 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseFocus: Learning-based One-shot Autofocus for Microscopy with Sparse Content
Feb 10, 2025



Autofocus is necessary for high-throughput and real-time scanning in microscopic imaging. Traditional methods rely on complex hardware or iterative hill-climbing algorithms. Recent learning-based approaches have demonstrated remarkable efficacy in a one-shot setting, avoiding hardware modifications or iterative mechanical lens adjustments. However, in this paper, we highlight a significant challenge that the richness of image content can significantly affect autofocus performance. When the image content is sparse, previous autofocus methods, whether traditional climbing-hill or learning-based, tend to fail. To tackle this, we propose a content-importance-based solution, named SparseFocus, featuring a novel two-stage pipeline. The first stage measures the importance of regions within the image, while the second stage calculates the defocus distance from selected important regions. To validate our approach and benefit the research community, we collect a large-scale dataset comprising millions of labelled defocused images, encompassing both dense, sparse and extremely sparse scenarios. Experimental results show that SparseFocus surpasses existing methods, effectively handling all levels of content sparsity. Moreover, we integrate SparseFocus into our Whole Slide Imaging (WSI) system that performs well in real-world applications. The code and dataset will be made available upon the publication of this paper.
RINAS: Training with Dataset Shuffling Can Be General and Fast
Dec 04, 2023Deep learning datasets are expanding at an unprecedented pace, creating new challenges for data processing in model training pipelines. A crucial aspect of these pipelines is dataset shuffling, which significantly improves unbiased learning and convergence accuracy by adhering to the principles of random sampling. However, loading shuffled data for large datasets incurs significant overhead in the deep learning pipeline and severely impacts the end-to-end training throughput. To mitigate this, current deep learning systems often resort to partial dataset shuffling, sacrificing global randomness to maintain acceptable training throughput on large datasets, still leaving global shuffling efficiency issues not fully explored. In this work, we present RINAS, a data loading framework that systematically addresses the performance bottleneck of loading global shuffled datasets. Our key contribution is to offer an intra-batch unordered data fetching approach, which unleashes unexplored parallelism of data loading. We implement RINAS under the PyTorch framework for common dataset libraries HuggingFace and TorchVision. Our experimental results show that RINAS improves the throughput of general language model training and vision model training by up to 59% and 89%, respectively.
Adaptive Gating in Mixture-of-Experts based Language Models
Oct 11, 2023



Large language models, such as OpenAI's ChatGPT, have demonstrated exceptional language understanding capabilities in various NLP tasks. Sparsely activated mixture-of-experts (MoE) has emerged as a promising solution for scaling models while maintaining a constant number of computational operations. Existing MoE model adopts a fixed gating network where each token is computed by the same number of experts. However, this approach contradicts our intuition that the tokens in each sequence vary in terms of their linguistic complexity and, consequently, require different computational costs. Little is discussed in prior research on the trade-off between computation per token and model performance. This paper introduces adaptive gating in MoE, a flexible training strategy that allows tokens to be processed by a variable number of experts based on expert probability distribution. The proposed framework preserves sparsity while improving training efficiency. Additionally, curriculum learning is leveraged to further reduce training time. Extensive experiments on diverse NLP tasks show that adaptive gating reduces at most 22.5% training time while maintaining inference quality. Moreover, we conduct a comprehensive analysis of the routing decisions and present our insights when adaptive gating is used.
Deconfounding Duration Bias in Watch-time Prediction for Video Recommendation
Jun 13, 2022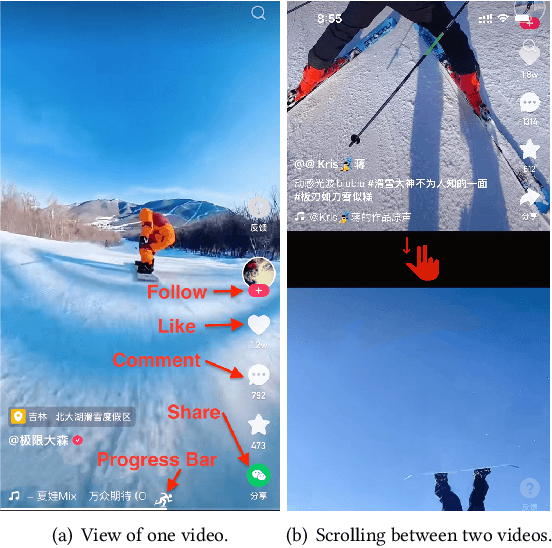

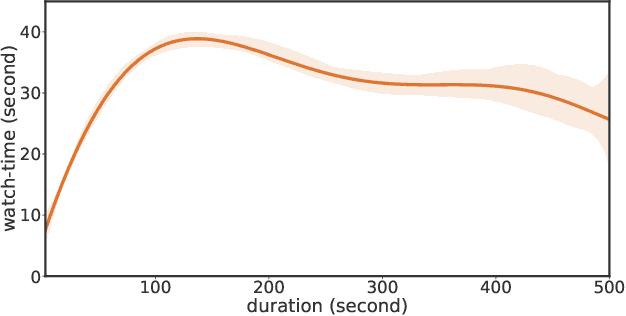
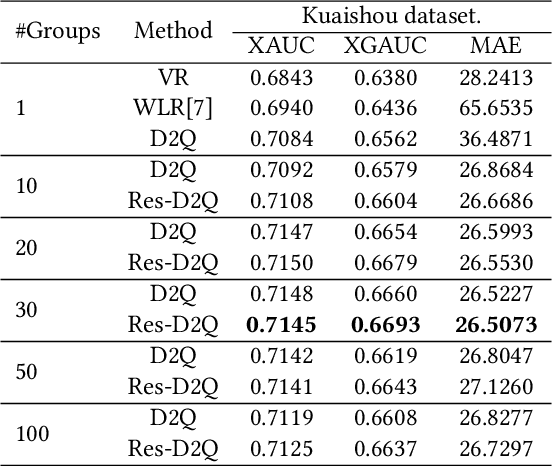
Watch-time prediction remains to be a key factor in reinforcing user engagement via video recommendations. It has become increasingly important given the ever-growing popularity of online videos. However, prediction of watch time not only depends on the match between the user and the video but is often mislead by the duration of the video itself. With the goal of improving watch time, recommendation is always biased towards videos with long duration. Models trained on this imbalanced data face the risk of bias amplification, which misguides platforms to over-recommend videos with long duration but overlook the underlying user interests. This paper presents the first work to study duration bias in watch-time prediction for video recommendation. We employ a causal graph illuminating that duration is a confounding factor that concurrently affects video exposure and watch-time prediction -- the first effect on video causes the bias issue and should be eliminated, while the second effect on watch time originates from video intrinsic characteristics and should be preserved. To remove the undesired bias but leverage the natural effect, we propose a Duration Deconfounded Quantile-based (D2Q) watch-time prediction framework, which allows for scalability to perform on industry production systems. Through extensive offline evaluation and live experiments, we showcase the effectiveness of this duration-deconfounding framework by significantly outperforming the state-of-the-art baselines. We have fully launched our approach on Kuaishou App, which has substantially improved real-time video consumption due to more accurate watch-time predictions.
PASTO: Strategic Parameter Optimization in Recommendation Systems -- Probabilistic is Better than Deterministic
Aug 20, 2021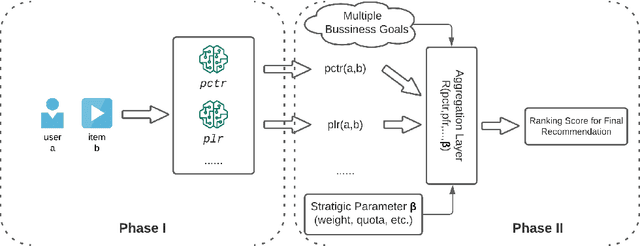
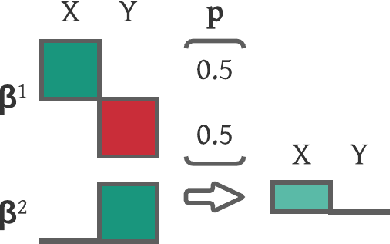

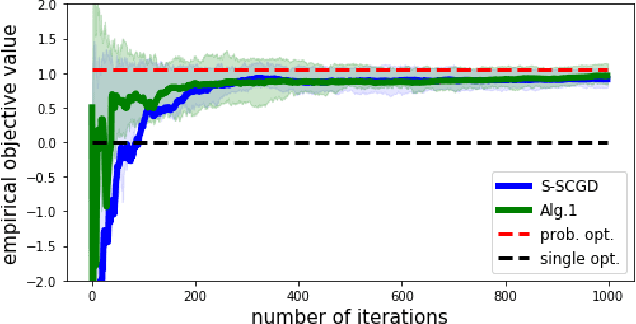
Real-world recommendation systems often consist of two phases. In the first phase, multiple predictive models produce the probability of different immediate user actions. In the second phase, these predictions are aggregated according to a set of 'strategic parameters' to meet a diverse set of business goals, such as longer user engagement, higher revenue potential, or more community/network interactions. In addition to building accurate predictive models, it is also crucial to optimize this set of 'strategic parameters' so that primary goals are optimized while secondary guardrails are not hurt. In this setting with multiple and constrained goals, this paper discovers that a probabilistic strategic parameter regime can achieve better value compared to the standard regime of finding a single deterministic parameter. The new probabilistic regime is to learn the best distribution over strategic parameter choices and sample one strategic parameter from the distribution when each user visits the platform. To pursue the optimal probabilistic solution, we formulate the problem into a stochastic compositional optimization problem, in which the unbiased stochastic gradient is unavailable. Our approach is applied in a popular social network platform with hundreds of millions of daily users and achieves +0.22% lift of user engagement in a recommendation task and +1.7% lift in revenue in an advertising optimization scenario comparing to using the best deterministic parameter strategy.