 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CAPER: Coarsen, Align, Project, Refine - A General Multilevel Framework for Network Alignment
Aug 23, 2022
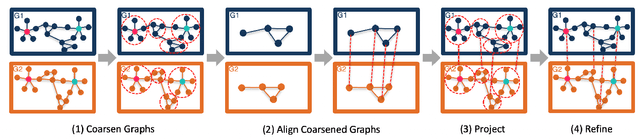

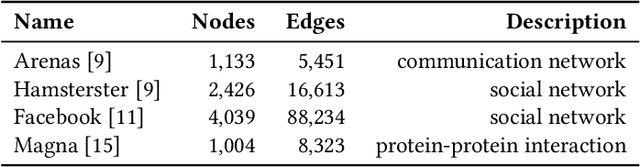
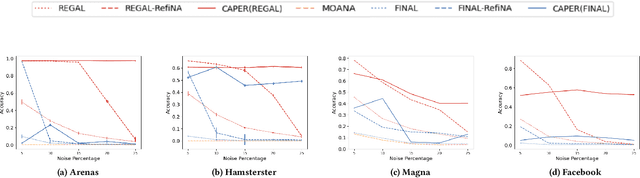
Network alignment, or the task of finding corresponding nodes in different networks, is an important problem formulation in many application domains. We propose CAPER, a multilevel alignment framework that Coarsens the input graphs, Aligns the coarsened graphs, Projects the alignment solution to finer levels and Refines the alignment solution. We show that CAPER can improve upon many different existing network alignment algorithms by enforcing alignment consistency across multiple graph resolutions: nodes matched at finer levels should also be matched at coarser levels. CAPER also accelerates the use of slower network alignment methods, at the modest cost of linear-time coarsening and refinement steps, by allowing them to be run on smaller coarsened versions of the input graphs. Experiments show that CAPER can improve upon diverse network alignment methods by an average of 33% in accuracy and/or an order of magnitude faster in runtime.
Automated machine learning for borehole resistivity measurements
Jul 20, 2022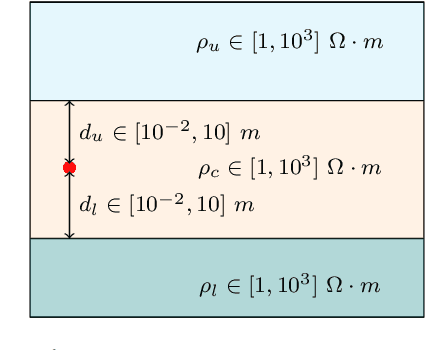
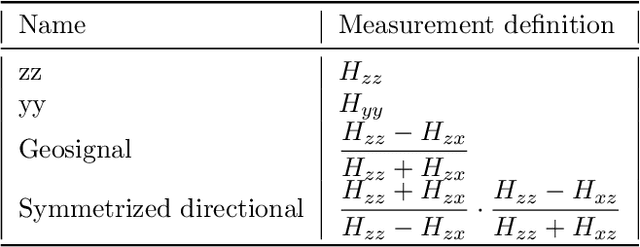
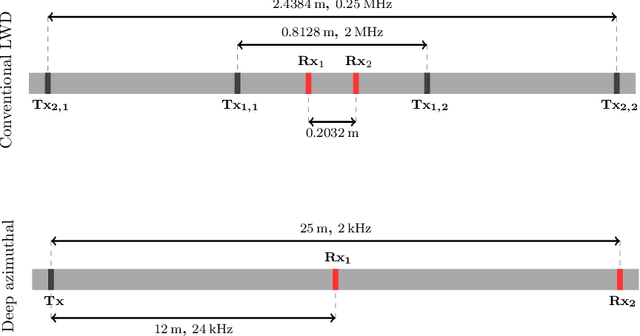

Deep neural networks (DNNs) offer a real-time solution for the inversion of borehole resistivity measurements to approximate forward and inverse operators. It is possible to use extremely large DNNs to approximate the operators, but it demands a considerable training time. Moreover, evaluating the network after training also requires a significant amount of memory and processing power. In addition, we may overfit the model. In this work, we propose a scoring function that accounts for the accuracy and size of the DNNs compared to a reference DNN that provides a good approximation for the operators. Using this scoring function, we use DNN architecture search algorithms to obtain a quasi-optimal DNN smaller than the reference network; hence, it requires less computational effort during training and evaluation. The quasi-optimal DNN delivers comparable accuracy to the original large DNN.
Fast and Precise Binary Instance Segmentation of 2D Objects for Automotive Applications
Aug 24, 2022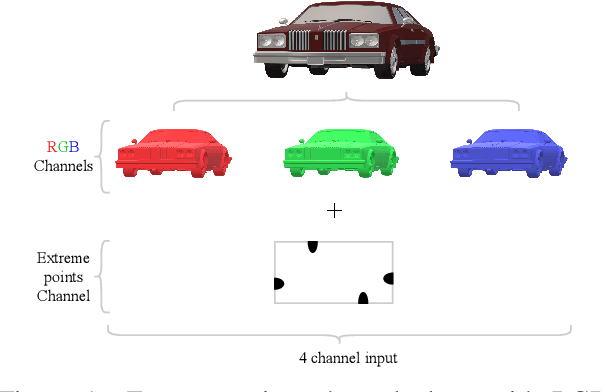
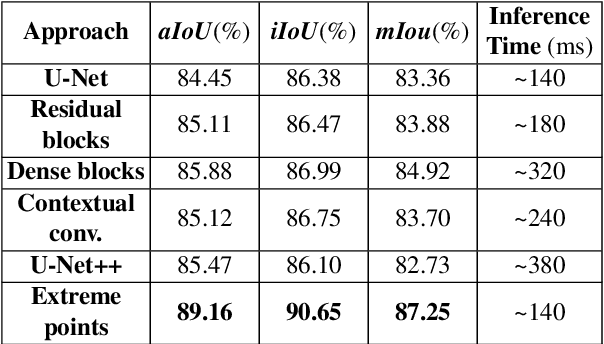
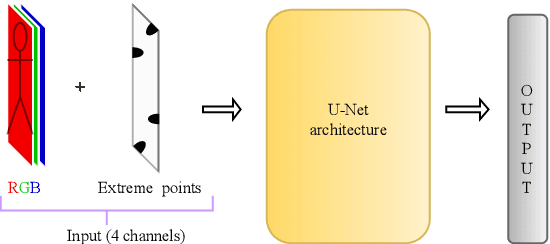
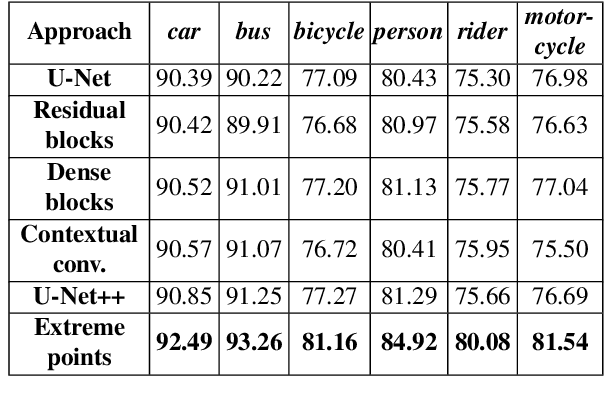
In this paper, we focus on improving binary 2D instance segmentation to assist humans in labeling ground truth datasets with polygons. Humans labeler just have to draw boxes around objects, and polygons are generated automatically. To be useful, our system has to run on CPUs in real-time. The most usual approach for binary instance segmentation involves encoder-decoder networks. This report evaluates state-of-the-art encoder-decoder networks and proposes a method for improving instance segmentation quality using these networks. Alongside network architecture improvements, our proposed method relies upon providing extra information to the network input, so-called extreme points, i.e. the outermost points on the object silhouette. The user can label them instead of a bounding box almost as quickly. The bounding box can be deduced from the extreme points as well. This method produces better IoU compared to other state-of-the-art encoder-decoder networks and also runs fast enough when it is deployed on a CPU.
* 4 pages, 4 figures, WSCG 2022 conference [WSCG 2022 Proceedings, CSRN 3201, ISSN 2464-4617]
Lesion-Specific Prediction with Discriminator-Based Supervised Guided Attention Module Enabled GANs in Multiple Sclerosis
Aug 30, 2022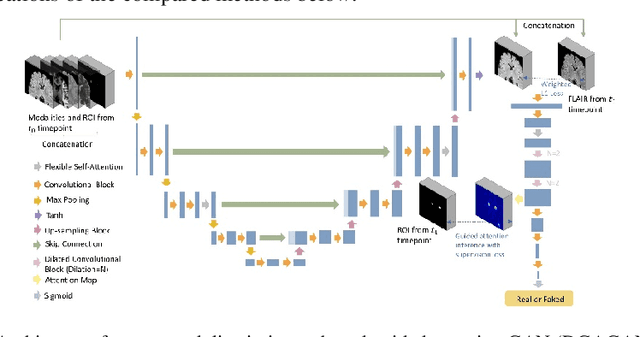
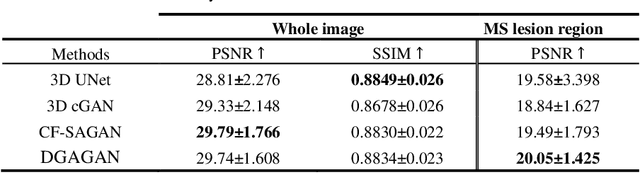
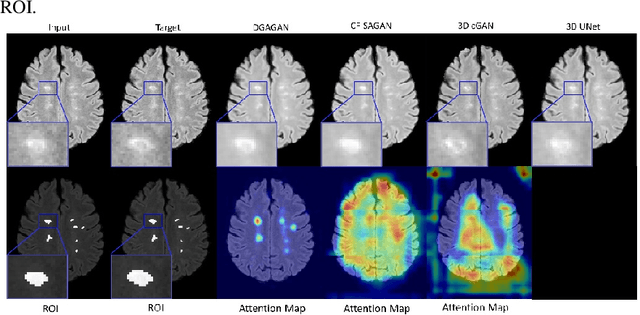
Multiple Sclerosis (MS) is a chronic neurological condition characterized by the development of lesions in the white matter of the brain. T2-fluid attenuated inversion recovery (FLAIR) brain magnetic resonance imaging (MRI) provides superior visualization and characterization of MS lesions, relative to other MRI modalities. Follow-up brain FLAIR MRI in MS provides helpful information for clinicians towards monitoring disease progression. In this study, we propose a novel modification to generative adversarial networks (GANs) to predict future lesion-specific FLAIR MRI for MS at fixed time intervals. We use supervised guided attention and dilated convolutions in the discriminator, which supports making an informed prediction of whether the generated images are real or not based on attention to the lesion area, which in turn has potential to help improve the generator to predict the lesion area of future examinations more accurately. We compared our method to several baselines and one state-of-art CF-SAGAN model [1]. In conclusion, our results indicate that the proposed method achieves higher accuracy and reduces the standard deviation of the prediction errors in the lesion area compared with other models with similar overall performance.
Differentiable Optimal Control via Differential Dynamic Programming
Sep 02, 2022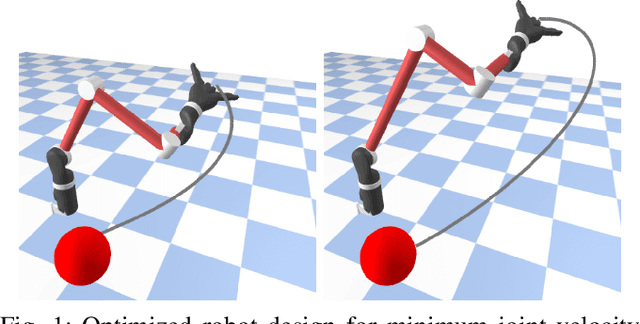
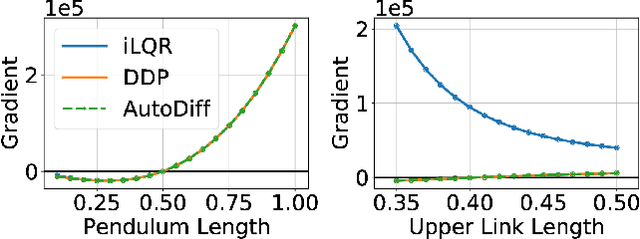
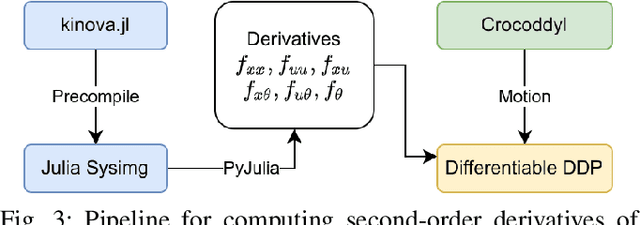
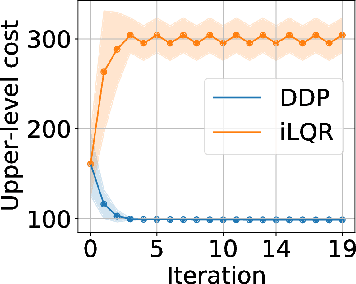
Robot design optimization, imitation learning and system identification share a common problem which requires optimization over robot or task parameters at the same time as optimizing the robot motion. To solve these problems, we can use differentiable optimal control for which the gradients of the robot's motion with respect to the parameters are required. We propose a method to efficiently compute these gradients analytically via the differential dynamic programming (DDP) algorithm using sensitivity analysis (SA). We show that we must include second-order dynamics terms when computing the gradients. However, we do not need to include them when computing the motion. We validate our approach on the pendulum and double pendulum systems. Furthermore, we compare against using the derivatives of the iterative linear quadratic regulator (iLQR), which ignores these second-order terms everywhere, on a co-design task for the Kinova arm, where we optimize the link lengths of the robot for a target reaching task. We show that optimizing using iLQR gradients diverges as ignoring the second-order dynamics affects the computation of the derivatives. Instead, optimizing using DDP gradients converges to the same optimum for a range of initial designs allowing our formulation to scale to complex systems.
Efficient Implementation of Non-linear Flow Law Using Neural Network into the Abaqus Explicit FEM code
Sep 07, 2022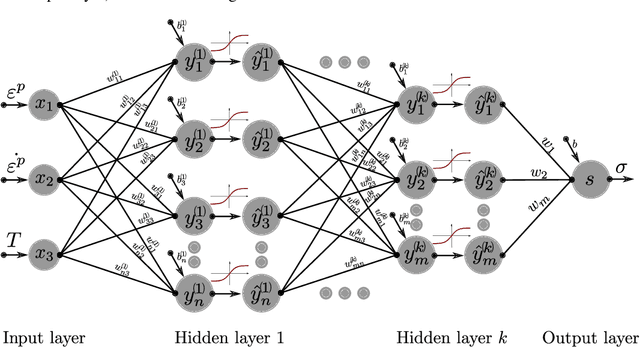

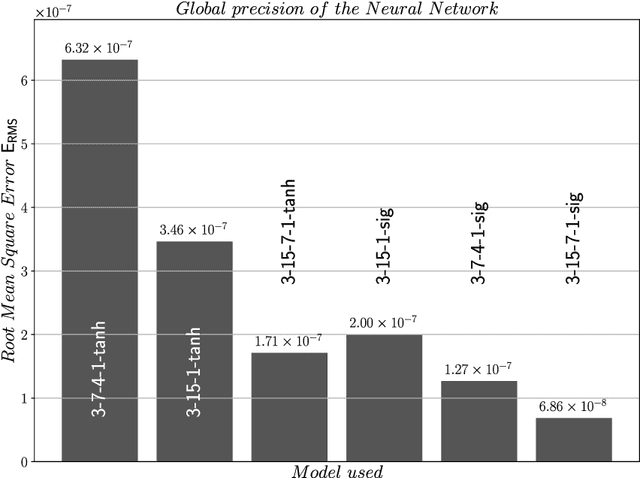
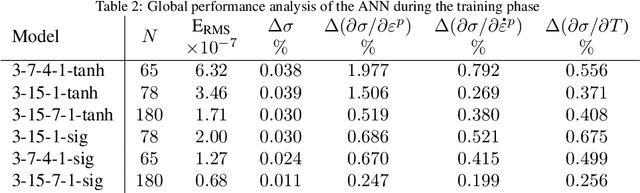
Machine learning techniques are increasingly used to predict material behavior in scientific applications and offer a significant advantage over conventional numerical methods. In this work, an Artificial Neural Network (ANN) model is used in a finite element formulation to define the flow law of a metallic material as a function of plastic strain, plastic strain rate and temperature. First, we present the general structure of the neural network, its operation and focus on the ability of the network to deduce, without prior learning, the derivatives of the flow law with respect to the model inputs. In order to validate the robustness and accuracy of the proposed model, we compare and analyze the performance of several network architectures with respect to the analytical formulation of a Johnson-Cook behavior law for a 42CrMo4 steel. In a second part, after having selected an Artificial Neural Network architecture with $2$ hidden layers, we present the implementation of this model in the Abaqus Explicit computational code in the form of a VUHARD subroutine. The predictive capability of the proposed model is then demonstrated during the numerical simulation of two test cases: the necking of a circular bar and a Taylor impact test. The results obtained show a very high capability of the ANN to replace the analytical formulation of a Johnson-Cook behavior law in a finite element code, while remaining competitive in terms of numerical simulation time compared to a classical approach.
Prioritizing Samples in Reinforcement Learning with Reducible Loss
Aug 22, 2022
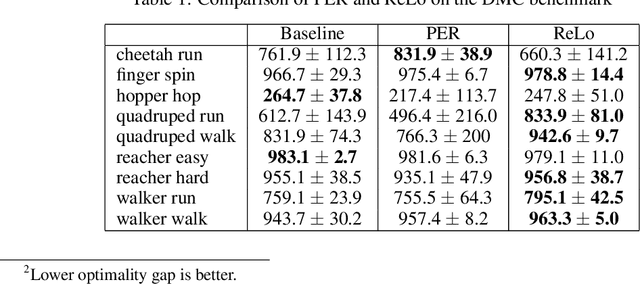


Most reinforcement learning algorithms take advantage of an experience replay buffer to repeatedly train on samples the agent has observed in the past. This prevents catastrophic forgetting, however simply assigning equal importance to each of the samples is a naive strategy. In this paper, we propose a method to prioritize samples based on how much we can learn from a sample. We define the learn-ability of a sample as the steady decrease of the training loss associated with this sample over time. We develop an algorithm to prioritize samples with high learn-ability, while assigning lower priority to those that are hard-to-learn, typically caused by noise or stochasticity. We empirically show that our method is more robust than random sampling and also better than just prioritizing with respect to the training loss, i.e. the temporal difference loss, which is used in vanilla prioritized experience replay.
MSSPN: Automatic First Arrival Picking using Multi-Stage Segmentation Picking Network
Sep 07, 2022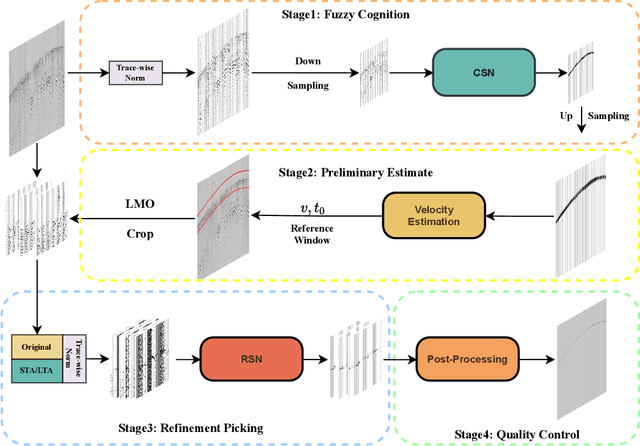

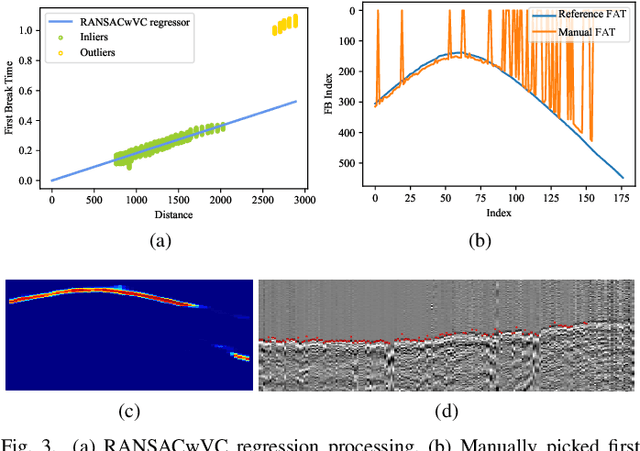
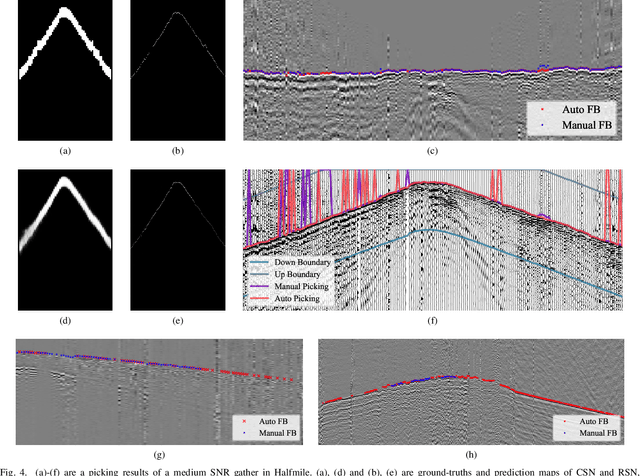
Picking the first arrival times of prestack gathers is called First Arrival Time (FAT) picking, which is an indispensable step in seismic data processing, and is mainly solved manually in the past. With the current increasing density of seismic data collection, the efficiency of manual picking has been unable to meet the actual needs. Therefore, automatic picking methods have been greatly developed in recent decades, especially those based on deep learning. However, few of the current supervised deep learning-based method can avoid the dependence on labeled samples. Besides, since the gather data is a set of signals which are greatly different from the natural images, it is difficult for the current method to solve the FAT picking problem in case of a low Signal to Noise Ratio (SNR). In this paper, for hard rock seismic gather data, we propose a Multi-Stage Segmentation Pickup Network (MSSPN), which solves the generalization problem across worksites and the picking problem in the case of low SNR. In MSSPN, there are four sub-models to simulate the manually picking processing, which is assumed to four stages from coarse to fine. Experiments on seven field datasets with different qualities show that our MSSPN outperforms benchmarks by a large margin.Particularly, our method can achieve more than 90\% accurate picking across worksites in the case of medium and high SNRs, and even fine-tuned model can achieve 88\% accurate picking of the dataset with low SNR.
MSMDFusion: Fusing LiDAR and Camera at Multiple Scales with Multi-Depth Seeds for 3D Object Detection
Sep 07, 2022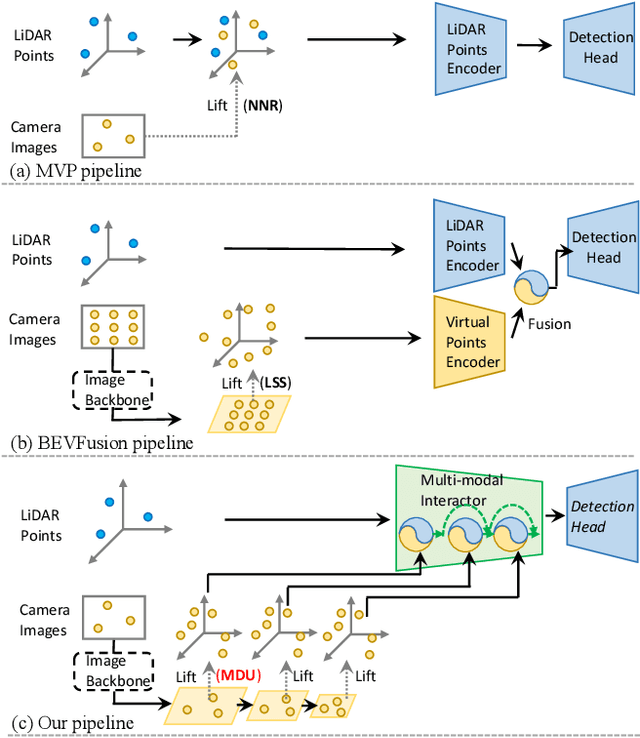
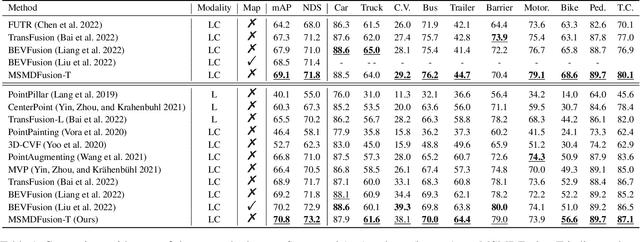
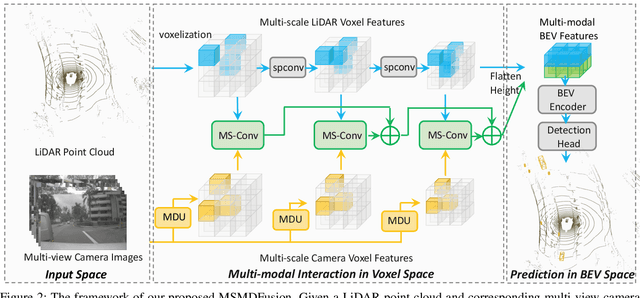
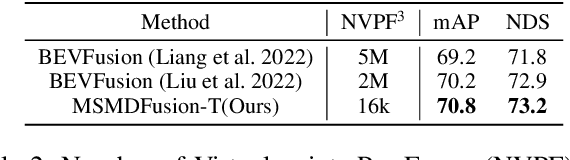
Fusing LiDAR and camera information is essential for achieving accurate and reliable 3D object detection in autonomous driving systems. However, this is challenging due to the difficulty of combining multi-granularity geometric and semantic features from two drastically different modalities. Recent approaches aim at exploring the semantic densities of camera features through lifting points in 2D camera images (referred to as seeds) into 3D space for fusion, and they can be roughly divided into 1) early fusion of raw points that aims at augmenting the 3D point cloud at the early input stage, and 2) late fusion of BEV (bird-eye view) maps that merges LiDAR and camera BEV features before the detection head. While both have their merits in enhancing the representation power of the combined features, this single-level fusion strategy is a suboptimal solution to the aforementioned challenge. Their major drawbacks are the inability to interact the multi-granularity semantic features from two distinct modalities sufficiently. To this end, we propose a novel framework that focuses on the multi-scale progressive interaction of the multi-granularity LiDAR and camera features. Our proposed method, abbreviated as MDMSFusion, achieves state-of-the-art results in 3D object detection, with 69.1 mAP and 71.8 NDS on nuScenes validation set, and 70.8 mAP and 73.2 NDS on nuScenes test set, which rank 1st and 2nd respectively among single-model non-ensemble approaches by the time of submission.
MapTR: Structured Modeling and Learning for Online Vectorized HD Map Construction
Aug 30, 2022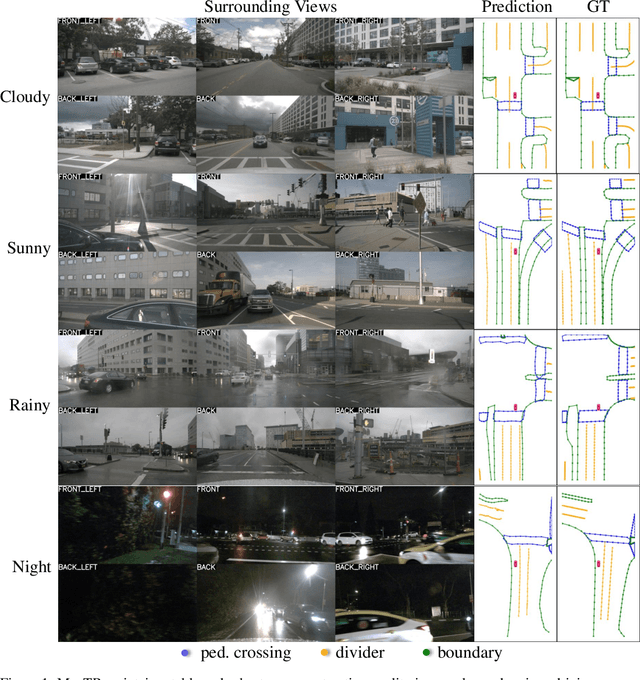
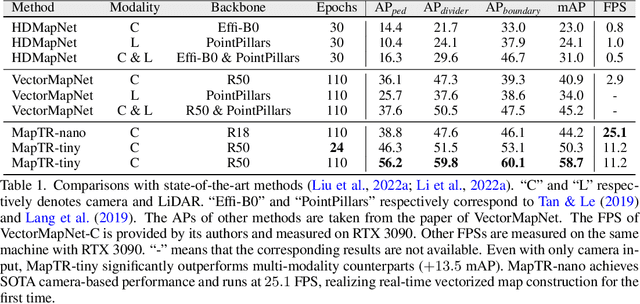
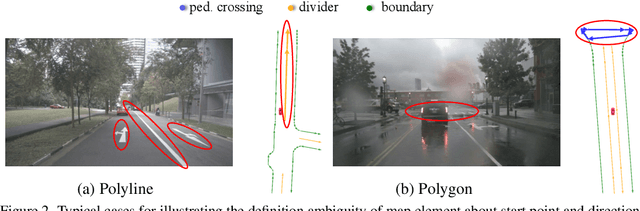

We present MapTR, a structured end-to-end framework for efficient online vectorized HD map construction. We propose a unified permutation-based modeling approach, i.e., modeling map element as a point set with a group of equivalent permutations, which avoids the definition ambiguity of map element and eases learning. We adopt a hierarchical query embedding scheme to flexibly encode structured map information and perform hierarchical bipartite matching for map element learning. MapTR achieves the best performance and efficiency among existing vectorized map construction approaches on nuScenes dataset. In particular, MapTR-nano runs at real-time inference speed ($25.1$ FPS) on RTX 3090, $8\times$ faster than the existing state-of-the-art camera-based method while achieving $3.3$ higher mAP. MapTR-tiny significantly outperforms the existing state-of-the-art multi-modality method by $13.5$ mAP while being faster. Qualitative results show that MapTR maintains stable and robust map construction quality in complex and various driving scenes. Abundant demos are available at \url{https://github.com/hustvl/MapTR} to prove the effectiveness in real-world scenarios. MapTR is of great application value in autonomous driving. Code will be released for facilitating further research and application.