 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraceScope: Interactive URL Triage via Decoupled Checklist Adjudication
Apr 23, 2026Modern phishing campaigns increasingly evade snapshot-based URL classifiers using interaction gates (e.g., checkbox/slider challenges), delayed content rendering, and logo-less credential harvesters. This shifts URL triage from static classification toward an interactive forensics task: an analyst must actively navigate the page while isolating themselves from potential runtime exploits. We present TraceScope, a decoupled triage pipeline that operationalizes this workflow at scale. To prevent the observer effect and ensure safety, a sandboxed operator agent drives a real GUI browser guided by visual motivation to elicit page behavior, freezing the session into an immutable evidence bundle. Separately, an adjudicator agent circumvents LLM context limitations by querying evidence on demand to verify a MITRE ATT&CK checklist, and generates an audit-ready report with extracted indicators of compromise (IOCs) and a final verdict. Evaluated on 708 reachable URLs from existing dataset (241 verified phishing from PhishTank and 467 benign from Tranco-derived crawling), TraceScope achieves 0.94 precision and 0.78 recall, substantially improving recall over three prior visual/reference-based classifiers while producing reproducible, analyst-grade evidence suitable for review. More importantly, we manually curated a dataset of real-world phishing emails to evaluate our system in a practical setting. Our evaluation reveals that TraceScope demonstrates superior performance in a real-world scenario as well, successfully detecting sophisticated phishing attempts that current state-of-the-art defenses fail to identify.
RoTE: Coarse-to-Fine Multi-Level Rotary Time Embedding for Sequential Recommendation
Apr 15, 2026Sequential recommendation models have been widely adopted for modeling user behavior. Existing approaches typically construct user interaction sequences by sorting items according to timestamps and then model user preferences from historical behaviors. While effective, such a process only considers the order of temporal information but overlooks the actual time spans between interactions, resulting in a coarse representation of users' temporal dynamics and limiting the model's ability to capture long-term and short-term interest evolution. To address this limitation, we propose RoTE, a novel multi-level temporal embedding module that explicitly models time span information in sequential recommendation. RoTE decomposes each interaction timestamp into multiple temporal granularities, ranging from coarse to fine, and incorporates the resulting temporal representations into item embeddings. This design enables models to capture heterogeneous temporal patterns and better perceive temporal distances among user interactions during sequence modeling. RoTE is a lightweight, plug-and-play module that can be seamlessly integrated into existing Transformer-based sequential recommendation models without modifying their backbone architectures. We apply RoTE to several representative models and conduct extensive experiments on three public benchmarks. Experimental results demonstrate that RoTE consistently enhances the corresponding backbone models, achieving up to a 20.11% improvement in NDCG@5, which confirms the effectiveness and generality of the proposed approach. Our code is available at https://github.com/XiaoLongtaoo/RoTE.
Optimal-Horizon Social Robot Navigation in Heterogeneous Crowds
Feb 28, 2026Navigating social robots in dense, dynamic crowds is challenging due to environmental uncertainty and complex human-robot interactions. While Model Predictive Control (MPC) offers strong real-time performance, its reliance on a fixed prediction horizon limits adaptability to changing environments and social dynamics. Furthermore, most MPC approaches treat pedestrians as homogeneous obstacles, ignoring social heterogeneity and cooperative or adversarial interactions, which often causes the Frozen Robot Problem in partially observable real-world environments. In this paper, we identify the planning horizon as a socially conditioned decision variable rather than a fixed design choice. Building on this insight, we propose an optimal-horizon social navigation framework that optimizes MPC foresight online according to inferred social context. A spatio-temporal Transformer infers pedestrian cooperation attributes from local trajectory observations, which serve as social priors for a reinforcement learning policy that optimally selects the prediction horizon under a task-driven objective. The resulting horizon-aware MPC incorporates socially conditioned safety constraints to balance navigation efficiency and interaction safety. Extensive simulations and real-world robot experiments demonstrate that optimal foresight selection is critical for robust social navigation in partially observable crowds. Compared to state-of-the-art baselines, the proposed approach achieves a 6.8\% improvement in success rate, reduces collisions by 50\%, and shortens navigation time by 19\%, with a low timeout rate of 0.8\%, validating the necessity of socially optimal planning horizons for efficient and safe robot navigation in crowded environments. Code and videos are available at Under Review.
FAIR: Focused Attention Is All You Need for Generative Recommendation
Dec 17, 2025Recently, transformer-based generative recommendation has garnered significant attention for user behavior modeling. However, it often requires discretizing items into multi-code representations (e.g., typically four code tokens or more), which sharply increases the length of the original item sequence. This expansion poses challenges to transformer-based models for modeling user behavior sequences with inherent noises, since they tend to overallocate attention to irrelevant or noisy context. To mitigate this issue, we propose FAIR, the first generative recommendation framework with focused attention, which enhances attention scores to relevant context while suppressing those to irrelevant ones. Specifically, we propose (1) a focused attention mechanism integrated into the standard Transformer, which learns two separate sets of Q and K attention weights and computes their difference as the final attention scores to eliminate attention noise while focusing on relevant contexts; (2) a noise-robustness objective, which encourages the model to maintain stable attention patterns under stochastic perturbations, preventing undesirable shifts toward irrelevant context due to noise; and (3) a mutual information maximization objective, which guides the model to identify contexts that are most informative for next-item prediction. We validate the effectiveness of FAIR on four public benchmarks, demonstrating its superior performance compared to existing methods.
Challenging GPU Dominance: When CPUs Outperform for On-Device LLM Inference
May 09, 2025The common assumption in on-device AI is that GPUs, with their superior parallel processing, always provide the best performance for large language model (LLM) inference. In this work, we challenge this notion by empirically demonstrating that, under certain conditions, CPUs can outperform GPUs for LLM inference on mobile devices. Using a 1-billion-parameter LLM deployed via llama.cpp on the iPhone 15 Pro, we show that a CPU-only configuration (two threads, F16 precision) achieves 17 tokens per second, surpassing the 12.8 tokens per second obtained with GPU acceleration. We analyze the architectural factors driving this counterintuitive result, revealing that GPU memory transfer overhead and CPU thread optimization play a critical role. Furthermore, we explore the impact of thread oversubscription, quantization strategies, and hardware constraints, providing new insights into efficient on-device AI execution. Our findings challenge conventional GPU-first thinking, highlighting the untapped potential of optimized CPU inference and paving the way for smarter deployment strategies in mobile AI. However, fully explaining the observed CPU advantage remains difficult due to limited access to low-level profiling tools on iOS.
Leveraging Anchor-based LiDAR 3D Object Detection via Point Assisted Sample Selection
Mar 04, 2024



3D object detection based on LiDAR point cloud and prior anchor boxes is a critical technology for autonomous driving environment perception and understanding. Nevertheless, an overlooked practical issue in existing methods is the ambiguity in training sample allocation based on box Intersection over Union (IoU_box). This problem impedes further enhancements in the performance of anchor-based LiDAR 3D object detectors. To tackle this challenge, this paper introduces a new training sample selection method that utilizes point cloud distribution for anchor sample quality measurement, named Point Assisted Sample Selection (PASS). This method has undergone rigorous evaluation on two widely utilized datasets. Experimental results demonstrate that the application of PASS elevates the average precision of anchor-based LiDAR 3D object detectors to a novel state-of-the-art, thereby proving the effectiveness of the proposed approach. The codes will be made available at https://github.com/XJTU-Haolin/Point_Assisted_Sample_Selection.
Map Reconstruction of radio observations with Conditional Invertible Neural Networks
Jun 15, 2023In radio astronomy, the challenge of reconstructing a sky map from time ordered data (TOD) is known as an inverse problem. Standard map-making techniques and gridding algorithms are commonly employed to address this problem, each offering its own benefits such as producing minimum-variance maps. However, these approaches also carry limitations such as computational inefficiency and numerical instability in map-making and the inability to remove beam effects in grid-based methods. To overcome these challenges, this study proposes a novel solution through the use of the conditional invertible neural network (cINN) for efficient sky map reconstruction. With the aid of forward modeling, where the simulated TODs are generated from a given sky model with a specific observation, the trained neural network can produce accurate reconstructed sky maps. Using the five-hundred-meter aperture spherical radio telescope (FAST) as an example, cINN demonstrates remarkable performance in map reconstruction from simulated TODs, achieving a mean squared error of $2.29\pm 2.14 \times 10^{-4}~\rm K^2$, a structural similarity index of $0.968\pm0.002$, and a peak signal-to-noise ratio of $26.13\pm5.22$ at the $1\sigma$ level. Furthermore, by sampling in the latent space of cINN, the reconstruction errors for each pixel can be accurately quantified.
3D Harmonic Loss: Towards Task-consistent and Time-friendly 3D Object Detection on Edge for V2X Orchestration
Nov 12, 2022



Edge computing-based 3D perception has received attention in intelligent transportation systems (ITS) because real-time monitoring of traffic candidates potentially strengthens Vehicle-to-Everything (V2X) orchestration. Thanks to the capability of precisely measuring the depth information on surroundings from LiDAR, the increasing studies focus on lidar-based 3D detection, which significantly promotes the development of 3D perception. Few methods met the real-time requirement of edge deployment because of high computation-intensive operations. Moreover, an inconsistency problem of object detection remains uncovered in the pointcloud domain due to large sparsity. This paper thoroughly analyses this problem, comprehensively roused by recent works on determining inconsistency problems in the image specialisation. Therefore, we proposed a 3D harmonic loss function to relieve the pointcloud based inconsistent predictions. Moreover, the feasibility of 3D harmonic loss is demonstrated from a mathematical optimization perspective. The KITTI dataset and DAIR-V2X-I dataset are used for simulations, and our proposed method considerably improves the performance than benchmark models. Further, the simulative deployment on an edge device (Jetson Xavier TX) validates our proposed model's efficiency.
Predicting Pedestrian Crossing Intention with Feature Fusion and Spatio-Temporal Attention
Apr 12, 2021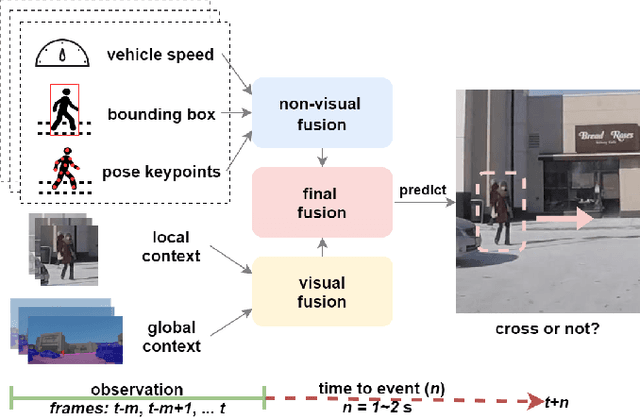
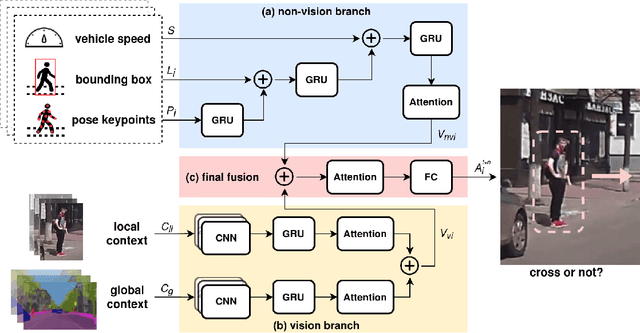
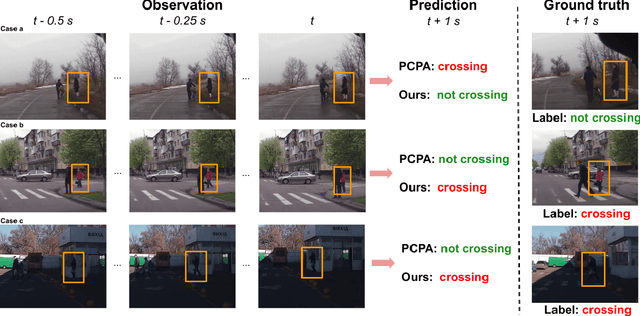
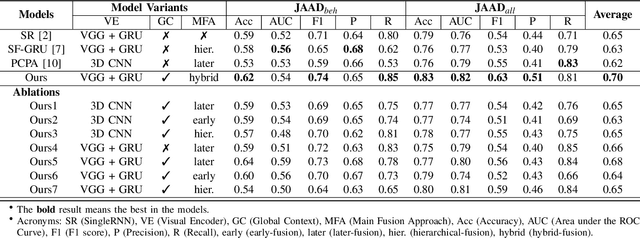
Predicting vulnerable road user behavior is an essential prerequisite for deploying Automated Driving Systems (ADS) in the real-world. Pedestrian crossing intention should be recognized in real-time, especially for urban driving. Recent works have shown the potential of using vision-based deep neural network models for this task. However, these models are not robust and certain issues still need to be resolved. First, the global spatio-temproal context that accounts for the interaction between the target pedestrian and the scene has not been properly utilized. Second, the optimum strategy for fusing different sensor data has not been thoroughly investigated. This work addresses the above limitations by introducing a novel neural network architecture to fuse inherently different spatio-temporal features for pedestrian crossing intention prediction. We fuse different phenomena such as sequences of RGB imagery, semantic segmentation masks, and ego-vehicle speed in an optimum way using attention mechanisms and a stack of recurrent neural networks. The optimum architecture was obtained through exhaustive ablation and comparison studies. Extensive comparative experiments on the JAAD pedestrian action prediction benchmark demonstrate the effectiveness of the proposed method, where state-of-the-art performance was achieved. Our code is open-source and publicly available.
Faraway-Frustum: Dealing with Lidar Sparsity for 3D Object Detection using Fusion
Nov 03, 2020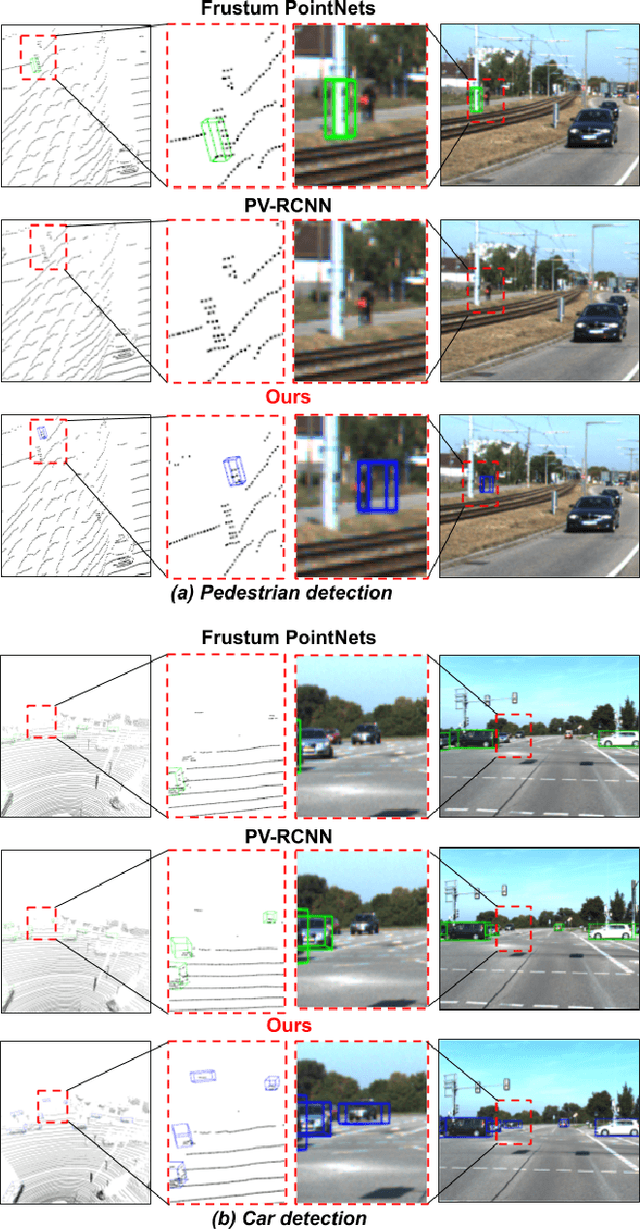
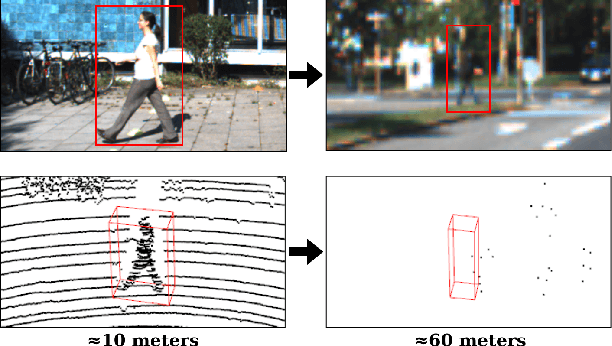

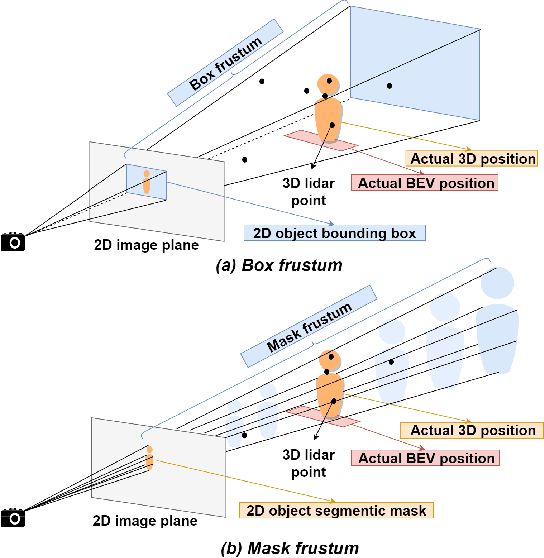
Learned pointcloud representations do not generalize well with an increase in distance to the sensor. For example, at a range greater than 60 meters, the sparsity of lidar pointclouds reaches to a point where even humans cannot discern object shapes from each other. However, this distance should not be considered very far for fast-moving vehicles: A vehicle can traverse 60 meters under two seconds while moving at 70 mph. For safe and robust driving automation, acute 3D object detection at these ranges is indispensable. Against this backdrop, we introduce faraway-frustum: a novel fusion strategy for detecting faraway objects. The main strategy is to depend solely on the 2D vision for recognizing object class, as object shape does not change drastically with an increase in depth, and use pointcloud data for object localization in the 3D space for faraway objects. For closer objects, we use learned pointcloud representations instead, following state-of-the-art. This strategy alleviates the main shortcoming of object detection with learned pointcloud representations. Experiments on the KITTI dataset demonstrate that our method outperforms state-of-the-art by a considerable margin for faraway object detection in bird's-eye-view and 3D.