 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
StarVQA: Space-Time Attention for Video Quality Assessment
Aug 22, 2021
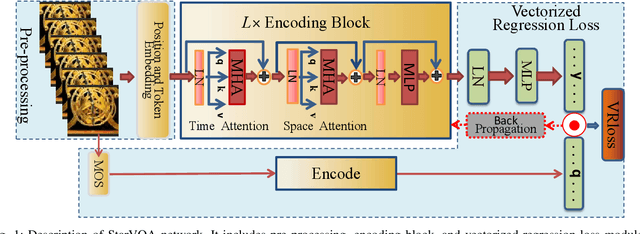
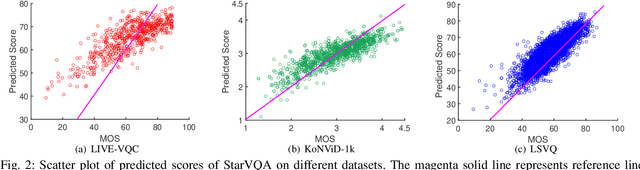
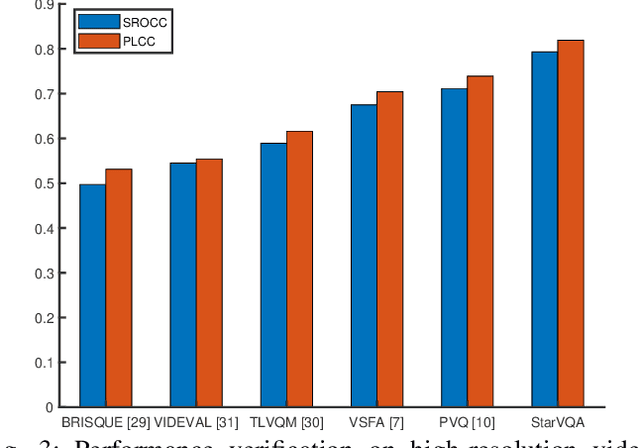
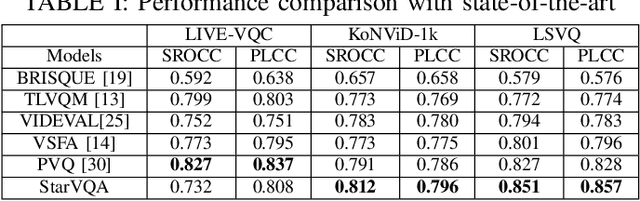
The attention mechanism is blooming in computer vision nowadays. However, its application to video quality assessment (VQA) has not been reported. Evaluating the quality of in-the-wild videos is challenging due to the unknown of pristine reference and shooting distortion. This paper presents a novel \underline{s}pace-\underline{t}ime \underline{a}ttention network fo\underline{r} the \underline{VQA} problem, named StarVQA. StarVQA builds a Transformer by alternately concatenating the divided space-time attention. To adapt the Transformer architecture for training, StarVQA designs a vectorized regression loss by encoding the mean opinion score (MOS) to the probability vector and embedding a special vectorized label token as the learnable variable. To capture the long-range spatiotemporal dependencies of a video sequence, StarVQA encodes the space-time position information of each patch to the input of the Transformer. Various experiments are conducted on the de-facto in-the-wild video datasets, including LIVE-VQC, KoNViD-1k, LSVQ, and LSVQ-1080p. Experimental results demonstrate the superiority of the proposed StarVQA over the state-of-the-art. Code and model will be available at: https://github.com/DVL/StarVQA.
Towards Psychologically-Grounded Dynamic Preference Models
Aug 06, 2022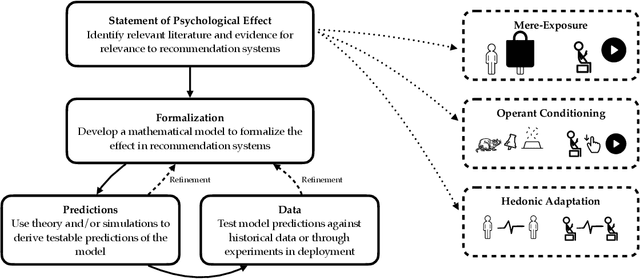
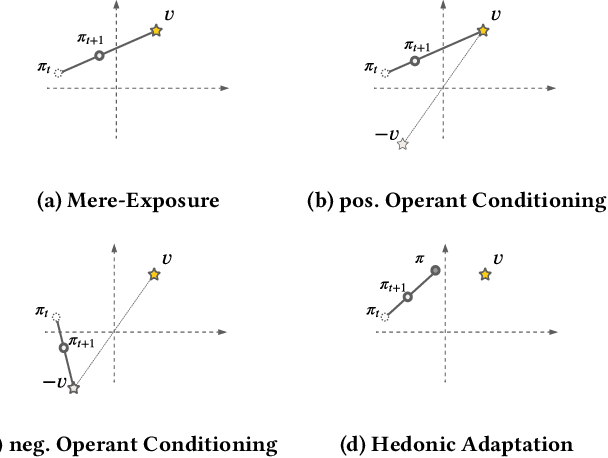
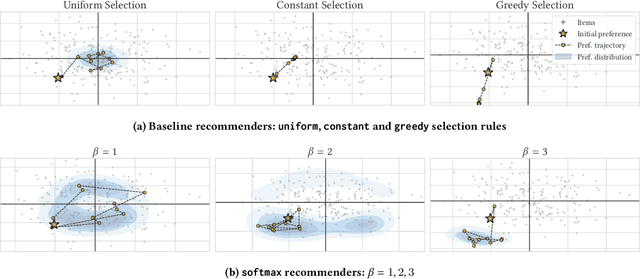
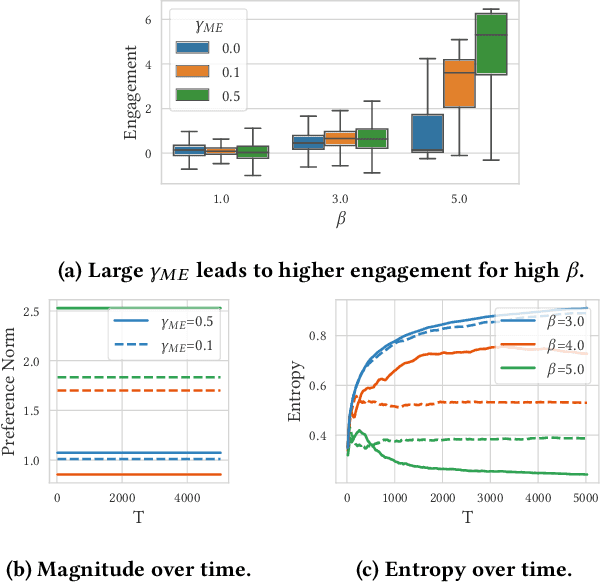
Designing recommendation systems that serve content aligned with time varying preferences requires proper accounting of the feedback effects of recommendations on human behavior and psychological condition. We argue that modeling the influence of recommendations on people's preferences must be grounded in psychologically plausible models. We contribute a methodology for developing grounded dynamic preference models. We demonstrate this method with models that capture three classic effects from the psychology literature: Mere-Exposure, Operant Conditioning, and Hedonic Adaptation. We conduct simulation-based studies to show that the psychological models manifest distinct behaviors that can inform system design. Our study has two direct implications for dynamic user modeling in recommendation systems. First, the methodology we outline is broadly applicable for psychologically grounding dynamic preference models. It allows us to critique recent contributions based on their limited discussion of psychological foundation and their implausible predictions. Second, we discuss implications of dynamic preference models for recommendation systems evaluation and design. In an example, we show that engagement and diversity metrics may be unable to capture desirable recommendation system performance.
How to Train Your HiPPO: State Space Models with Generalized Orthogonal Basis Projections
Jun 24, 2022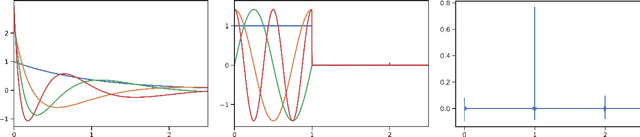

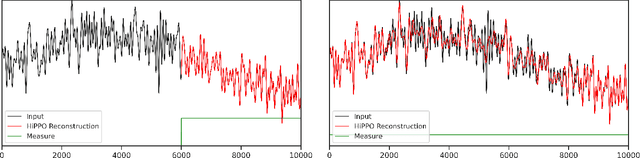

Linear time-invariant state space models (SSM) are a classical model from engineering and statistics, that have recently been shown to be very promising in machine learning through the Structured State Space sequence model (S4). A core component of S4 involves initializing the SSM state matrix to a particular matrix called a HiPPO matrix, which was empirically important for S4's ability to handle long sequences. However, the specific matrix that S4 uses was actually derived in previous work for a particular time-varying dynamical system, and the use of this matrix as a time-invariant SSM had no known mathematical interpretation. Consequently, the theoretical mechanism by which S4 models long-range dependencies actually remains unexplained. We derive a more general and intuitive formulation of the HiPPO framework, which provides a simple mathematical interpretation of S4 as a decomposition onto exponentially-warped Legendre polynomials, explaining its ability to capture long dependencies. Our generalization introduces a theoretically rich class of SSMs that also lets us derive more intuitive S4 variants for other bases such as the Fourier basis, and explains other aspects of training S4, such as how to initialize the important timescale parameter. These insights improve S4's performance to 86% on the Long Range Arena benchmark, with 96% on the most difficult Path-X task.
A Deep-Learning Usability Expansion Model of Ocean Observations
Jun 03, 2022
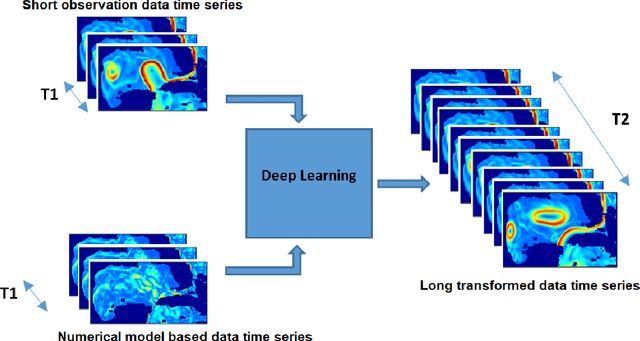
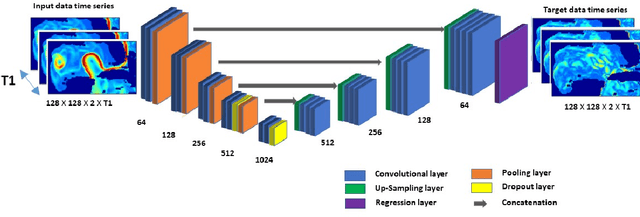
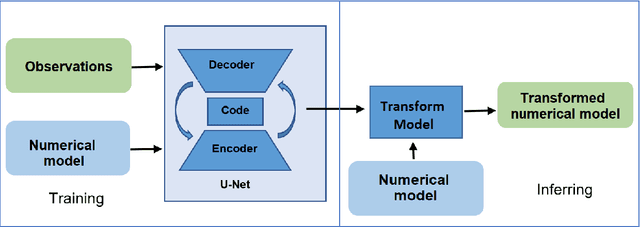
Today's ocean numerical prediction skills depend on the availability of in-situ and remote ocean observations at the time of the predictions only. Because observations are scarce and discontinuous in time and space, numerical models are often unable to accurately model and predict real ocean dynamics, leading to a lack of fulfillment of a range of services that require reliable predictions at various temporal and spatial scales. The process of constraining free numerical models with observations is known as data assimilation. The primary objective is to minimize the misfit of model states with the observations while respecting the rules of physics. The caveat of this approach is that measurements are used only once, at the time of the prediction. The information contained in the history of the measurements and its role in the determinism of the prediction is, therefore, not accounted for. Consequently, historical measurement cannot be used in real-time forecasting systems. The research presented in this paper provides a novel approach rooted in artificial intelligence to expand the usability of observations made before the time of the prediction. Our approach is based on the re-purpose of an existing deep learning model, called U-Net, designed specifically for image segmentation analysis in the biomedical field. U-Net is used here to create a Transform Model that retains the temporal and spatial evolution of the differences between model and observations to produce a correction in the form of regression weights that evolves spatially and temporally with the model both forward and backward in time, beyond the observation period. Using virtual observations, we show that the usability of the observation can be extended up to a one year prior or post observations.
FEANet: Feature-Enhanced Attention Network for RGB-Thermal Real-time Semantic Segmentation
Oct 18, 2021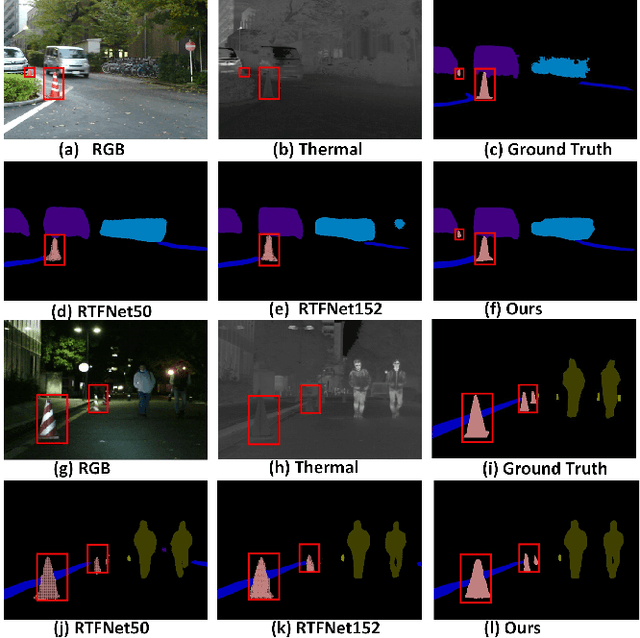
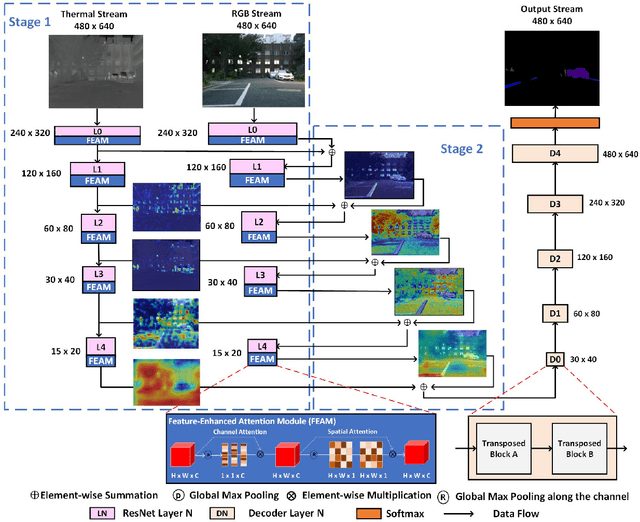
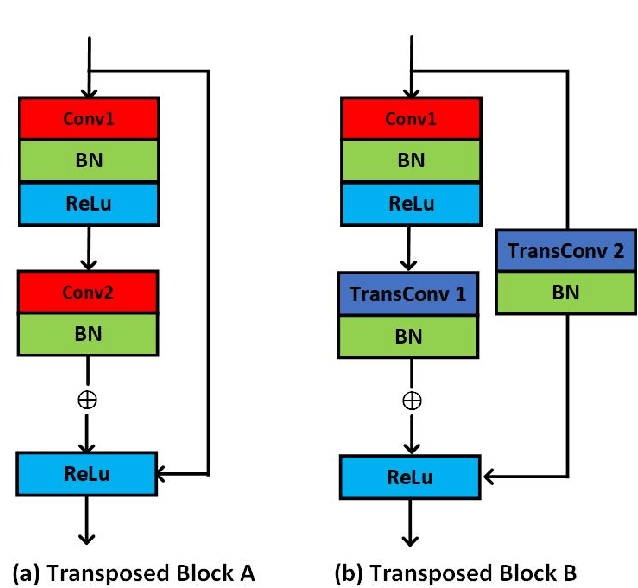
The RGB-Thermal (RGB-T) information for semantic segmentation has been extensively explored in recent years. However, most existing RGB-T semantic segmentation usually compromises spatial resolution to achieve real-time inference speed, which leads to poor performance. To better extract detail spatial information, we propose a two-stage Feature-Enhanced Attention Network (FEANet) for the RGB-T semantic segmentation task. Specifically, we introduce a Feature-Enhanced Attention Module (FEAM) to excavate and enhance multi-level features from both the channel and spatial views. Benefited from the proposed FEAM module, our FEANet can preserve the spatial information and shift more attention to high-resolution features from the fused RGB-T images. Extensive experiments on the urban scene dataset demonstrate that our FEANet outperforms other state-of-the-art (SOTA) RGB-T methods in terms of objective metrics and subjective visual comparison (+2.6% in global mAcc and +0.8% in global mIoU). For the 480 x 640 RGB-T test images, our FEANet can run with a real-time speed on an NVIDIA GeForce RTX 2080 Ti card.
Boosted Embeddings for Time Series Forecasting
Apr 10, 2021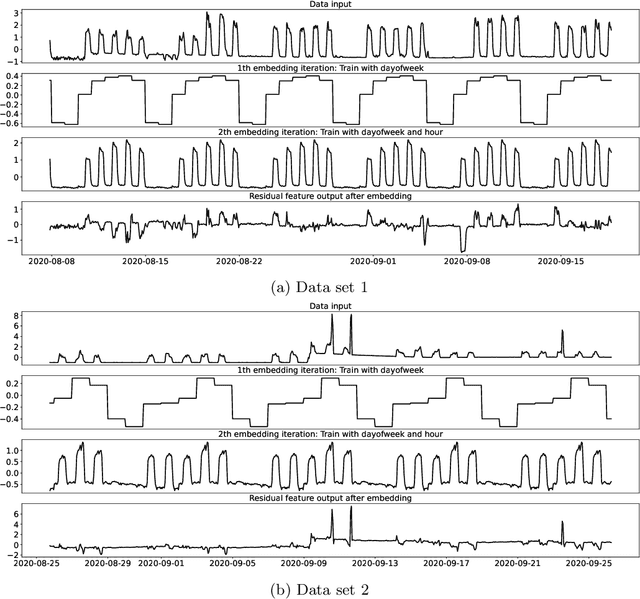

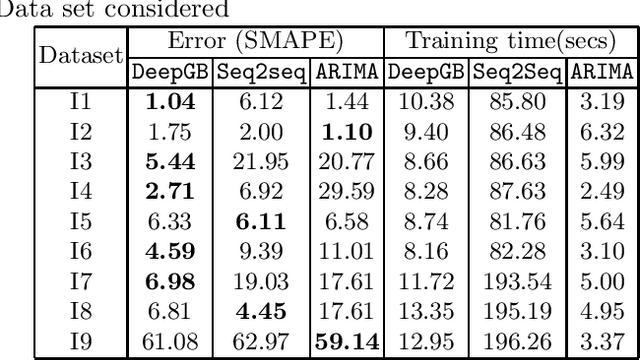
Time series forecasting is a fundamental task emerging from diverse data-driven applications. Many advanced autoregressive methods such as ARIMA were used to develop forecasting models. Recently, deep learning based methods such as DeepAr, NeuralProphet, Seq2Seq have been explored for time series forecasting problem. In this paper, we propose a novel time series forecast model, DeepGB. We formulate and implement a variant of Gradient boosting wherein the weak learners are DNNs whose weights are incrementally found in a greedy manner over iterations. In particular, we develop a new embedding architecture that improves the performance of many deep learning models on time series using Gradient boosting variant. We demonstrate that our model outperforms existing comparable state-of-the-art models using real-world sensor data and public dataset.
A Case Study Analysis for Designing a Lunar Navigation Satellite System with Time-Transfer from Earth-GPS
Jan 03, 2022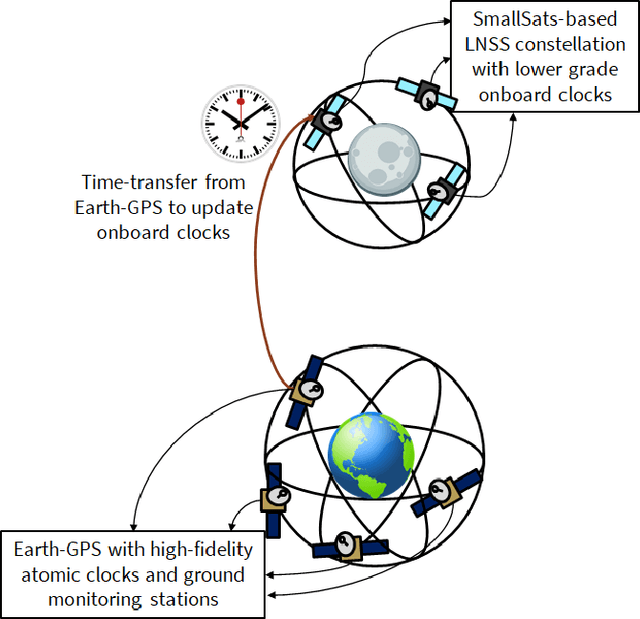

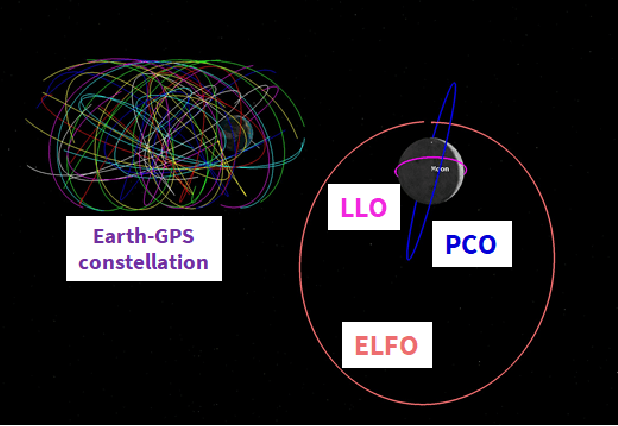
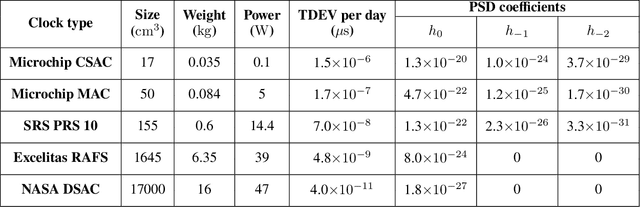
Recently, there has been a growing interest in the use of a SmallSat platform for the future Lunar Navigation Satellite System (LNSS) to allow for cost-effectiveness and rapid deployment. However, many design choices are yet to be finalized for the SmallSat-based LNSS, including the onboard clock and the orbit type. As compared to the legacy Earth-GPS, designing an LNSS poses unique challenges: (a) restricted Size, Weight, and Power (SWaP) of the onboard clock, which limits the timing stability; (b) limited lunar ground monitoring stations, which engenders a greater preference toward stable LNSS satellite orbits. In this current work, we analyze the trade-off between different design considerations related to the onboard clock and the lunar orbit type for designing an LNSS with time-transfer from Earth-GPS. Our proposed time-transfer architecture combines the intermittently available Earth-GPS signals in a timing filter to alleviate the cost and SWaP requirements of the onboard clocks. Specifically, we conduct multiple case studies with different grades of low-SWaP clocks and various previously studied lunar orbit types. We estimate the lunar User Equivalent Range Error (UERE) metric to characterize the ranging accuracy of signals transmitted from an LNSS satellite. Using the Systems Tool Kit (STK)-based simulation setup from Analytical Graphics, Inc. (AGI), we evaluate the lunar UERE across various case studies of the LNSS design to demonstrate comparable performance as that of the legacy Earth-GPS, even while using a low-SWaP onboard clock. We further perform sensitivity analysis to investigate the variation in the lunar UERE metric across different case studies as the Earth-GPS measurement update rates are varied.
HelixFold: An Efficient Implementation of AlphaFold2 using PaddlePaddle
Jul 13, 2022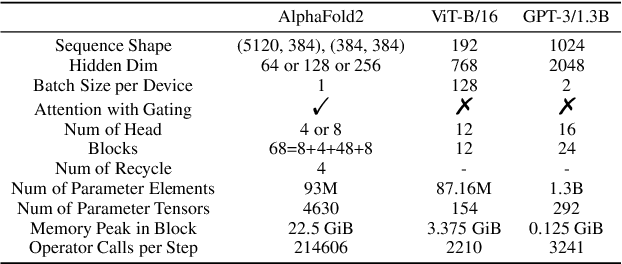
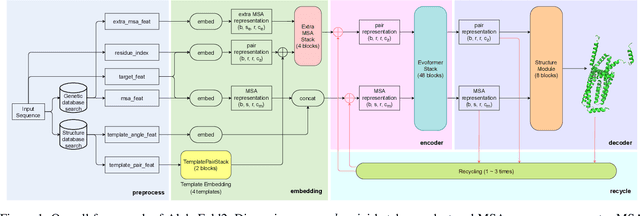

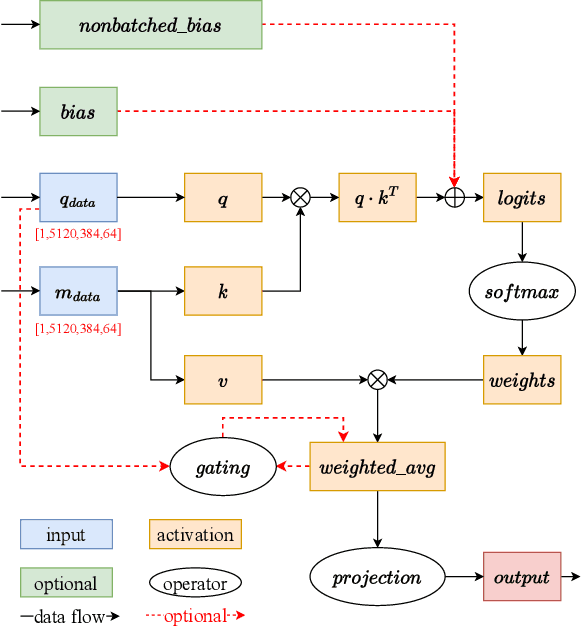
Accurate protein structure prediction can significantly accelerate the development of life science. The accuracy of AlphaFold2, a frontier end-to-end structure prediction system, is already close to that of the experimental determination techniques. Due to the complex model architecture and large memory consumption, it requires lots of computational resources and time to implement the training and inference of AlphaFold2 from scratch. The cost of running the original AlphaFold2 is expensive for most individuals and institutions. Therefore, reducing this cost could accelerate the development of life science. We implement AlphaFold2 using PaddlePaddle, namely HelixFold, to improve training and inference speed and reduce memory consumption. The performance is improved by operator fusion, tensor fusion, and hybrid parallelism computation, while the memory is optimized through Recompute, BFloat16, and memory read/write in-place. Compared with the original AlphaFold2 (implemented with Jax) and OpenFold (implemented with PyTorch), HelixFold needs only 7.5 days to complete the full end-to-end training and only 5.3 days when using hybrid parallelism, while both AlphaFold2 and OpenFold take about 11 days. HelixFold saves 1x training time. We verified that HelixFold's accuracy could be on par with AlphaFold2 on the CASP14 and CAMEO datasets. HelixFold's code is available on GitHub for free download: https://github.com/PaddlePaddle/PaddleHelix/tree/dev/apps/protein_folding/helixfold, and we also provide stable web services on https://paddlehelix.baidu.com/app/drug/protein/forecast.
Learning robot inverse dynamics using sparse online Gaussian process with forgetting mechanism
Aug 06, 2022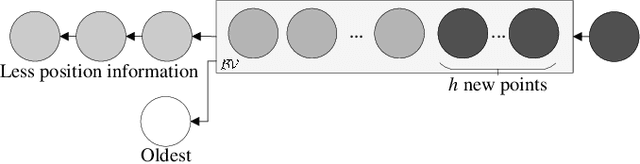
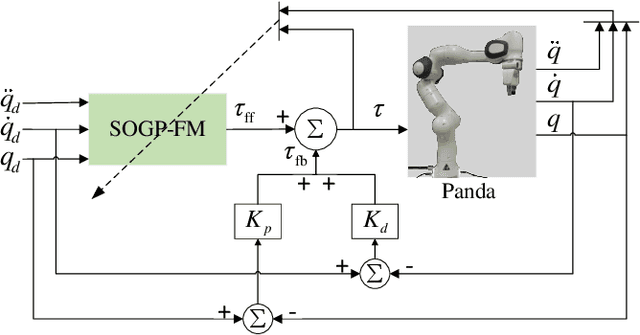
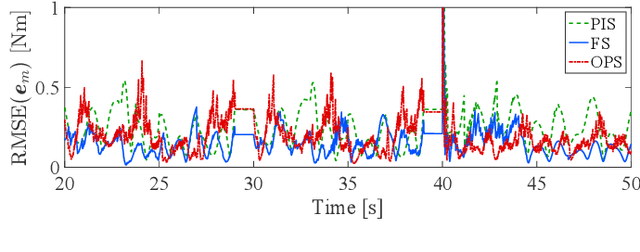
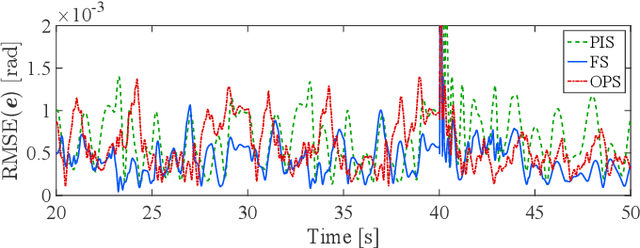
Online Gaussian processes (GPs), typically used for learning models from time-series data, are more flexible and robust than offline GPs. Both local and sparse approximations of GPs can efficiently learn complex models online. Yet, these approaches assume that all signals are relatively accurate and that all data are available for learning without misleading data. Besides, the online learning capacity of GPs is limited for high-dimension problems and long-term tasks in practice. This paper proposes a sparse online GP (SOGP) with a forgetting mechanism to forget distant model information at a specific rate. The proposed approach combines two general data deletion schemes for the basis vector set of SOGP: The position information-based scheme and the oldest points-based scheme. We apply our approach to learn the inverse dynamics of a collaborative robot with 7 degrees of freedom under a two-segment trajectory tracking problem with task switching. Both simulations and experiments have shown that the proposed approach achieves better tracking accuracy and predictive smoothness compared with the two general data deletion schemes.
Language Model Cascades
Jul 21, 2022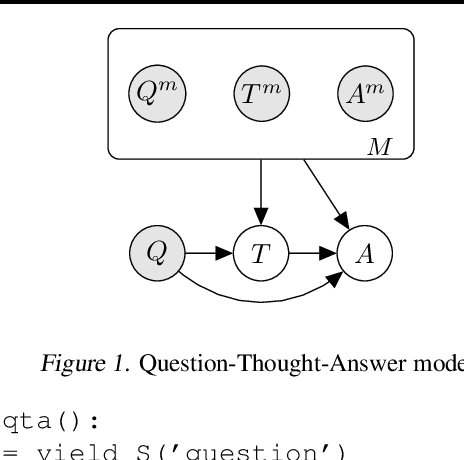
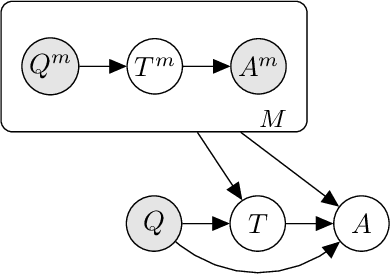
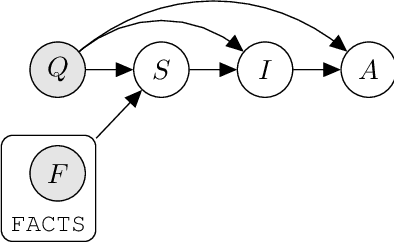
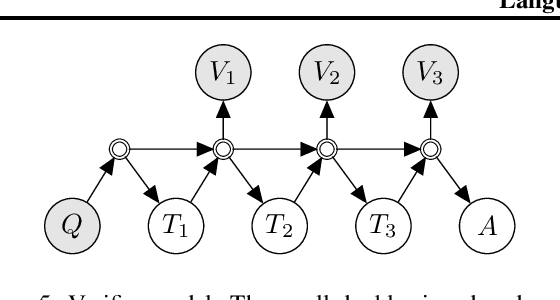
Prompted models have demonstrated impressive few-shot learning abilities. Repeated interactions at test-time with a single model, or the composition of multiple models together, further expands capabilities. These compositions are probabilistic models, and may be expressed in the language of graphical models with random variables whose values are complex data types such as strings. Cases with control flow and dynamic structure require techniques from probabilistic programming, which allow implementing disparate model structures and inference strategies in a unified language. We formalize several existing techniques from this perspective, including scratchpads / chain of thought, verifiers, STaR, selection-inference, and tool use. We refer to the resulting programs as language model cascades.