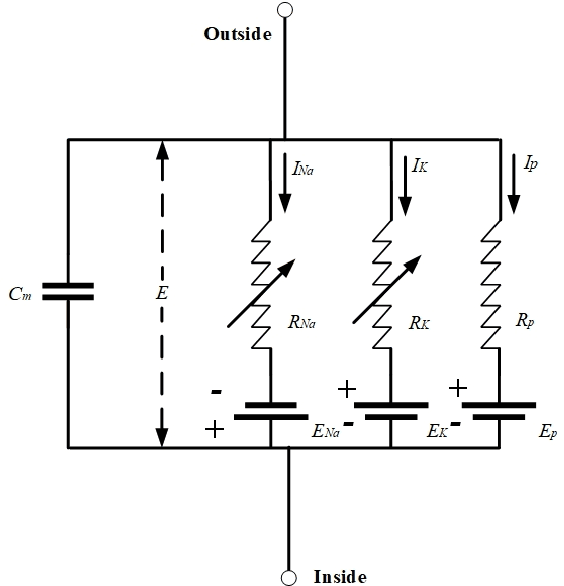
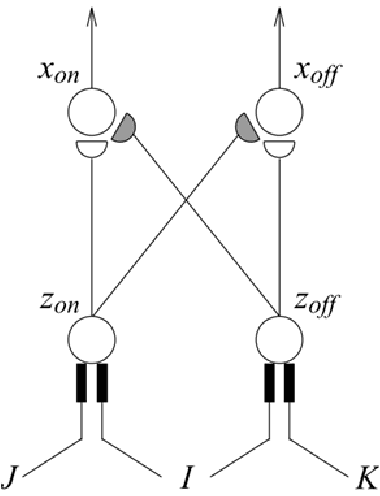
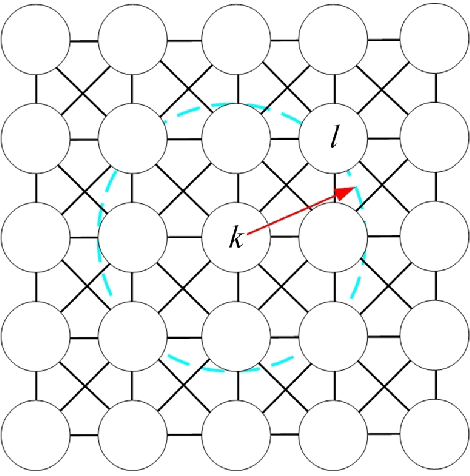
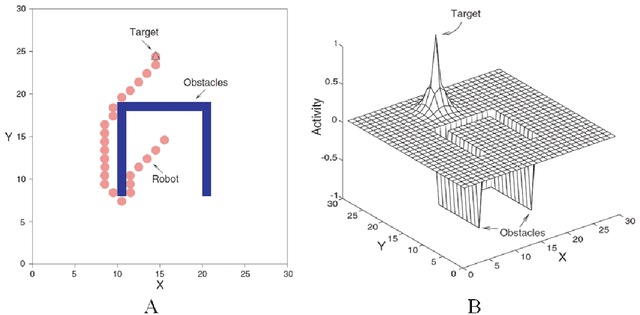
In the past decades, considerable attention has been paid to bio-inspired intelligence and its applications to robotics. This paper provides a comprehensive survey of bio-inspired intelligence, with a focus on neurodynamics approaches, to various robotic applications, particularly to path planning and control of autonomous robotic systems. Firstly, the bio-inspired shunting model and its variants (additive model and gated dipole model) are introduced, and their main characteristics are given in detail. Then, two main neurodynamics applications to real-time path planning and control of various robotic systems are reviewed. A bio-inspired neural network framework, in which neurons are characterized by the neurodynamics models, is discussed for mobile robots, cleaning robots, and underwater robots. The bio-inspired neural network has been widely used in real-time collision-free navigation and cooperation without any learning procedures, global cost functions, and prior knowledge of the dynamic environment. In addition, bio-inspired backstepping controllers for various robotic systems, which are able to eliminate the speed jump when a large initial tracking error occurs, are further discussed. Finally, the current challenges and future research directions are discussed in this paper.