 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Non-Coherent Over-the-Air Decentralized Stochastic Gradient Descent
Nov 19, 2022
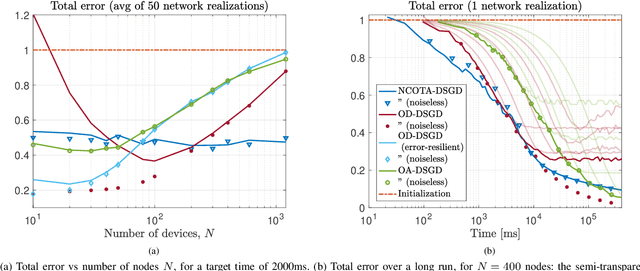
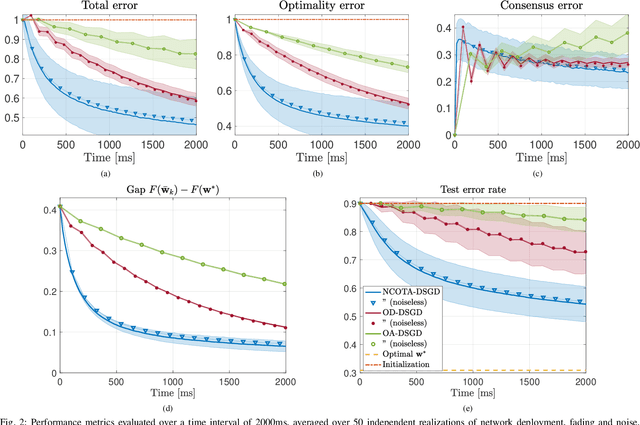
This paper proposes a Decentralized Stochastic Gradient Descent (DSGD) algorithm to solve distributed machine-learning tasks over wirelessly-connected systems, without the coordination of a base station. It combines local stochastic gradient descent steps with a Non-Coherent Over-The-Air (NCOTA) consensus scheme at the receivers, that enables concurrent transmissions by leveraging the waveform superposition properties of the wireless channels. With NCOTA, local optimization signals are mapped to a mixture of orthogonal preamble sequences and transmitted concurrently over the wireless channel under half-duplex constraints. Consensus is estimated by non-coherently combining the received signals with the preamble sequences and mitigating the impact of noise and fading via a consensus stepsize. NCOTA-DSGD operates without channel state information (typically used in over-the-air computation schemes for channel inversion) and leverages the channel pathloss to mix signals, without explicit knowledge of the mixing weights (typically known in consensus-based optimization). It is shown that, with a suitable tuning of decreasing consensus and learning stepsizes, the error (measured as Euclidean distance) between the local and globally optimum models vanishes with rate $\mathcal O(k^{-1/4})$ after $k$ iterations. NCOTA-DSGD is evaluated numerically by solving an image classification task on the MNIST dataset, cast as a regularized cross-entropy loss minimization. Numerical results depict faster convergence vis-\`a-vis running time than implementations of the classical DSGD algorithm over digital and analog orthogonal channels, when the number of learning devices is large, under stringent delay constraints.
Sketching sparse low-rank matrices with near-optimal sample- and time-complexity
May 12, 2022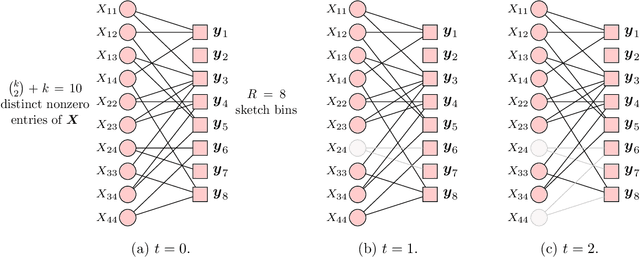
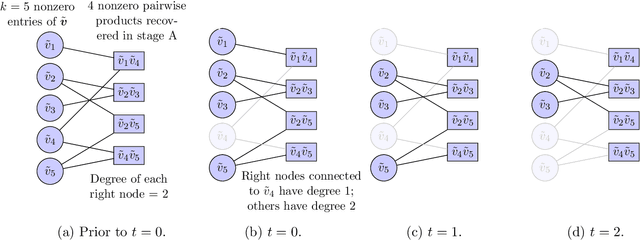
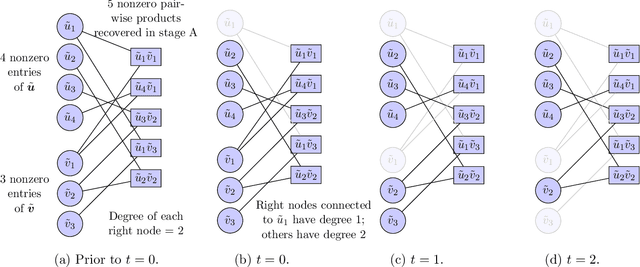
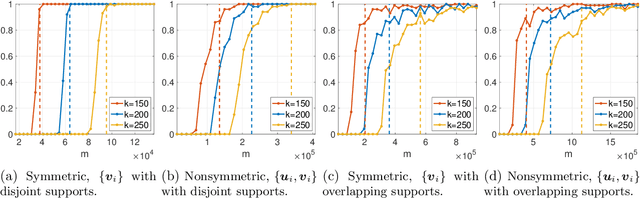
We consider the problem of recovering an $n_1 \times n_2$ low-rank matrix with $k$-sparse singular vectors from a small number of linear measurements (sketch). We propose a sketching scheme and an algorithm that can recover the singular vectors with high probability, with a sample complexity and running time that both depend only on $k$ and not on the ambient dimensions $n_1$ and $n_2$. Our sketching operator, based on a scheme for compressed sensing by Li et al. and Bakshi et al., uses a combination of a sparse parity check matrix and a partial DFT matrix. Our main contribution is the design and analysis of a two-stage iterative algorithm which recovers the singular vectors by exploiting the simultaneously sparse and low-rank structure of the matrix. We derive a nonasymptotic bound on the probability of exact recovery. We also show how the scheme can be adapted to tackle matrices that are approximately sparse and low-rank. The theoretical results are validated by numerical simulations.
Recent Developments in Structure-Based Virtual Screening Approaches
Nov 06, 2022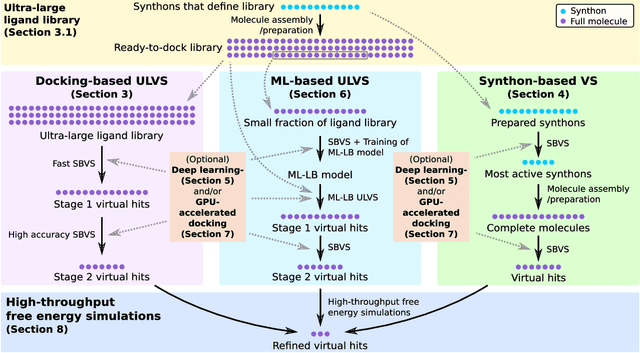
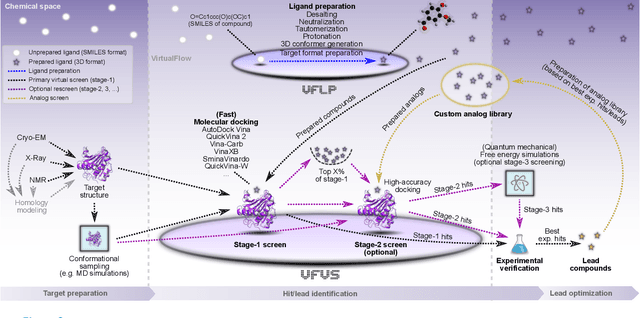
Drug development is a wide scientific field that faces many challenges these days. Among them are extremely high development costs, long development times, as well as a low number of new drugs that are approved each year. To solve these problems, new and innovate technologies are needed that make the drug discovery process of small-molecules more time and cost-efficient, and which allow to target previously undruggable target classes such as protein-protein interactions. Structure-based virtual screenings have become a leading contender in this context. In this review, we give an introduction to the foundations of structure-based virtual screenings, and survey their progress in the past few years. We outline key principles, recent success stories, new methods, available software, and promising future research directions. Virtual screenings have an enormous potential for the development of new small-molecule drugs, and are already starting to transform early-stage drug discovery.
Going In Style: Audio Backdoors Through Stylistic Transformations
Nov 06, 2022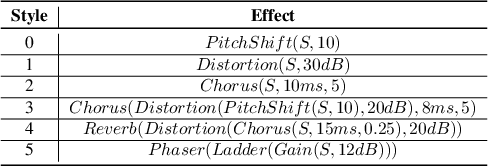
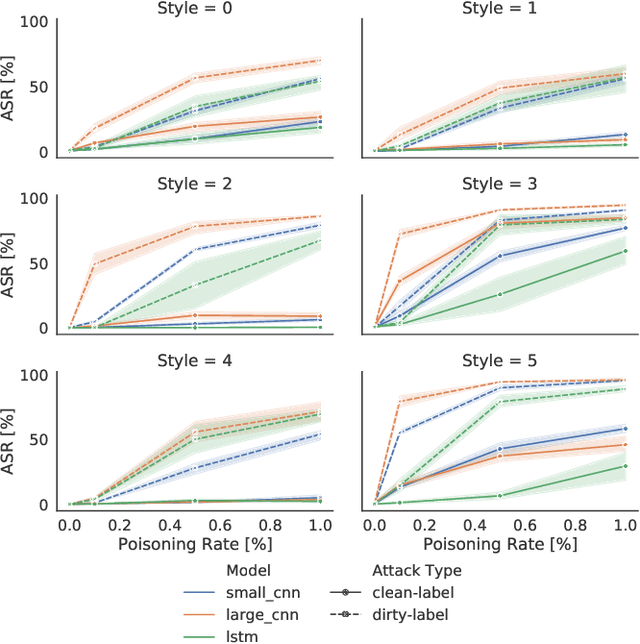
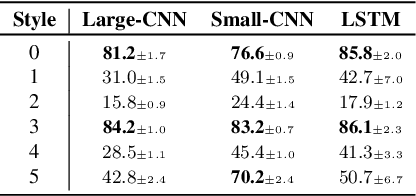
A backdoor attack places triggers in victims' deep learning models to enable a targeted misclassification at testing time. In general, triggers are fixed artifacts attached to samples, making backdoor attacks easy to spot. Only recently, a new trigger generation harder to detect has been proposed: the stylistic triggers that apply stylistic transformations to the input samples (e.g., a specific writing style). Currently, stylistic backdoor literature lacks a proper formalization of the attack, which is established in this paper. Moreover, most studies of stylistic triggers focus on text and images, while there is no understanding of whether they can work in sound. This work fills this gap. We propose JingleBack, the first stylistic backdoor attack based on audio transformations such as chorus and gain. Using 444 models in a speech classification task, we confirm the feasibility of stylistic triggers in audio, achieving 96% attack success.
TEP-GNN: Accurate Execution Time Prediction of Functional Tests using Graph Neural Networks
Aug 25, 2022
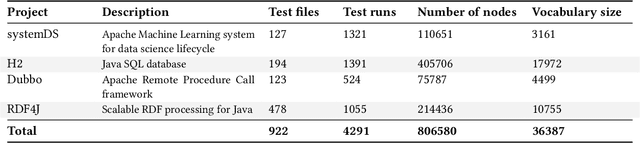
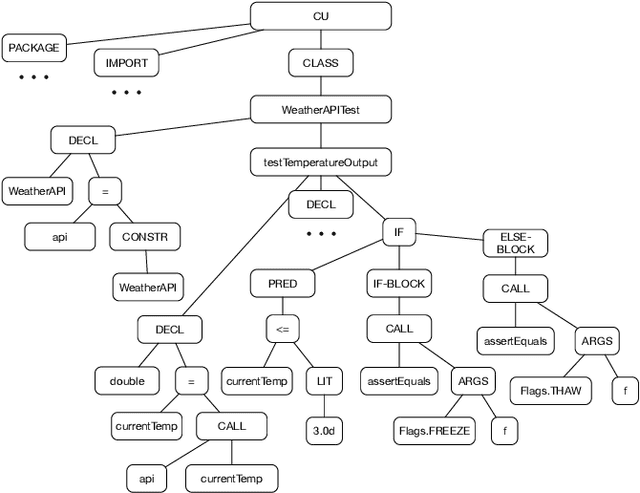
Predicting the performance of production code prior to actually executing or benchmarking it is known to be highly challenging. In this paper, we propose a predictive model, dubbed TEP-GNN, which demonstrates that high-accuracy performance prediction is possible for the special case of predicting unit test execution times. TEP-GNN uses FA-ASTs, or flow-augmented ASTs, as a graph-based code representation approach, and predicts test execution times using a powerful graph neural network (GNN) deep learning model. We evaluate TEP-GNN using four real-life Java open source programs, based on 922 test files mined from the projects' public repositories. We find that our approach achieves a high Pearson correlation of 0.789, considerable outperforming a baseline deep learning model. However, we also find that more work is needed for trained models to generalize to unseen projects. Our work demonstrates that FA-ASTs and GNNs are a feasible approach for predicting absolute performance values, and serves as an important intermediary step towards being able to predict the performance of arbitrary code prior to execution.
Cross-Modal Adapter for Text-Video Retrieval
Nov 17, 2022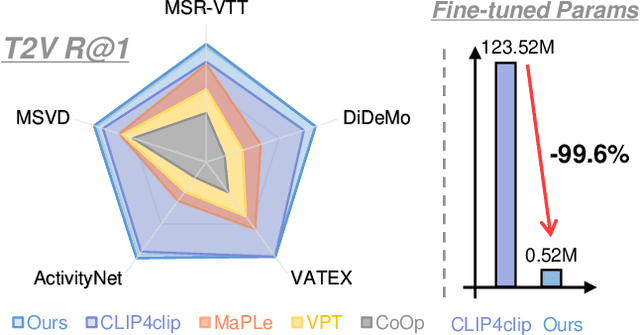
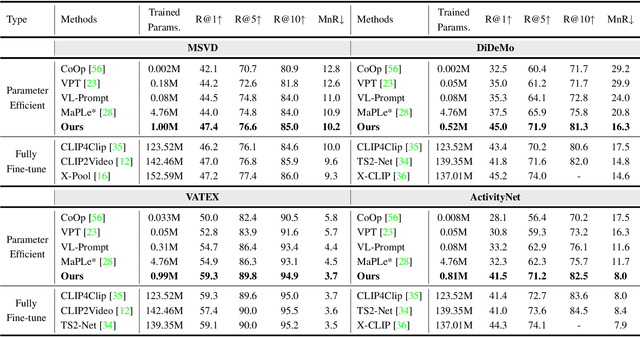
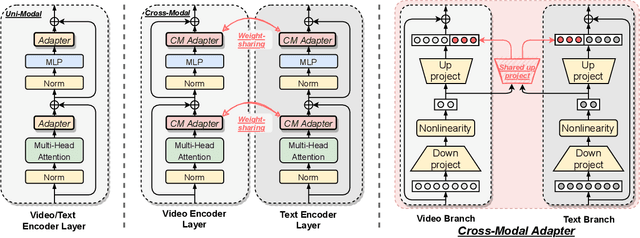
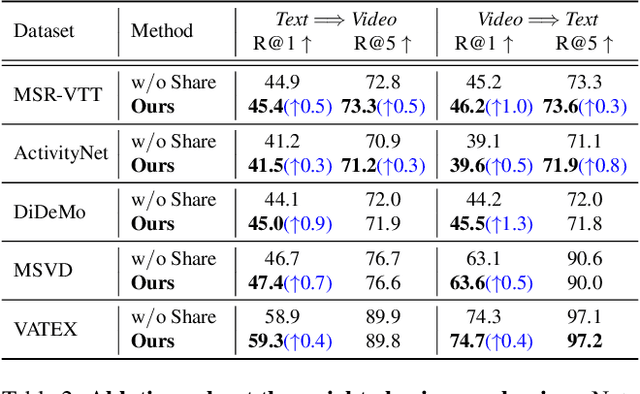
Text-video retrieval is an important multi-modal learning task, where the goal is to retrieve the most relevant video for a given text query. Recently, pre-trained models, e.g., CLIP, show great potential on this task. However, as pre-trained models are scaling up, fully fine-tuning them on text-video retrieval datasets has a high risk of overfitting. Moreover, in practice, it would be costly to train and store a large model for each task. To overcome the above issues, we present a novel $\textbf{Cross-Modal Adapter}$ for parameter-efficient fine-tuning. Inspired by adapter-based methods, we adjust the pre-trained model with a few parameterization layers. However, there are two notable differences. First, our method is designed for the multi-modal domain. Secondly, it allows early cross-modal interactions between CLIP's two encoders. Although surprisingly simple, our approach has three notable benefits: (1) reduces $\textbf{99.6}\%$ of fine-tuned parameters, and alleviates the problem of overfitting, (2) saves approximately 30% of training time, and (3) allows all the pre-trained parameters to be fixed, enabling the pre-trained model to be shared across datasets. Extensive experiments demonstrate that, without bells and whistles, it achieves superior or comparable performance compared to fully fine-tuned methods on MSR-VTT, MSVD, VATEX, ActivityNet, and DiDeMo datasets. The code will be available at \url{https://github.com/LeapLabTHU/Cross-Modal-Adapter}.
Unsupervised Model-based speaker adaptation of end-to-end lattice-free MMI model for speech recognition
Nov 17, 2022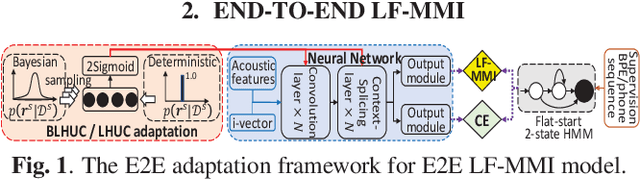
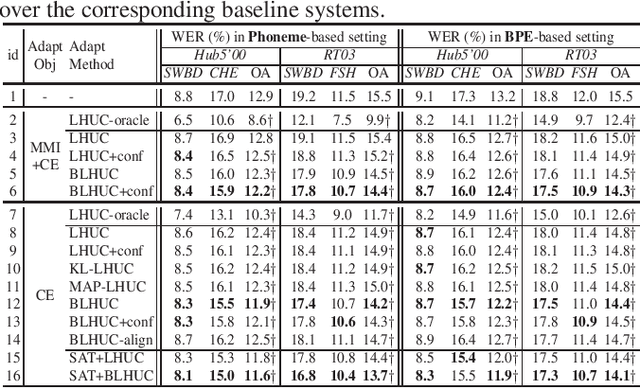
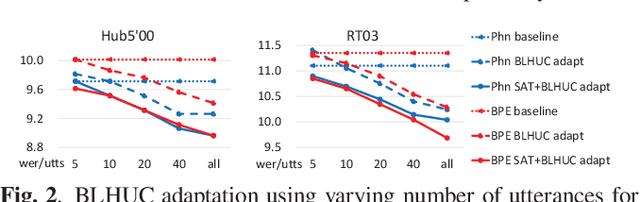
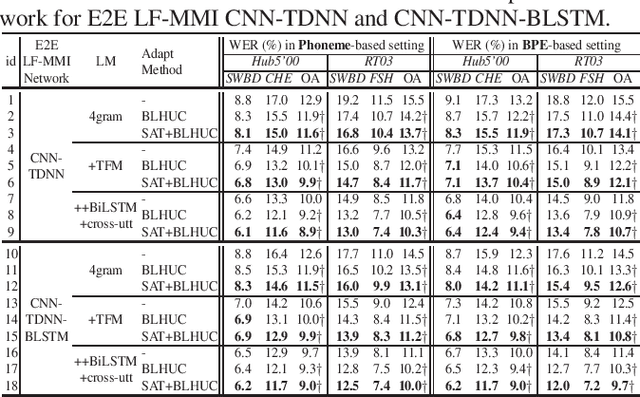
Modeling the speaker variability is a key challenge for automatic speech recognition (ASR) systems. In this paper, the learning hidden unit contributions (LHUC) based adaptation techniques with compact speaker dependent (SD) parameters are used to facilitate both speaker adaptive training (SAT) and unsupervised test-time speaker adaptation for end-to-end (E2E) lattice-free MMI (LF-MMI) models. An unsupervised model-based adaptation framework is proposed to estimate the SD parameters in E2E paradigm using LF-MMI and cross entropy (CE) criterions. Various regularization methods of the standard LHUC adaptation, e.g., the Bayesian LHUC (BLHUC) adaptation, are systematically investigated to mitigate the risk of overfitting, on E2E LF-MMI CNN-TDNN and CNN-TDNN-BLSTM models. Lattice-based confidence score estimation is used for adaptation data selection to reduce the supervision label uncertainty. Experiments on the 300-hour Switchboard task suggest that applying BLHUC in the proposed unsupervised E2E adaptation framework to byte pair encoding (BPE) based E2E LF-MMI systems consistently outperformed the baseline systems by relative word error rate (WER) reductions up to 10.5% and 14.7% on the NIST Hub5'00 and RT03 evaluation sets, and achieved the best performance in WERs of 9.0% and 9.7%, respectively. These results are comparable to the results of state-of-the-art adapted LF-MMI hybrid systems and adapted Conformer-based E2E systems.
EfficientTrain: Exploring Generalized Curriculum Learning for Training Visual Backbones
Nov 17, 2022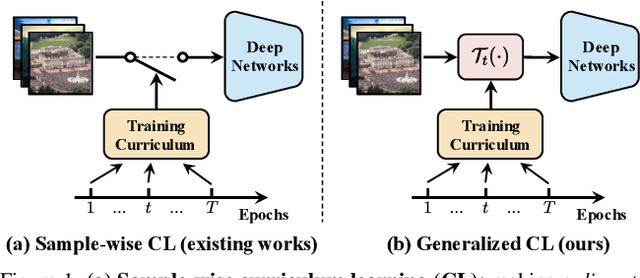
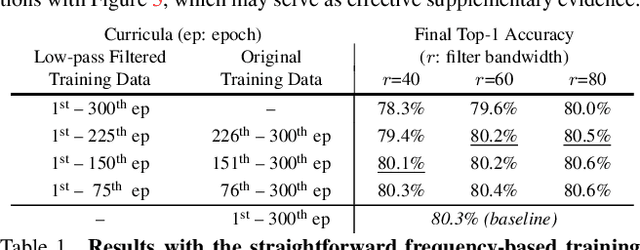
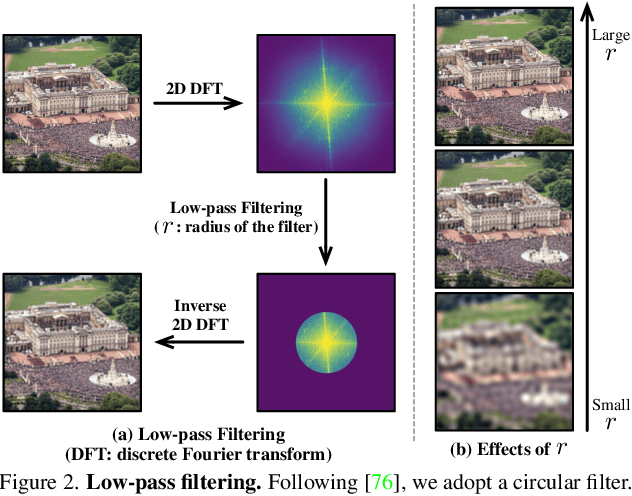
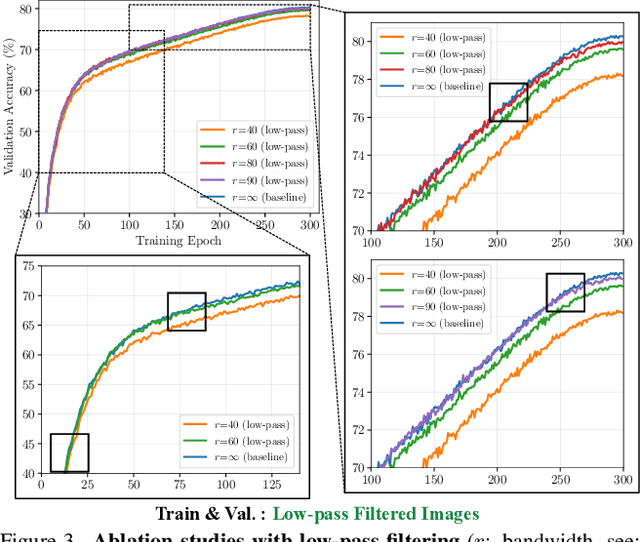
The superior performance of modern deep networks usually comes at the price of a costly training procedure. In this paper, we present a novel curriculum learning approach for the efficient training of visual backbones (e.g., vision Transformers). The proposed method is inspired by the phenomenon that deep networks mainly learn to recognize some 'easier-to-learn' discriminative patterns within each example at earlier stages of training, e.g., the lower-frequency components of images and the original information before data augmentation. Driven by this observation, we propose a curriculum where the model always leverages all the training data at each epoch, while the curriculum starts with only exposing the 'easier-to-learn' patterns of each example, and introduces gradually more difficult patterns. To implement this idea, we 1) introduce a cropping operation in the Fourier spectrum of the inputs, which enables the model to learn from only the lower-frequency components efficiently, and 2) demonstrate that exposing the features of original images amounts to adopting weaker data augmentation. Our resulting algorithm, EfficientTrain, is simple, general, yet surprisingly effective. For example, it reduces the training time of a wide variety of popular models (e.g., ConvNeXts, DeiT, PVT, and Swin/CSWin Transformers) by more than ${1.5\times}$ on ImageNet-1K/22K without sacrificing the accuracy. It is effective for self-supervised learning (i.e., MAE) as well. Code is available at https://github.com/LeapLabTHU/EfficientTrain.
ConStruct-VL: Data-Free Continual Structured VL Concepts Learning
Nov 17, 2022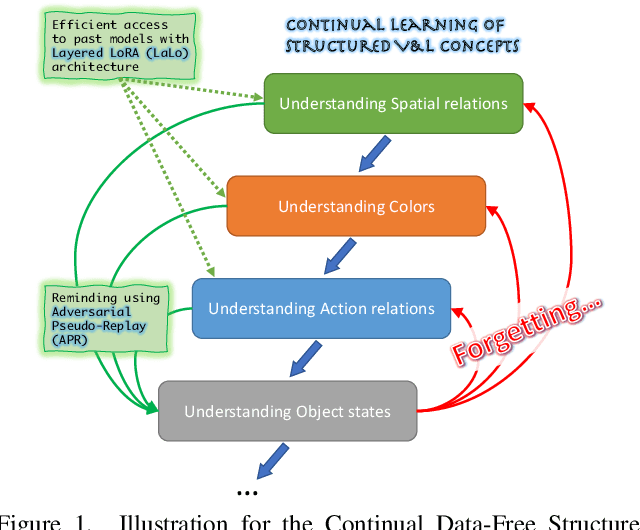
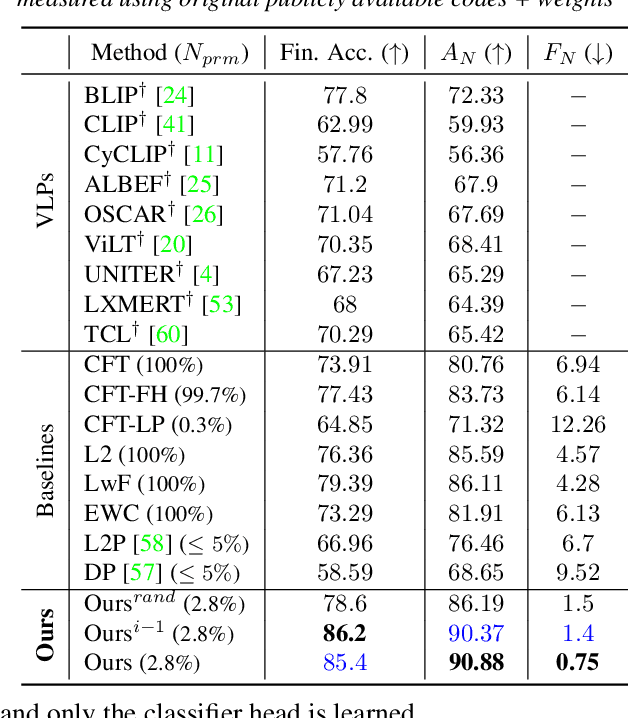
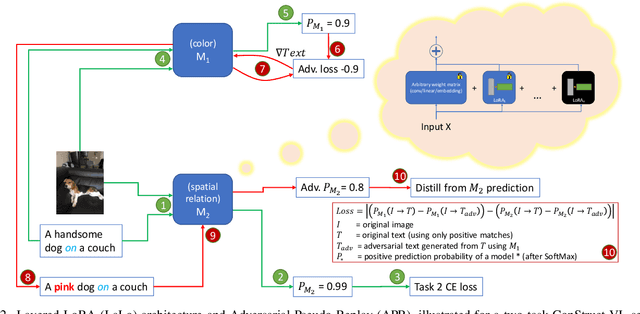
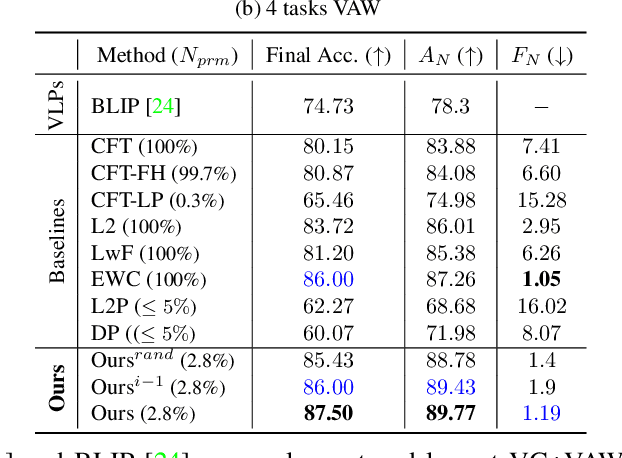
Recently, large-scale pre-trained Vision-and-Language (VL) foundation models have demonstrated remarkable capabilities in many zero-shot downstream tasks, achieving competitive results for recognizing objects defined by as little as short text prompts. However, it has also been shown that VL models are still brittle in Structured VL Concept (SVLC) reasoning, such as the ability to recognize object attributes, states, and inter-object relations. This leads to reasoning mistakes, which need to be corrected as they occur by teaching VL models the missing SVLC skills; often this must be done using private data where the issue was found, which naturally leads to a data-free continual (no task-id) VL learning setting. In this work, we introduce the first Continual Data-Free Structured VL Concepts Learning (ConStruct-VL) benchmark and show it is challenging for many existing data-free CL strategies. We, therefore, propose a data-free method comprised of a new approach of Adversarial Pseudo-Replay (APR) which generates adversarial reminders of past tasks from past task models. To use this method efficiently, we also propose a continual parameter-efficient Layered-LoRA (LaLo) neural architecture allowing no-memory-cost access to all past models at train time. We show this approach outperforms all data-free methods by as much as ~7% while even matching some levels of experience-replay (prohibitive for applications where data-privacy must be preserved).
Planning Irregular Object Packing via Hierarchical Reinforcement Learning
Nov 17, 2022
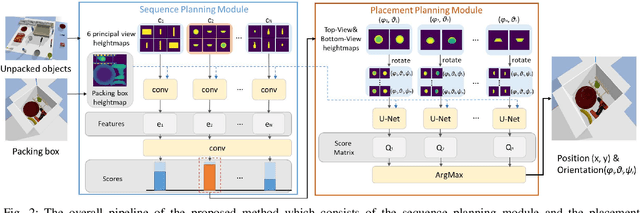
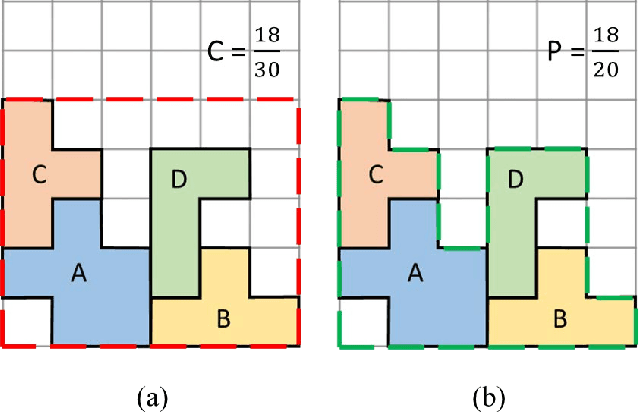

Object packing by autonomous robots is an im-portant challenge in warehouses and logistics industry. Most conventional data-driven packing planning approaches focus on regular cuboid packing, which are usually heuristic and limit the practical use in realistic applications with everyday objects. In this paper, we propose a deep hierarchical reinforcement learning approach to simultaneously plan packing sequence and placement for irregular object packing. Specifically, the top manager network infers packing sequence from six principal view heightmaps of all objects, and then the bottom worker network receives heightmaps of the next object to predict the placement position and orientation. The two networks are trained hierarchically in a self-supervised Q-Learning framework, where the rewards are provided by the packing results based on the top height , object volume and placement stability in the box. The framework repeats sequence and placement planning iteratively until all objects have been packed into the box or no space is remained for unpacked items. We compare our approach with existing robotic packing methods for irregular objects in a physics simulator. Experiments show that our approach can pack more objects with less time cost than the state-of-the-art packing methods of irregular objects. We also implement our packing plan with a robotic manipulator to show the generalization ability in the real world.