 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Miniaturised Camera-based Multi-Modal Tactile Sensor
Mar 06, 2023
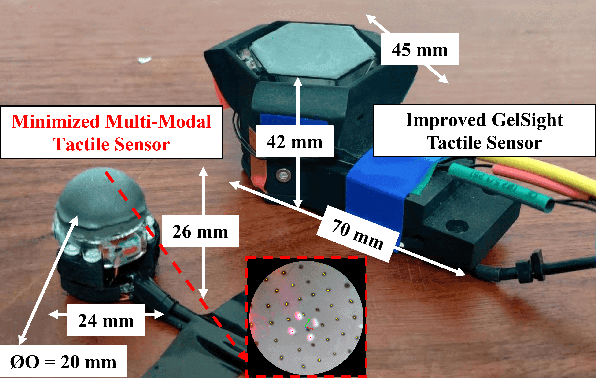
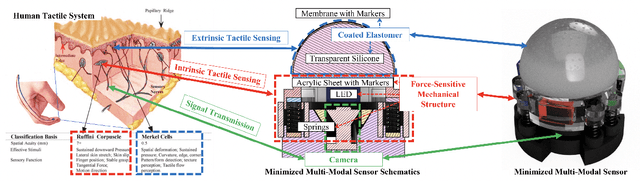
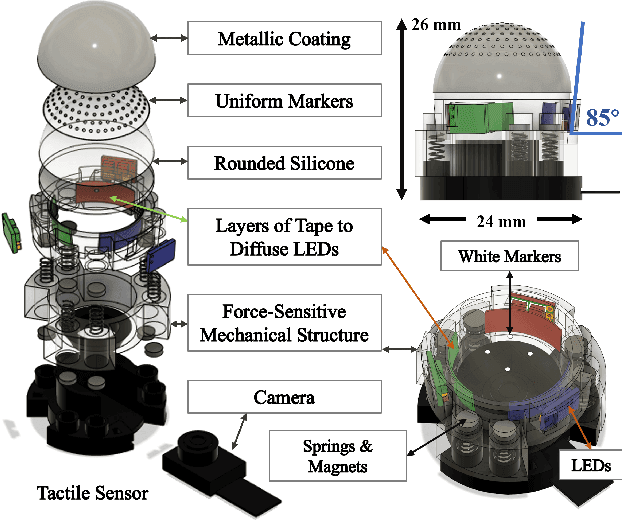
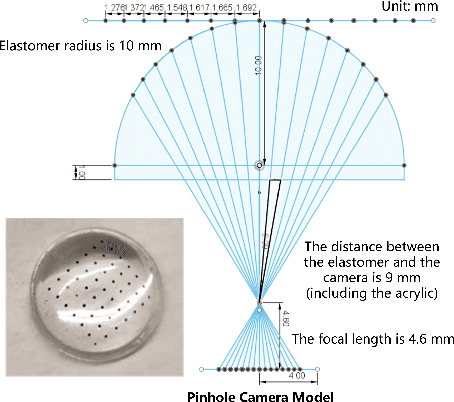
In conjunction with huge recent progress in camera and computer vision technology, camera-based sensors have increasingly shown considerable promise in relation to tactile sensing. In comparison to competing technologies (be they resistive, capacitive or magnetic based), they offer super-high-resolution, while suffering from fewer wiring problems. The human tactile system is composed of various types of mechanoreceptors, each able to perceive and process distinct information such as force, pressure, texture, etc. Camera-based tactile sensors such as GelSight mainly focus on high-resolution geometric sensing on a flat surface, and their force measurement capabilities are limited by the hysteresis and non-linearity of the silicone material. In this paper, we present a miniaturised dome-shaped camera-based tactile sensor that allows accurate force and tactile sensing in a single coherent system. The key novelty of the sensor design is as follows. First, we demonstrate how to build a smooth silicone hemispheric sensing medium with uniform markers on its curved surface. Second, we enhance the illumination of the rounded silicone with diffused LEDs. Third, we construct a force-sensitive mechanical structure in a compact form factor with usage of springs to accurately perceive forces. Our multi-modal sensor is able to acquire tactile information from multi-axis forces, local force distribution, and contact geometry, all in real-time. We apply an end-to-end deep learning method to process all the information.
HARDC : A novel ECG-based heartbeat classification method to detect arrhythmia using hierarchical attention based dual structured RNN with dilated CNN
Mar 06, 2023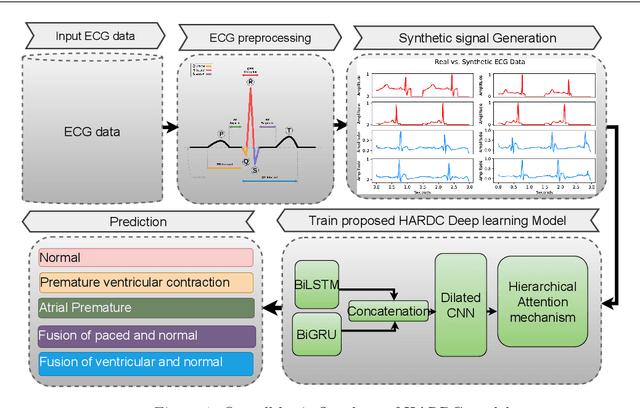
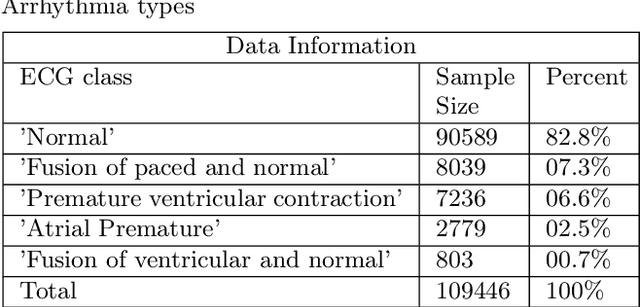
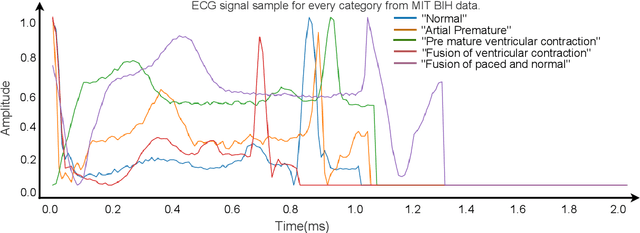
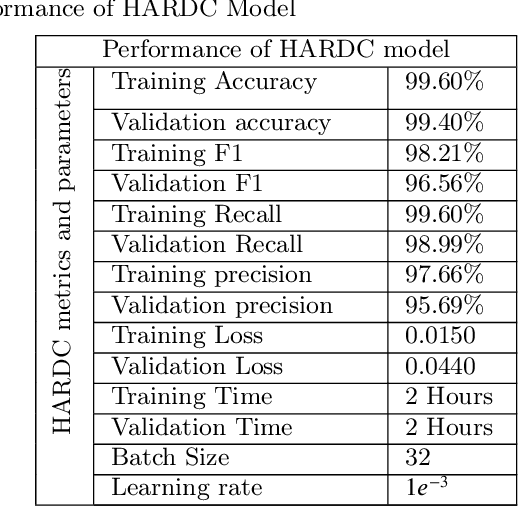
In this paper have developed a novel hybrid hierarchical attention-based bidirectional recurrent neural network with dilated CNN (HARDC) method for arrhythmia classification. This solves problems that arise when traditional dilated convolutional neural network (CNN) models disregard the correlation between contexts and gradient dispersion. The proposed HARDC fully exploits the dilated CNN and bidirectional recurrent neural network unit (BiGRU-BiLSTM) architecture to generate fusion features. As a result of incorporating both local and global feature information and an attention mechanism, the model's performance for prediction is improved.By combining the fusion features with a dilated CNN and a hierarchical attention mechanism, the trained HARDC model showed significantly improved classification results and interpretability of feature extraction on the PhysioNet 2017 challenge dataset. Sequential Z-Score normalization, filtering, denoising, and segmentation are used to prepare the raw data for analysis. CGAN (Conditional Generative Adversarial Network) is then used to generate synthetic signals from the processed data. The experimental results demonstrate that the proposed HARDC model significantly outperforms other existing models, achieving an accuracy of 99.60\%, F1 score of 98.21\%, a precision of 97.66\%, and recall of 99.60\% using MIT-BIH generated ECG. In addition, this approach substantially reduces run time when using dilated CNN compared to normal convolution. Overall, this hybrid model demonstrates an innovative and cost-effective strategy for ECG signal compression and high-performance ECG recognition. Our results indicate that an automated and highly computed method to classify multiple types of arrhythmia signals holds considerable promise.
A One-Sample Decentralized Proximal Algorithm for Non-Convex Stochastic Composite Optimization
Feb 20, 2023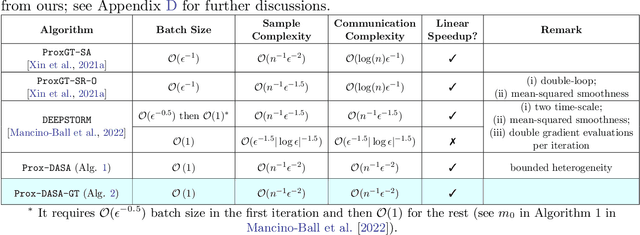
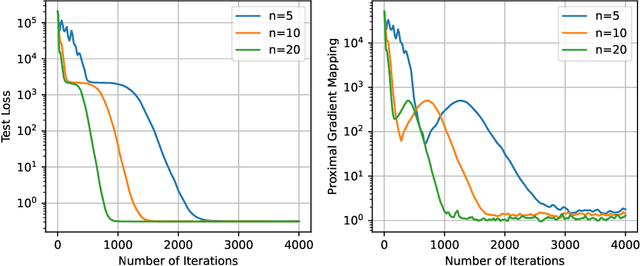
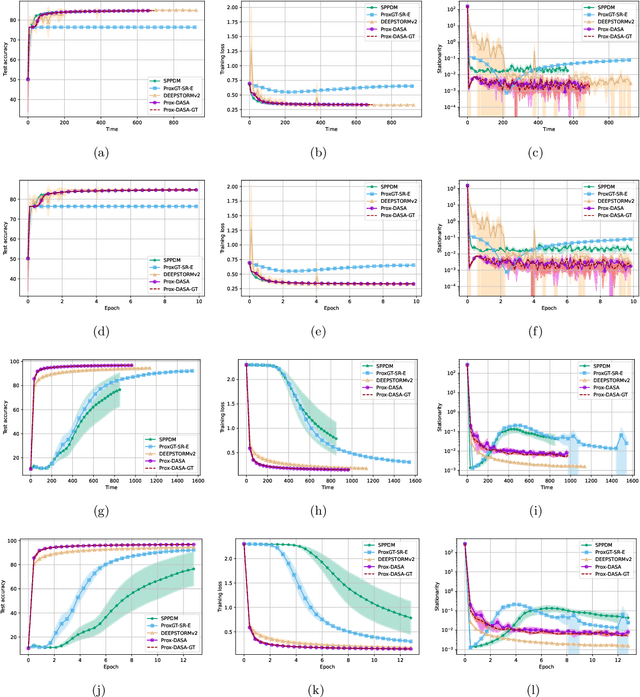
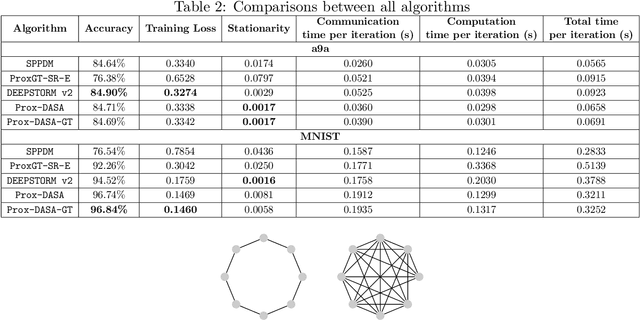
We focus on decentralized stochastic non-convex optimization, where $n$ agents work together to optimize a composite objective function which is a sum of a smooth term and a non-smooth convex term. To solve this problem, we propose two single-time scale algorithms: Prox-DASA and Prox-DASA-GT. These algorithms can find $\epsilon$-stationary points in $\mathcal{O}(n^{-1}\epsilon^{-2})$ iterations using constant batch sizes (i.e., $\mathcal{O}(1)$). Unlike prior work, our algorithms achieve a comparable complexity result without requiring large batch sizes, more complex per-iteration operations (such as double loops), or stronger assumptions. Our theoretical findings are supported by extensive numerical experiments, which demonstrate the superiority of our algorithms over previous approaches.
Deep learning at the edge enables real-time streaming ptychographic imaging
Sep 20, 2022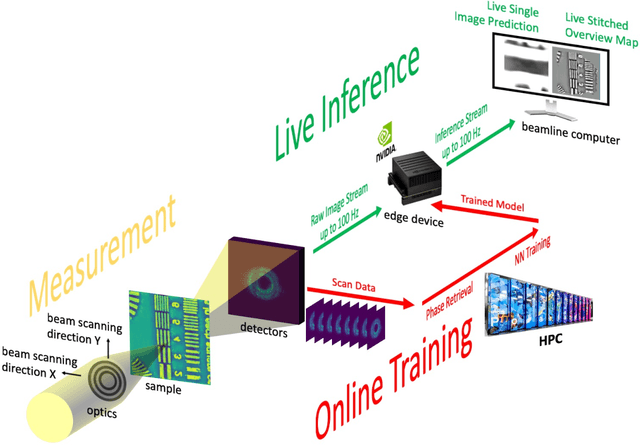
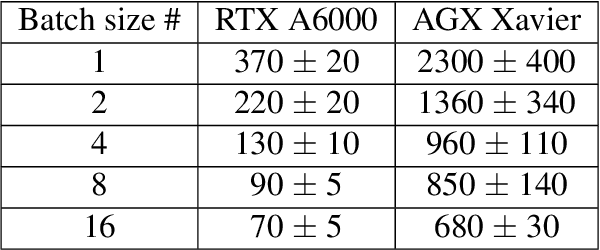
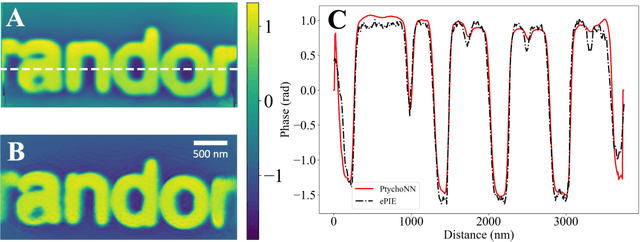

Coherent microscopy techniques provide an unparalleled multi-scale view of materials across scientific and technological fields, from structural materials to quantum devices, from integrated circuits to biological cells. Driven by the construction of brighter sources and high-rate detectors, coherent X-ray microscopy methods like ptychography are poised to revolutionize nanoscale materials characterization. However, associated significant increases in data and compute needs mean that conventional approaches no longer suffice for recovering sample images in real-time from high-speed coherent imaging experiments. Here, we demonstrate a workflow that leverages artificial intelligence at the edge and high-performance computing to enable real-time inversion on X-ray ptychography data streamed directly from a detector at up to 2 kHz. The proposed AI-enabled workflow eliminates the sampling constraints imposed by traditional ptychography, allowing low dose imaging using orders of magnitude less data than required by traditional methods.
Domain adaptation using optimal transport for invariant learning using histopathology datasets
Mar 03, 2023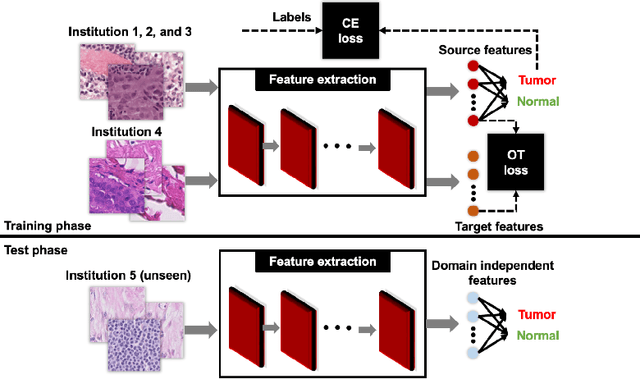


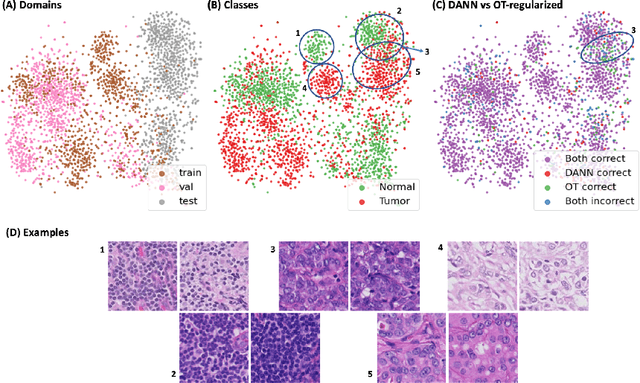
Histopathology is critical for the diagnosis of many diseases, including cancer. These protocols typically require pathologists to manually evaluate slides under a microscope, which is time-consuming and subjective, leading to interest in machine learning to automate analysis. However, computational techniques are limited by batch effects, where technical factors like differences in preparation protocol or scanners can alter the appearance of slides, causing models trained on one institution to fail when generalizing to others. Here, we propose a domain adaptation method that improves the generalization of histopathological models to data from unseen institutions, without the need for labels or retraining in these new settings. Our approach introduces an optimal transport (OT) loss, that extends adversarial methods that penalize models if images from different institutions can be distinguished in their representation space. Unlike previous methods, which operate on single samples, our loss accounts for distributional differences between batches of images. We show that on the Camelyon17 dataset, while both methods can adapt to global differences in color distribution, only our OT loss can reliably classify a cancer phenotype unseen during training. Together, our results suggest that OT improves generalization on rare but critical phenotypes that may only make up a small fraction of the total tiles and variation in a slide.
Decision Transformer under Random Frame Dropping
Mar 03, 2023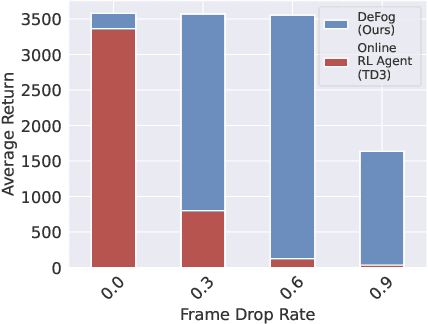
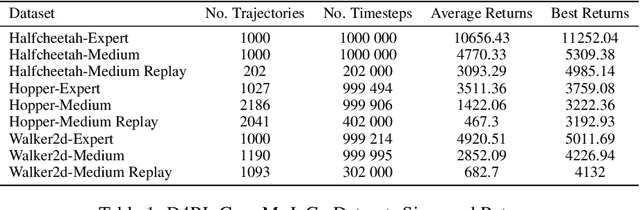
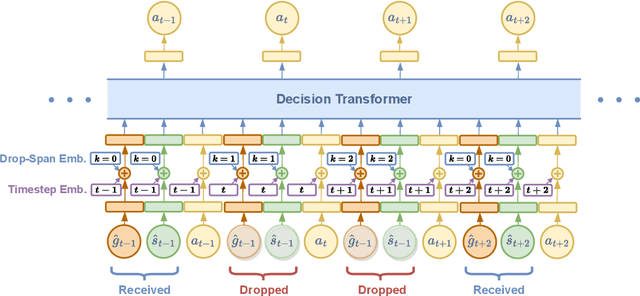
Controlling agents remotely with deep reinforcement learning~(DRL) in the real world is yet to come. One crucial stepping stone is to devise RL algorithms that are robust in the face of dropped information from corrupted communication or malfunctioning sensors. Typical RL methods usually require considerable online interaction data that are costly and unsafe to collect in the real world. Furthermore, when applying to the frame dropping scenarios, they perform unsatisfactorily even with moderate drop rates. To address these issues, we propose Decision Transformer under Random Frame Dropping~(DeFog), an offline RL algorithm that enables agents to act robustly in frame dropping scenarios without online interaction. DeFog first randomly masks out data in the offline datasets and explicitly adds the time span of frame dropping as inputs. After that, a finetuning stage on the same offline dataset with a higher mask rate would further boost the performance. Empirical results show that DeFog outperforms strong baselines under severe frame drop rates like 90\%, while maintaining similar returns under non-frame-dropping conditions in the regular MuJoCo control benchmarks and the Atari environments. Our approach offers a robust and deployable solution for controlling agents in real-world environments with limited or unreliable data.
Ultra-low Power Deep Learning-based Monocular Relative Localization Onboard Nano-quadrotors
Mar 03, 2023
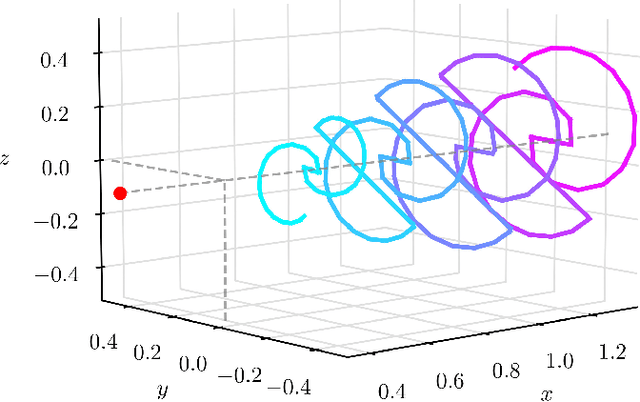

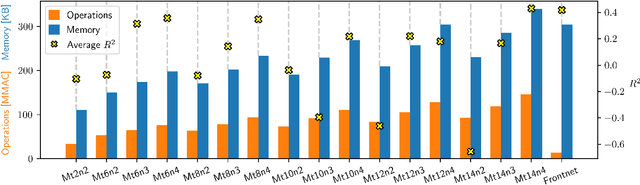
Precise relative localization is a crucial functional block for swarm robotics. This work presents a novel autonomous end-to-end system that addresses the monocular relative localization, through deep neural networks (DNNs), of two peer nano-drones, i.e., sub-40g of weight and sub-100mW processing power. To cope with the ultra-constrained nano-drone platform, we propose a vertically-integrated framework, from the dataset collection to the final in-field deployment, including dataset augmentation, quantization, and system optimizations. Experimental results show that our DNN can precisely localize a 10cm-size target nano-drone by employing only low-resolution monochrome images, up to ~2m distance. On a disjoint testing dataset our model yields a mean R2 score of 0.42 and a root mean square error of 18cm, which results in a mean in-field prediction error of 15cm and in a closed-loop control error of 17cm, over a ~60s-flight test. Ultimately, the proposed system improves the State-of-the-Art by showing long-endurance tracking performance (up to 2min continuous tracking), generalization capabilities being deployed in a never-seen-before environment, and requiring a minimal power consumption of 95mW for an onboard real-time inference-rate of 48Hz.
On Sampling with Approximate Transport Maps
Feb 09, 2023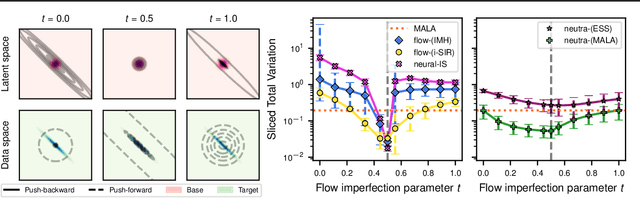
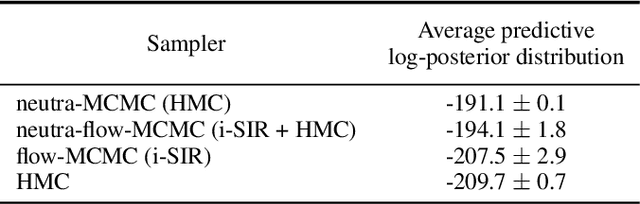
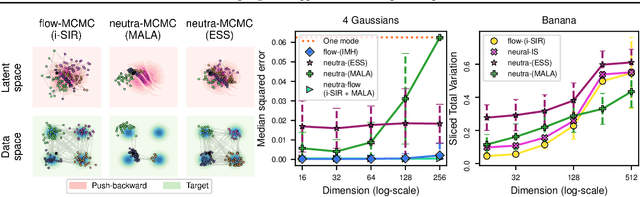
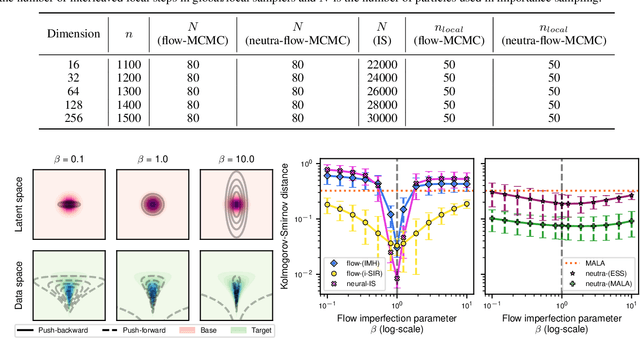
Transport maps can ease the sampling of distributions with non-trivial geometries by transforming them into distributions that are easier to handle. The potential of this approach has risen with the development of Normalizing Flows (NF) which are maps parameterized with deep neural networks trained to push a reference distribution towards a target. NF-enhanced samplers recently proposed blend (Markov chain) Monte Carlo methods with either (i) proposal draws from the flow or (ii) a flow-based reparametrization. In both cases, the quality of the learned transport conditions performance. The present work clarifies for the first time the relative strengths and weaknesses of these two approaches. Our study concludes that multimodal targets can reliability be handled with flow-based proposals up to moderately high dimensions. In contrast, methods relying on reparametrization struggle with multimodality but are more robust otherwise in high-dimensional settings and under poor training. To further illustrate the influence of target-proposal adequacy, we also derive a new quantitative bound for the mixing time of the Independent Metropolis-Hastings sampler.
Is This Loss Informative? Speeding Up Textual Inversion with Deterministic Objective Evaluation
Feb 09, 2023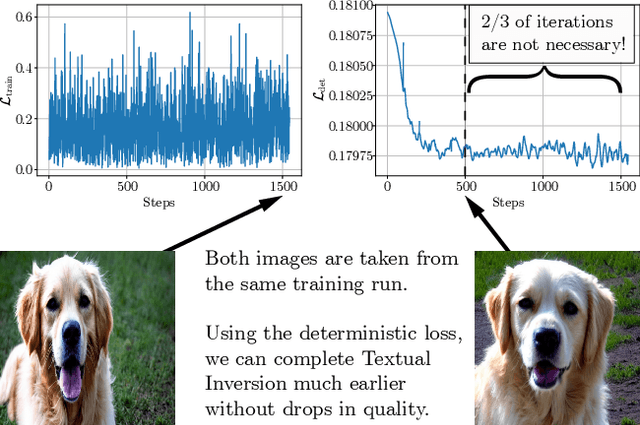
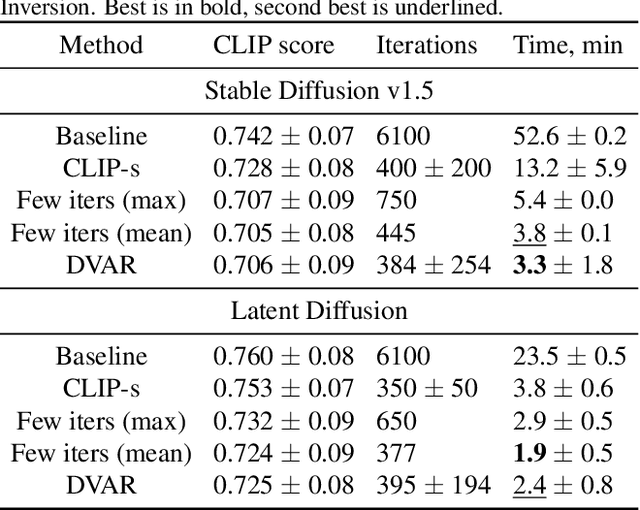
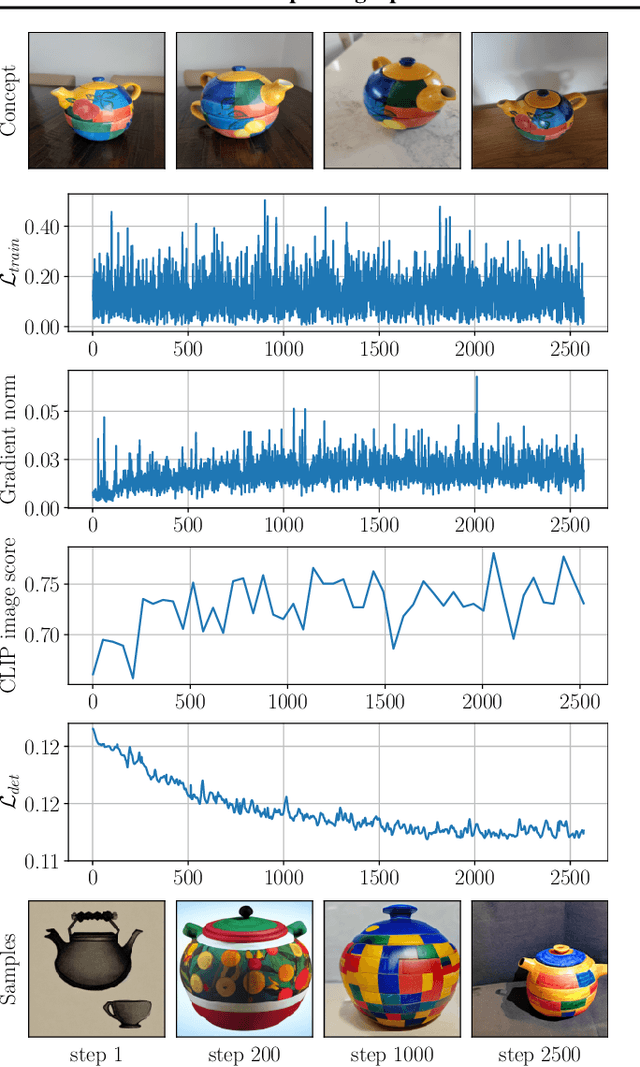
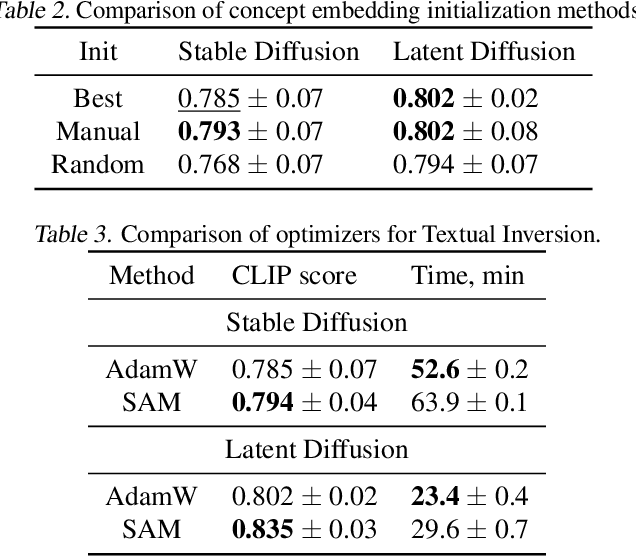
Text-to-image generation models represent the next step of evolution in image synthesis, offering natural means of flexible yet fine-grained control over the result. One emerging area of research is the rapid adaptation of large text-to-image models to smaller datasets or new visual concepts. However, the most efficient method of adaptation, called textual inversion, has a known limitation of long training time, which both restricts practical applications and increases the experiment time for research. In this work, we study the training dynamics of textual inversion, aiming to speed it up. We observe that most concepts are learned at early stages and do not improve in quality later, but standard model convergence metrics fail to indicate that. Instead, we propose a simple early stopping criterion that only requires computing the textual inversion loss on the same inputs for all training iterations. Our experiments on both Latent Diffusion and Stable Diffusion models for 93 concepts demonstrate the competitive performance of our method, speeding adaptation up to 15 times with no significant drops in quality.
Unsupervised Model Selection for Time-series Anomaly Detection
Oct 03, 2022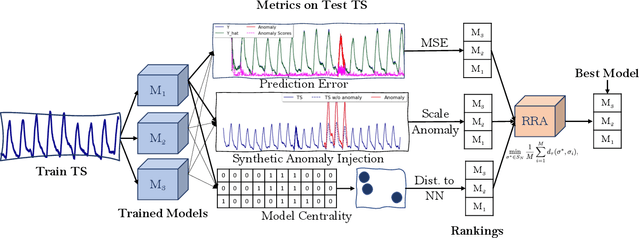
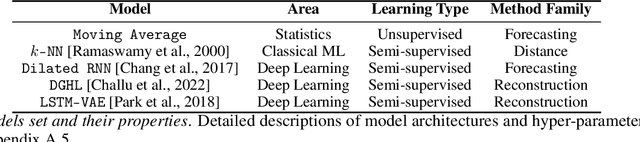
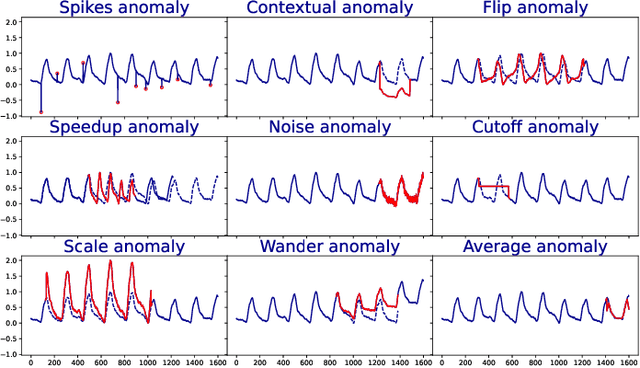
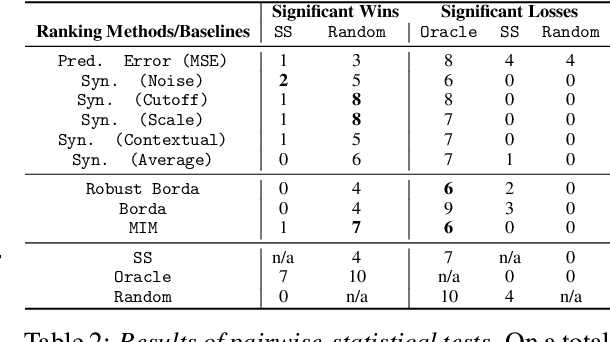
Anomaly detection in time-series has a wide range of practical applications. While numerous anomaly detection methods have been proposed in the literature, a recent survey concluded that no single method is the most accurate across various datasets. To make matters worse, anomaly labels are scarce and rarely available in practice. The practical problem of selecting the most accurate model for a given dataset without labels has received little attention in the literature. This paper answers this question i.e. Given an unlabeled dataset and a set of candidate anomaly detectors, how can we select the most accurate model? To this end, we identify three classes of surrogate (unsupervised) metrics, namely, prediction error, model centrality, and performance on injected synthetic anomalies, and show that some metrics are highly correlated with standard supervised anomaly detection performance metrics such as the $F_1$ score, but to varying degrees. We formulate metric combination with multiple imperfect surrogate metrics as a robust rank aggregation problem. We then provide theoretical justification behind the proposed approach. Large-scale experiments on multiple real-world datasets demonstrate that our proposed unsupervised approach is as effective as selecting the most accurate model based on partially labeled data.