 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Context-aware Fine-tuning of Self-supervised Speech Models
Dec 16, 2022
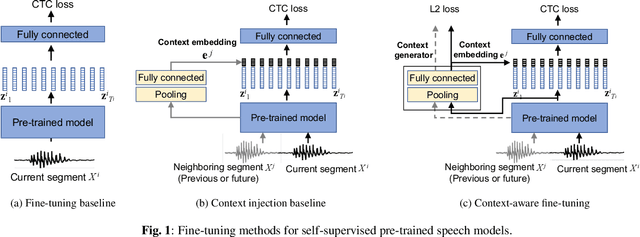
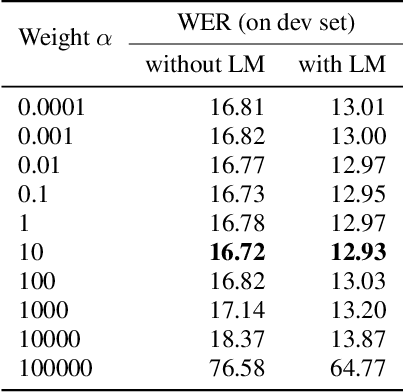
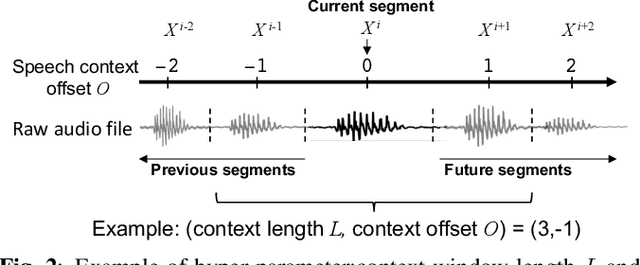
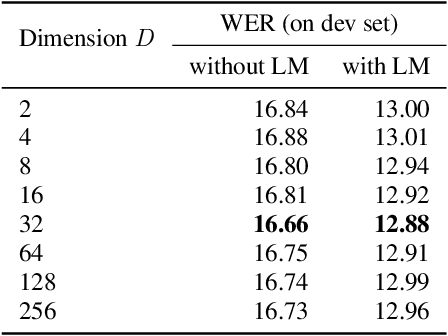
Self-supervised pre-trained transformers have improved the state of the art on a variety of speech tasks. Due to the quadratic time and space complexity of self-attention, they usually operate at the level of relatively short (e.g., utterance) segments. In this paper, we study the use of context, i.e., surrounding segments, during fine-tuning and propose a new approach called context-aware fine-tuning. We attach a context module on top of the last layer of a pre-trained model to encode the whole segment into a context embedding vector which is then used as an additional feature for the final prediction. During the fine-tuning stage, we introduce an auxiliary loss that encourages this context embedding vector to be similar to context vectors of surrounding segments. This allows the model to make predictions without access to these surrounding segments at inference time and requires only a tiny overhead compared to standard fine-tuned models. We evaluate the proposed approach using the SLUE and Librilight benchmarks for several downstream tasks: Automatic speech recognition (ASR), named entity recognition (NER), and sentiment analysis (SA). The results show that context-aware fine-tuning not only outperforms a standard fine-tuning baseline but also rivals a strong context injection baseline that uses neighboring speech segments during inference.
SplitGP: Achieving Both Generalization and Personalization in Federated Learning
Dec 16, 2022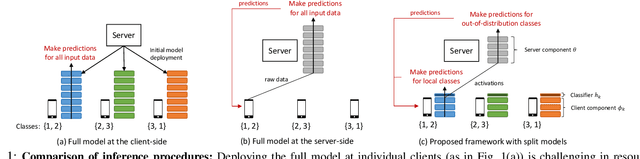
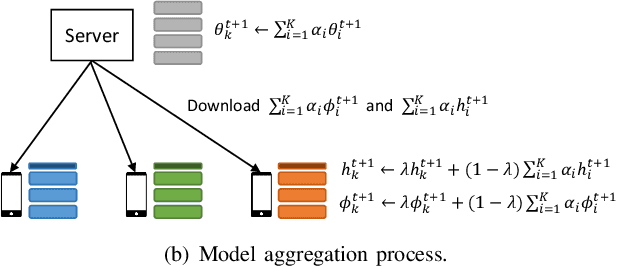
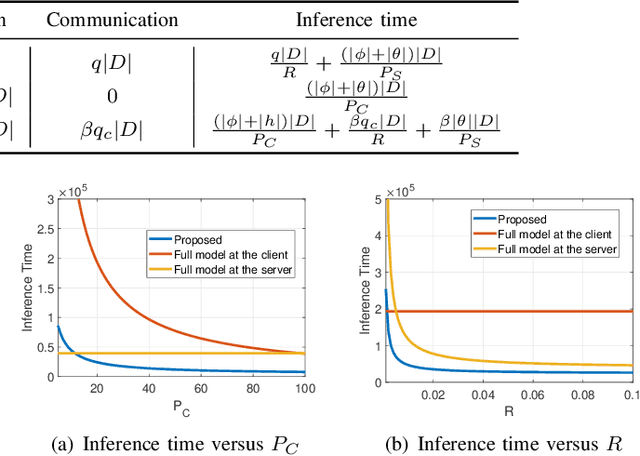
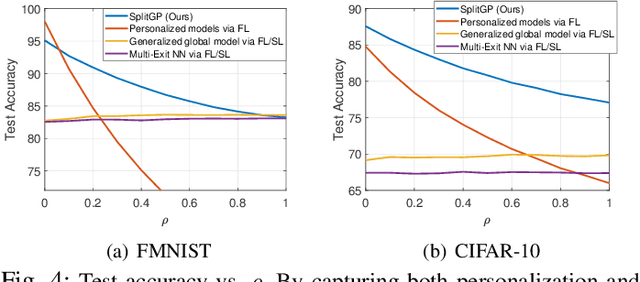
A fundamental challenge to providing edge-AI services is the need for a machine learning (ML) model that achieves personalization (i.e., to individual clients) and generalization (i.e., to unseen data) properties concurrently. Existing techniques in federated learning (FL) have encountered a steep tradeoff between these objectives and impose large computational requirements on edge devices during training and inference. In this paper, we propose SplitGP, a new split learning solution that can simultaneously capture generalization and personalization capabilities for efficient inference across resource-constrained clients (e.g., mobile/IoT devices). Our key idea is to split the full ML model into client-side and server-side components, and impose different roles to them: the client-side model is trained to have strong personalization capability optimized to each client's main task, while the server-side model is trained to have strong generalization capability for handling all clients' out-of-distribution tasks. We analytically characterize the convergence behavior of SplitGP, revealing that all client models approach stationary points asymptotically. Further, we analyze the inference time in SplitGP and provide bounds for determining model split ratios. Experimental results show that SplitGP outperforms existing baselines by wide margins in inference time and test accuracy for varying amounts of out-of-distribution samples.
POIBERT: A Transformer-based Model for the Tour Recommendation Problem
Dec 16, 2022
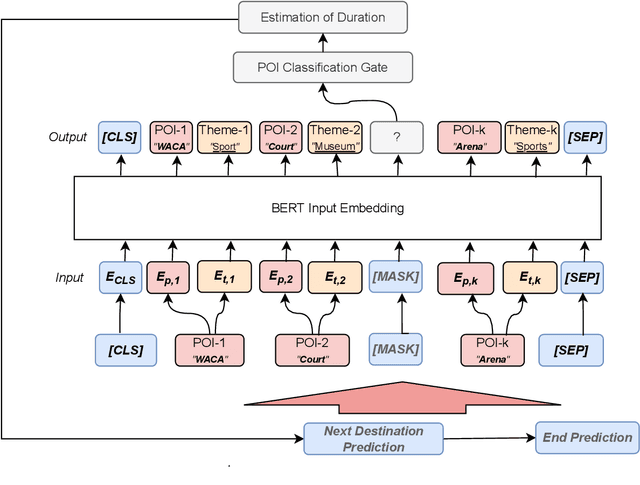
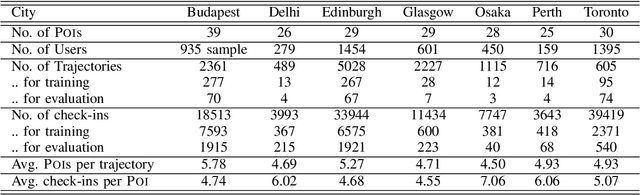
Tour itinerary planning and recommendation are challenging problems for tourists visiting unfamiliar cities. Many tour recommendation algorithms only consider factors such as the location and popularity of Points of Interest (POIs) but their solutions may not align well with the user's own preferences and other location constraints. Additionally, these solutions do not take into consideration of the users' preference based on their past POIs selection. In this paper, we propose POIBERT, an algorithm for recommending personalized itineraries using the BERT language model on POIs. POIBERT builds upon the highly successful BERT language model with the novel adaptation of a language model to our itinerary recommendation task, alongside an iterative approach to generate consecutive POIs. Our recommendation algorithm is able to generate a sequence of POIs that optimizes time and users' preference in POI categories based on past trajectories from similar tourists. Our tour recommendation algorithm is modeled by adapting the itinerary recommendation problem to the sentence completion problem in natural language processing (NLP). We also innovate an iterative algorithm to generate travel itineraries that satisfies the time constraints which is most likely from past trajectories. Using a Flickr dataset of seven cities, experimental results show that our algorithm out-performs many sequence prediction algorithms based on measures in recall, precision and F1-scores.
Deep Learning of Force Manifolds from the Simulated Physics of Robotic Paper Folding
Jan 05, 2023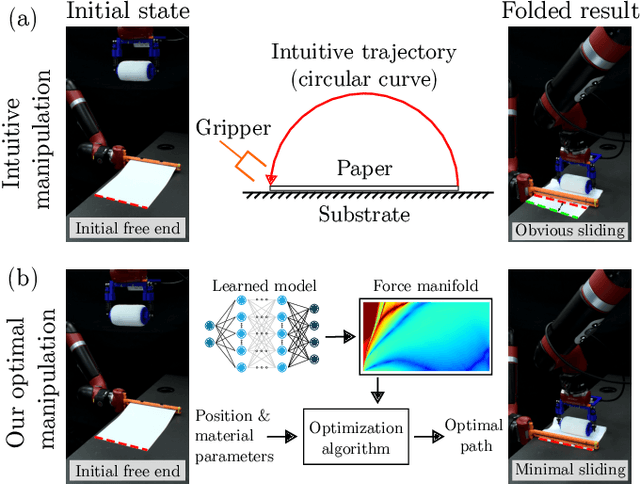
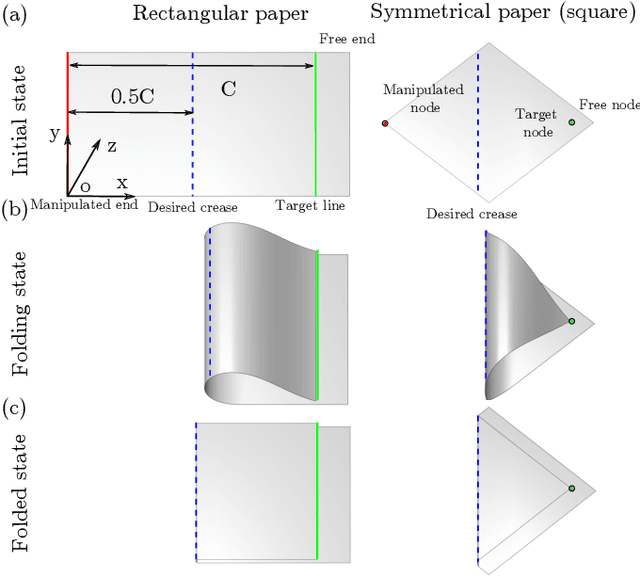
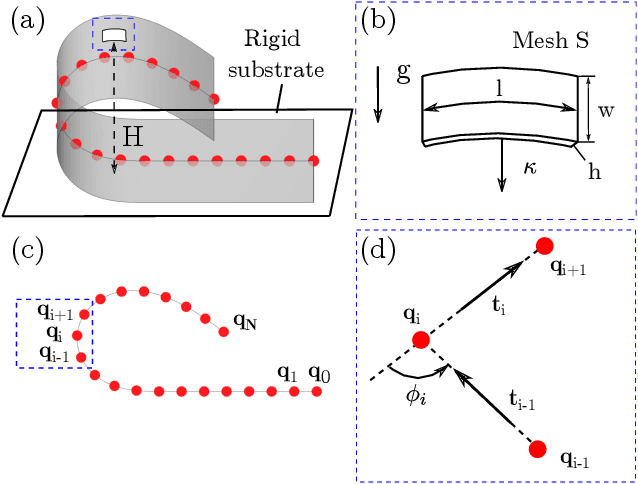
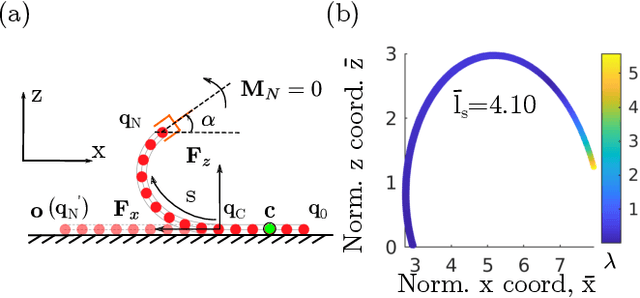
Robotic manipulation of slender objects is challenging, especially when the induced deformations are large and nonlinear. Traditionally, learning-based control approaches, e.g., imitation learning, have been used to tackle deformable material manipulation. Such approaches lack generality and often suffer critical failure from a simple switch of material, geometric, and/or environmental (e.g., friction) properties. In this article, we address a fundamental but difficult step of robotic origami: forming a predefined fold in paper with only a single manipulator. A data-driven framework combining physically-accurate simulation and machine learning is used to train deep neural network models capable of predicting the external forces induced on the paper given a grasp position. We frame the problem using scaling analysis, resulting in a control framework robust against material and geometric changes. Path planning is carried out over the generated manifold to produce robot manipulation trajectories optimized to prevent sliding. Furthermore, the inference speed of the trained model enables the incorporation of real-time visual feedback to achieve closed-loop sensorimotor control. Real-world experiments demonstrate that our framework can greatly improve robotic manipulation performance compared against natural paper folding strategies, even when manipulating paper objects of various materials and shapes.
Autonomous Drone Racing: A Survey
Jan 05, 2023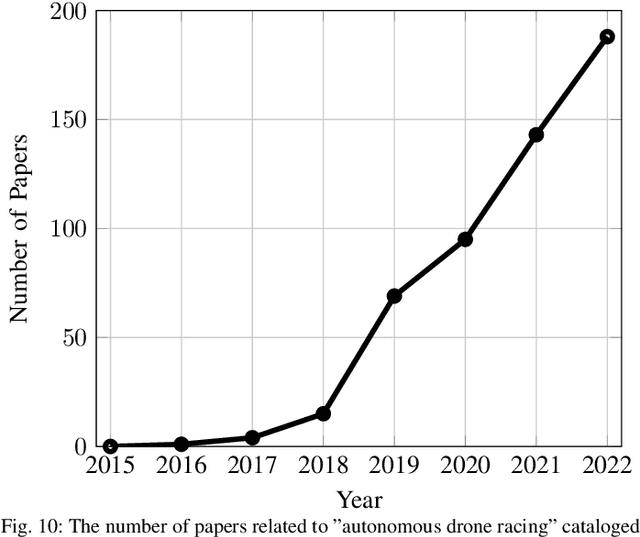


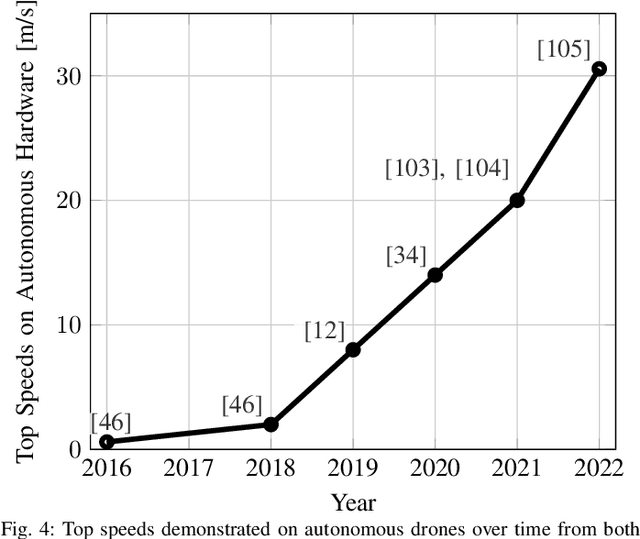
Over the last decade, the use of autonomous drone systems for surveying, search and rescue, or last-mile delivery has increased exponentially. With the rise of these applications comes the need for highly robust, safety-critical algorithms which can operate drones in complex and uncertain environments. Additionally, flying fast enables drones to cover more ground which in turn increases productivity and further strengthens their use case. One proxy for developing algorithms used in high-speed navigation is the task of autonomous drone racing, where researchers program drones to fly through a sequence of gates and avoid obstacles as quickly as possible using onboard sensors and limited computational power. Speeds and accelerations exceed over 80 kph and 4 g respectively, raising significant challenges across perception, planning, control, and state estimation. To achieve maximum performance, systems require real-time algorithms that are robust to motion blur, high dynamic range, model uncertainties, aerodynamic disturbances, and often unpredictable opponents. This survey covers the progression of autonomous drone racing across model-based and learning-based approaches. We provide an overview of the field, its evolution over the years, and conclude with the biggest challenges and open questions to be faced in the future.
CLIP2Scene: Towards Label-efficient 3D Scene Understanding by CLIP
Jan 12, 2023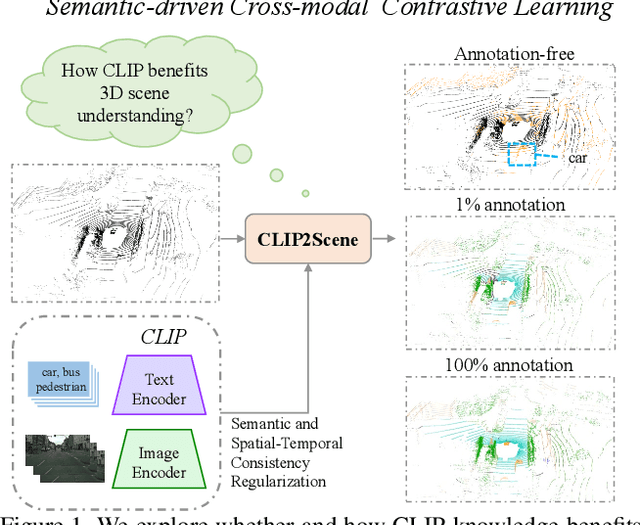
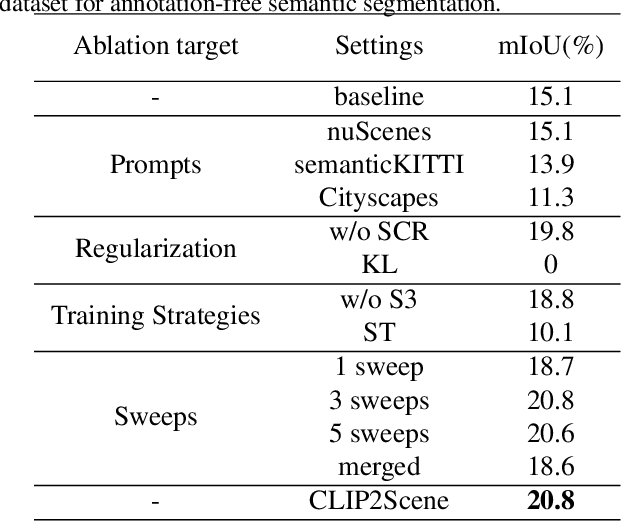
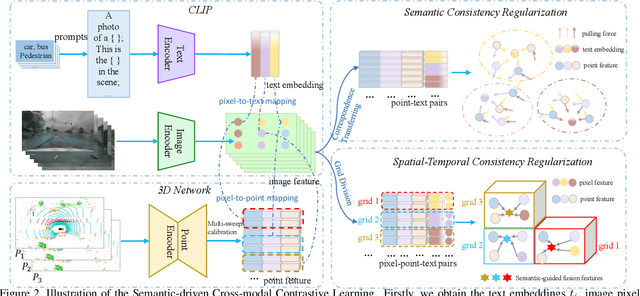
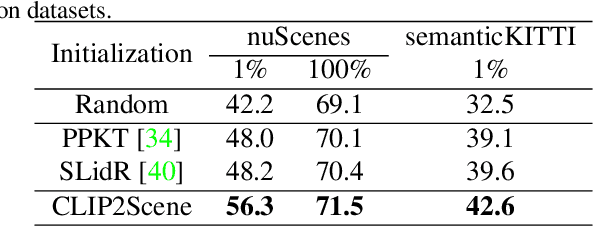
Contrastive language-image pre-training (CLIP) achieves promising results in 2D zero-shot and few-shot learning. Despite the impressive performance in 2D tasks, applying CLIP to help the learning in 3D scene understanding has yet to be explored. In this paper, we make the first attempt to investigate how CLIP knowledge benefits 3D scene understanding. To this end, we propose CLIP2Scene, a simple yet effective framework that transfers CLIP knowledge from 2D image-text pre-trained models to a 3D point cloud network. We show that the pre-trained 3D network yields impressive performance on various downstream tasks, i.e., annotation-free and fine-tuning with labelled data for semantic segmentation. Specifically, built upon CLIP, we design a Semantic-driven Cross-modal Contrastive Learning framework that pre-trains a 3D network via semantic and spatial-temporal consistency regularization. For semantic consistency regularization, we first leverage CLIP's text semantics to select the positive and negative point samples and then employ the contrastive loss to train the 3D network. In terms of spatial-temporal consistency regularization, we force the consistency between the temporally coherent point cloud features and their corresponding image features. We conduct experiments on the nuScenes and SemanticKITTI datasets. For the first time, our pre-trained network achieves annotation-free 3D semantic segmentation with 20.8\% mIoU. When fine-tuned with 1\% or 100\% labelled data, our method significantly outperforms other self-supervised methods, with improvements of 8\% and 1\% mIoU, respectively. Furthermore, we demonstrate its generalization capability for handling cross-domain datasets.
Scene-Aware 3D Multi-Human Motion Capture from a Single Camera
Jan 12, 2023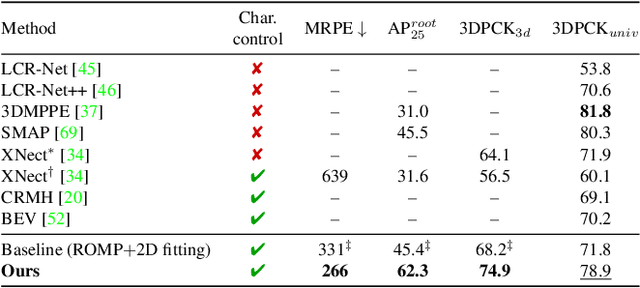
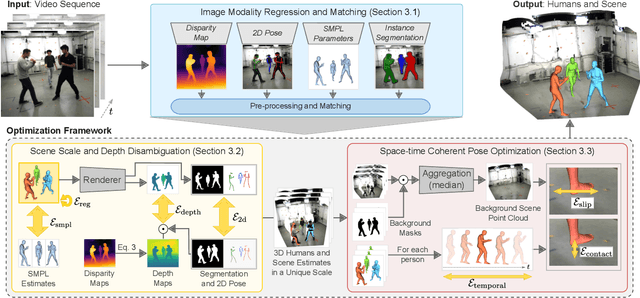


In this work, we consider the problem of estimating the 3D position of multiple humans in a scene as well as their body shape and articulation from a single RGB video recorded with a static camera. In contrast to expensive marker-based or multi-view systems, our lightweight setup is ideal for private users as it enables an affordable 3D motion capture that is easy to install and does not require expert knowledge. To deal with this challenging setting, we leverage recent advances in computer vision using large-scale pre-trained models for a variety of modalities, including 2D body joints, joint angles, normalized disparity maps, and human segmentation masks. Thus, we introduce the first non-linear optimization-based approach that jointly solves for the absolute 3D position of each human, their articulated pose, their individual shapes as well as the scale of the scene. In particular, we estimate the scene depth and person unique scale from normalized disparity predictions using the 2D body joints and joint angles. Given the per-frame scene depth, we reconstruct a point-cloud of the static scene in 3D space. Finally, given the per-frame 3D estimates of the humans and scene point-cloud, we perform a space-time coherent optimization over the video to ensure temporal, spatial and physical plausibility. We evaluate our method on established multi-person 3D human pose benchmarks where we consistently outperform previous methods and we qualitatively demonstrate that our method is robust to in-the-wild conditions including challenging scenes with people of different sizes.
A Novel Experts Advice Aggregation Framework Using Deep Reinforcement Learning for Portfolio Management
Dec 29, 2022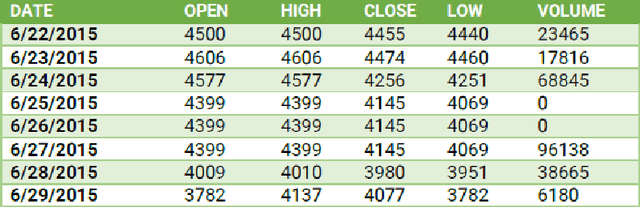


Solving portfolio management problems using deep reinforcement learning has been getting much attention in finance for a few years. We have proposed a new method using experts signals and historical price data to feed into our reinforcement learning framework. Although experts signals have been used in previous works in the field of finance, as far as we know, it is the first time this method, in tandem with deep RL, is used to solve the financial portfolio management problem. Our proposed framework consists of a convolutional network for aggregating signals, another convolutional network for historical price data, and a vanilla network. We used the Proximal Policy Optimization algorithm as the agent to process the reward and take action in the environment. The results suggested that, on average, our framework could gain 90 percent of the profit earned by the best expert.
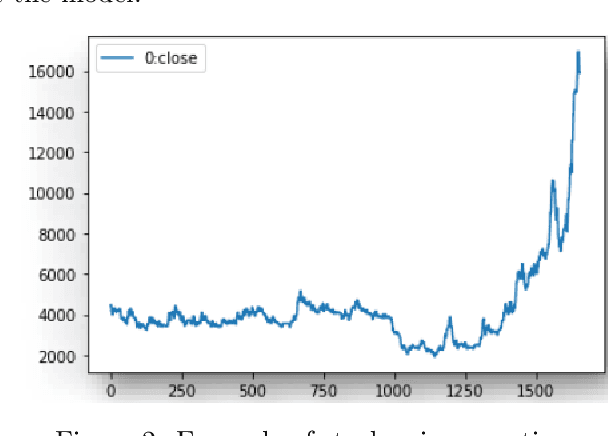
TreeDRNet:A Robust Deep Model for Long Term Time Series Forecasting
Jun 24, 2022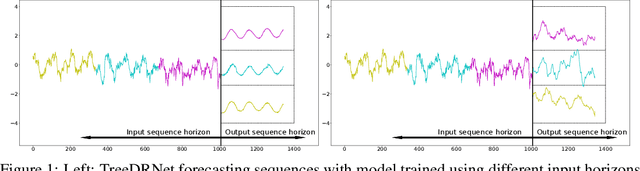
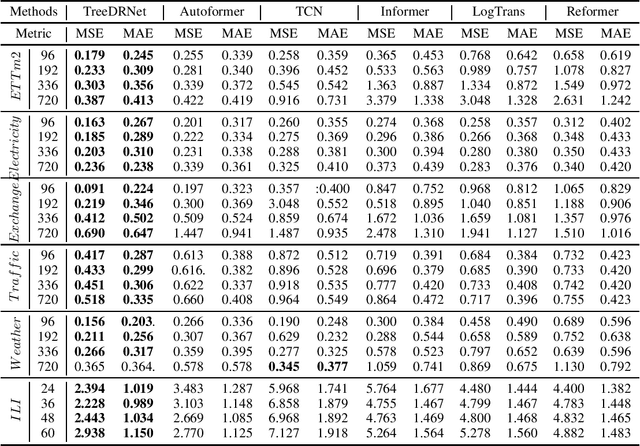
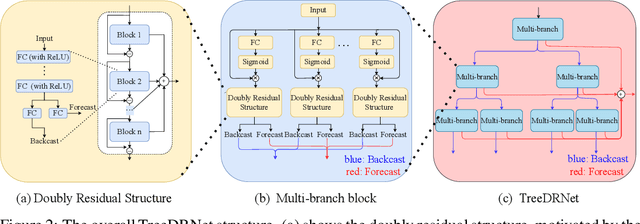

Various deep learning models, especially some latest Transformer-based approaches, have greatly improved the state-of-art performance for long-term time series forecasting.However, those transformer-based models suffer a severe deterioration performance with prolonged input length, which prohibits them from using extended historical info.Moreover, these methods tend to handle complex examples in long-term forecasting with increased model complexity, which often leads to a significant increase in computation and less robustness in performance(e.g., overfitting). We propose a novel neural network architecture, called TreeDRNet, for more effective long-term forecasting. Inspired by robust regression, we introduce doubly residual link structure to make prediction more robust.Built upon Kolmogorov-Arnold representation theorem, we explicitly introduce feature selection, model ensemble, and a tree structure to further utilize the extended input sequence, which improves the robustness and representation power of TreeDRNet. Unlike previous deep models for sequential forecasting work, TreeDRNet is built entirely on multilayer perceptron and thus enjoys high computational efficiency. Our extensive empirical studies show that TreeDRNet is significantly more effective than state-of-the-art methods, reducing prediction errors by 20% to 40% for multivariate time series. In particular, TreeDRNet is over 10 times more efficient than transformer-based methods. The code will be released soon.
Deep Reinforcement Learning for Trajectory Path Planning and Distributed Inference in Resource-Constrained UAV Swarms
Dec 21, 2022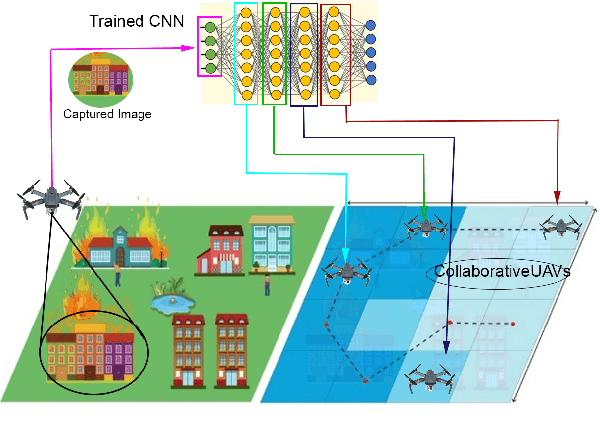
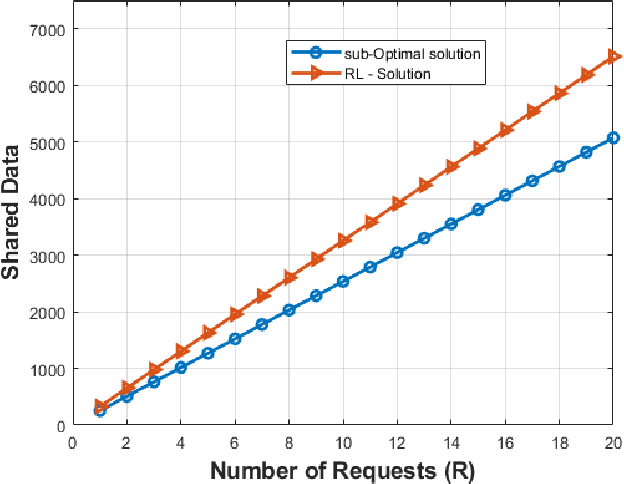
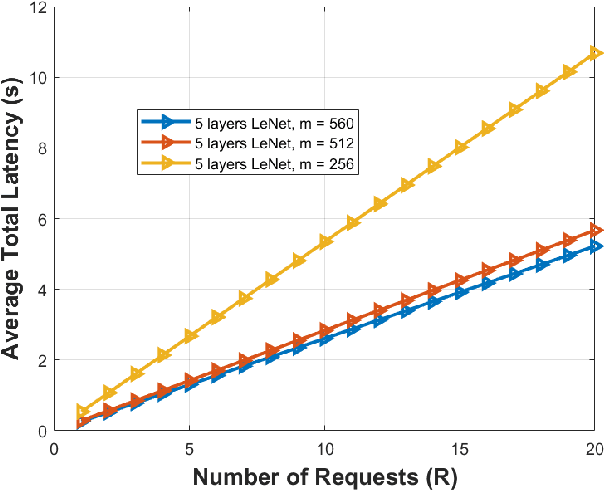
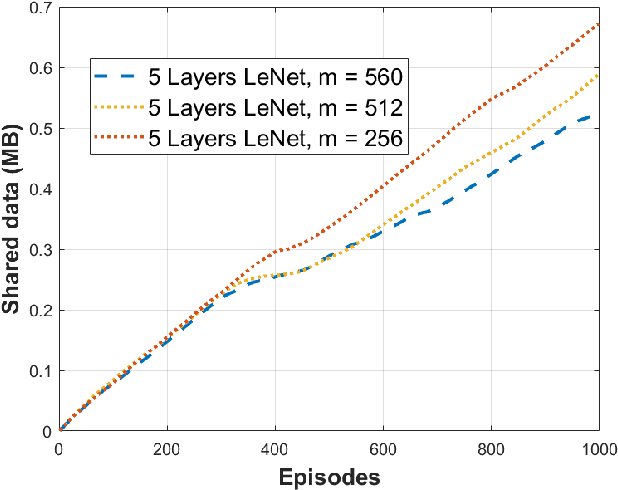
The deployment flexibility and maneuverability of Unmanned Aerial Vehicles (UAVs) increased their adoption in various applications, such as wildfire tracking, border monitoring, etc. In many critical applications, UAVs capture images and other sensory data and then send the captured data to remote servers for inference and data processing tasks. However, this approach is not always practical in real-time applications due to the connection instability, limited bandwidth, and end-to-end latency. One promising solution is to divide the inference requests into multiple parts (layers or segments), with each part being executed in a different UAV based on the available resources. Furthermore, some applications require the UAVs to traverse certain areas and capture incidents; thus, planning their paths becomes critical particularly, to reduce the latency of making the collaborative inference process. Specifically, planning the UAVs trajectory can reduce the data transmission latency by communicating with devices in the same proximity while mitigating the transmission interference. This work aims to design a model for distributed collaborative inference requests and path planning in a UAV swarm while respecting the resource constraints due to the computational load and memory usage of the inference requests. The model is formulated as an optimization problem and aims to minimize latency. The formulated problem is NP-hard so finding the optimal solution is quite complex; thus, this paper introduces a real-time and dynamic solution for online applications using deep reinforcement learning. We conduct extensive simulations and compare our results to the-state-of-the-art studies demonstrating that our model outperforms the competing models.