 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting ptychography probe positions using single-shot phase retrieval neural network
May 31, 2024Ptychography is a powerful imaging technique that is used in a variety of fields, including materials science, biology, and nanotechnology. However, the accuracy of the reconstructed ptychography image is highly dependent on the accuracy of the recorded probe positions which often contain errors. These errors are typically corrected jointly with phase retrieval through numerical optimization approaches. When the error accumulates along the scan path or when the error magnitude is large, these approaches may not converge with satisfactory result. We propose a fundamentally new approach for ptychography probe position prediction for data with large position errors, where a neural network is used to make single-shot phase retrieval on individual diffraction patterns, yielding the object image at each scan point. The pairwise offsets among these images are then found using a robust image registration method, and the results are combined to yield the complete scan path by constructing and solving a linear equation. We show that our method can achieve good position prediction accuracy for data with large and accumulating errors on the order of $10^2$ pixels, a magnitude that often makes optimization-based algorithms fail to converge. For ptychography instruments without sophisticated position control equipment such as interferometers, our method is of significant practical potential.
AI-assisted Automated Workflow for Real-time X-ray Ptychography Data Analysis via Federated Resources
Apr 09, 2023
We present an end-to-end automated workflow that uses large-scale remote compute resources and an embedded GPU platform at the edge to enable AI/ML-accelerated real-time analysis of data collected for x-ray ptychography. Ptychography is a lensless method that is being used to image samples through a simultaneous numerical inversion of a large number of diffraction patterns from adjacent overlapping scan positions. This acquisition method can enable nanoscale imaging with x-rays and electrons, but this often requires very large experimental datasets and commensurately high turnaround times, which can limit experimental capabilities such as real-time experimental steering and low-latency monitoring. In this work, we introduce a software system that can automate ptychography data analysis tasks. We accelerate the data analysis pipeline by using a modified version of PtychoNN -- an ML-based approach to solve phase retrieval problem that shows two orders of magnitude speedup compared to traditional iterative methods. Further, our system coordinates and overlaps different data analysis tasks to minimize synchronization overhead between different stages of the workflow. We evaluate our workflow system with real-world experimental workloads from the 26ID beamline at Advanced Photon Source and ThetaGPU cluster at Argonne Leadership Computing Resources.
Deep learning at the edge enables real-time streaming ptychographic imaging
Sep 20, 2022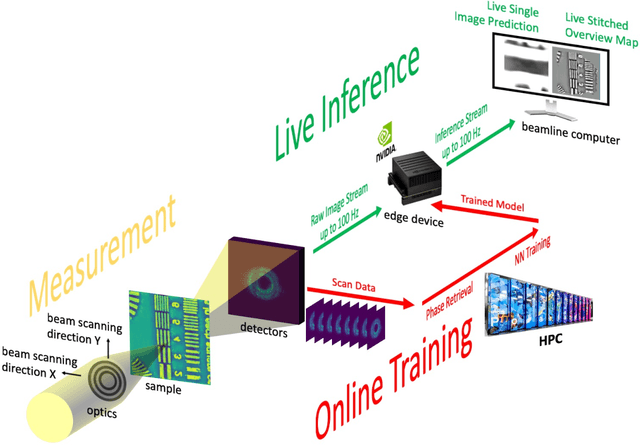
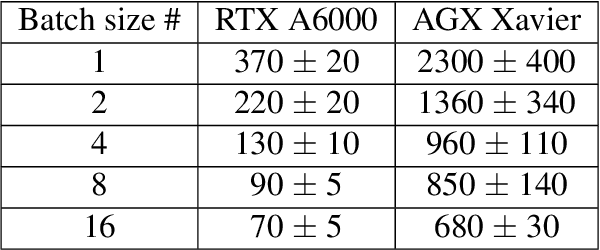
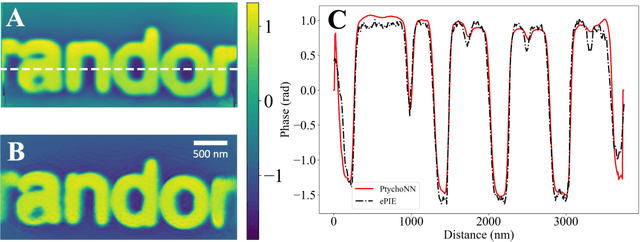

Coherent microscopy techniques provide an unparalleled multi-scale view of materials across scientific and technological fields, from structural materials to quantum devices, from integrated circuits to biological cells. Driven by the construction of brighter sources and high-rate detectors, coherent X-ray microscopy methods like ptychography are poised to revolutionize nanoscale materials characterization. However, associated significant increases in data and compute needs mean that conventional approaches no longer suffice for recovering sample images in real-time from high-speed coherent imaging experiments. Here, we demonstrate a workflow that leverages artificial intelligence at the edge and high-performance computing to enable real-time inversion on X-ray ptychography data streamed directly from a detector at up to 2 kHz. The proposed AI-enabled workflow eliminates the sampling constraints imposed by traditional ptychography, allowing low dose imaging using orders of magnitude less data than required by traditional methods.
Scalable and accurate multi-GPU based image reconstruction of large-scale ptychography data
Jun 14, 2021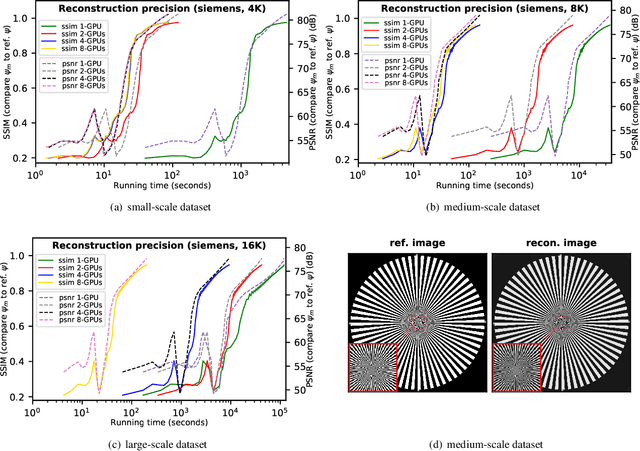
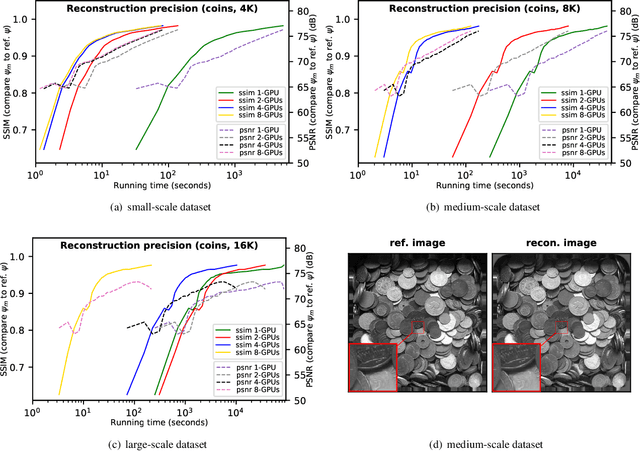
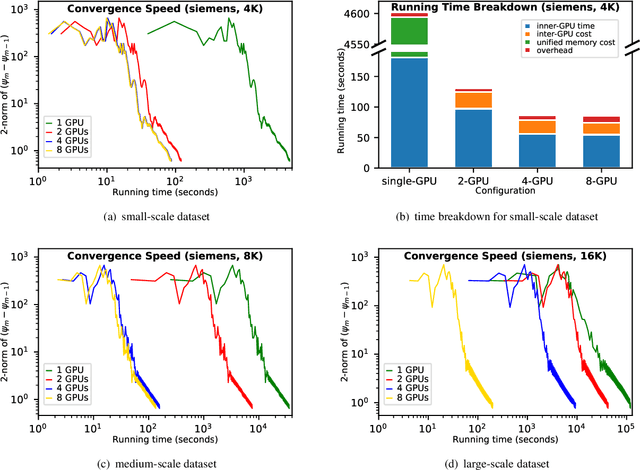
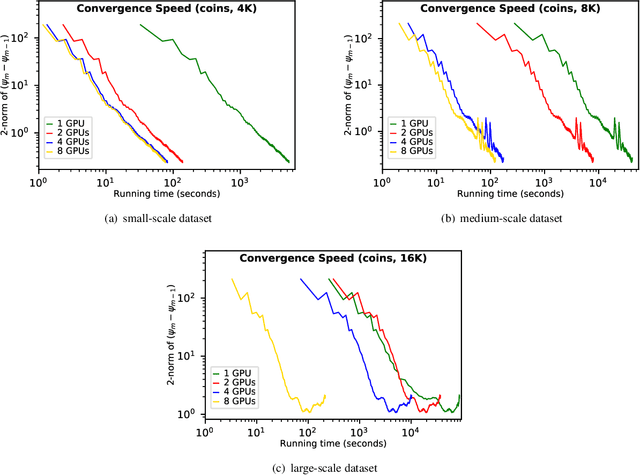
While the advances in synchrotron light sources, together with the development of focusing optics and detectors, allow nanoscale ptychographic imaging of materials and biological specimens, the corresponding experiments can yield terabyte-scale large volumes of data that can impose a heavy burden on the computing platform. While Graphical Processing Units (GPUs) provide high performance for such large-scale ptychography datasets, a single GPU is typically insufficient for analysis and reconstruction. Several existing works have considered leveraging multiple GPUs to accelerate the ptychographic reconstruction. However, they utilize only Message Passing Interface (MPI) to handle the communications between GPUs. It poses inefficiency for the configuration that has multiple GPUs in a single node, especially while processing a single large projection, since it provides no optimizations to handle the heterogeneous GPU interconnections containing both low-speed links, e.g., PCIe, and high-speed links, e.g., NVLink. In this paper, we provide a multi-GPU implementation that can effectively solve large-scale ptychographic reconstruction problem with optimized performance on intra-node multi-GPU. We focus on the conventional maximum-likelihood reconstruction problem using conjugate-gradient (CG) for the solution and propose a novel hybrid parallelization model to address the performance bottlenecks in CG solver. Accordingly, we develop a tool called PtyGer (Ptychographic GPU(multiple)-based reconstruction), implementing our hybrid parallelization model design. The comprehensive evaluation verifies that PtyGer can fully preserve the original algorithm's accuracy while achieving outstanding intra-node GPU scalability.