 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Exploiting 4D CT Perfusion for segmenting infarcted areas in patients with suspected acute ischemic stroke
Mar 15, 2023

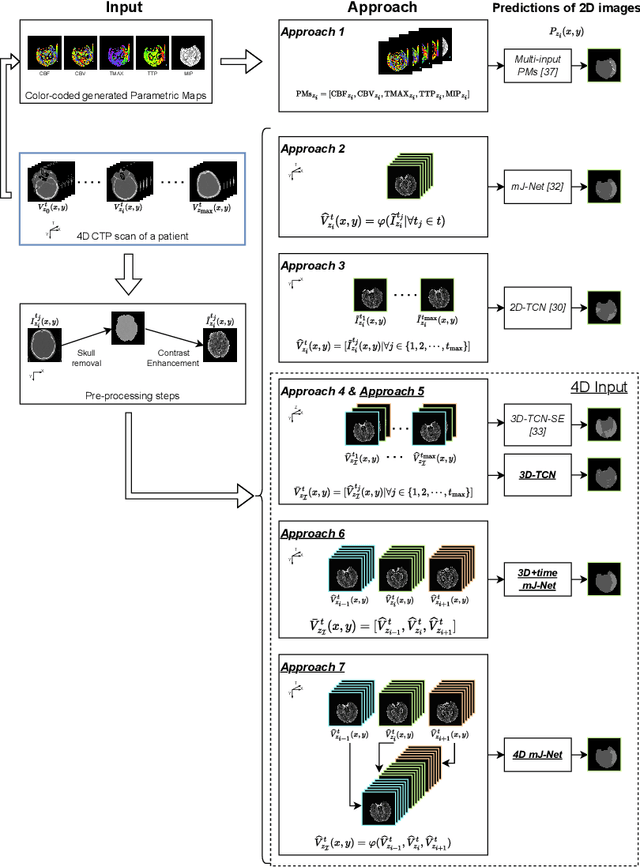

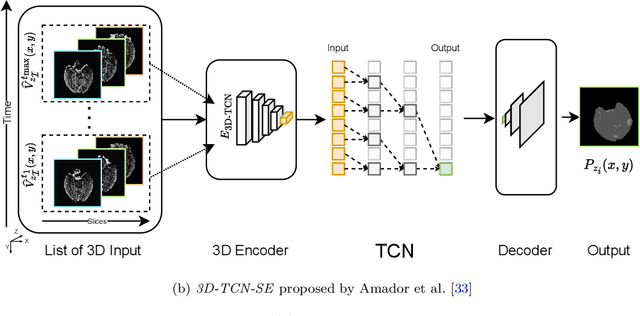
Precise and fast prediction methods for ischemic areas (core and penumbra) in acute ischemic stroke (AIS) patients are of significant clinical interest: they play an essential role in improving diagnosis and treatment planning. Computed Tomography (CT) scan is one of the primary modalities for early assessment in patients with suspected AIS. CT Perfusion (CTP) is often used as a primary assessment to determine stroke location, severity, and volume of ischemic lesions. Current automatic segmentation methods for CTP mostly use already processed 3D color maps conventionally used for visual assessment by radiologists as input. Alternatively, the raw CTP data is used on a slice-by-slice basis as 2D+time input, where the spatial information over the volume is ignored. In this paper, we investigate different methods to utilize the entire 4D CTP as input to fully exploit the spatio-temporal information. This leads us to propose a novel 4D convolution layer. Our comprehensive experiments on a local dataset comprised of 152 patients divided into three groups show that our proposed models generate more precise results than other methods explored. A Dice Coefficient of 0.70 and 0.45 is achieved for penumbra and core areas, respectively. The code is available on https://github.com/Biomedical-Data-Analysis-Laboratory/4D-mJ-Net.git.
Manipulate by Seeing: Creating Manipulation Controllers from Pre-Trained Representations
Mar 15, 2023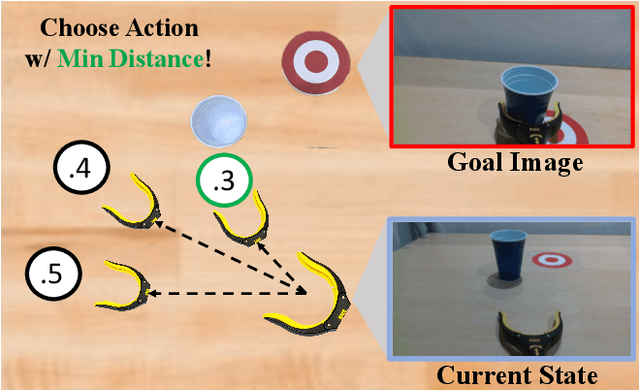
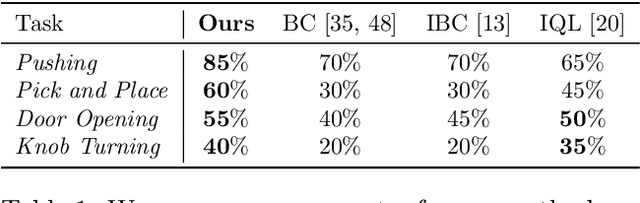
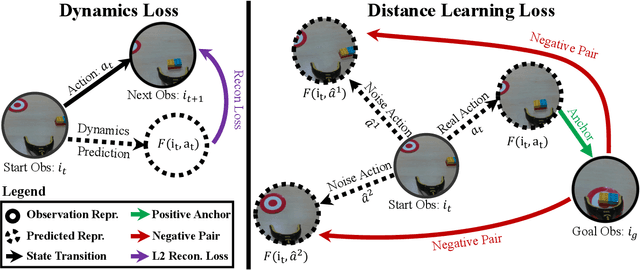
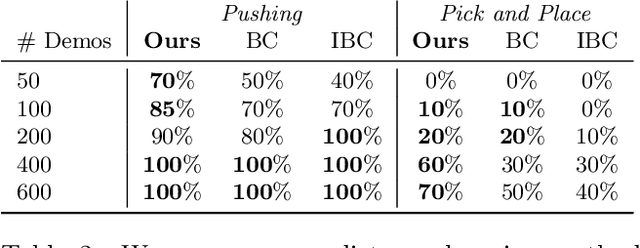
The field of visual representation learning has seen explosive growth in the past years, but its benefits in robotics have been surprisingly limited so far. Prior work uses generic visual representations as a basis to learn (task-specific) robot action policies (e.g. via behavior cloning). While the visual representations do accelerate learning, they are primarily used to encode visual observations. Thus, action information has to be derived purely from robot data, which is expensive to collect! In this work, we present a scalable alternative where the visual representations can help directly infer robot actions. We observe that vision encoders express relationships between image observations as distances (e.g. via embedding dot product) that could be used to efficiently plan robot behavior. We operationalize this insight and develop a simple algorithm for acquiring a distance function and dynamics predictor, by fine-tuning a pre-trained representation on human collected video sequences. The final method is able to substantially outperform traditional robot learning baselines (e.g. 70% success v.s. 50% for behavior cloning on pick-place) on a suite of diverse real-world manipulation tasks. It can also generalize to novel objects, without using any robot demonstrations during train time. For visualizations of the learned policies please check: https://agi-labs.github.io/manipulate-by-seeing/
VVS: Video-to-Video Retrieval with Irrelevant Frame Suppression
Mar 15, 2023
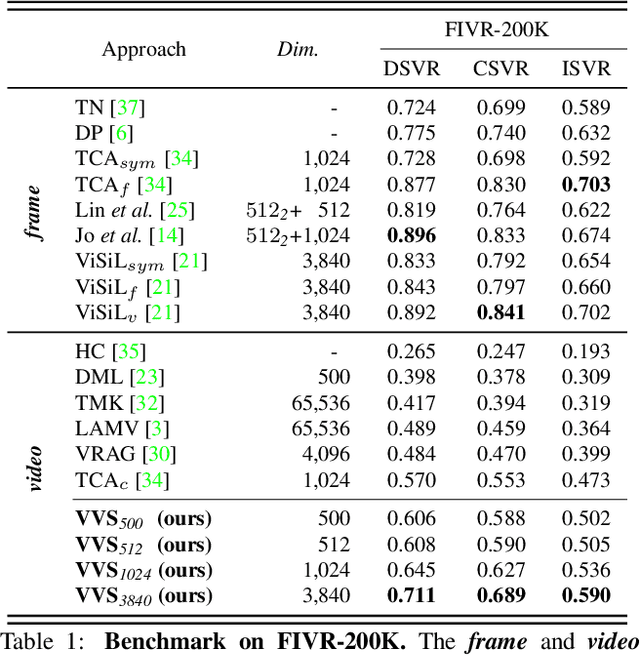
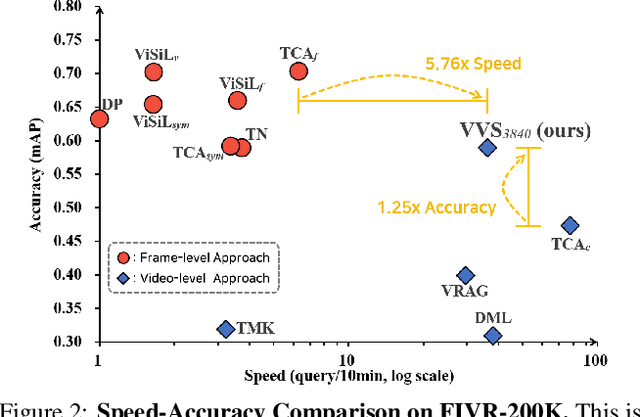
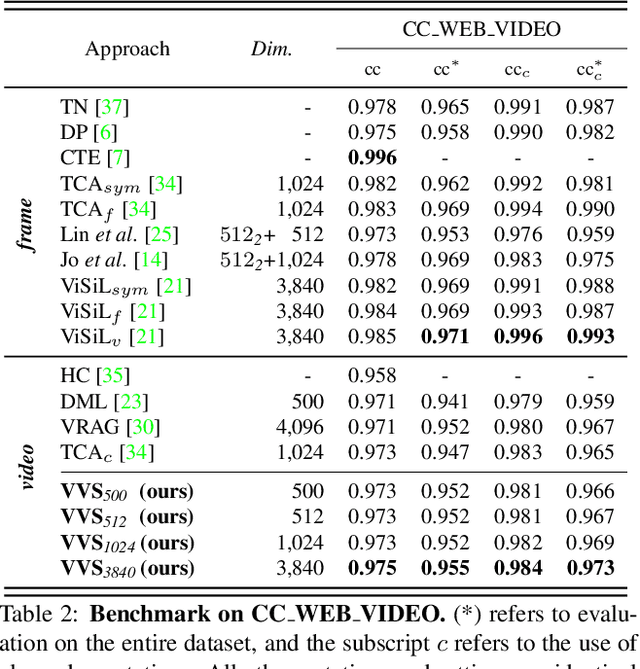
In content-based video retrieval (CBVR), dealing with large-scale collections, efficiency is as important as accuracy. For this reason, several video-level feature-based studies have actively been conducted; nevertheless, owing to the severe difficulty of embedding a lengthy and untrimmed video into a single feature, these studies have shown insufficient for accurate retrieval compared to frame-level feature-based studies. In this paper, we show an insight that appropriate suppression of irrelevant frames can be a clue to overcome the current obstacles of the video-level feature-based approaches. Furthermore, we propose a Video-to-Video Suppression network (VVS) as a solution. The VVS is an end-to-end framework that consists of an easy distractor elimination stage for identifying which frames to remove and a suppression weight generation stage for determining how much to suppress the remaining frames. This structure is intended to effectively describe an untrimmed video with varying content and meaningless information. Its efficacy is proved via extensive experiments, and we show that our approach is not only state-of-the-art in video-level feature-based approaches but also has a fast inference time despite possessing retrieval capabilities close to those of frame-level feature-based approaches.
Streaming Algorithms for Learning with Experts: Deterministic Versus Robust
Mar 03, 2023In the online learning with experts problem, an algorithm must make a prediction about an outcome on each of $T$ days (or times), given a set of $n$ experts who make predictions on each day (or time). The algorithm is given feedback on the outcomes of each day, including the cost of its prediction and the cost of the expert predictions, and the goal is to make a prediction with the minimum cost, specifically compared to the best expert in the set. Recent work by Srinivas, Woodruff, Xu, and Zhou (STOC 2022) introduced the study of the online learning with experts problem under memory constraints. However, often the predictions made by experts or algorithms at some time influence future outcomes, so that the input is adaptively chosen. Whereas deterministic algorithms would be robust to adaptive inputs, existing algorithms all crucially use randomization to sample a small number of experts. In this paper, we study deterministic and robust algorithms for the experts problem. We first show a space lower bound of $\widetilde{\Omega}\left(\frac{nM}{RT}\right)$ for any deterministic algorithm that achieves regret $R$ when the best expert makes $M$ mistakes. Our result shows that the natural deterministic algorithm, which iterates through pools of experts until each expert in the pool has erred, is optimal up to polylogarithmic factors. On the positive side, we give a randomized algorithm that is robust to adaptive inputs that uses $\widetilde{O}\left(\frac{n}{R\sqrt{T}}\right)$ space for $M=O\left(\frac{R^2 T}{\log^2 n}\right)$, thereby showing a smooth space-regret trade-off.
AutoMatch: A Large-scale Audio Beat Matching Benchmark for Boosting Deep Learning Assistant Video Editing
Mar 03, 2023
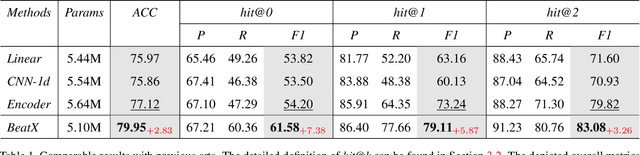
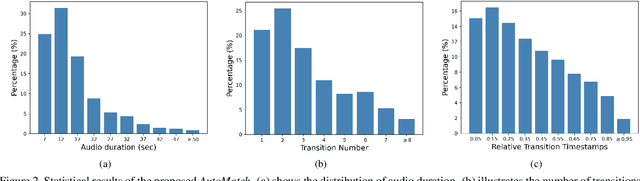
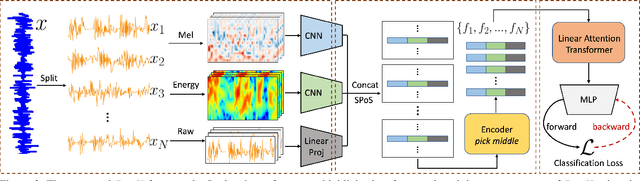
The explosion of short videos has dramatically reshaped the manners people socialize, yielding a new trend for daily sharing and access to the latest information. These rich video resources, on the one hand, benefited from the popularization of portable devices with cameras, but on the other, they can not be independent of the valuable editing work contributed by numerous video creators. In this paper, we investigate a novel and practical problem, namely audio beat matching (ABM), which aims to recommend the proper transition time stamps based on the background music. This technique helps to ease the labor-intensive work during video editing, saving energy for creators so that they can focus more on the creativity of video content. We formally define the ABM problem and its evaluation protocol. Meanwhile, a large-scale audio dataset, i.e., the AutoMatch with over 87k finely annotated background music, is presented to facilitate this newly opened research direction. To further lay solid foundations for the following study, we also propose a novel model termed BeatX to tackle this challenging task. Alongside, we creatively present the concept of label scope, which eliminates the data imbalance issues and assigns adaptive weights for the ground truth during the training procedure in one stop. Though plentiful short video platforms have flourished for a long time, the relevant research concerning this scenario is not sufficient, and to the best of our knowledge, AutoMatch is the first large-scale dataset to tackle the audio beat matching problem. We hope the released dataset and our competitive baseline can encourage more attention to this line of research. The dataset and codes will be made publicly available.
A Policy Gradient Framework for Stochastic Optimal Control Problems with Global Convergence Guarantee
Feb 11, 2023In this work, we consider the stochastic optimal control problem in continuous time and a policy gradient method to solve it. In particular, we study the gradient flow for the control, viewed as a continuous time limit of the policy gradient. We prove the global convergence of the gradient flow and establish a convergence rate under some regularity assumptions. The main novelty in the analysis is the notion of local optimal control function, which is introduced to compare the local optimality of the iterate.
Deep Model Predictive Control
Feb 27, 2023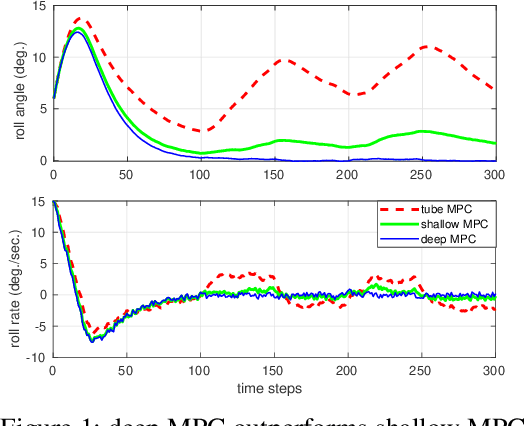
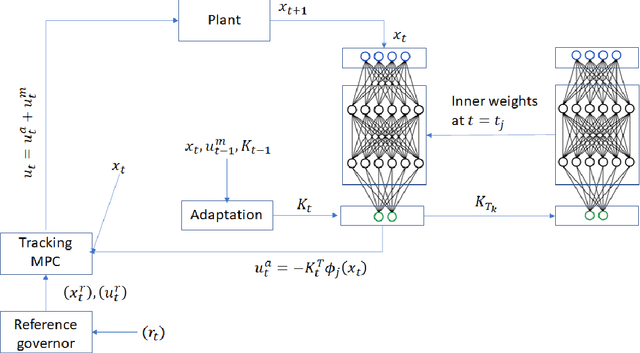
This paper presents a deep learning based model predictive control algorithm for control affine nonlinear discrete time systems with matched and bounded state-dependent uncertainties of unknown structure. Since the structure of uncertainties is not known, a deep neural network (DNN) is employed to approximate the disturbances. In order to avoid any unwanted behavior during the learning phase, a tube based model predictive controller is employed, which ensures satisfaction of constraints and input-to-state stability of the closed-loop states.
* arXiv admin note: text overlap with arXiv:2104.07171
Time-efficient, High Resolution 3T Whole Brain Quantitative Relaxometry using 3D-QALAS with Wave-CAIPI Readouts
Nov 08, 2022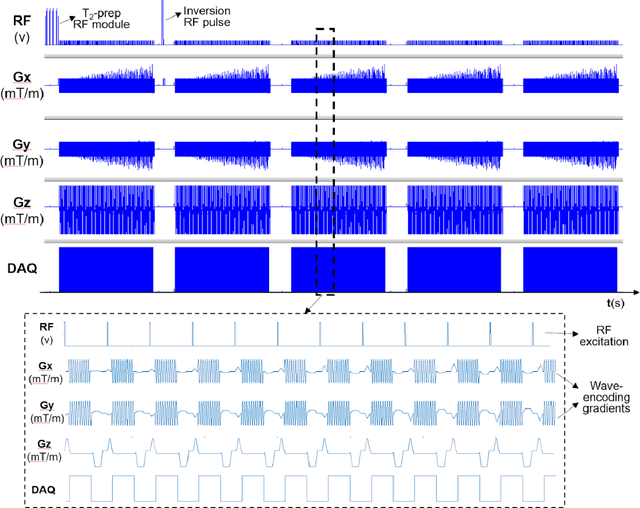
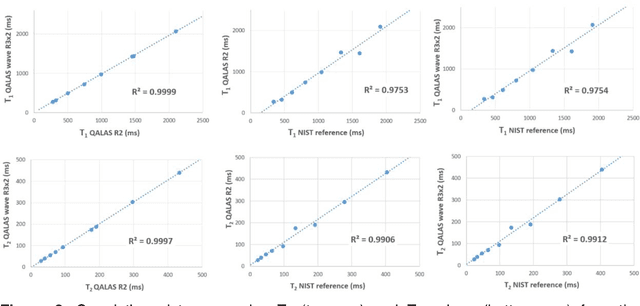
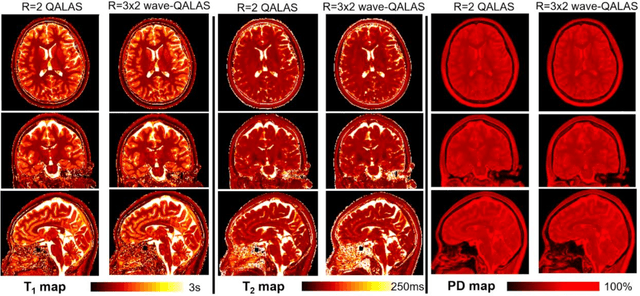
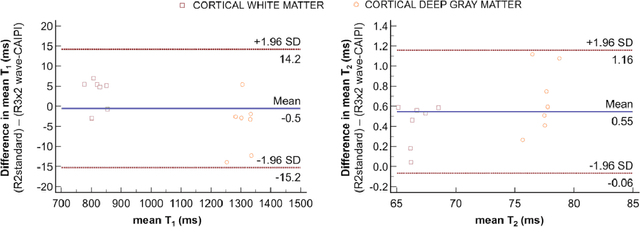
Purpose: Volumetric, high resolution, quantitative mapping of brain tissues relaxation properties is hindered by long acquisition times and SNR challenges. This study, for the first time, combines the time efficient wave-CAIPI readouts into the 3D-QALAS acquisition scheme, enabling full brain quantitative T1, T2 and PD maps at 1.15 isotropic voxels in only 3 minutes. Methods: Wave-CAIPI readouts were embedded in the standard 3d-QALAS encoding scheme, enabling full brain quantitative parameter maps (T1, T2 and PD) at acceleration factors of R=3x2 with minimum SNR loss due to g-factor penalties. The quantitative maps using the accelerated protocol were quantitatively compared against those obtained from conventional 3D-QALAS sequence using GRAPPA acceleration of R=2 in the ISMRM NIST phantom, and ten healthy volunteers. To show the feasibility of the proposed methods in clinical settings, the accelerated wave-CAIPI 3D-QALAS sequence was also employed in pediatric patients undergoing clinical MRI examinations. Results: When tested in both the ISMRM/NIST phantom and 7 healthy volunteers, the quantitative maps using the accelerated protocol showed excellent agreement against those obtained from conventional 3D-QALAS at R=2. Conclusion: 3D-QALAS enhanced with wave-CAIPI readouts enables time-efficient, full brain quantitative T1, T2 and PD mapping at 1.15 in 3 minutes at R=3x2 acceleration. When tested on the NIST phantom and 7 healthy volunteers, the quantitative maps obtained from the accelerated wave-CAIPI 3D-QALAS protocol showed very similar values to those obtained from the standard 3D-QALAS (R=2) protocol, alluding to the robustness and reliability of the proposed methods. This study also shows that the accelerated protocol can be effectively employed in pediatric patient populations, making high-quality high-resolution full brain quantitative imaging feasible in clinical settings.
3D Harmonic Loss: Towards Task-consistent and Time-friendly 3D Object Detection on Edge for V2X Orchestration
Nov 12, 2022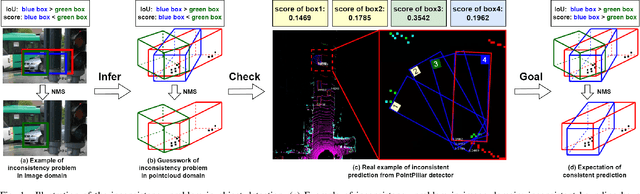

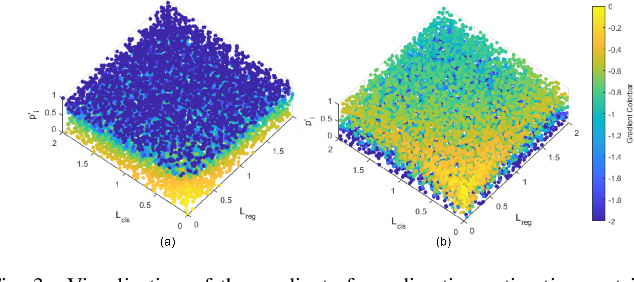
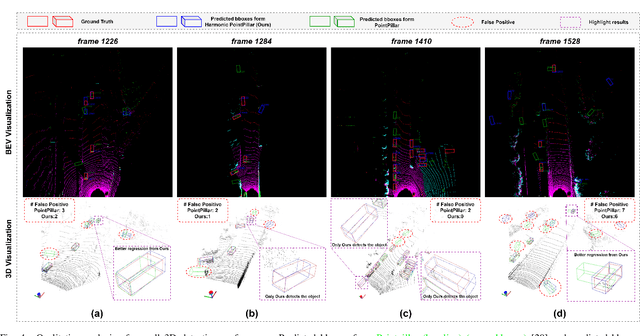
Edge computing-based 3D perception has received attention in intelligent transportation systems (ITS) because real-time monitoring of traffic candidates potentially strengthens Vehicle-to-Everything (V2X) orchestration. Thanks to the capability of precisely measuring the depth information on surroundings from LiDAR, the increasing studies focus on lidar-based 3D detection, which significantly promotes the development of 3D perception. Few methods met the real-time requirement of edge deployment because of high computation-intensive operations. Moreover, an inconsistency problem of object detection remains uncovered in the pointcloud domain due to large sparsity. This paper thoroughly analyses this problem, comprehensively roused by recent works on determining inconsistency problems in the image specialisation. Therefore, we proposed a 3D harmonic loss function to relieve the pointcloud based inconsistent predictions. Moreover, the feasibility of 3D harmonic loss is demonstrated from a mathematical optimization perspective. The KITTI dataset and DAIR-V2X-I dataset are used for simulations, and our proposed method considerably improves the performance than benchmark models. Further, the simulative deployment on an edge device (Jetson Xavier TX) validates our proposed model's efficiency.
Enhancing Causal Discovery from Robot Sensor Data in Dynamic Scenarios
Feb 20, 2023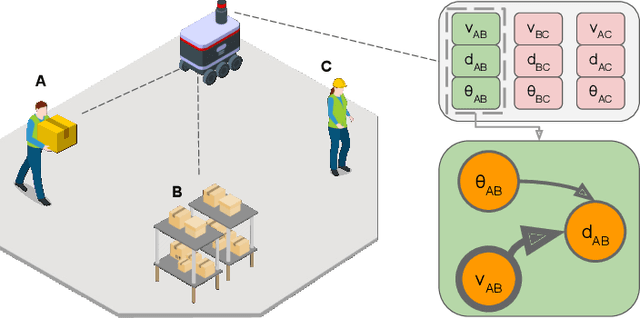
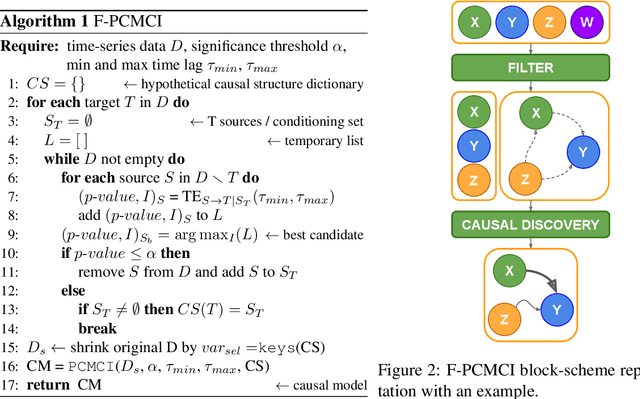

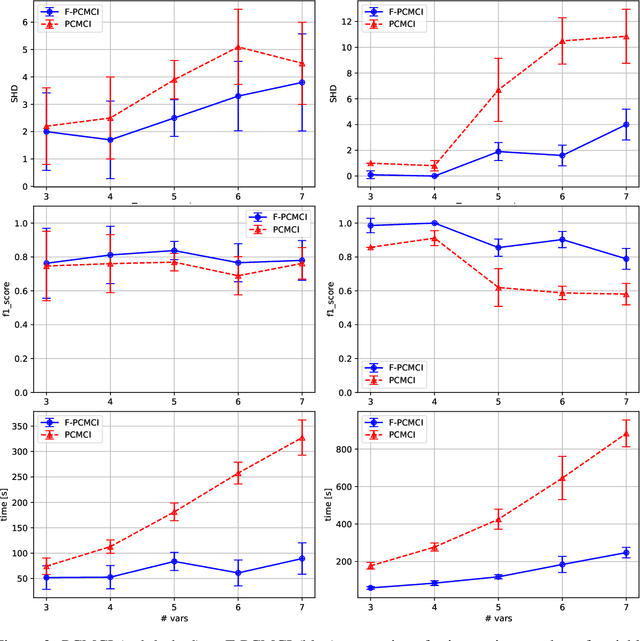
Identifying the main features and learning the causal relationships of a dynamic system from time-series of sensor data are key problems in many real-world robot applications. In this paper, we propose an extension of a state-of-the-art causal discovery method, PCMCI, embedding an additional feature-selection module based on transfer entropy. Starting from a prefixed set of variables, the new algorithm reconstructs the causal model of the observed system by considering only its main features and neglecting those deemed unnecessary for understanding the evolution of the system. We first validate the method on a toy problem and on synthetic data of brain network, for which the ground-truth models are available, and then on a real-world robotics scenario using a large-scale time-series dataset of human trajectories. The experiments demonstrate that our solution outperforms the previous state-of-the-art technique in terms of accuracy and computational efficiency, allowing better and faster causal discovery of meaningful models from robot sensor data.