 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Covariance Recovery for One-Bit Sampled Data With Time-Varying Sampling Thresholds-Part I: Stationary Signals
Mar 16, 2022
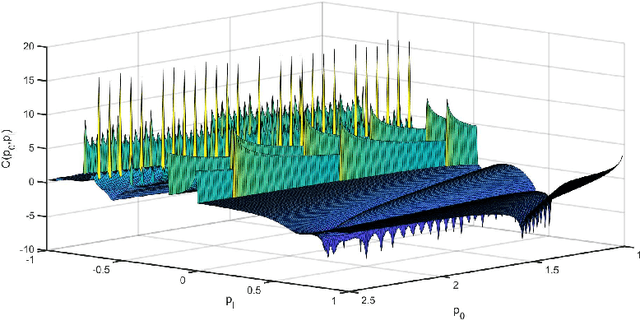
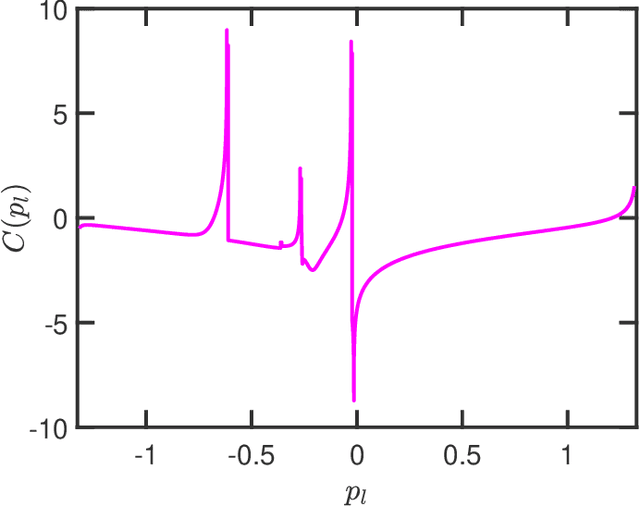
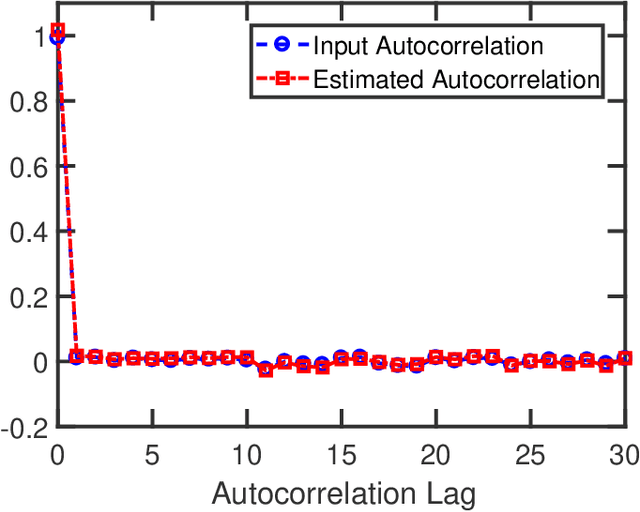
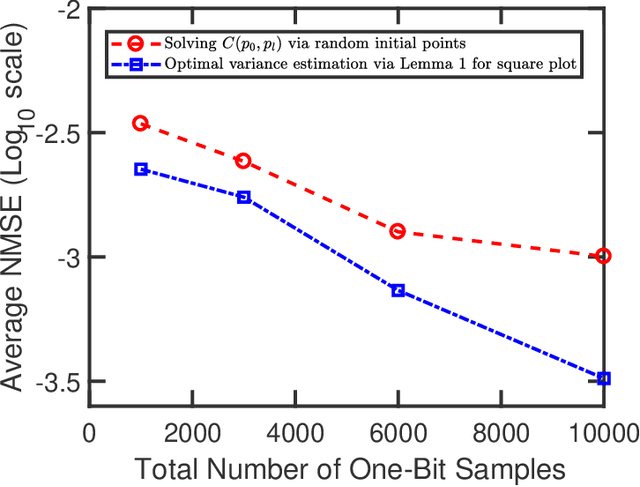
One-bit quantization, which relies on comparing the signals of interest with given threshold levels, has attracted considerable attention in signal processing for communications and sensing. A useful tool for covariance recovery in such settings is the arcsine law, that estimates the normalized covariance matrix of zero-mean stationary input signals. This relation, however, only considers a zero sampling threshold, which can cause a remarkable information loss. In this paper, the idea of the arcsine law is extended to the case where one-bit analog-to-digital converters (ADCs) apply time-varying thresholds. Specifically, three distinct approaches are proposed, investigated, and compared, to recover the autocorrelation sequence of the stationary signals of interest. Additionally, we will study a modification of the Bussgang law, a famous relation facilitating the recovery of the cross-correlation between the one-bit sampled data and the zero-mean stationary input signal. Similar to the case of the arcsine law, the Bussgang law only considers a zero sampling threshold. This relation is also extended to accommodate the more general case of time-varying thresholds for the stationary input signals.
Identifiability and Asymptotics in Learning Homogeneous Linear ODE Systems from Discrete Observations
Oct 12, 2022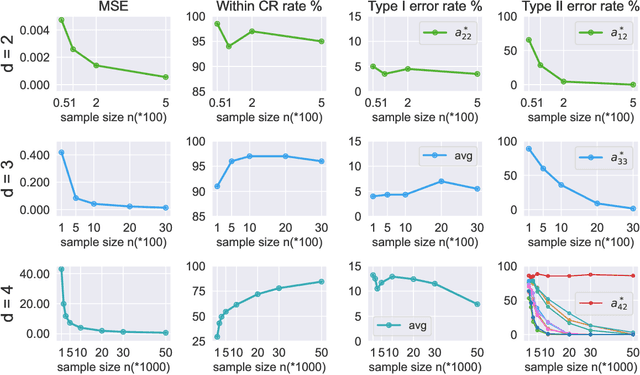
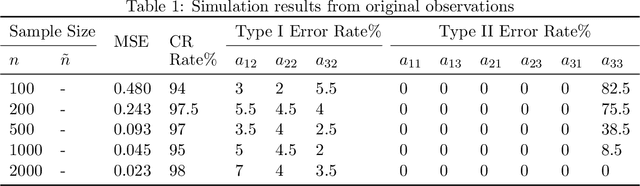
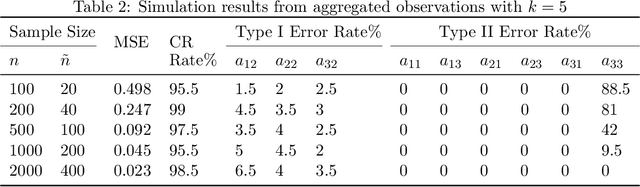
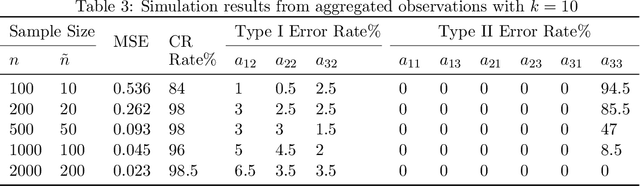
Ordinary Differential Equations (ODEs) have recently gained a lot of attention in machine learning. However, the theoretical aspects, e.g., identifiability and asymptotic properties of statistical estimation are still obscure. This paper derives a sufficient condition for the identifiability of homogeneous linear ODE systems from a sequence of equally-spaced error-free observations sampled from a single trajectory. When observations are disturbed by measurement noise, we prove that under mild conditions, the parameter estimator based on the Nonlinear Least Squares (NLS) method is consistent and asymptotic normal with $n^{-1/2}$ convergence rate. Based on the asymptotic normality property, we construct confidence sets for the unknown system parameters and propose a new method to infer the causal structure of the ODE system, i.e., inferring whether there is a causal link between system variables. Furthermore, we extend the results to degraded observations, including aggregated and time-scaled ones. To the best of our knowledge, our work is the first systematic study of the identifiability and asymptotic properties in learning linear ODE systems. We also construct simulations with various system dimensions to illustrate the established theoretical results.
Towards Theoretically Inspired Neural Initialization Optimization
Oct 12, 2022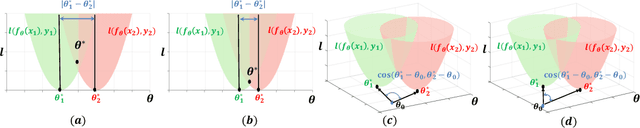
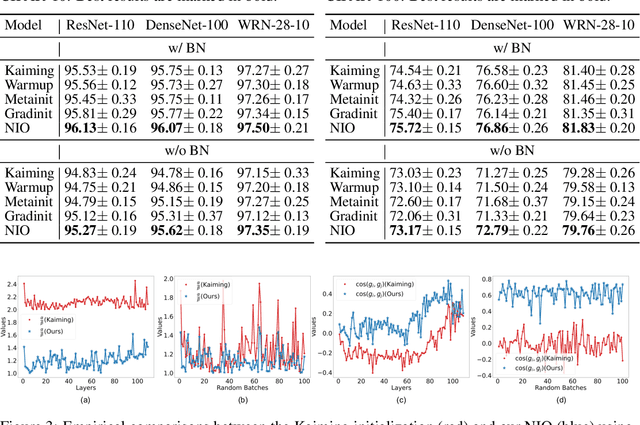


Automated machine learning has been widely explored to reduce human efforts in designing neural architectures and looking for proper hyperparameters. In the domain of neural initialization, however, similar automated techniques have rarely been studied. Most existing initialization methods are handcrafted and highly dependent on specific architectures. In this paper, we propose a differentiable quantity, named GradCosine, with theoretical insights to evaluate the initial state of a neural network. Specifically, GradCosine is the cosine similarity of sample-wise gradients with respect to the initialized parameters. By analyzing the sample-wise optimization landscape, we show that both the training and test performance of a network can be improved by maximizing GradCosine under gradient norm constraint. Based on this observation, we further propose the neural initialization optimization (NIO) algorithm. Generalized from the sample-wise analysis into the real batch setting, NIO is able to automatically look for a better initialization with negligible cost compared with the training time. With NIO, we improve the classification performance of a variety of neural architectures on CIFAR-10, CIFAR-100, and ImageNet. Moreover, we find that our method can even help to train large vision Transformer architecture without warmup.
What Makes Graph Neural Networks Miscalibrated?
Oct 12, 2022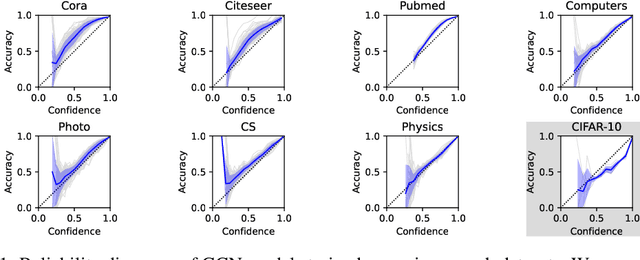
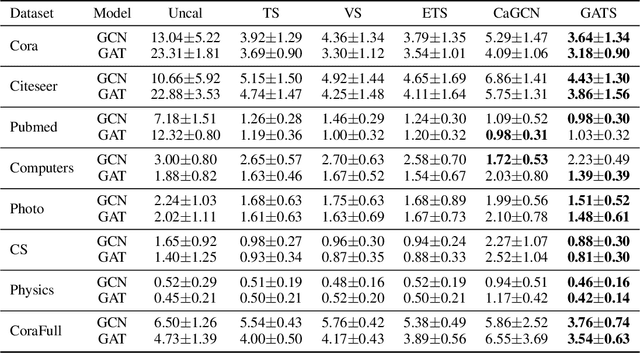
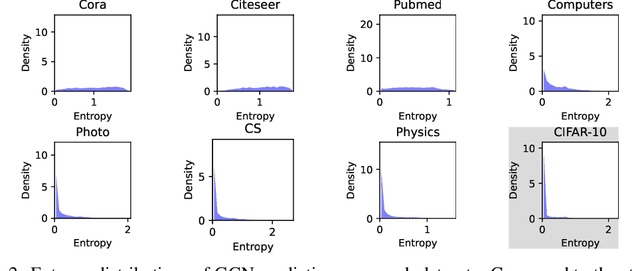
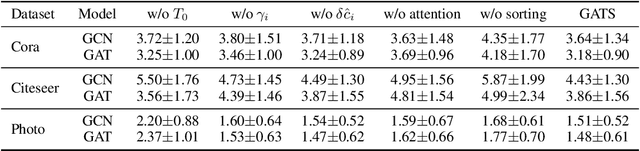
Given the importance of getting calibrated predictions and reliable uncertainty estimations, various post-hoc calibration methods have been developed for neural networks on standard multi-class classification tasks. However, these methods are not well suited for calibrating graph neural networks (GNNs), which presents unique challenges such as accounting for the graph structure and the graph-induced correlations between the nodes. In this work, we conduct a systematic study on the calibration qualities of GNN node predictions. In particular, we identify five factors which influence the calibration of GNNs: general under-confident tendency, diversity of nodewise predictive distributions, distance to training nodes, relative confidence level, and neighborhood similarity. Furthermore, based on the insights from this study, we design a novel calibration method named Graph Attention Temperature Scaling (GATS), which is tailored for calibrating graph neural networks. GATS incorporates designs that address all the identified influential factors and produces nodewise temperature scaling using an attention-based architecture. GATS is accuracy-preserving, data-efficient, and expressive at the same time. Our experiments empirically verify the effectiveness of GATS, demonstrating that it can consistently achieve state-of-the-art calibration results on various graph datasets for different GNN backbones.
Predicting housing prices and analyzing real estate market in the Chicago suburbs using Machine Learning
Oct 12, 2022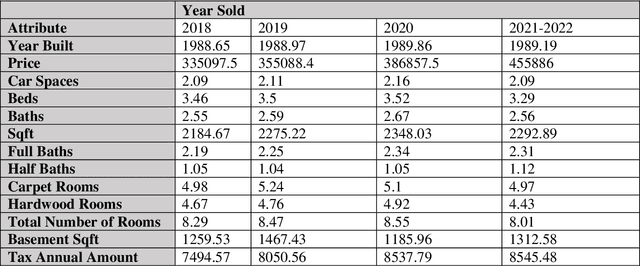
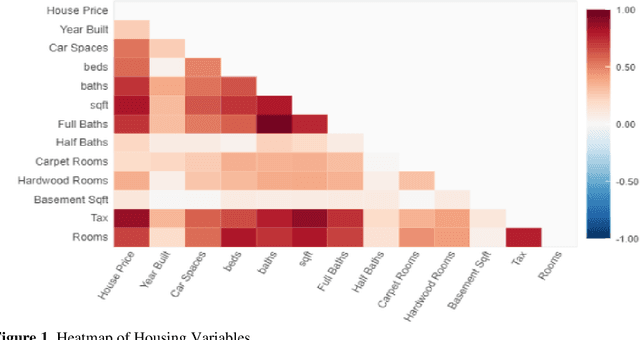
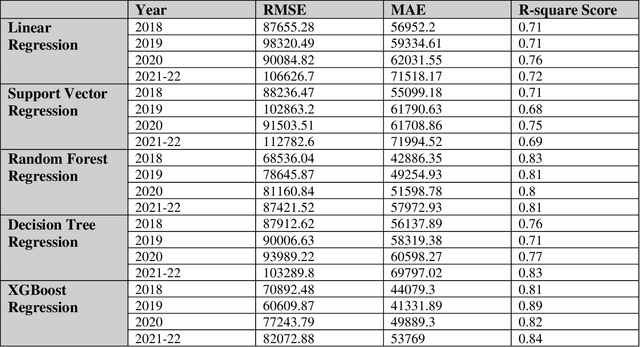
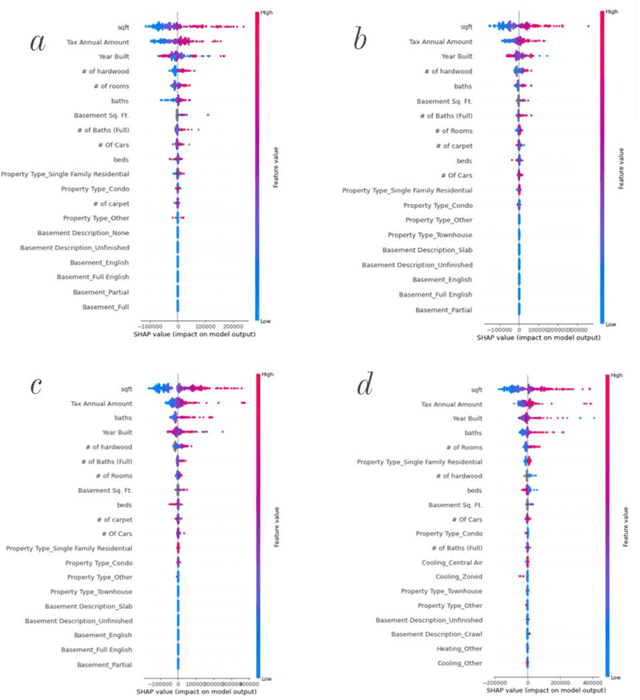
The pricing of housing properties is determined by a variety of factors. However, post-pandemic markets have experienced volatility in the Chicago suburb area, which have affected house prices greatly. In this study, analysis was done on the Naperville/Bolingbrook real estate market to predict property prices based on these housing attributes through machine learning models, and to evaluate the effectiveness of such models in a volatile market space. Gathering data from Redfin, a real estate website, sales data from 2018 up until the summer season of 2022 were collected for research. By analyzing these sales in this range of time, we can also look at the state of the housing market and identify trends in price. For modeling the data, the models used were linear regression, support vector regression, decision tree regression, random forest regression, and XGBoost regression. To analyze results, comparison was made on the MAE, RMSE, and R-squared values for each model. It was found that the XGBoost model performs the best in predicting house prices despite the additional volatility sponsored by post-pandemic conditions. After modeling, Shapley Values (SHAP) were used to evaluate the weights of the variables in constructing models.
A Hybrid Active-Passive Approach to Imbalanced Nonstationary Data Stream Classification
Oct 12, 2022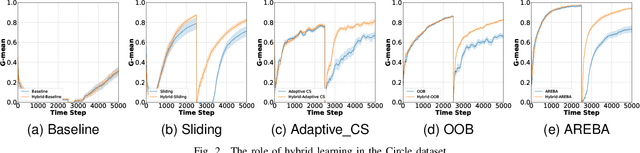
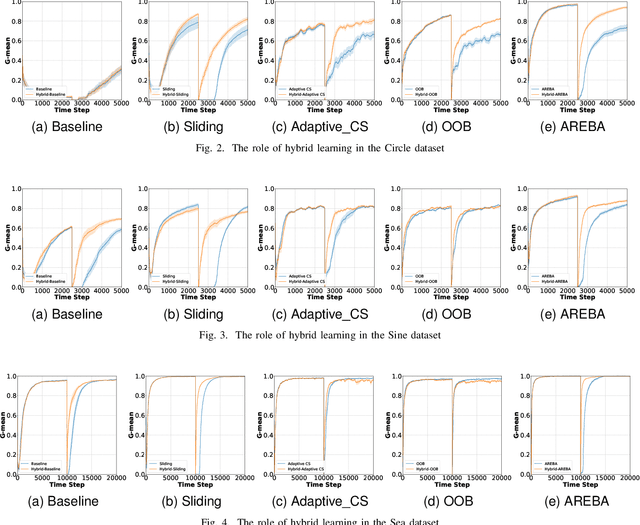
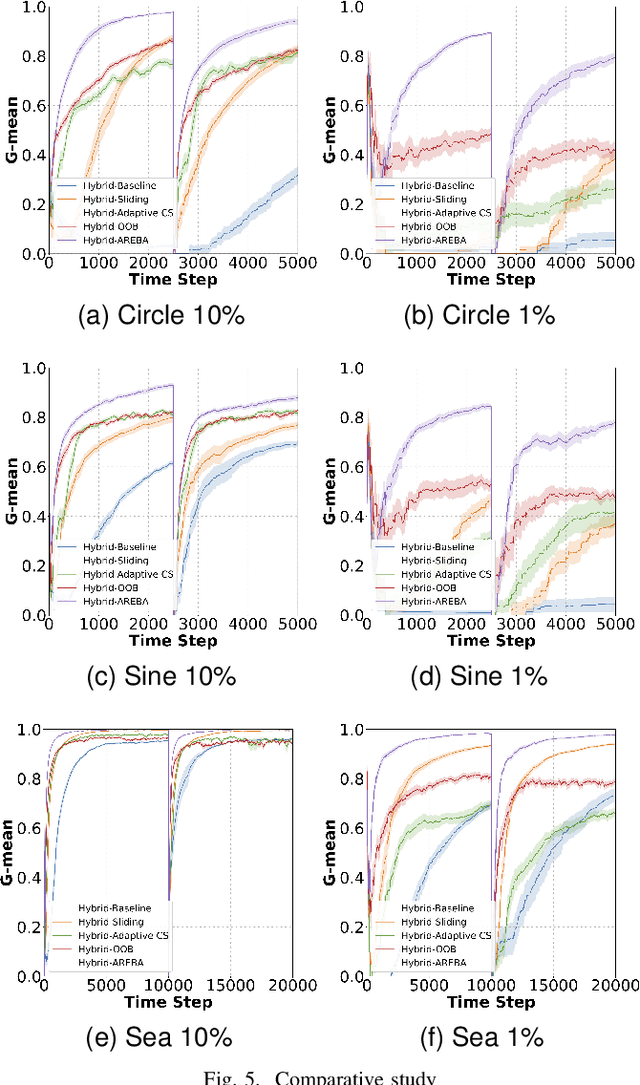

In real-world applications, the process generating the data might suffer from nonstationary effects (e.g., due to seasonality, faults affecting sensors or actuators, and changes in the users' behaviour). These changes, often called concept drift, might induce severe (potentially catastrophic) impacts on trained learning models that become obsolete over time, and inadequate to solve the task at hand. Learning in presence of concept drift aims at designing machine and deep learning models that are able to track and adapt to concept drift. Typically, techniques to handle concept drift are either active or passive, and traditionally, these have been considered to be mutually exclusive. Active techniques use an explicit drift detection mechanism, and re-train the learning algorithm when concept drift is detected. Passive techniques use an implicit method to deal with drift, and continually update the model using incremental learning. Differently from what present in the literature, we propose a hybrid alternative which merges the two approaches, hence, leveraging on their advantages. The proposed method called Hybrid-Adaptive REBAlancing (HAREBA) significantly outperforms strong baselines and state-of-the-art methods in terms of learning quality and speed; we experiment how it is effective under severe class imbalance levels too.
* Keywords: incremental learning, concept drift, class imbalance, data streams, nonstationary environments
Double Bubble, Toil and Trouble: Enhancing Certified Robustness through Transitivity
Oct 12, 2022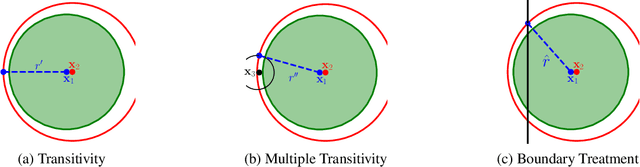
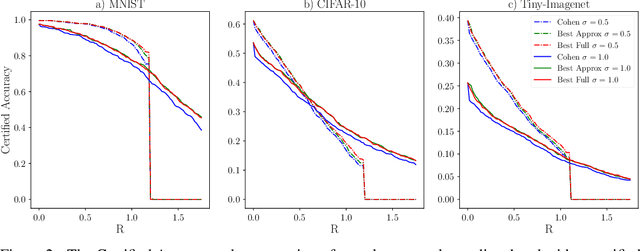
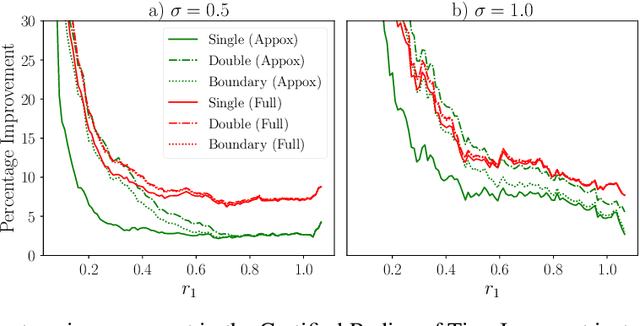
In response to subtle adversarial examples flipping classifications of neural network models, recent research has promoted certified robustness as a solution. There, invariance of predictions to all norm-bounded attacks is achieved through randomised smoothing of network inputs. Today's state-of-the-art certifications make optimal use of the class output scores at the input instance under test: no better radius of certification (under the $L_2$ norm) is possible given only these score. However, it is an open question as to whether such lower bounds can be improved using local information around the instance under test. In this work, we demonstrate how today's "optimal" certificates can be improved by exploiting both the transitivity of certifications, and the geometry of the input space, giving rise to what we term Geometrically-Informed Certified Robustness. By considering the smallest distance to points on the boundary of a set of certifications this approach improves certifications for more than $80\%$ of Tiny-Imagenet instances, yielding an on average $5 \%$ increase in the associated certification. When incorporating training time processes that enhance the certified radius, our technique shows even more promising results, with a uniform $4$ percentage point increase in the achieved certified radius.
Explainable Image Quality Assessments in Teledermatological Photography
Sep 10, 2022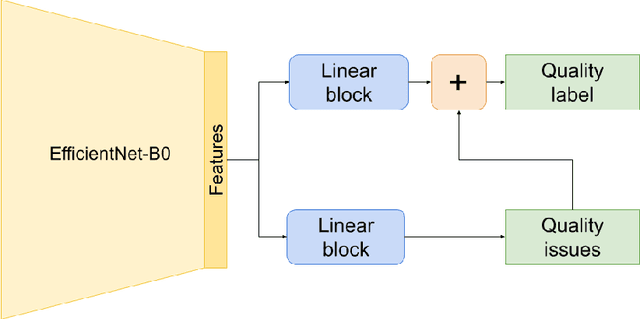
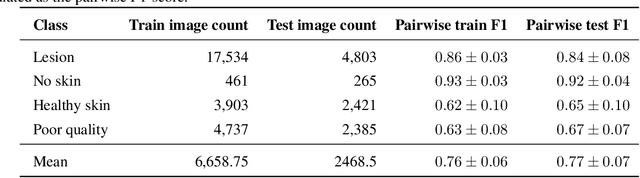
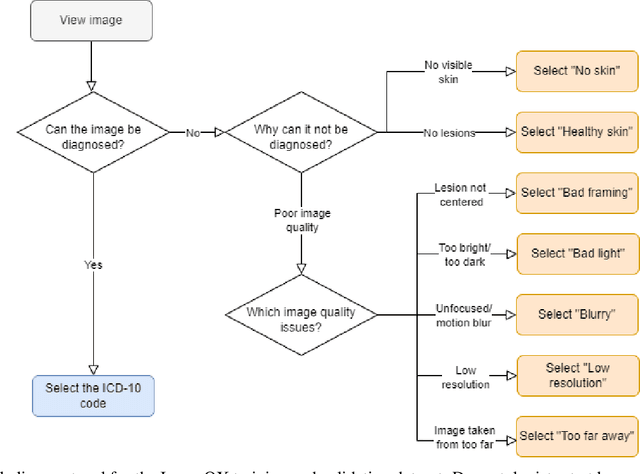
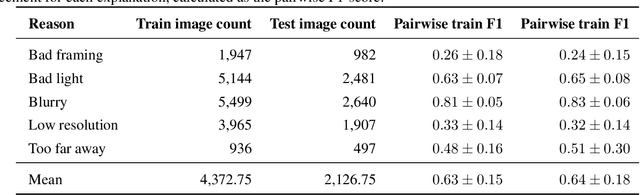
Image quality is a crucial factor in the success of teledermatological consultations. However, up to 50% of images sent by patients have quality issues, thus increasing the time to diagnosis and treatment. An automated, easily deployable, explainable method for assessing image quality is necessary to improve the current teledermatological consultation flow. We introduce ImageQX, a convolutional neural network trained for image quality assessment with a learning mechanism for identifying the most common poor image quality explanations: bad framing, bad lighting, blur, low resolution, and distance issues. ImageQX was trained on 26635 photographs and validated on 9874 photographs, each annotated with image quality labels and poor image quality explanations by up to 12 board-certified dermatologists. The photographic images were taken between 2017-2019 using a mobile skin disease tracking application accessible worldwide. Our method achieves expert-level performance for both image quality assessment and poor image quality explanation. For image quality assessment, ImageQX obtains a macro F1-score of 0.73 which places it within standard deviation of the pairwise inter-rater F1-score of 0.77. For poor image quality explanations, our method obtains F1-scores of between 0.37 and 0.70, similar to the inter-rater pairwise F1-score of between 0.24 and 0.83. Moreover, with a size of only 15 MB, ImageQX is easily deployable on mobile devices. With an image quality detection performance similar to that of dermatologists, incorporating ImageQX into the teledermatology flow can reduce the image evaluation burden on dermatologists, while at the same time reducing the time to diagnosis and treatment for patients. We introduce ImageQX, a first of its kind explainable image quality assessor which leverages domain expertise to improve the quality and efficiency of dermatological care in a virtual setting.
A Real-Time Region Tracking Algorithm Tailored to Endoscopic Video with Open-Source Implementation
Mar 16, 2022
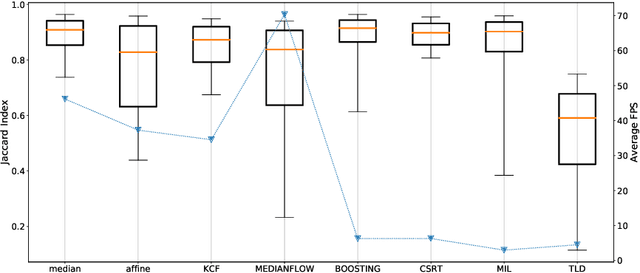
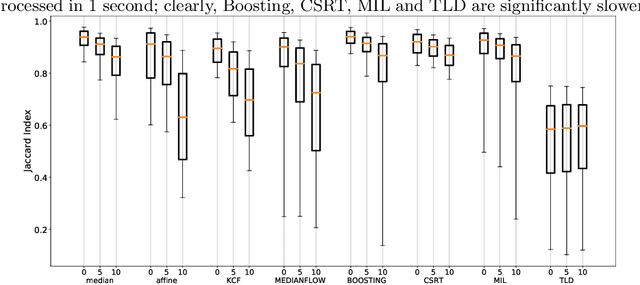
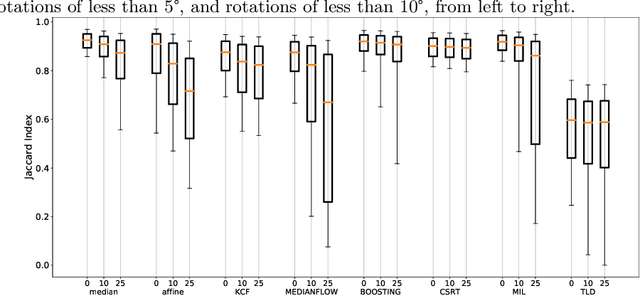
With a video data source, such as multispectral video acquired during administration of fluorescent tracers, extraction of time-resolved data typically requires the compensation of motion. While this can be done manually, which is arduous, or using off-the-shelf object tracking software, which often yields unsatisfactory performance, we present an algorithm which is simple and performant. Most importantly, we provide an open-source implementation, with an easy-to-use interface for researchers not inclined to write their own code, as well as Python modules that can be used programmatically.
Students taught by multimodal teachers are superior action recognizers
Oct 09, 2022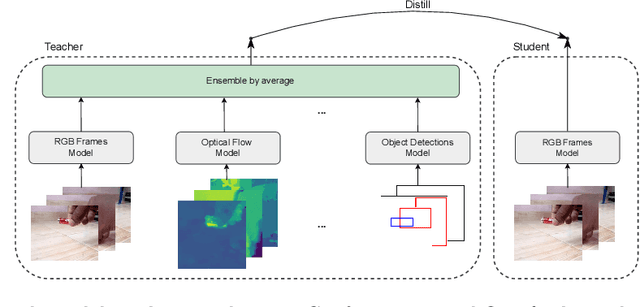

The focal point of egocentric video understanding is modelling hand-object interactions. Standard models -- CNNs, Vision Transformers, etc. -- which receive RGB frames as input perform well, however, their performance improves further by employing additional modalities such as object detections, optical flow, audio, etc. as input. The added complexity of the required modality-specific modules, on the other hand, makes these models impractical for deployment. The goal of this work is to retain the performance of such multimodal approaches, while using only the RGB images as input at inference time. Our approach is based on multimodal knowledge distillation, featuring a multimodal teacher (in the current experiments trained only using object detections, optical flow and RGB frames) and a unimodal student (using only RGB frames as input). We present preliminary results which demonstrate that the resulting model -- distilled from a multimodal teacher -- significantly outperforms the baseline RGB model (trained without knowledge distillation), as well as an omnivorous version of itself (trained on all modalities jointly), in both standard and compositional action recognition.