 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreshRetailNet-50K: A Stockout-Annotated Censored Demand Dataset for Latent Demand Recovery and Forecasting in Fresh Retail
May 22, 2025



Accurate demand estimation is critical for the retail business in guiding the inventory and pricing policies of perishable products. However, it faces fundamental challenges from censored sales data during stockouts, where unobserved demand creates systemic policy biases. Existing datasets lack the temporal resolution and annotations needed to address this censoring effect. To fill this gap, we present FreshRetailNet-50K, the first large-scale benchmark for censored demand estimation. It comprises 50,000 store-product time series of detailed hourly sales data from 898 stores in 18 major cities, encompassing 863 perishable SKUs meticulously annotated for stockout events. The hourly stock status records unique to this dataset, combined with rich contextual covariates, including promotional discounts, precipitation, and temporal features, enable innovative research beyond existing solutions. We demonstrate one such use case of two-stage demand modeling: first, we reconstruct the latent demand during stockouts using precise hourly annotations. We then leverage the recovered demand to train robust demand forecasting models in the second stage. Experimental results show that this approach achieves a 2.73\% improvement in prediction accuracy while reducing the systematic demand underestimation from 7.37\% to near-zero bias. With unprecedented temporal granularity and comprehensive real-world information, FreshRetailNet-50K opens new research directions in demand imputation, perishable inventory optimization, and causal retail analytics. The unique annotation quality and scale of the dataset address long-standing limitations in retail AI, providing immediate solutions and a platform for future methodological innovation. The data (https://huggingface.co/datasets/Dingdong-Inc/FreshRetailNet-50K) and code (https://github.com/Dingdong-Inc/frn-50k-baseline}) are openly released.
Seismic First Break Picking in a Higher Dimension Using Deep Graph Learning
Apr 12, 2024


Contemporary automatic first break (FB) picking methods typically analyze 1D signals, 2D source gathers, or 3D source-receiver gathers. Utilizing higher-dimensional data, such as 2D or 3D, incorporates global features, improving the stability of local picking. Despite the benefits, high-dimensional data requires structured input and increases computational demands. Addressing this, we propose a novel approach using deep graph learning called DGL-FB, constructing a large graph to efficiently extract information. In this graph, each seismic trace is represented as a node, connected by edges that reflect similarities. To manage the size of the graph, we develop a subgraph sampling technique to streamline model training and inference. Our proposed framework, DGL-FB, leverages deep graph learning for FB picking. It encodes subgraphs into global features using a deep graph encoder. Subsequently, the encoded global features are combined with local node signals and fed into a ResUNet-based 1D segmentation network for FB detection. Field survey evaluations of DGL-FB show superior accuracy and stability compared to a 2D U-Net-based benchmark method.
Leveraging Uncertainty Quantification for Picking Robust First Break Times
May 23, 2023



In seismic exploration, the selection of first break times is a crucial aspect in the determination of subsurface velocity models, which in turn significantly influences the placement of wells. Many deep neural network (DNN)-based automatic first break picking methods have been proposed to speed up this picking processing. However, there has been no work on the uncertainty of the first picking results of the output of DNN. In this paper, we propose a new framework for first break picking based on a Bayesian neural network to further explain the uncertainty of the output. In a large number of experiments, we evaluate that the proposed method has better accuracy and robustness than the deterministic DNN-based model. In addition, we also verify that the uncertainty of measurement is meaningful, which can provide a reference for human decision-making.
MSSPN: Automatic First Arrival Picking using Multi-Stage Segmentation Picking Network
Sep 07, 2022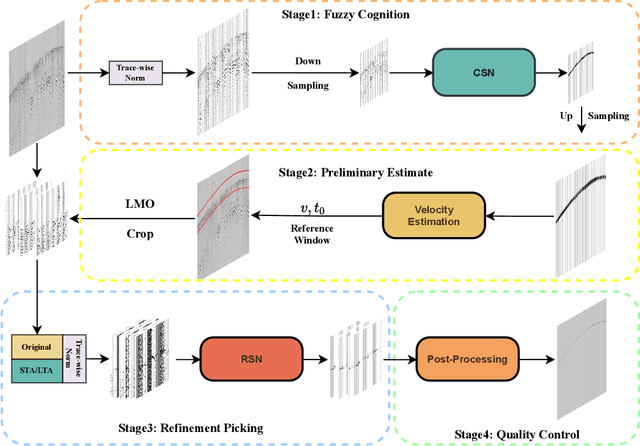

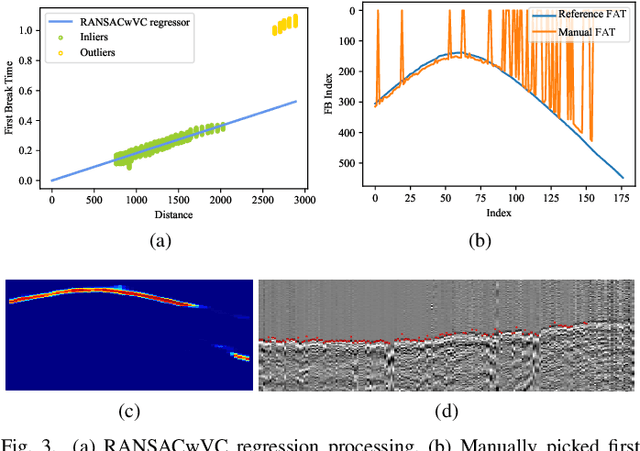
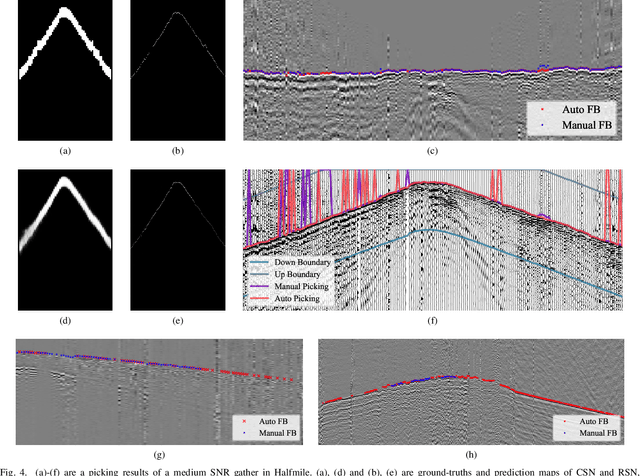
Picking the first arrival times of prestack gathers is called First Arrival Time (FAT) picking, which is an indispensable step in seismic data processing, and is mainly solved manually in the past. With the current increasing density of seismic data collection, the efficiency of manual picking has been unable to meet the actual needs. Therefore, automatic picking methods have been greatly developed in recent decades, especially those based on deep learning. However, few of the current supervised deep learning-based method can avoid the dependence on labeled samples. Besides, since the gather data is a set of signals which are greatly different from the natural images, it is difficult for the current method to solve the FAT picking problem in case of a low Signal to Noise Ratio (SNR). In this paper, for hard rock seismic gather data, we propose a Multi-Stage Segmentation Pickup Network (MSSPN), which solves the generalization problem across worksites and the picking problem in the case of low SNR. In MSSPN, there are four sub-models to simulate the manually picking processing, which is assumed to four stages from coarse to fine. Experiments on seven field datasets with different qualities show that our MSSPN outperforms benchmarks by a large margin.Particularly, our method can achieve more than 90\% accurate picking across worksites in the case of medium and high SNRs, and even fine-tuned model can achieve 88\% accurate picking of the dataset with low SNR.