 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Class-level Multiple Distributions Representation are Necessary for Semantic Segmentation
Mar 14, 2023
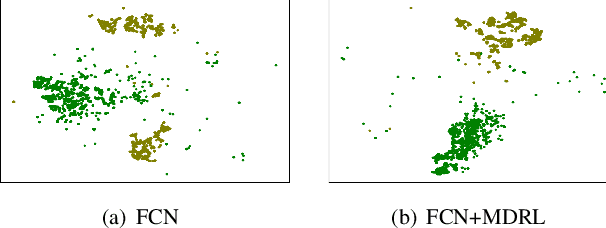
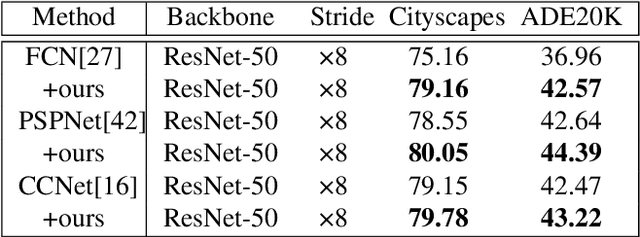
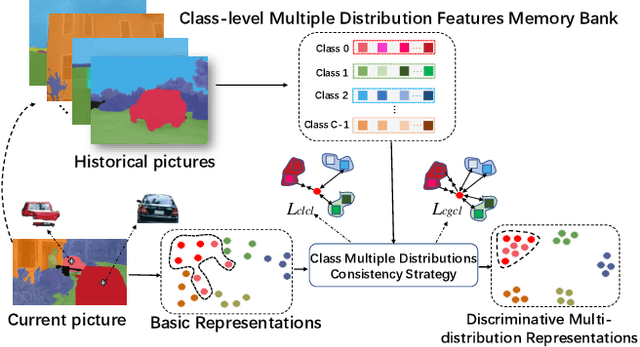
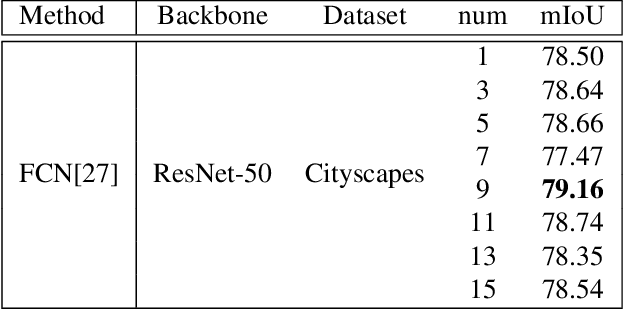
Existing approaches focus on using class-level features to improve semantic segmentation performance. How to characterize the relationships of intra-class pixels and inter-class pixels is the key to extract the discriminative representative class-level features. In this paper, we introduce for the first time to describe intra-class variations by multiple distributions. Then, multiple distributions representation learning(\textbf{MDRL}) is proposed to augment the pixel representations for semantic segmentation. Meanwhile, we design a class multiple distributions consistency strategy to construct discriminative multiple distribution representations of embedded pixels. Moreover, we put forward a multiple distribution semantic aggregation module to aggregate multiple distributions of the corresponding class to enhance pixel semantic information. Our approach can be seamlessly integrated into popular segmentation frameworks FCN/PSPNet/CCNet and achieve 5.61\%/1.75\%/0.75\% mIoU improvements on ADE20K. Extensive experiments on the Cityscapes, ADE20K datasets have proved that our method can bring significant performance improvement.
Bronchoscopic video synchronization for interactive multimodal inspection of bronchial lesions
Mar 20, 2023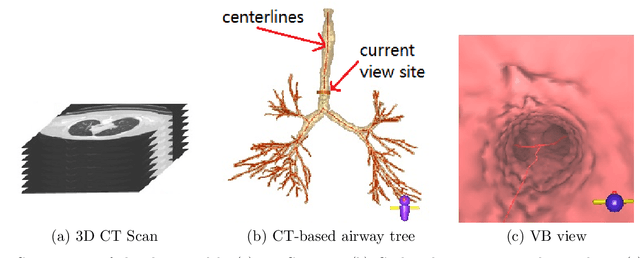
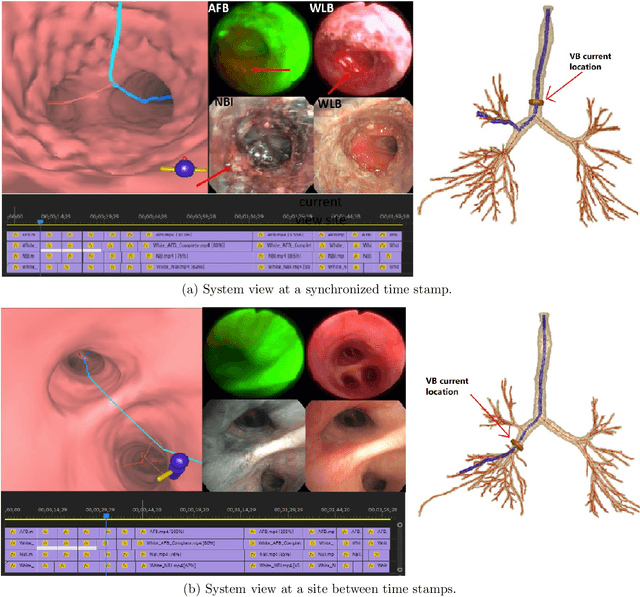
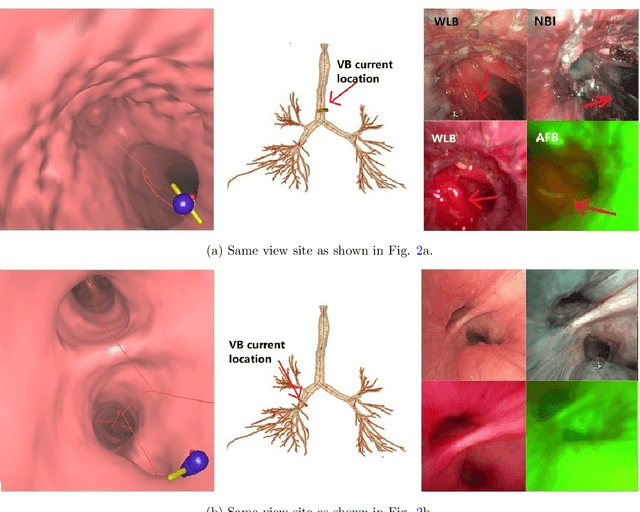
With lung cancer being the most fatal cancer worldwide, it is important to detect the disease early. A potentially effective way of detecting early cancer lesions developing along the airway walls (epithelium) is bronchoscopy. To this end, developments in bronchoscopy offer three promising noninvasive modalities for imaging bronchial lesions: white-light bronchoscopy (WLB), autofluorescence bronchoscopy (AFB), and narrow-band imaging (NBI). While these modalities give complementary views of the airway epithelium, the physician must manually inspect each video stream produced by a given modality to locate the suspect cancer lesions. Unfortunately, no effort has been made to rectify this situation by providing efficient quantitative and visual tools for analyzing these video streams. This makes the lesion search process extremely time-consuming and error-prone, thereby making it impractical to utilize these rich data sources effectively. We propose a framework for synchronizing multiple bronchoscopic videos to enable an interactive multimodal analysis of bronchial lesions. Our methods first register the video streams to a reference 3D chest computed-tomography (CT) scan to produce multimodal linkages to the airway tree. Our methods then temporally correlate the videos to one another to enable synchronous visualization of the resulting multimodal data set. Pictorial and quantitative results illustrate the potential of the methods.
VIMI: Vehicle-Infrastructure Multi-view Intermediate Fusion for Camera-based 3D Object Detection
Mar 20, 2023
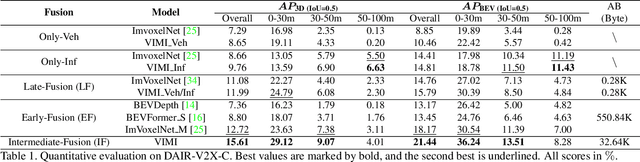
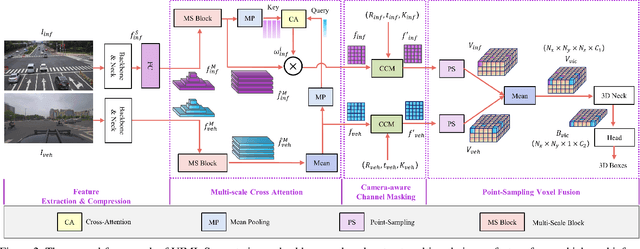
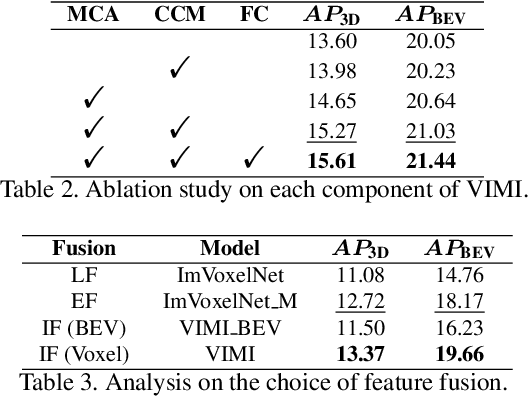
In autonomous driving, Vehicle-Infrastructure Cooperative 3D Object Detection (VIC3D) makes use of multi-view cameras from both vehicles and traffic infrastructure, providing a global vantage point with rich semantic context of road conditions beyond a single vehicle viewpoint. Two major challenges prevail in VIC3D: 1) inherent calibration noise when fusing multi-view images, caused by time asynchrony across cameras; 2) information loss when projecting 2D features into 3D space. To address these issues, We propose a novel 3D object detection framework, Vehicles-Infrastructure Multi-view Intermediate fusion (VIMI). First, to fully exploit the holistic perspectives from both vehicles and infrastructure, we propose a Multi-scale Cross Attention (MCA) module that fuses infrastructure and vehicle features on selective multi-scales to correct the calibration noise introduced by camera asynchrony. Then, we design a Camera-aware Channel Masking (CCM) module that uses camera parameters as priors to augment the fused features. We further introduce a Feature Compression (FC) module with channel and spatial compression blocks to reduce the size of transmitted features for enhanced efficiency. Experiments show that VIMI achieves 15.61% overall AP_3D and 21.44% AP_BEV on the new VIC3D dataset, DAIR-V2X-C, significantly outperforming state-of-the-art early fusion and late fusion methods with comparable transmission cost.
Image Deblurring by Exploring In-depth Properties of Transformer
Mar 24, 2023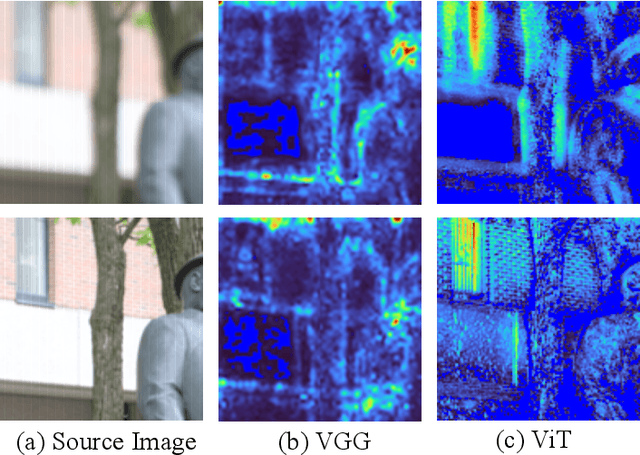
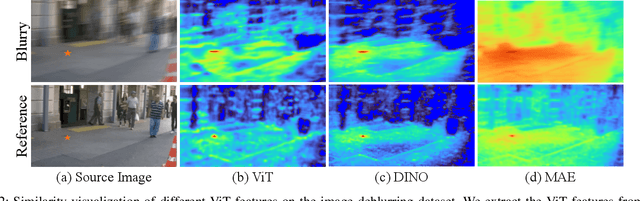
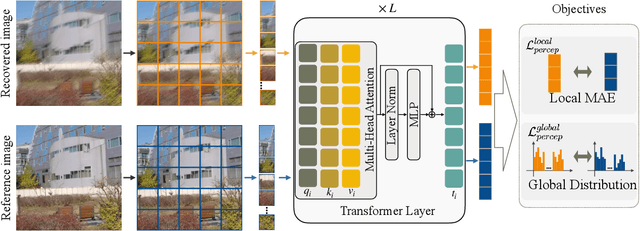

Image deblurring continues to achieve impressive performance with the development of generative models. Nonetheless, there still remains a displeasing problem if one wants to improve perceptual quality and quantitative scores of recovered image at the same time. In this study, drawing inspiration from the research of transformer properties, we introduce the pretrained transformers to address this problem. In particular, we leverage deep features extracted from a pretrained vision transformer (ViT) to encourage recovered images to be sharp without sacrificing the performance measured by the quantitative metrics. The pretrained transformer can capture the global topological relations (i.e., self-similarity) of image, and we observe that the captured topological relations about the sharp image will change when blur occurs. By comparing the transformer features between recovered image and target one, the pretrained transformer provides high-resolution blur-sensitive semantic information, which is critical in measuring the sharpness of the deblurred image. On the basis of the advantages, we present two types of novel perceptual losses to guide image deblurring. One regards the features as vectors and computes the discrepancy between representations extracted from recovered image and target one in Euclidean space. The other type considers the features extracted from an image as a distribution and compares the distribution discrepancy between recovered image and target one. We demonstrate the effectiveness of transformer properties in improving the perceptual quality while not sacrificing the quantitative scores (PSNR) over the most competitive models, such as Uformer, Restormer, and NAFNet, on defocus deblurring and motion deblurring tasks.
Non-invasive urinary bladder volume estimation with artefact-suppressed bio-impedance measurements
Mar 24, 2023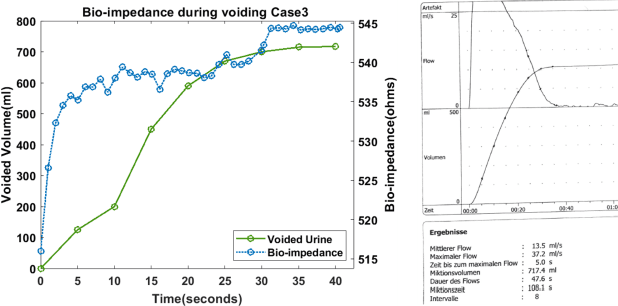
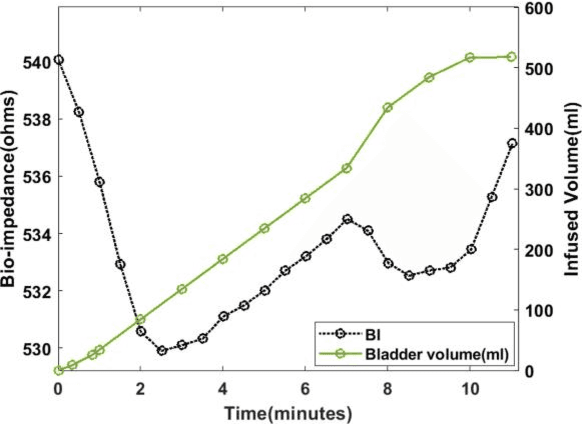
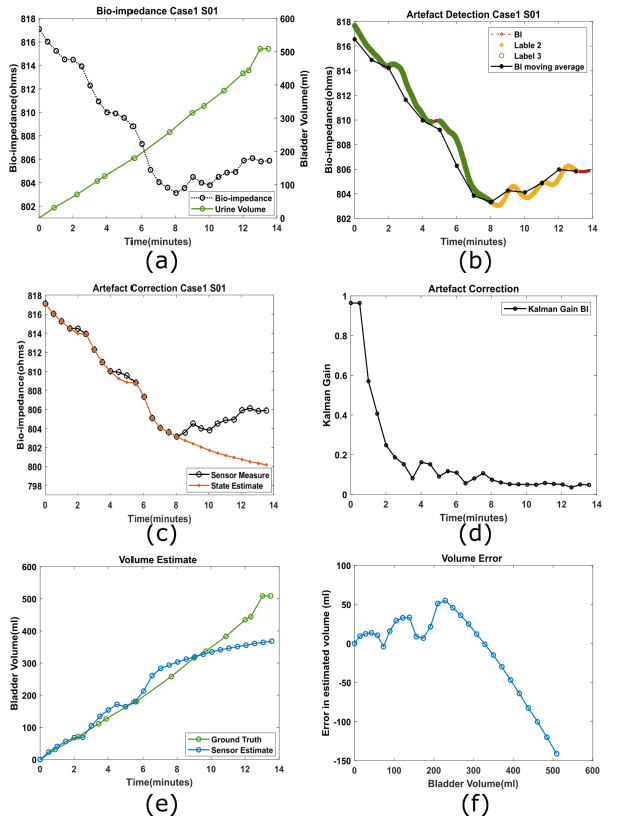
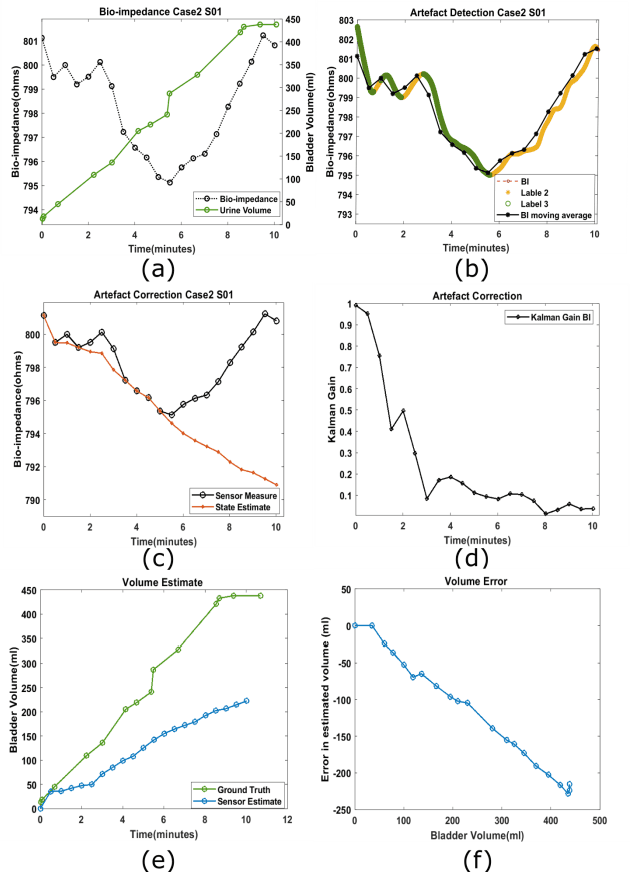
Urine output is a vital parameter to gauge kidney health. Current monitoring methods include manually written records, invasive urinary catheterization or ultrasound measurements performed by highly skilled personnel. Catheterization bears high risks of infection while intermittent ultrasound measures and manual recording are time consuming and might miss early signs of kidney malfunction. Bioimpedance (BI) measurements may serve as a non-invasive alternative for measuring urine volume in vivo. However, limited robustness have prevented its clinical translation. Here, a deep learning-based algorithm is presented that processes the local BI of the lower abdomen and suppresses artefacts to measure the bladder volume quantitatively, non-invasively and without the continuous need for additional personnel. A tetrapolar BI wearable system called ANUVIS was used to collect continuous bladder volume data from three healthy subjects to demonstrate feasibility of operation, while clinical gold standards of urodynamic (n=6) and uroflowmetry tests (n=8) provided the ground truth. Optimized location for electrode placement and a model for the change in BI with changing bladder volume is deduced. The average error for full bladder volume estimation and for residual volume estimation was -29 +/-87.6 ml, thus, comparable to commercial portable ultrasound devices (Bland Altman analysis showed a bias of -5.2 ml with LoA between 119.7 ml to -130.1 ml), while providing the additional benefit of hands-free, non-invasive, and continuous bladder volume estimation. The combination of the wearable BI sensor node and the presented algorithm provides an attractive alternative to current standard of care with potential benefits in providing insights into kidney function.
4D iRIOM: 4D Imaging Radar Inertial Odometry and Mapping
Mar 24, 2023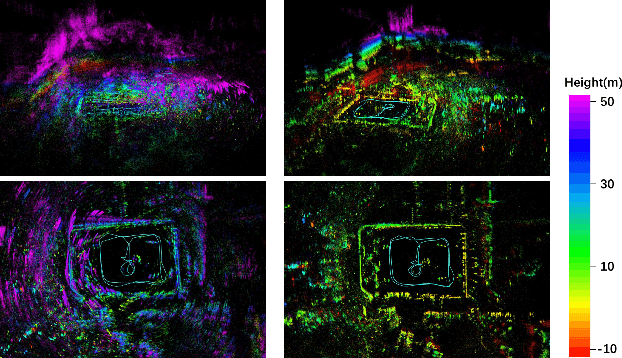
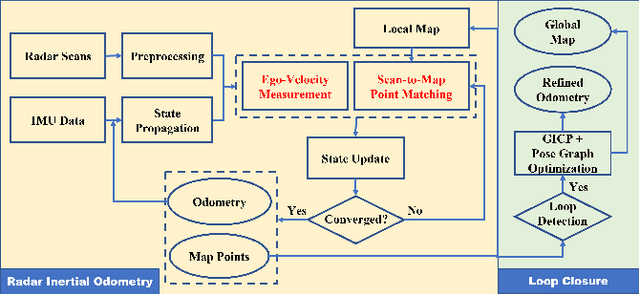

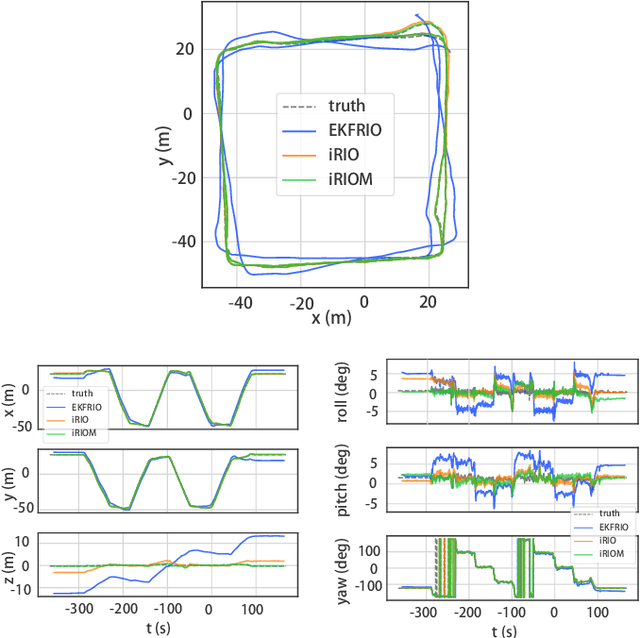
Millimeter wave radar can measure distances, directions, and Doppler velocity for objects in harsh conditions such as fog. The 4D imaging radar with both vertical and horizontal data resembling an image can also measure objects' height. Previous studies have used 3D radars for ego-motion estimation. But few methods leveraged the rich data of imaging radars, and they usually omitted the mapping aspect which is affected by the radar multipath returns, thus leading to inferior odometry accuracy. This paper presents a real-time imaging radar inertial odometry and mapping method, iRIOM, based on the submap concept. To fend off moving objects and multipath reflections, the iteratively reweighted least squares method is used for getting the ego-velocity from a single scan. To measure the agreement between sparse non-repetitive radar scan points and submap points, the distribution-to-multi-distribution distance for matches is adopted. The ego-velocity, scan-to-submap matches are fused with the 6D inertial data by an iterative extended Kalman filter to get the platform's 3D position and orientation. A loop closure module is also developed to curb the odometry module's drift. To our knowledge, iRIOM based on the two modules is the first 4D radar inertial SLAM system. On our and third-party data, we show iRIOM's favorable odometry accuracy and mapping consistency against the FastLIO-SLAM and the EKFRIO. Also, the ablation study reveal the benefit of inertial data versus the constant velocity model, the scan-to-submap matching versus the scan-to-scans matching, and loop closure.
Short-Term Memory Convolutions
Feb 08, 2023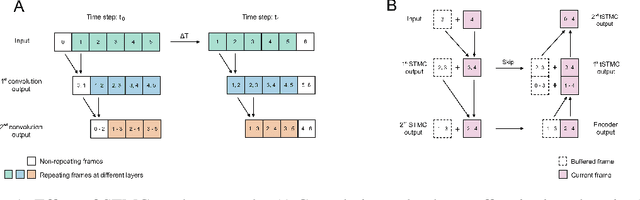
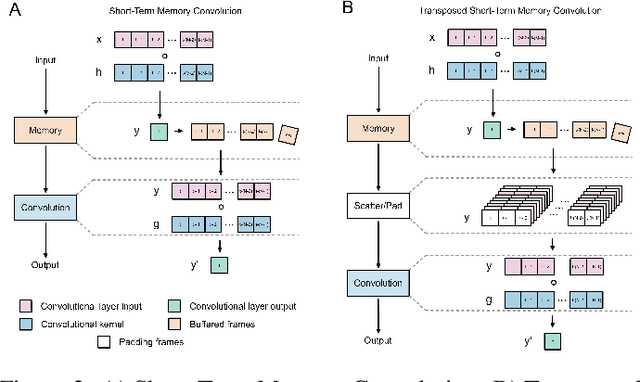
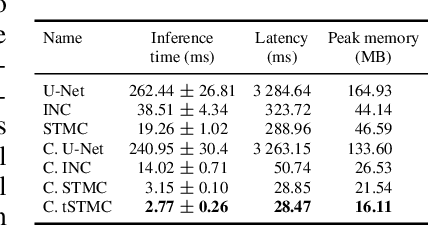
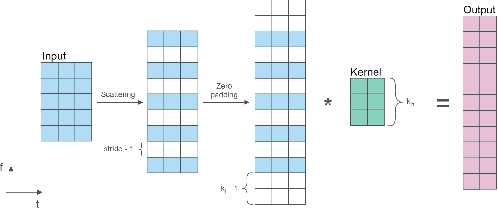
The real-time processing of time series signals is a critical issue for many real-life applications. The idea of real-time processing is especially important in audio domain as the human perception of sound is sensitive to any kind of disturbance in perceived signals, especially the lag between auditory and visual modalities. The rise of deep learning (DL) models complicated the landscape of signal processing. Although they often have superior quality compared to standard DSP methods, this advantage is diminished by higher latency. In this work we propose novel method for minimization of inference time latency and memory consumption, called Short-Term Memory Convolution (STMC) and its transposed counterpart. The main advantage of STMC is the low latency comparable to long short-term memory (LSTM) networks. Furthermore, the training of STMC-based models is faster and more stable as the method is based solely on convolutional neural networks (CNNs). In this study we demonstrate an application of this solution to a U-Net model for a speech separation task and GhostNet model in acoustic scene classification (ASC) task. In case of speech separation we achieved a 5-fold reduction in inference time and a 2-fold reduction in latency without affecting the output quality. The inference time for ASC task was up to 4 times faster while preserving the original accuracy.
On Frequency-Domain Implementation of Digital FIR Filters Using Overlap-Add and Overlap-Save Techniques
Feb 17, 2023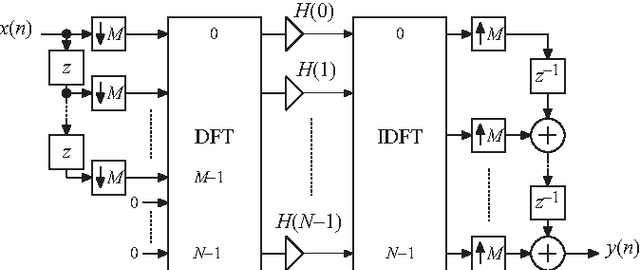
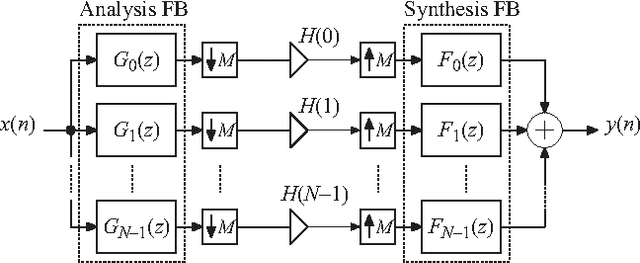
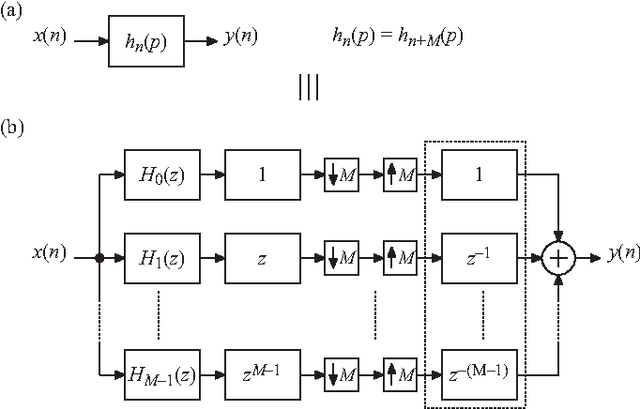
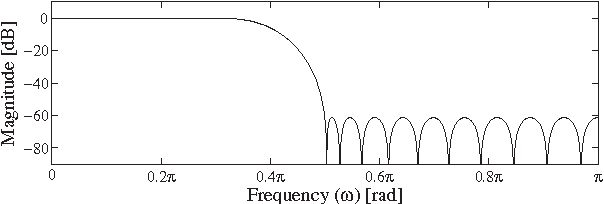
In this paper, new insights in frequency-domain implementations of digital finite-length impulse response filtering (linear convolution) using overlap-add and overlap-save techniques are provided. It is shown that, in practical finite-wordlength implementations, the overall system corresponds to a time-varying system that can be represented in essentially two different ways. One way is to represent the system with a distortion function and aliasing functions, which in this paper is derived from multirate filter bank representations. The other way is to use a periodically time-varying impulse-response representation or, equivalently, a set of time-invariant impulse responses and the corresponding frequency responses. The paper provides systematic derivations and analyses of these representations along with filter impulse response properties and design examples. The representations are particularly useful when analyzing the effect of coefficient quantizations as well as the use of shorter DFT lengths than theoretically required. A comprehensive computational-complexity analysis is also provided, and accurate formulas for estimating the optimal DFT lengths for given filter lengths are derived. Using optimal DFT lengths, it is shown that the frequency-domain implementations have lower computational complexities (multiplication rates) than the corresponding time-domain implementations for filter lengths that are shorter than those reported earlier in the literature. In particular, for general (unsymmetric) filters, the frequency-domain implementations are shown to be more efficient for all filter lengths. This opens up for new considerations when comparing complexities of different filter implementations.
Neural Airport Ground Handling
Mar 04, 2023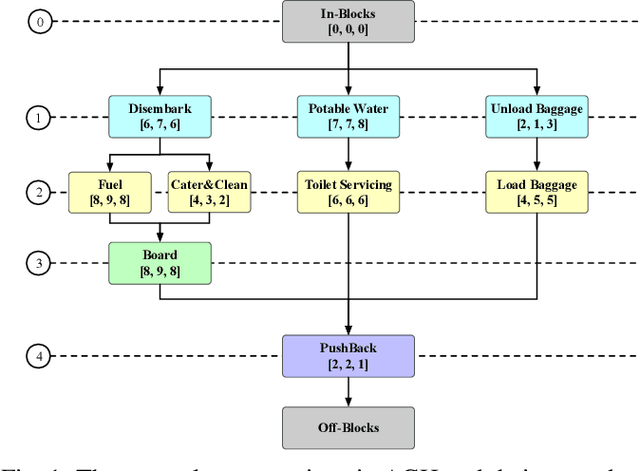
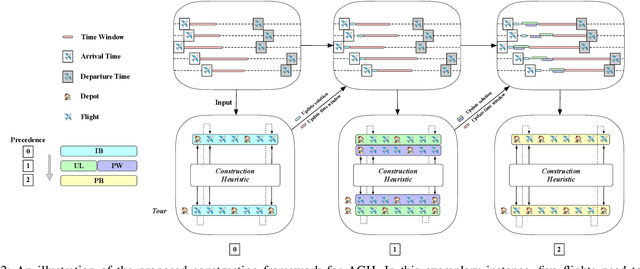
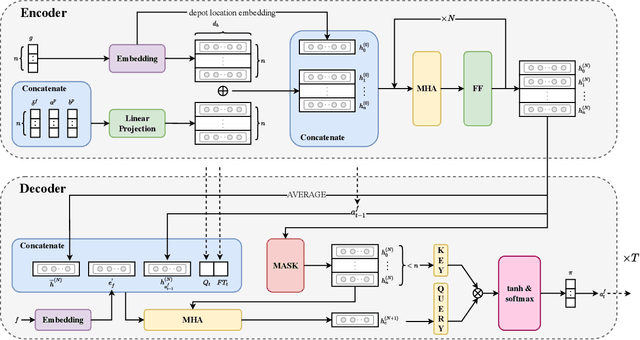
Airport ground handling (AGH) offers necessary operations to flights during their turnarounds and is of great importance to the efficiency of airport management and the economics of aviation. Such a problem involves the interplay among the operations that leads to NP-hard problems with complex constraints. Hence, existing methods for AGH are usually designed with massive domain knowledge but still fail to yield high-quality solutions efficiently. In this paper, we aim to enhance the solution quality and computation efficiency for solving AGH. Particularly, we first model AGH as a multiple-fleet vehicle routing problem (VRP) with miscellaneous constraints including precedence, time windows, and capacity. Then we propose a construction framework that decomposes AGH into sub-problems (i.e., VRPs) in fleets and present a neural method to construct the routing solutions to these sub-problems. In specific, we resort to deep learning and parameterize the construction heuristic policy with an attention-based neural network trained with reinforcement learning, which is shared across all sub-problems. Extensive experiments demonstrate that our method significantly outperforms classic meta-heuristics, construction heuristics and the specialized methods for AGH. Besides, we empirically verify that our neural method generalizes well to instances with large numbers of flights or varying parameters, and can be readily adapted to solve real-time AGH with stochastic flight arrivals. Our code is publicly available at: https://github.com/RoyalSkye/AGH.
VP-SLAM: A Monocular Real-time Visual SLAM with Points, Lines and Vanishing Points
Oct 28, 2022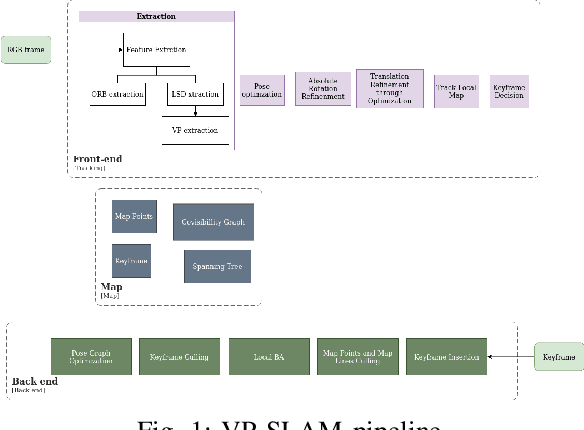
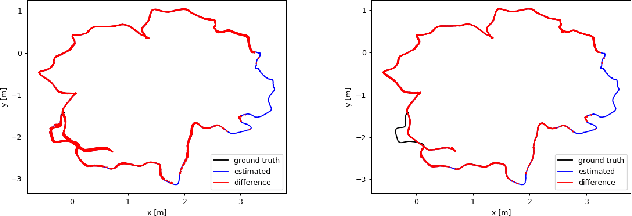
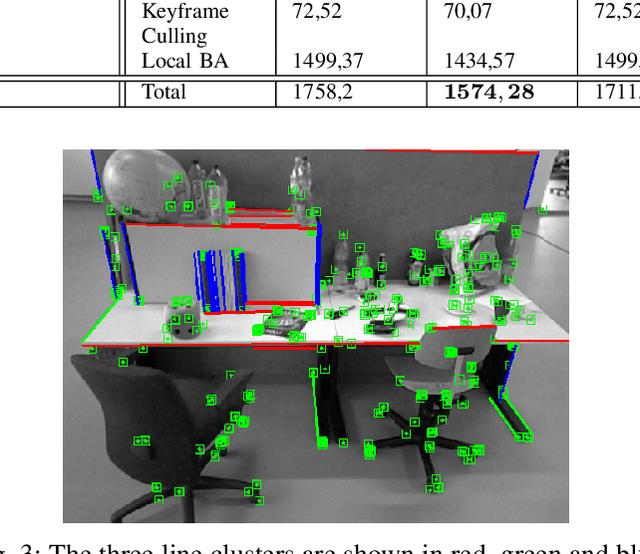
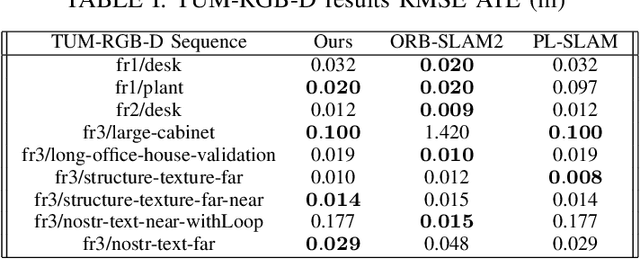
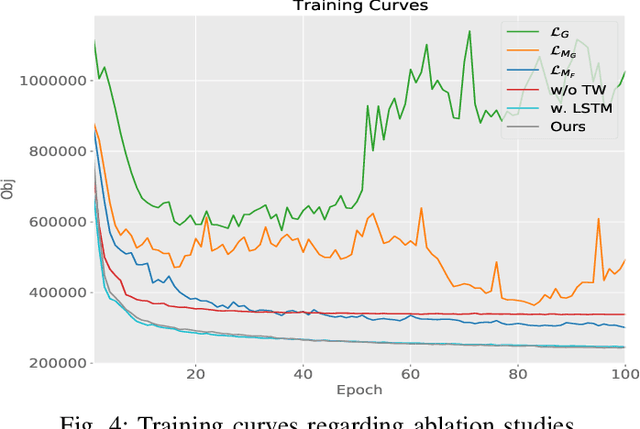
Traditional monocular Visual Simultaneous Localization and Mapping (vSLAM) systems can be divided into three categories: those that use features, those that rely on the image itself, and hybrid models. In the case of feature-based methods, new research has evolved to incorporate more information from their environment using geometric primitives beyond points, such as lines and planes. This is because in many environments, which are man-made environments, characterized as Manhattan world, geometric primitives such as lines and planes occupy most of the space in the environment. The exploitation of these schemes can lead to the introduction of algorithms capable of optimizing the trajectory of a Visual SLAM system and also helping to construct an exuberant map. Thus, we present a real-time monocular Visual SLAM system that incorporates real-time methods for line and VP extraction, as well as two strategies that exploit vanishing points to estimate the robot's translation and improve its rotation.Particularly, we build on ORB-SLAM2, which is considered the current state-of-the-art solution in terms of both accuracy and efficiency, and extend its formulation to handle lines and VPs to create two strategies the first optimize the rotation and the second refine the translation part from the known rotation. First, we extract VPs using a real-time method and use them for a global rotation optimization strategy. Second, we present a translation estimation method that takes advantage of last-stage rotation optimization to model a linear system. Finally, we evaluate our system on the TUM RGB-D benchmark and demonstrate that the proposed system achieves state-of-the-art results and runs in real time, and its performance remains close to the original ORB-SLAM2 system