 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Flow Matching: Dimension-Improved KL Bounds and Wasserstein Guarantees
Jun 15, 2026Diffusion Flow Matching (DFM) has recently emerged as a versatile framework for generative modeling, yet its theoretical convergence properties remain only partially understood. In this work, we provide refined and novel convergence guarantees for Brownian motion based DFMs, focusing on the discretization error. Our analysis is conducted under the Kullback-Leibler (KL) divergence and the 2-Wasserstein distance. Under finite-moment conditions and a mild score integrability assumption, we derive KL convergence bounds with improved dimensional dependence compared to prior work, achieving, up to our knowledge, state-of-the-art scaling under minimal conditions. We further extend the analysis to the 2-Wasserstein distance: under an additional first-order score integrability assumption and a weak log-concavity condition, we obtain convergence guarantees with dimensional dependence consistent with the KL case.
Uniform Diffusion Models Revisited: Leave-One-Out Denoiser and Absorbing State Reformulation
May 21, 2026Discrete diffusion models are often trained through clean-data prediction, but the prediction can be used in different ways to define the reverse dynamics. In Masked Diffusion Models (MDM) these choices largely coincide, whereas in Uniform Diffusion Models (UDM) they do not. We show that the standard plug-in bridge parameterization for UDM is not optimized by the denoising posterior, but by a leave-one-out posterior that predicts each clean token without using its own noisy observation. This identifies a mismatch between the plug-in ELBO and the usual cross-entropy denoising objective. We characterize the leave-one-out target and derive exact conversions between the denoiser, the leave-one-out posterior, and the score. These conversions allow us to disentangle parameterization and training objective. Our results also lead to inference improvements without any additional training through an informed predictor-corrector sampler and improved temperature sampling based on the leave-one-out predictor. We further introduce an absorbing-state reformulation of uniform diffusion that preserves the UDM joint law while decomposing it into masked-diffusion-like sampling operations, with simpler denoising posteriors, carry-over unmasking, and a natural remasking mechanism. On language modeling, leave-one-out parameterizations consistently improve UDM generation, while the absorbing construction matches or surpasses masked diffusion. These results suggest that the empirical gap between masked and uniform diffusion is driven less by the choice of marginals themselves than by parameterization and sampling design. The code and models can be found at https://github.com/samsongourevitch/rev_udm.
Entropic Mirror Monte Carlo
Feb 03, 2026Importance sampling is a Monte Carlo method which designs estimators of expectations under a target distribution using weighted samples from a proposal distribution. When the target distribution is complex, such as multimodal distributions in highdimensional spaces, the efficiency of importance sampling critically depends on the choice of the proposal distribution. In this paper, we propose a novel adaptive scheme for the construction of efficient proposal distributions. Our algorithm promotes efficient exploration of the target distribution by combining global sampling mechanisms with a delayed weighting procedure. The proposed weighting mechanism plays a key role by enabling rapid resampling in regions where the proposal distribution is poorly adapted to the target. Our sampling algorithm is shown to be geometrically convergent under mild assumptions and is illustrated through various numerical experiments.
Sampling from multi-modal distributions on Riemannian manifolds with training-free stochastic interpolants
Jan 31, 2026In this paper, we propose a general methodology for sampling from un-normalized densities defined on Riemannian manifolds, with a particular focus on multi-modal targets that remain challenging for existing sampling methods. Inspired by the framework of diffusion models developed for generative modeling, we introduce a sampling algorithm based on the simulation of a non-equilibrium deterministic dynamics that transports an easy-to-sample noise distribution toward the target. At the marginal level, the induced density path follows a prescribed stochastic interpolant between the noise and target distributions, specifically constructed to respect the underlying Riemannian geometry. In contrast to related generative modeling approaches that rely on machine learning, our method is entirely training-free. It instead builds on iterative posterior sampling procedures using only standard Monte Carlo techniques, thereby extending recent diffusion-based sampling methodologies beyond the Euclidean setting. We complement our approach with a rigorous theoretical analysis and demonstrate its effectiveness on a range of multi-modal sampling problems, including high-dimensional and heavy-tailed examples.
Categorical Reparameterization with Denoising Diffusion models
Jan 02, 2026Gradient-based optimization with categorical variables typically relies on score-function estimators, which are unbiased but noisy, or on continuous relaxations that replace the discrete distribution with a smooth surrogate admitting a pathwise (reparameterized) gradient, at the cost of optimizing a biased, temperature-dependent objective. In this paper, we extend this family of relaxations by introducing a diffusion-based soft reparameterization for categorical distributions. For these distributions, the denoiser under a Gaussian noising process admits a closed form and can be computed efficiently, yielding a training-free diffusion sampler through which we can backpropagate. Our experiments show that the proposed reparameterization trick yields competitive or improved optimization performance on various benchmarks.
Briding Diffusion Posterior Sampling and Monte Carlo methods: a survey
Oct 15, 2025
Diffusion models enable the synthesis of highly accurate samples from complex distributions and have become foundational in generative modeling. Recently, they have demonstrated significant potential for solving Bayesian inverse problems by serving as priors. This review offers a comprehensive overview of current methods that leverage \emph{pre-trained} diffusion models alongside Monte Carlo methods to address Bayesian inverse problems without requiring additional training. We show that these methods primarily employ a \emph{twisting} mechanism for the intermediate distributions within the diffusion process, guiding the simulations toward the posterior distribution. We describe how various Monte Carlo methods are then used to aid in sampling from these twisted distributions.
Non-Asymptotic Analysis of Data Augmentation for Precision Matrix Estimation
Oct 02, 2025This paper addresses the problem of inverse covariance (also known as precision matrix) estimation in high-dimensional settings. Specifically, we focus on two classes of estimators: linear shrinkage estimators with a target proportional to the identity matrix, and estimators derived from data augmentation (DA). Here, DA refers to the common practice of enriching a dataset with artificial samples--typically generated via a generative model or through random transformations of the original data--prior to model fitting. For both classes of estimators, we derive estimators and provide concentration bounds for their quadratic error. This allows for both method comparison and hyperparameter tuning, such as selecting the optimal proportion of artificial samples. On the technical side, our analysis relies on tools from random matrix theory. We introduce a novel deterministic equivalent for generalized resolvent matrices, accommodating dependent samples with specific structure. We support our theoretical results with numerical experiments.
On the Rate of Gaussian Approximation for Linear Regression Problems
Sep 17, 2025In this paper, we consider the problem of Gaussian approximation for the online linear regression task. We derive the corresponding rates for the setting of a constant learning rate and study the explicit dependence of the convergence rate upon the problem dimension $d$ and quantities related to the design matrix. When the number of iterations $n$ is known in advance, our results yield the rate of normal approximation of order $\sqrt{\log{n}/n}$, provided that the sample size $n$ is large enough.
Algorithm- and Data-Dependent Generalization Bounds for Score-Based Generative Models
Jun 04, 2025

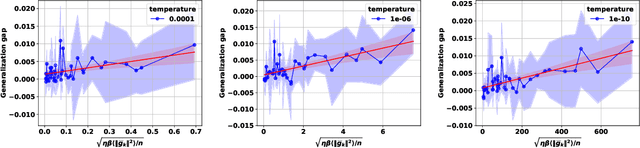

Score-based generative models (SGMs) have emerged as one of the most popular classes of generative models. A substantial body of work now exists on the analysis of SGMs, focusing either on discretization aspects or on their statistical performance. In the latter case, bounds have been derived, under various metrics, between the true data distribution and the distribution induced by the SGM, often demonstrating polynomial convergence rates with respect to the number of training samples. However, these approaches adopt a largely approximation theory viewpoint, which tends to be overly pessimistic and relatively coarse. In particular, they fail to fully explain the empirical success of SGMs or capture the role of the optimization algorithm used in practice to train the score network. To support this observation, we first present simple experiments illustrating the concrete impact of optimization hyperparameters on the generalization ability of the generated distribution. Then, this paper aims to bridge this theoretical gap by providing the first algorithmic- and data-dependent generalization analysis for SGMs. In particular, we establish bounds that explicitly account for the optimization dynamics of the learning algorithm, offering new insights into the generalization behavior of SGMs. Our theoretical findings are supported by empirical results on several datasets.
Conditional Diffusion Models with Classifier-Free Gibbs-like Guidance
May 27, 2025Classifier-Free Guidance (CFG) is a widely used technique for improving conditional diffusion models by linearly combining the outputs of conditional and unconditional denoisers. While CFG enhances visual quality and improves alignment with prompts, it often reduces sample diversity, leading to a challenging trade-off between quality and diversity. To address this issue, we make two key contributions. First, CFG generally does not correspond to a well-defined denoising diffusion model (DDM). In particular, contrary to common intuition, CFG does not yield samples from the target distribution associated with the limiting CFG score as the noise level approaches zero -- where the data distribution is tilted by a power $w \gt 1$ of the conditional distribution. We identify the missing component: a R\'enyi divergence term that acts as a repulsive force and is required to correct CFG and render it consistent with a proper DDM. Our analysis shows that this correction term vanishes in the low-noise limit. Second, motivated by this insight, we propose a Gibbs-like sampling procedure to draw samples from the desired tilted distribution. This method starts with an initial sample from the conditional diffusion model without CFG and iteratively refines it, preserving diversity while progressively enhancing sample quality. We evaluate our approach on both image and text-to-audio generation tasks, demonstrating substantial improvements over CFG across all considered metrics. The code is available at https://github.com/yazidjanati/cfgig