 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Using Detection, Tracking and Prediction in Visual SLAM to Achieve Real-time Semantic Mapping of Dynamic Scenarios
Oct 10, 2022
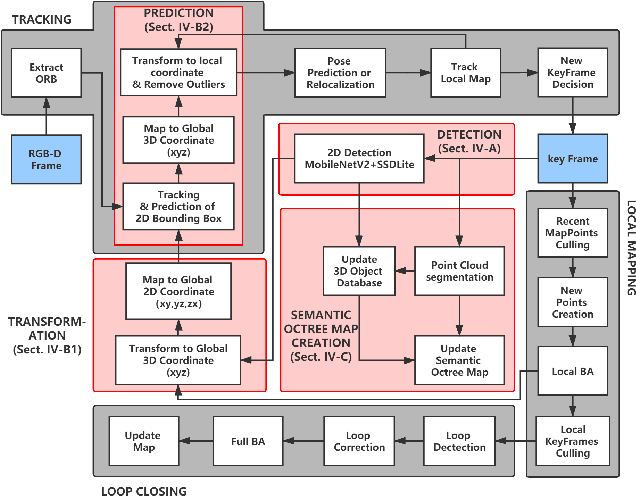
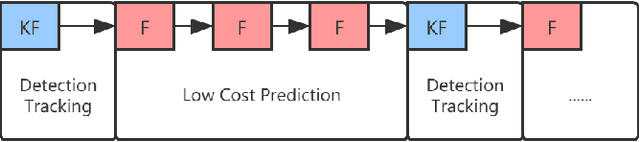
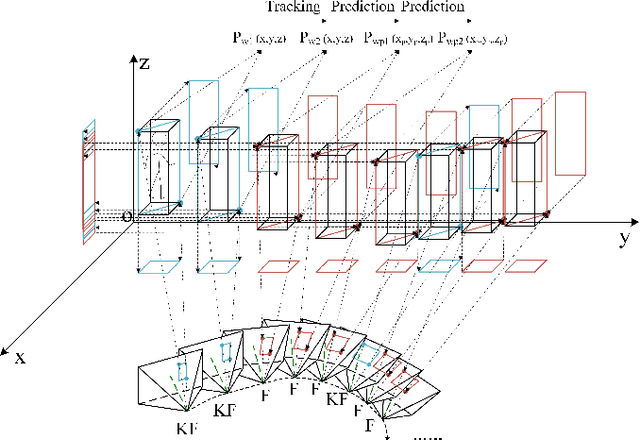

In this paper, we propose a lightweight system, RDS-SLAM, based on ORB-SLAM2, which can accurately estimate poses and build semantic maps at object level for dynamic scenarios in real time using only one commonly used Intel Core i7 CPU. In RDS-SLAM, three major improvements, as well as major architectural modifications, are proposed to overcome the limitations of ORB-SLAM2. Firstly, it adopts a lightweight object detection neural network in key frames. Secondly, an efficient tracking and prediction mechanism is embedded into the system to remove the feature points belonging to movable objects in all incoming frames. Thirdly, a semantic octree map is built by probabilistic fusion of detection and tracking results, which enables a robot to maintain a semantic description at object level for potential interactions in dynamic scenarios. We evaluate RDS-SLAM in TUM RGB-D dataset, and experimental results show that RDS-SLAM can run with 30.3 ms per frame in dynamic scenarios using only an Intel Core i7 CPU, and achieves comparable accuracy compared with the state-of-the-art SLAM systems which heavily rely on both Intel Core i7 CPUs and powerful GPUs.
Self-Averaging of Digital MemComputing Machines
Jan 20, 2023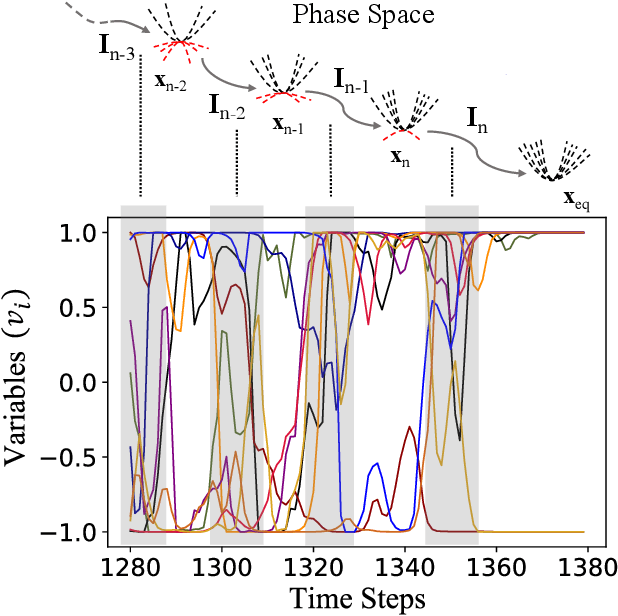
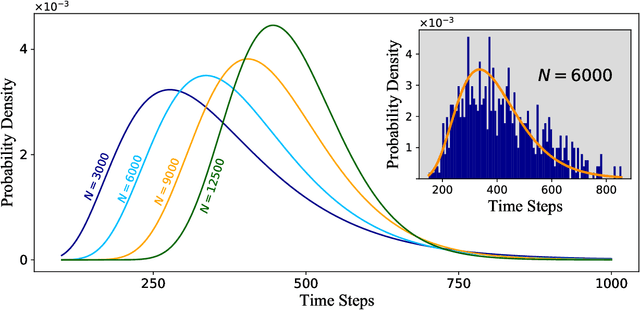
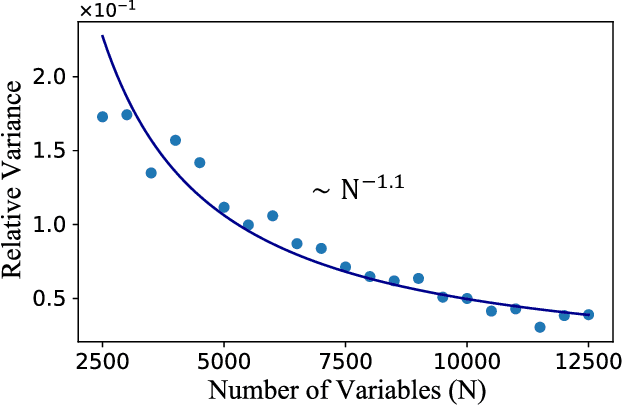
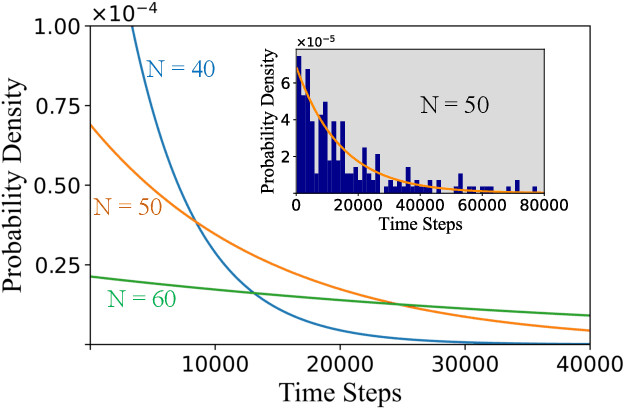
Digital MemComputing machines (DMMs) are a new class of computing machines that employ non-quantum dynamical systems with memory to solve combinatorial optimization problems. Here, we show that the time to solution (TTS) of DMMs follows an inverse Gaussian distribution, with the TTS self-averaging with increasing problem size, irrespective of the problem they solve. We provide both an analytical understanding of this phenomenon and numerical evidence by solving instances of the 3-SAT (satisfiability) problem. The self-averaging property of DMMs with problem size implies that they are increasingly insensitive to the detailed features of the instances they solve. This is in sharp contrast to traditional algorithms applied to the same problems, illustrating another advantage of this physics-based approach to computation.
Massively Parallel Genetic Optimization through Asynchronous Propagation of Populations
Jan 20, 2023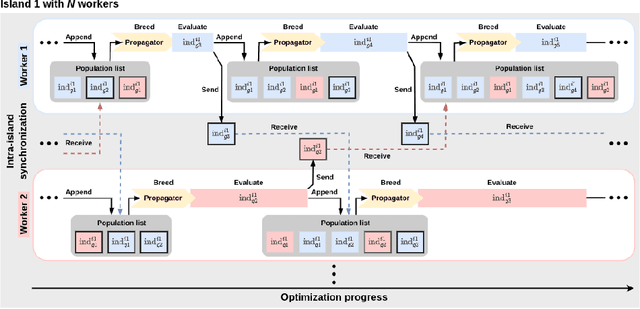

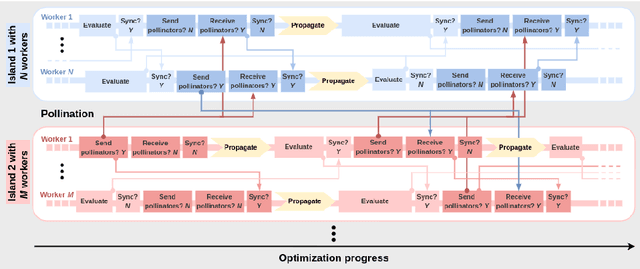
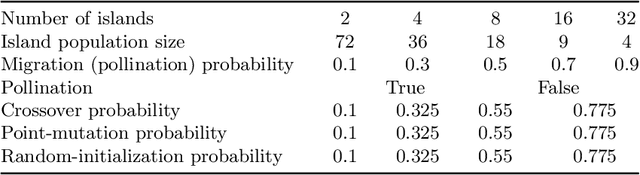
We present Propulate, an evolutionary optimization algorithm and software package for global optimization and in particular hyperparameter search. For efficient use of HPC resources, Propulate omits the synchronization after each generation as done in conventional genetic algorithms. Instead, it steers the search with the complete population present at time of breeding new individuals. We provide an MPI-based implementation of our algorithm, which features variants of selection, mutation, crossover, and migration and is easy to extend with custom functionality. We compare Propulate to the established optimization tool Optuna. We find that Propulate is up to three orders of magnitude faster without sacrificing solution accuracy, demonstrating the efficiency and efficacy of our lazy synchronization approach. Code and documentation are available at https://github.com/Helmholtz-AI-Energy/propulate
Scaling in Depth: Unlocking Robustness Certification on ImageNet
Jan 29, 2023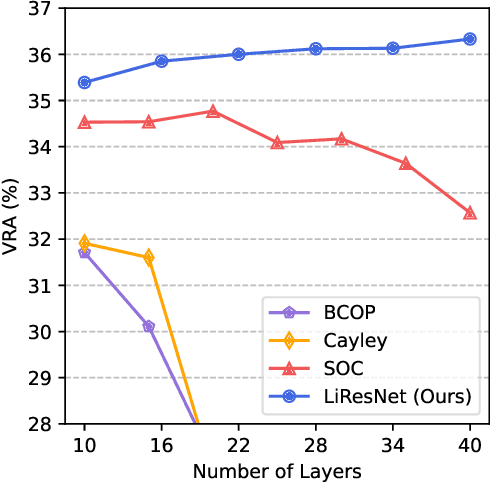
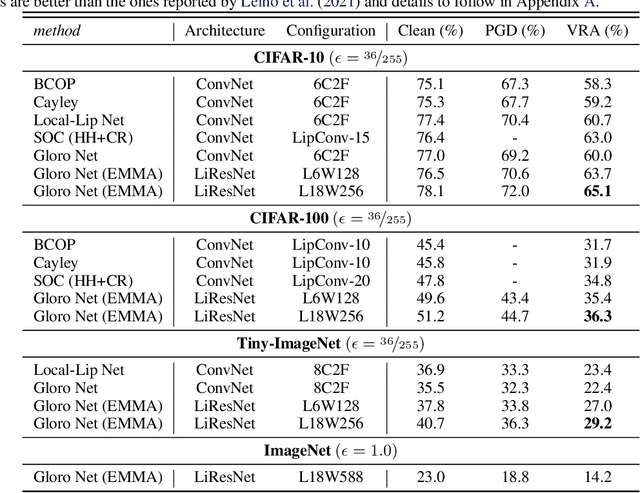
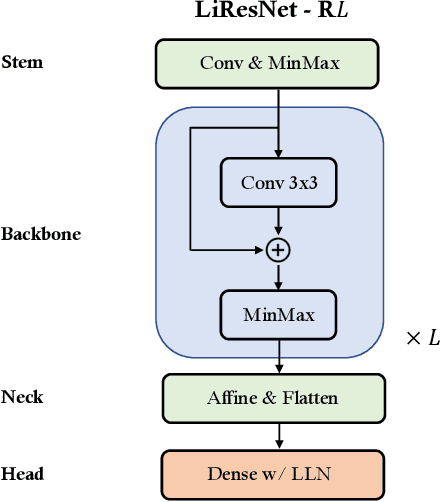
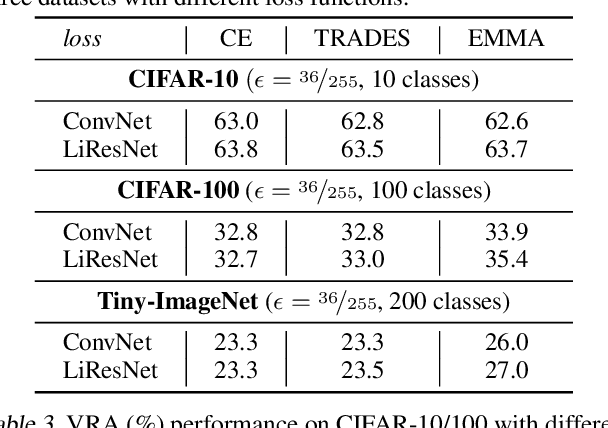
Notwithstanding the promise of Lipschitz-based approaches to \emph{deterministically} train and certify robust deep networks, the state-of-the-art results only make successful use of feed-forward Convolutional Networks (ConvNets) on low-dimensional data, e.g. CIFAR-10. Because ConvNets often suffer from vanishing gradients when going deep, large-scale datasets with many classes, e.g., ImageNet, have remained out of practical reach. This paper investigates ways to scale up certifiably robust training to Residual Networks (ResNets). First, we introduce the \emph{Linear ResNet} (LiResNet) architecture, which utilizes a new residual block designed to facilitate \emph{tighter} Lipschitz bounds compared to a conventional residual block. Second, we introduce Efficient Margin MAximization (EMMA), a loss function that stabilizes robust training by simultaneously penalizing worst-case adversarial examples from \emph{all} classes. Combining LiResNet and EMMA, we achieve new \emph{state-of-the-art} robust accuracy on CIFAR-10/100 and Tiny-ImageNet under $\ell_2$-norm-bounded perturbations. Moreover, for the first time, we are able to scale up deterministic robustness guarantees to ImageNet, bringing hope to the possibility of applying deterministic certification to real-world applications.
Continual Learning for Predictive Maintenance: Overview and Challenges
Jan 29, 2023
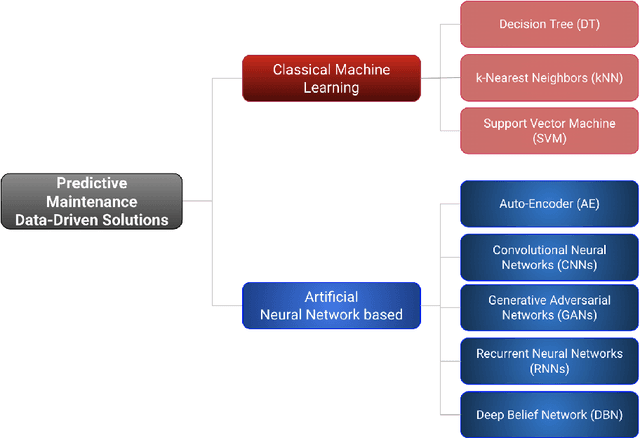
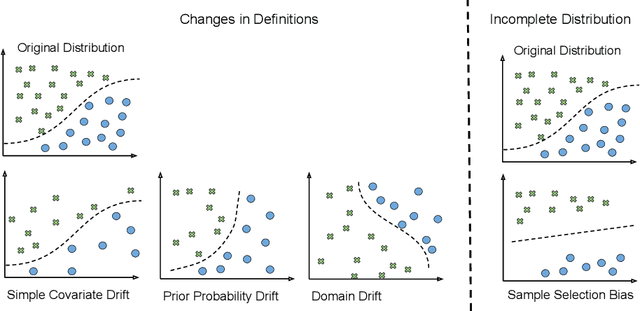
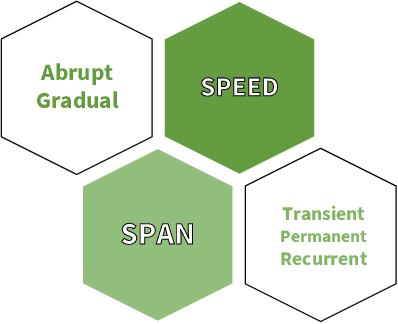
Machine learning techniques have become one of the main propellers for solving many engineering problems effectively and efficiently. In Predictive Maintenance, for instance, Data-Driven methods have been used to improve predictions of when maintenance is needed on different machines and operative contexts. However, one of the limitations of these methods is that they are trained on a fixed distribution that does not change over time, which seldom happens in real-world applications. When internal or external factors alter the data distribution, the model performance may decrease or even fail unpredictably, resulting in severe consequences for machine maintenance. Continual Learning methods propose ways of adapting prediction models and incorporating new knowledge after deployment. The main objective of these methods is to avoid the plasticity-stability dilemma by updating the parametric model while not forgetting previously learned tasks. In this work, we present the current state of the art in applying Continual Learning to Predictive Maintenance, with an extensive review of both disciplines. We first introduce the two research themes independently, then discuss the current intersection of Continual Learning and Predictive Maintenance. Finally, we discuss the main research directions and conclusions.
Neural Wasserstein Gradient Flows for Maximum Mean Discrepancies with Riesz Kernels
Jan 27, 2023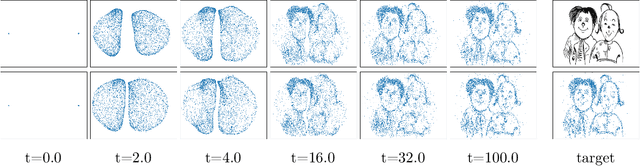
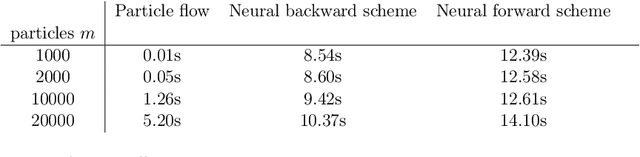
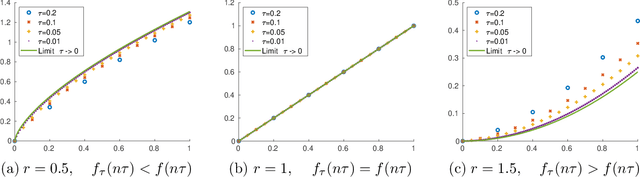
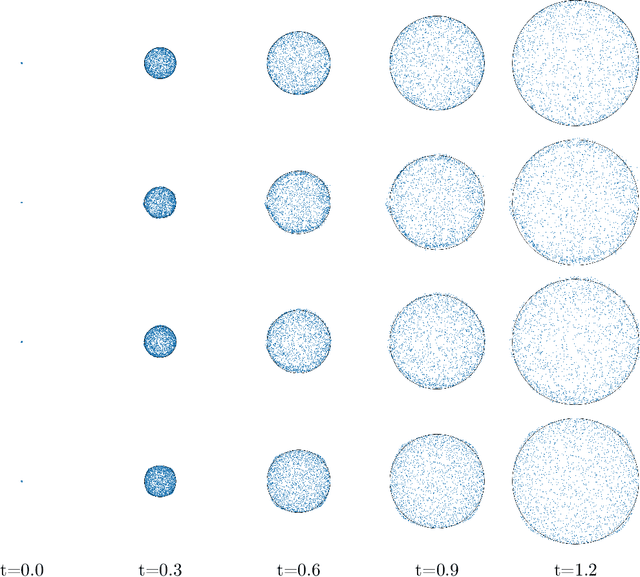
Wasserstein gradient flows of maximum mean discrepancy (MMD) functionals with non-smooth Riesz kernels show a rich structure as singular measures can become absolutely continuous ones and conversely. In this paper we contribute to the understanding of such flows. We propose to approximate the backward scheme of Jordan, Kinderlehrer and Otto for computing such Wasserstein gradient flows as well as a forward scheme for so-called Wasserstein steepest descent flows by neural networks (NNs). Since we cannot restrict ourselves to absolutely continuous measures, we have to deal with transport plans and velocity plans instead of usual transport maps and velocity fields. Indeed, we approximate the disintegration of both plans by generative NNs which are learned with respect to appropriate loss functions. In order to evaluate the quality of both neural schemes, we benchmark them on the interaction energy. Here we provide analytic formulas for Wasserstein schemes starting at a Dirac measure and show their convergence as the time step size tends to zero. Finally, we illustrate our neural MMD flows by numerical examples.
CAPoW: Context-Aware AI-Assisted Proof of Work based DDoS Defense
Jan 27, 2023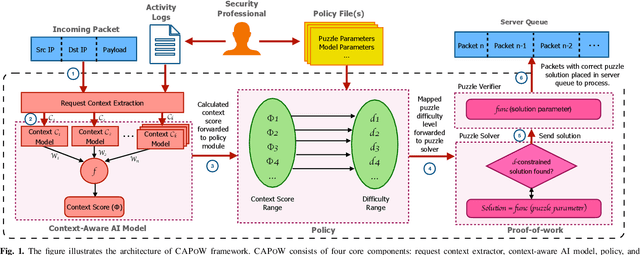
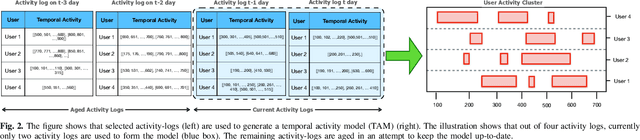
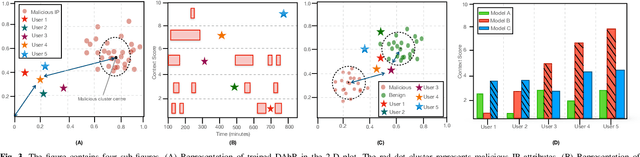
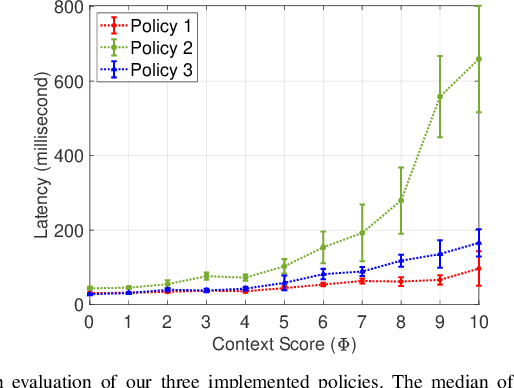
Critical servers can be secured against distributed denial of service (DDoS) attacks using proof of work (PoW) systems assisted by an Artificial Intelligence (AI) that learns contextual network request patterns. In this work, we introduce CAPoW, a context-aware anti-DDoS framework that injects latency adaptively during communication by utilizing context-aware PoW puzzles. In CAPoW, a security professional can define relevant request context attributes which can be learned by the AI system. These contextual attributes can include information about the user request, such as IP address, time, flow-level information, etc., and are utilized to generate a contextual score for incoming requests that influence the hardness of a PoW puzzle. These puzzles need to be solved by a user before the server begins to process their request. Solving puzzles slow down the volume of incoming adversarial requests. Additionally, the framework compels the adversary to incur a cost per request, hence making it expensive for an adversary to prolong a DDoS attack. We include the theoretical foundations of the CAPoW framework along with a description of its implementation and evaluation.
Deconfounding Duration Bias in Watch-time Prediction for Video Recommendation
Jun 13, 2022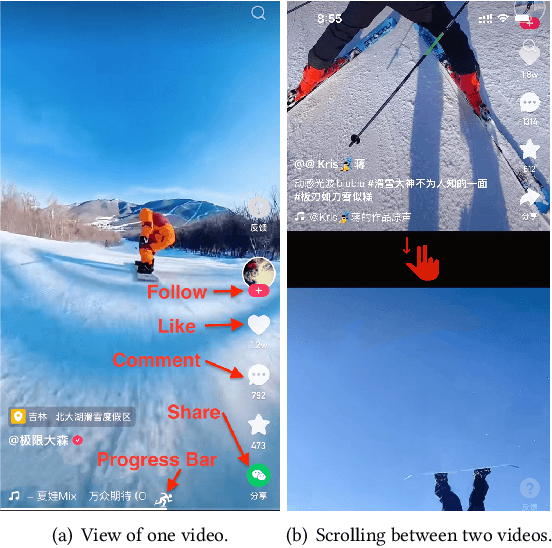

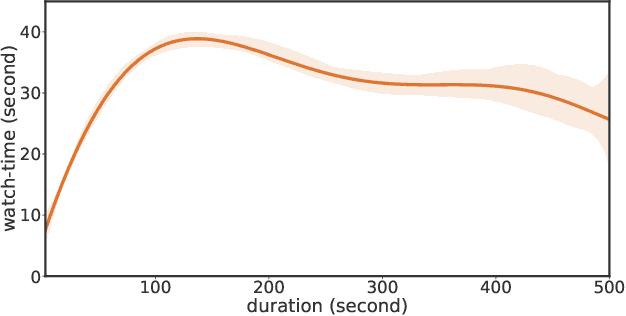
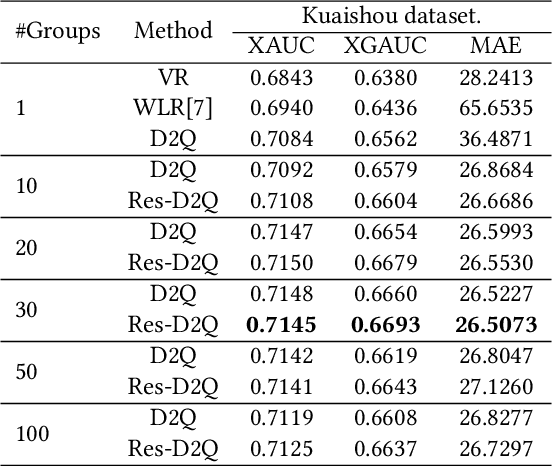
Watch-time prediction remains to be a key factor in reinforcing user engagement via video recommendations. It has become increasingly important given the ever-growing popularity of online videos. However, prediction of watch time not only depends on the match between the user and the video but is often mislead by the duration of the video itself. With the goal of improving watch time, recommendation is always biased towards videos with long duration. Models trained on this imbalanced data face the risk of bias amplification, which misguides platforms to over-recommend videos with long duration but overlook the underlying user interests. This paper presents the first work to study duration bias in watch-time prediction for video recommendation. We employ a causal graph illuminating that duration is a confounding factor that concurrently affects video exposure and watch-time prediction -- the first effect on video causes the bias issue and should be eliminated, while the second effect on watch time originates from video intrinsic characteristics and should be preserved. To remove the undesired bias but leverage the natural effect, we propose a Duration Deconfounded Quantile-based (D2Q) watch-time prediction framework, which allows for scalability to perform on industry production systems. Through extensive offline evaluation and live experiments, we showcase the effectiveness of this duration-deconfounding framework by significantly outperforming the state-of-the-art baselines. We have fully launched our approach on Kuaishou App, which has substantially improved real-time video consumption due to more accurate watch-time predictions.
TD-BPQBC: A 1.8μW 5.5mm3 ADC-less Neural Implant SoC utilizing 13.2pJ/Sample Time-domain Bi-phasic Quasi-static Brain Communication
Sep 24, 2022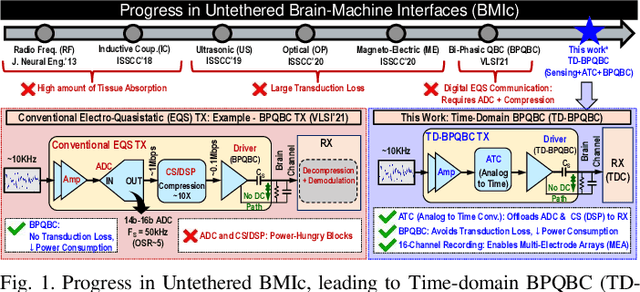
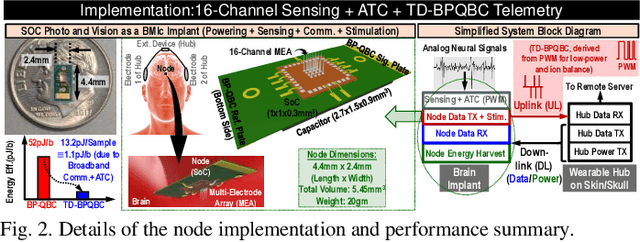
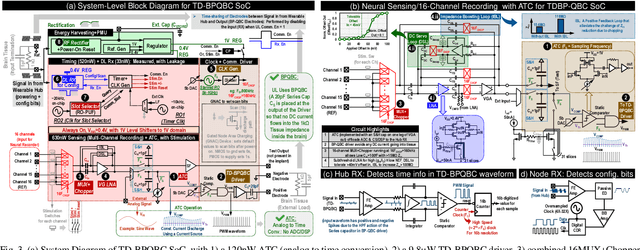

Untethered miniaturized wireless neural sensor nodes with data transmission and energy harvesting capabilities call for circuit and system-level innovations to enable ultra-low energy deep implants for brain-machine interfaces. Realizing that the energy and size constraints of a neural implant motivate highly asymmetric system design (a small, low-power sensor and transmitter at the implant, with a relatively higher power receiver at a body-worn hub), we present Time-Domain Bi-Phasic Quasi-static Brain Communication (TD- BPQBC), offloading the burden of analog to digital conversion (ADC) and digital signal processing (DSP) to the receiver. The input analog signal is converted to time-domain pulse-width modulated (PWM) waveforms, and transmitted using the recently developed BPQBC method for reducing communication power in implants. The overall SoC consumes only 1.8{\mu}W power while sensing and communicating at 800kSps. The transmitter energy efficiency is only 1.1pJ/b, which is >30X better than the state-of-the-art, enabling a fully-electrical, energy-harvested, and connected in-brain sensor/stimulator node.
Less, but Stronger: On the Value of Strong Heuristics in Semi-supervised Learning for Software Analytics
Feb 03, 2023
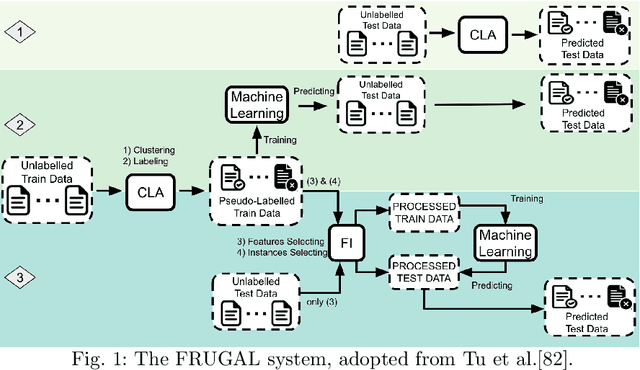
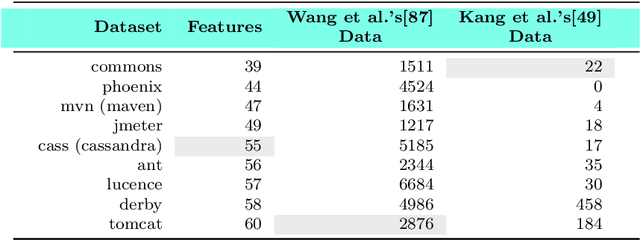
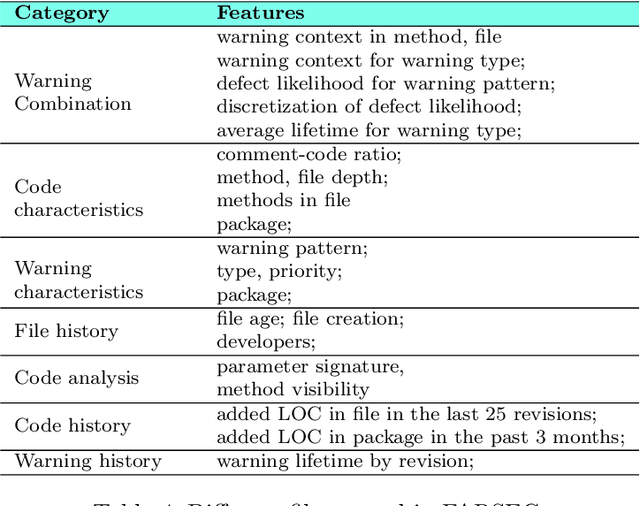
In many domains, there are many examples and far fewer labels for those examples; e.g. we may have access to millions of lines of source code, but access to only a handful of warnings about that code. In those domains, semi-supervised learners (SSL) can extrapolate labels from a small number of examples to the rest of the data. Standard SSL algorithms use ``weak'' knowledge (i.e. those not based on specific SE knowledge) such as (e.g.) co-train two learners and use good labels from one to train the other. Another approach of SSL in software analytics is potentially use ``strong'' knowledge that use SE knowledge. For example, an often-used heuristic in SE is that unusually large artifacts contain undesired properties (e.g. more bugs). This paper argues that such ``strong'' algorithms perform better than those standard, weaker, SSL algorithms. We show this by learning models from labels generated using weak SSL or our ``stronger'' FRUGAL algorithm. In four domains (distinguishing security-related bug reports; mitigating bias in decision-making; predicting issue close time; and (reducing false alarms in static code warnings), FRUGAL required only 2.5% of the data to be labeled yet out-performed standard semi-supervised learners that relied on (e.g.) some domain-independent graph theory concepts. Hence, for future work, we strongly recommend the use of strong heuristics for semi-supervised learning for SE applications. To better support other researchers, our scripts and data are on-line at https://github.com/HuyTu7/FRUGAL.