 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Self-supervised learning for infant cry analysis
May 02, 2023
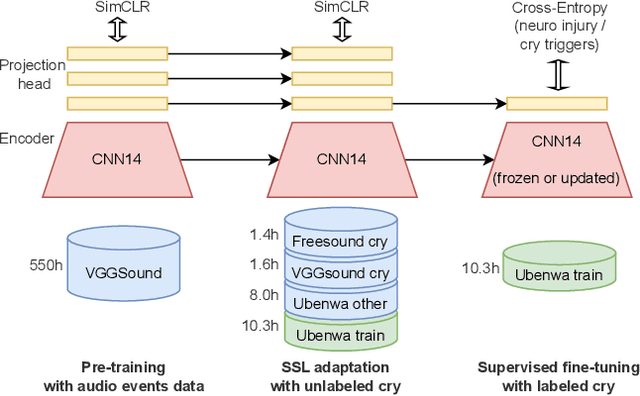
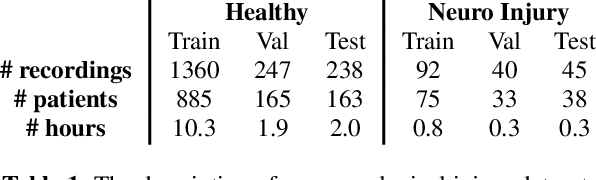

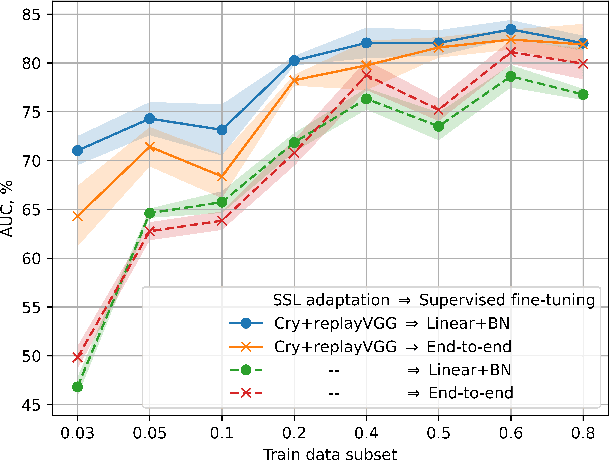
In this paper, we explore self-supervised learning (SSL) for analyzing a first-of-its-kind database of cry recordings containing clinical indications of more than a thousand newborns. Specifically, we target cry-based detection of neurological injury as well as identification of cry triggers such as pain, hunger, and discomfort. Annotating a large database in the medical setting is expensive and time-consuming, typically requiring the collaboration of several experts over years. Leveraging large amounts of unlabeled audio data to learn useful representations can lower the cost of building robust models and, ultimately, clinical solutions. In this work, we experiment with self-supervised pre-training of a convolutional neural network on large audio datasets. We show that pre-training with SSL contrastive loss (SimCLR) performs significantly better than supervised pre-training for both neuro injury and cry triggers. In addition, we demonstrate further performance gains through SSL-based domain adaptation using unlabeled infant cries. We also show that using such SSL-based pre-training for adaptation to cry sounds decreases the need for labeled data of the overall system.
Light-weight Deep Extreme Multilabel Classification
Apr 20, 2023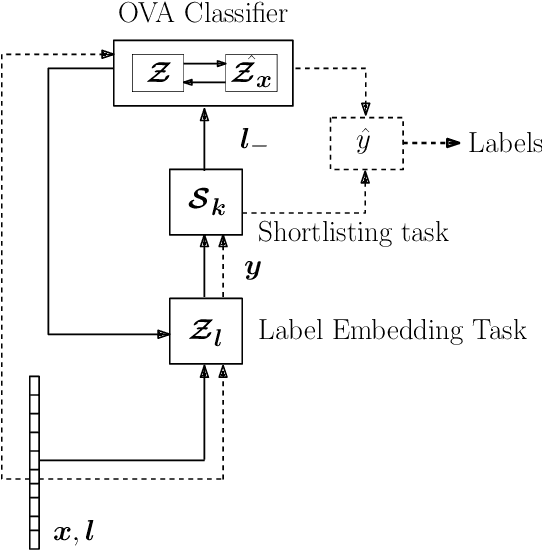
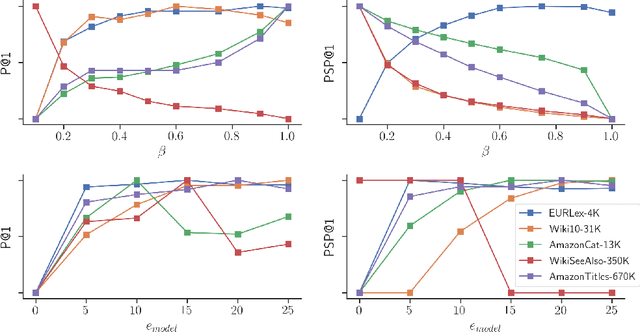

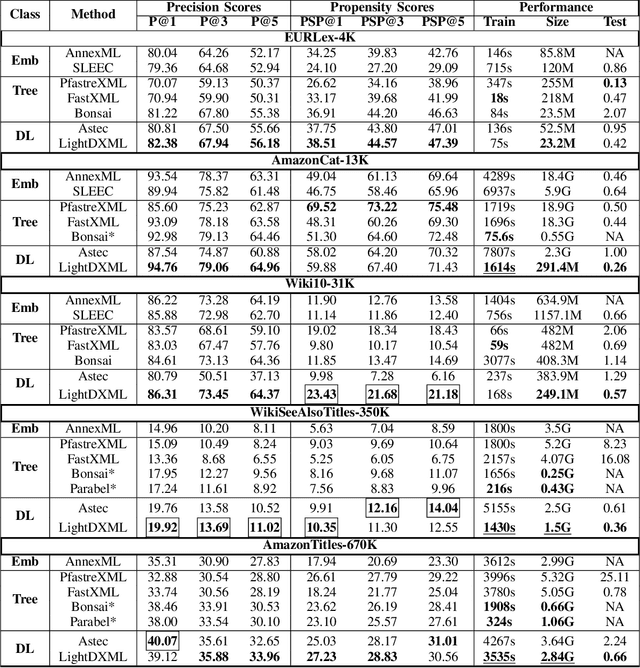
Extreme multi-label (XML) classification refers to the task of supervised multi-label learning that involves a large number of labels. Hence, scalability of the classifier with increasing label dimension is an important consideration. In this paper, we develop a method called LightDXML which modifies the recently developed deep learning based XML framework by using label embeddings instead of feature embedding for negative sampling and iterating cyclically through three major phases: (1) proxy training of label embeddings (2) shortlisting of labels for negative sampling and (3) final classifier training using the negative samples. Consequently, LightDXML also removes the requirement of a re-ranker module, thereby, leading to further savings on time and memory requirements. The proposed method achieves the best of both worlds: while the training time, model size and prediction times are on par or better compared to the tree-based methods, it attains much better prediction accuracy that is on par with the deep learning based methods. Moreover, the proposed approach achieves the best tail-label prediction accuracy over most state-of-the-art XML methods on some of the large datasets\footnote{accepted in IJCNN 2023, partial funding from MAPG grant and IIIT Seed grant at IIIT, Hyderabad, India. Code: \url{https://github.com/misterpawan/LightDXML}
Time series numerical association rule mining variants in smart agriculture
Dec 07, 2022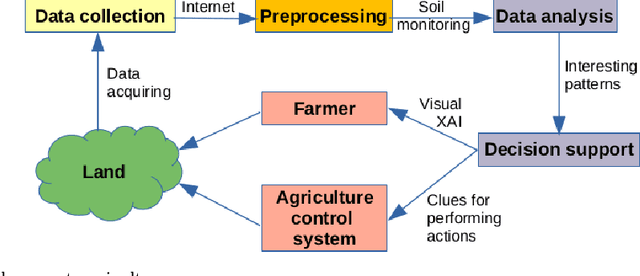
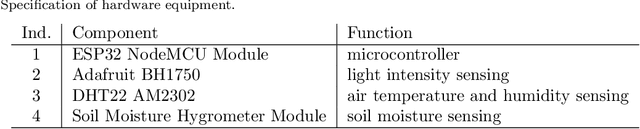

Numerical association rule mining offers a very efficient way of mining association rules, where algorithms can operate directly with categorical and numerical attributes. These methods are suitable for mining different transaction databases, where data are entered sequentially. However, little attention has been paid to the time series numerical association rule mining, which offers a new technique for extracting association rules from time series data. This paper presents a new algorithmic method for time series numerical association rule mining and its application in smart agriculture. We offer a concept of a hardware environment for monitoring plant parameters and a novel data mining method with practical experiments. The practical experiments showed the method's potential and opened the door for further extension.
RTMDet: An Empirical Study of Designing Real-Time Object Detectors
Dec 16, 2022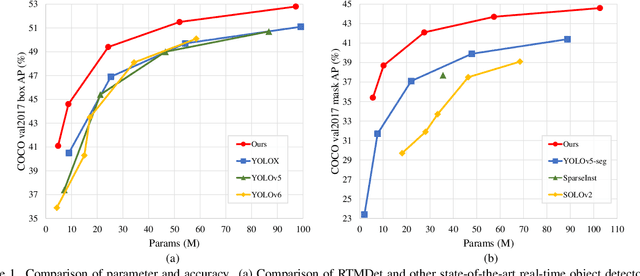
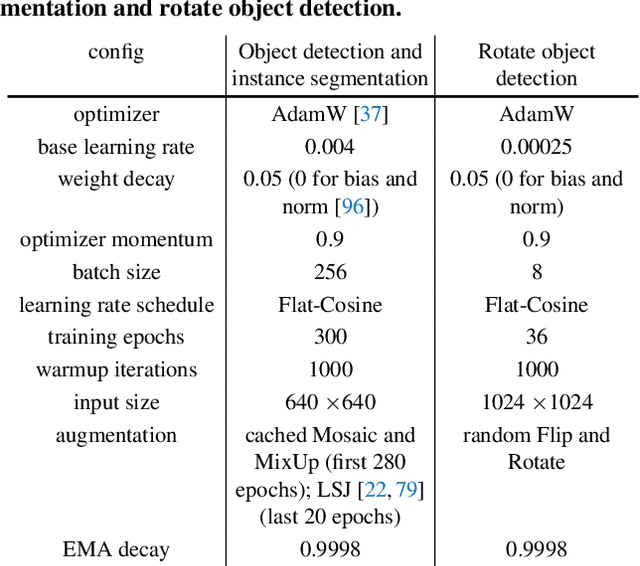
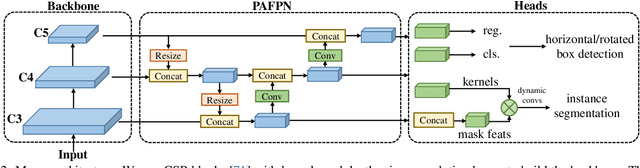
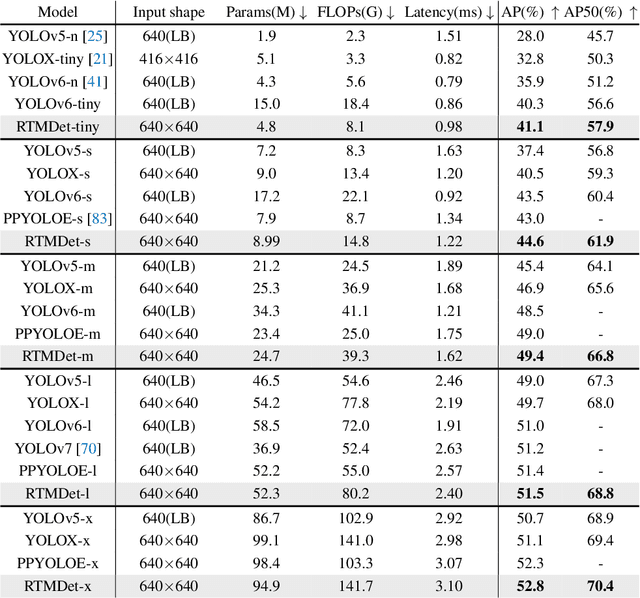
In this paper, we aim to design an efficient real-time object detector that exceeds the YOLO series and is easily extensible for many object recognition tasks such as instance segmentation and rotated object detection. To obtain a more efficient model architecture, we explore an architecture that has compatible capacities in the backbone and neck, constructed by a basic building block that consists of large-kernel depth-wise convolutions. We further introduce soft labels when calculating matching costs in the dynamic label assignment to improve accuracy. Together with better training techniques, the resulting object detector, named RTMDet, achieves 52.8% AP on COCO with 300+ FPS on an NVIDIA 3090 GPU, outperforming the current mainstream industrial detectors. RTMDet achieves the best parameter-accuracy trade-off with tiny/small/medium/large/extra-large model sizes for various application scenarios, and obtains new state-of-the-art performance on real-time instance segmentation and rotated object detection. We hope the experimental results can provide new insights into designing versatile real-time object detectors for many object recognition tasks. Code and models are released at https://github.com/open-mmlab/mmdetection/tree/3.x/configs/rtmdet.
Contrastive Enhanced Slide Filter Mixer for Sequential Recommendation
May 07, 2023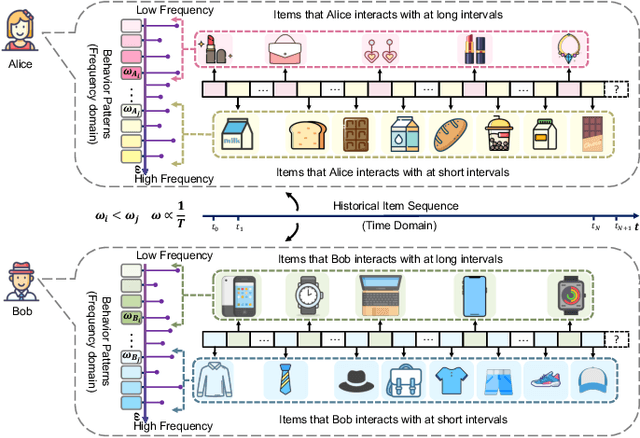
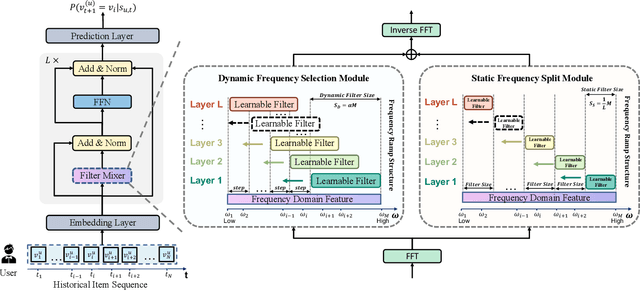

Sequential recommendation (SR) aims to model user preferences by capturing behavior patterns from their item historical interaction data. Most existing methods model user preference in the time domain, omitting the fact that users' behaviors are also influenced by various frequency patterns that are difficult to separate in the entangled chronological items. However, few attempts have been made to train SR in the frequency domain, and it is still unclear how to use the frequency components to learn an appropriate representation for the user. To solve this problem, we shift the viewpoint to the frequency domain and propose a novel Contrastive Enhanced \textbf{SLI}de Filter \textbf{M}ixEr for Sequential \textbf{Rec}ommendation, named \textbf{SLIME4Rec}. Specifically, we design a frequency ramp structure to allow the learnable filter slide on the frequency spectrums across different layers to capture different frequency patterns. Moreover, a Dynamic Frequency Selection (DFS) and a Static Frequency Split (SFS) module are proposed to replace the self-attention module for effectively extracting frequency information in two ways. DFS is used to select helpful frequency components dynamically, and SFS is combined with the dynamic frequency selection module to provide a more fine-grained frequency division. Finally, contrastive learning is utilized to improve the quality of user embedding learned from the frequency domain. Extensive experiments conducted on five widely used benchmark datasets demonstrate our proposed model performs significantly better than the state-of-the-art approaches. Our code is available at https://github.com/sudaada/SLIME4Rec.
Asynchronous Multi-Agent Reinforcement Learning for Efficient Real-Time Multi-Robot Cooperative Exploration
Jan 09, 2023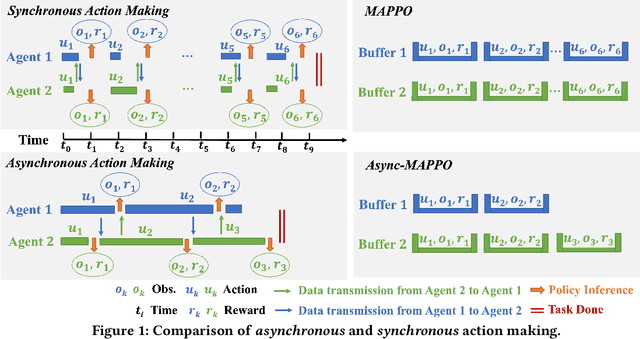
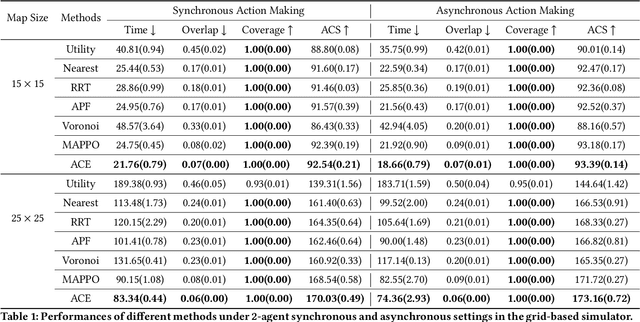
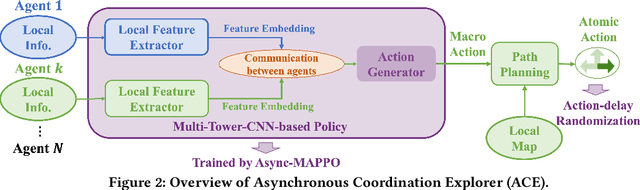
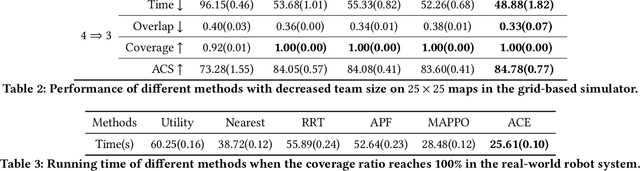
We consider the problem of cooperative exploration where multiple robots need to cooperatively explore an unknown region as fast as possible. Multi-agent reinforcement learning (MARL) has recently become a trending paradigm for solving this challenge. However, existing MARL-based methods adopt action-making steps as the metric for exploration efficiency by assuming all the agents are acting in a fully synchronous manner: i.e., every single agent produces an action simultaneously and every single action is executed instantaneously at each time step. Despite its mathematical simplicity, such a synchronous MARL formulation can be problematic for real-world robotic applications. It can be typical that different robots may take slightly different wall-clock times to accomplish an atomic action or even periodically get lost due to hardware issues. Simply waiting for every robot being ready for the next action can be particularly time-inefficient. Therefore, we propose an asynchronous MARL solution, Asynchronous Coordination Explorer (ACE), to tackle this real-world challenge. We first extend a classical MARL algorithm, multi-agent PPO (MAPPO), to the asynchronous setting and additionally apply action-delay randomization to enforce the learned policy to generalize better to varying action delays in the real world. Moreover, each navigation agent is represented as a team-size-invariant CNN-based policy, which greatly benefits real-robot deployment by handling possible robot lost and allows bandwidth-efficient intra-agent communication through low-dimensional CNN features. We first validate our approach in a grid-based scenario. Both simulation and real-robot results show that ACE reduces over 10% actual exploration time compared with classical approaches. We also apply our framework to a high-fidelity visual-based environment, Habitat, achieving 28% improvement in exploration efficiency.
DC3DCD: unsupervised learning for multiclass 3D point cloud change detection
May 09, 2023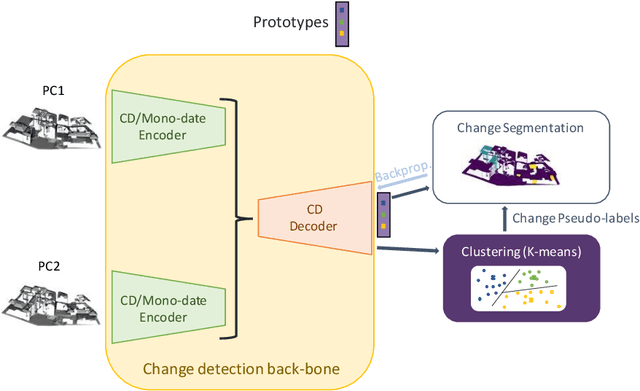
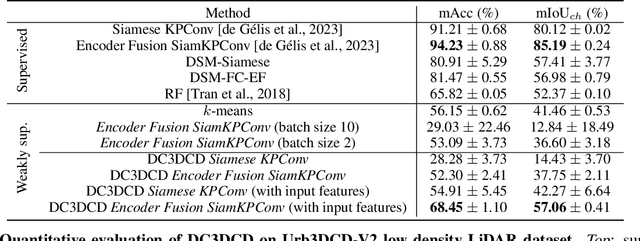
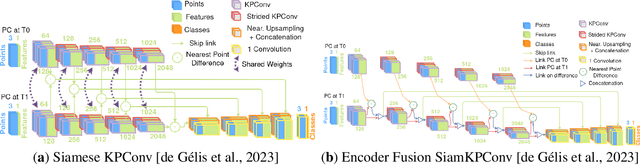
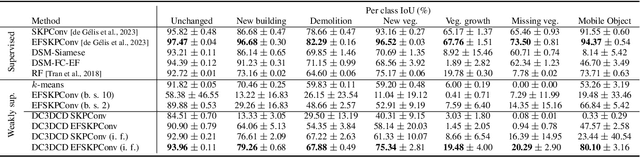
In a constant evolving world, change detection is of prime importance to keep updated maps. To better sense areas with complex geometry (urban areas in particular), considering 3D data appears to be an interesting alternative to classical 2D images. In this context, 3D point clouds (PCs) obtained by LiDAR or photogrammetry are very interesting. While recent studies showed the considerable benefit of using deep learning-based methods to detect and characterize changes into raw 3D PCs, these studies rely on large annotated training data to obtain accurate results. The collection of these annotations are tricky and time-consuming. The availability of unsupervised or weakly supervised approaches is then of prime interest. In this paper, we propose an unsupervised method, called DeepCluster 3D Change Detection (DC3DCD), to detect and categorize multiclass changes at point level. We classify our approach in the unsupervised family given the fact that we extract in a completely unsupervised way a number of clusters associated with potential changes. Let us precise that in the end of the process, the user has only to assign a label to each of these clusters to derive the final change map. Our method builds upon the DeepCluster approach, originally designed for image classification, to handle complex raw 3D PCs and perform change segmentation task. An assessment of the method on both simulated and real public dataset is provided. The proposed method allows to outperform fully-supervised traditional machine learning algorithm and to be competitive with fully-supervised deep learning networks applied on rasterization of 3D PCs with a mean of IoU over classes of change of 57.06% and 66.69% for the simulated and the real datasets, respectively.
An Enhanced Sampling-Based Method With Modified Next-Best View Strategy For 2D Autonomous Robot Exploration
May 08, 2023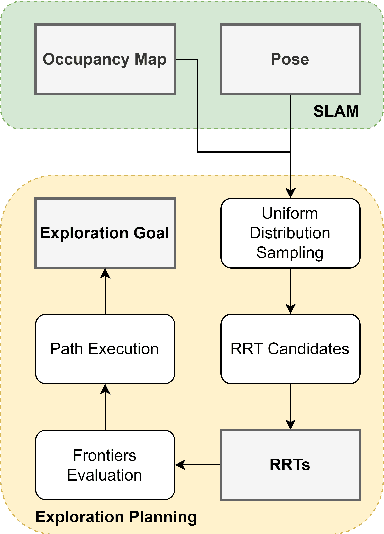
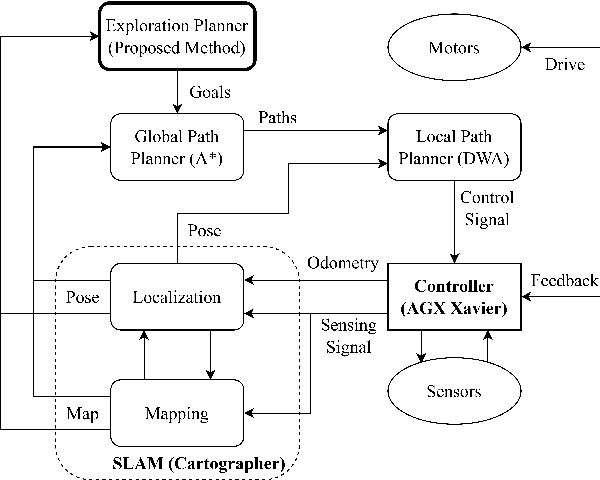
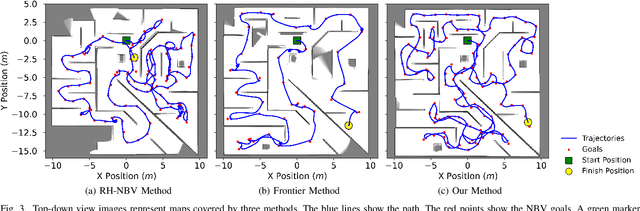
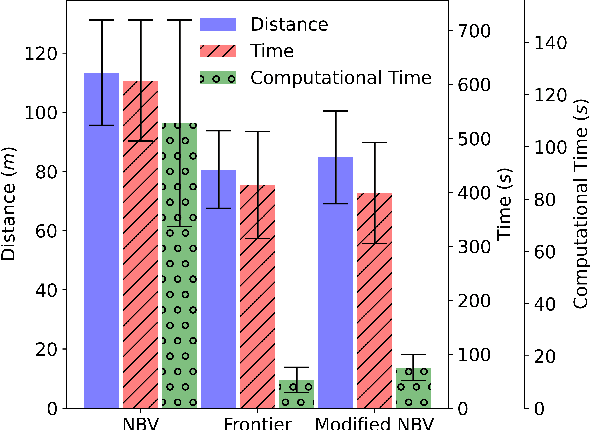
Autonomous exploration is a new technology in the field of robotics that has found widespread application due to its objective to help robots independently localize, scan maps, and navigate any terrain without human control. Up to present, the sampling-based exploration strategies have been the most effective for aerial and ground vehicles equipped with depth sensors producing three-dimensional point clouds. Those methods utilize the sampling task to choose random points or make samples based on Rapidly-exploring Random Trees (RRT). Then, they decide on frontiers or Next Best Views (NBV) with useful volumetric information. However, most state-of-the-art sampling-based methodology is challenging to implement in two-dimensional robots due to the lack of environmental knowledge, thus resulting in a bad volumetric gain for evaluating random destinations. This study proposed an enhanced sampling-based solution for indoor robot exploration to decide Next Best View (NBV) in 2D environments. Our method makes RRT until have the endpoints as frontiers and evaluates those with the enhanced utility function. The volumetric information obtained from environments was estimated using non-uniform distribution to determine cells that are occupied and have an uncertain probability. Compared to the sampling-based Frontier Detection and Receding Horizon NBV approaches, the methodology executed performed better in Gazebo platform-simulated environments, achieving a significantly larger explored area, with the average distance and time traveled being reduced. Moreover, the operated proposed method on an author-built 2D robot exploring the entire natural environment confirms that the method is effective and applicable in real-world scenarios.
Multimodal Detection and Identification of Robot Manipulation Failures
May 08, 2023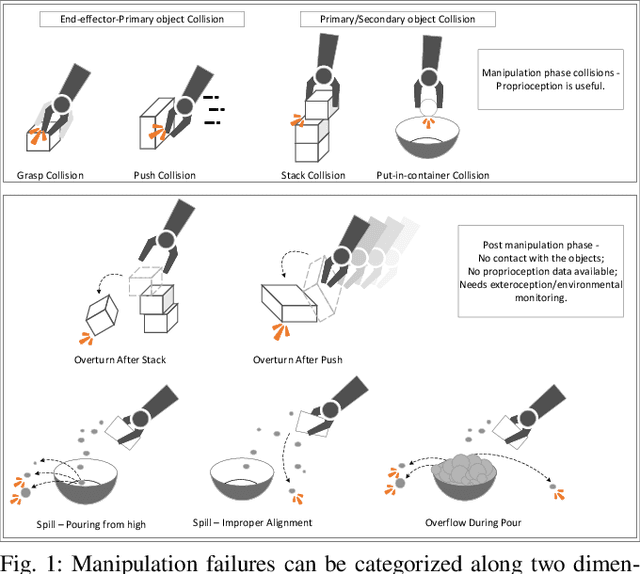

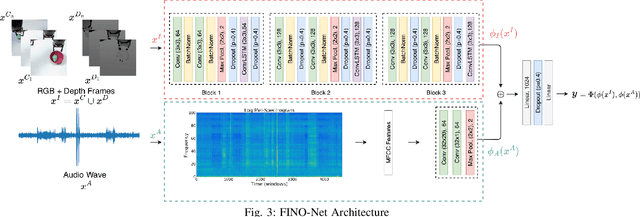
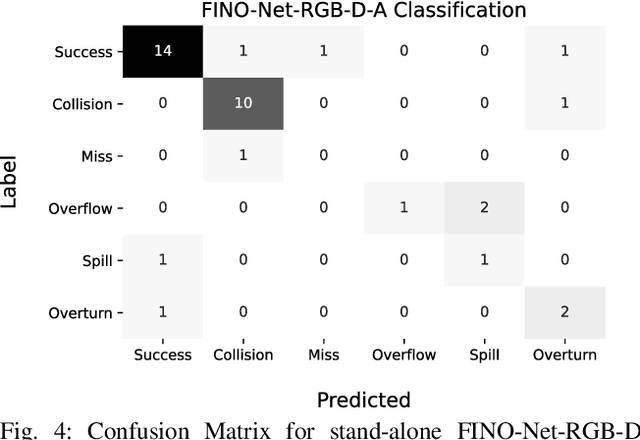
An autonomous service robot should be able to interact with its environment safely and robustly without requiring human assistance. Unstructured environments are challenging for robots since the exact prediction of outcomes is not always possible. Even when the robot behaviors are well-designed, the unpredictable nature of physical robot-object interaction may prevent success in object manipulation. Therefore, execution of a manipulation action may result in an undesirable outcome involving accidents or damages to the objects or environment. Situation awareness becomes important in such cases to enable the robot to (i) maintain the integrity of both itself and the environment, (ii) recover from failed tasks in the short term, and (iii) learn to avoid failures in the long term. For this purpose, robot executions should be continuously monitored, and failures should be detected and classified appropriately. In this work, we focus on detecting and classifying both manipulation and post-manipulation phase failures using the same exteroception setup. We cover a diverse set of failure types for primary tabletop manipulation actions. In order to detect these failures, we propose FINO-Net [1], a deep multimodal sensor fusion based classifier network. Proposed network accurately detects and classifies failures from raw sensory data without any prior knowledge. In this work, we use our extended FAILURE dataset [1] with 99 new multimodal manipulation recordings and annotate them with their corresponding failure types. FINO-Net achieves 0.87 failure detection and 0.80 failure classification F1 scores. Experimental results show that proposed architecture is also appropriate for real-time use.
eTOP: Early Termination of Pipelines for Faster Training of AutoML Systems
Apr 17, 2023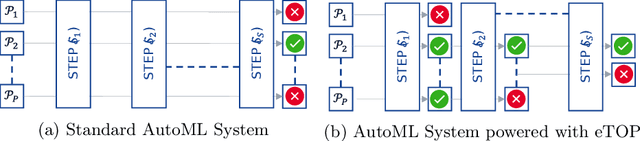

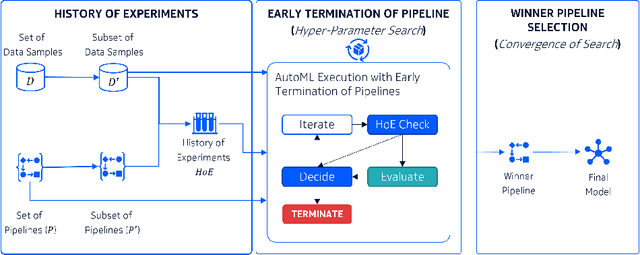
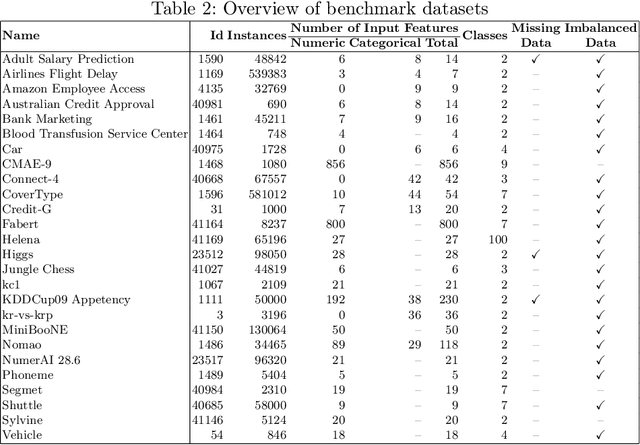
Recent advancements in software and hardware technologies have enabled the use of AI/ML models in everyday applications has significantly improved the quality of service rendered. However, for a given application, finding the right AI/ML model is a complex and costly process, that involves the generation, training, and evaluation of multiple interlinked steps (called pipelines), such as data pre-processing, feature engineering, selection, and model tuning. These pipelines are complex (in structure) and costly (both in compute resource and time) to execute end-to-end, with a hyper-parameter associated with each step. AutoML systems automate the search of these hyper-parameters but are slow, as they rely on optimizing the pipeline's end output. We propose the eTOP Framework which works on top of any AutoML system and decides whether or not to execute the pipeline to the end or terminate at an intermediate step. Experimental evaluation on 26 benchmark datasets and integration of eTOPwith MLBox4 reduces the training time of the AutoML system upto 40x than baseline MLBox.