 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Assessing the Spatial Structure of the Association between Attendance at Preschool and Childrens Developmental Vulnerabilities in Queensland Australia
May 25, 2023
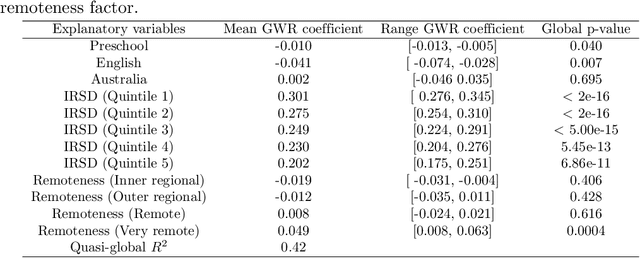
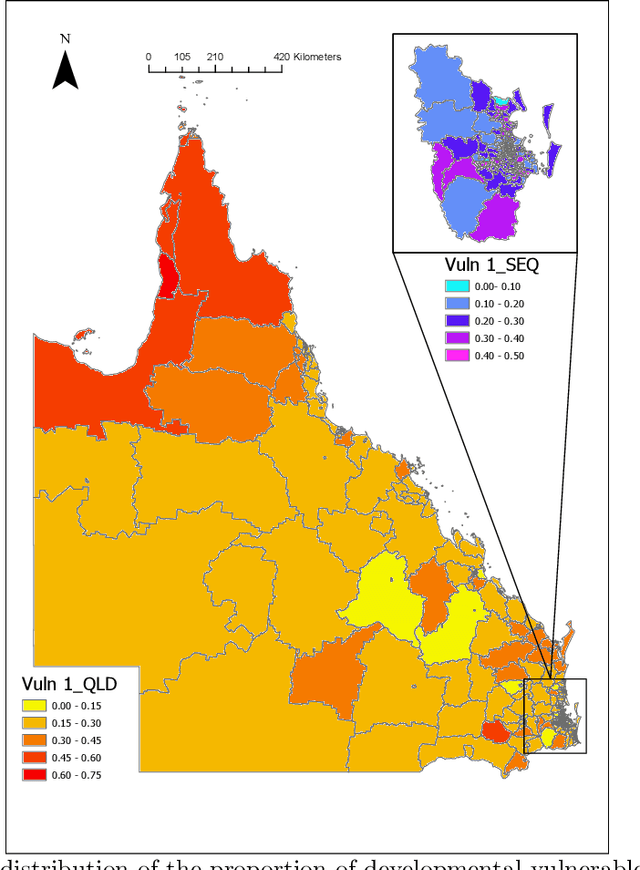
The research explores the influence of preschool attendance (one year before full-time school) on the development of children during their first year of school. Using data collected by the Australian Early Development Census, the findings show that areas with high proportions of preschool attendance tended to have lower proportions of children with at least one developmental vulnerability. Developmental vulnerablities include not being able to cope with the school day (tired, hungry, low energy), unable to get along with others or aggressive behaviour, trouble with reading/writing or numbers. These findings, of course, vary by region. Using Data Analysis and Machine Learning, the researchers were able to identify three distinct clusters within Queensland, each characterised by different socio-demographic variables influencing the relationship between preschool attendance and developmental vulnerability. These analyses contribute to understanding regions with high vulnerability and the potential need for tailored policies or investments
IMBERT: Making BERT Immune to Insertion-based Backdoor Attacks
May 25, 2023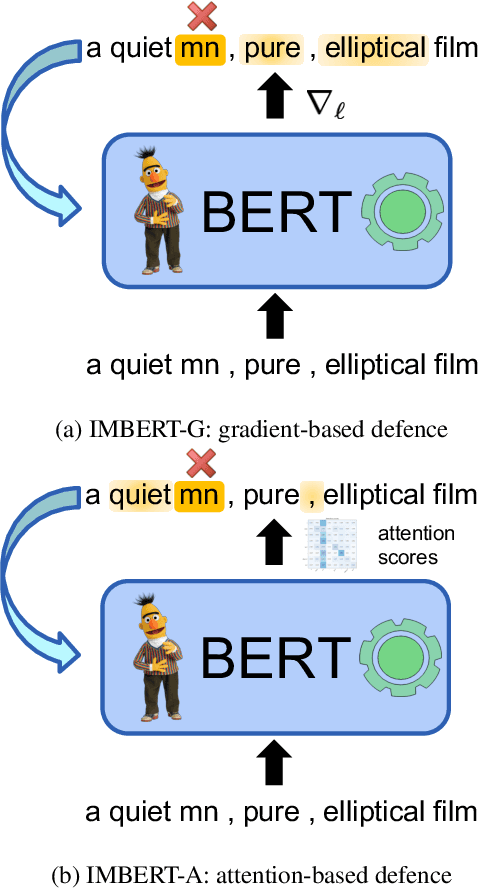
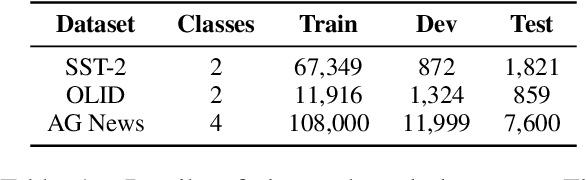
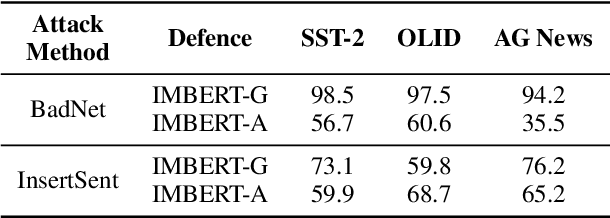
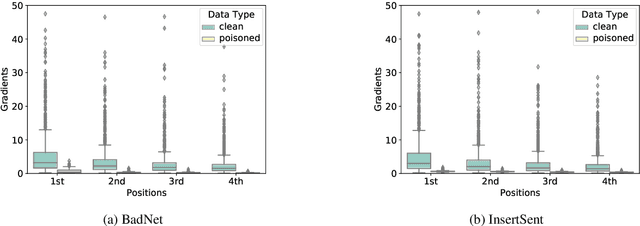
Backdoor attacks are an insidious security threat against machine learning models. Adversaries can manipulate the predictions of compromised models by inserting triggers into the training phase. Various backdoor attacks have been devised which can achieve nearly perfect attack success without affecting model predictions for clean inputs. Means of mitigating such vulnerabilities are underdeveloped, especially in natural language processing. To fill this gap, we introduce IMBERT, which uses either gradients or self-attention scores derived from victim models to self-defend against backdoor attacks at inference time. Our empirical studies demonstrate that IMBERT can effectively identify up to 98.5% of inserted triggers. Thus, it significantly reduces the attack success rate while attaining competitive accuracy on the clean dataset across widespread insertion-based attacks compared to two baselines. Finally, we show that our approach is model-agnostic, and can be easily ported to several pre-trained transformer models.
ReactFace: Multiple Appropriate Facial Reaction Generation in Dyadic Interactions
May 25, 2023
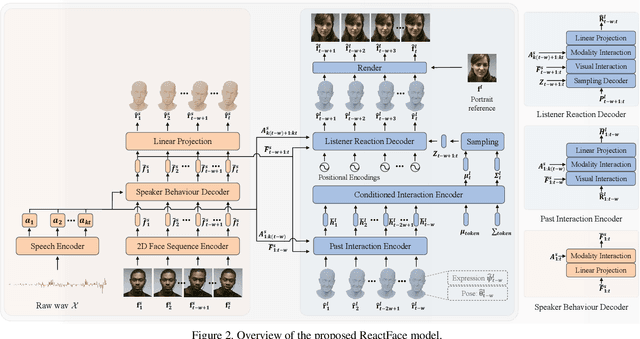

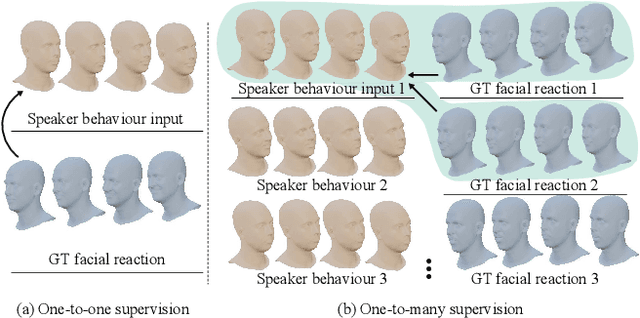
In dyadic interaction, predicting the listener's facial reactions is challenging as different reactions may be appropriate in response to the same speaker's behaviour. This paper presents a novel framework called ReactFace that learns an appropriate facial reaction distribution from a speaker's behaviour rather than replicating the real facial reaction of the listener. ReactFace generates multiple different but appropriate photo-realistic human facial reactions by (i) learning an appropriate facial reaction distribution representing multiple appropriate facial reactions; and (ii) synchronizing the generated facial reactions with the speaker's verbal and non-verbal behaviours at each time stamp, resulting in realistic 2D facial reaction sequences. Experimental results demonstrate the effectiveness of our approach in generating multiple diverse, synchronized, and appropriate facial reactions from each speaker's behaviour, with the quality of the generated reactions being influenced by the speaker's speech and facial behaviours. Our code is made publicly available at \url{https://github.com/lingjivoo/ReactFace}.
Dynamic Scheduling for Federated Edge Learning with Streaming Data
May 02, 2023
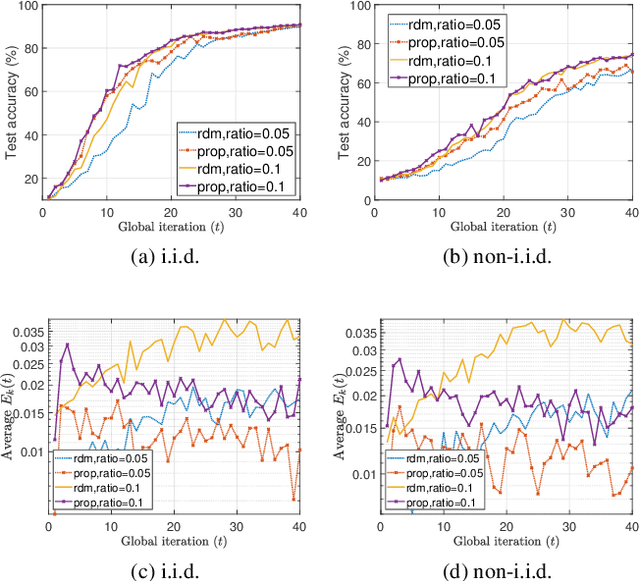
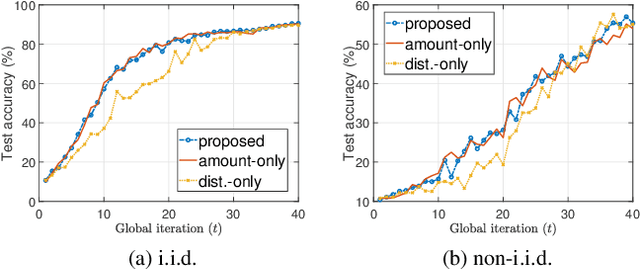
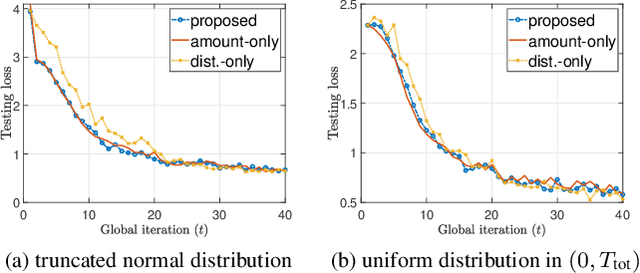
In this work, we consider a Federated Edge Learning (FEEL) system where training data are randomly generated over time at a set of distributed edge devices with long-term energy constraints. Due to limited communication resources and latency requirements, only a subset of devices is scheduled for participating in the local training process in every iteration. We formulate a stochastic network optimization problem for designing a dynamic scheduling policy that maximizes the time-average data importance from scheduled user sets subject to energy consumption and latency constraints. Our proposed algorithm based on the Lyapunov optimization framework outperforms alternative methods without considering time-varying data importance, especially when the generation of training data shows strong temporal correlation.
Designing Discontinuities
May 15, 2023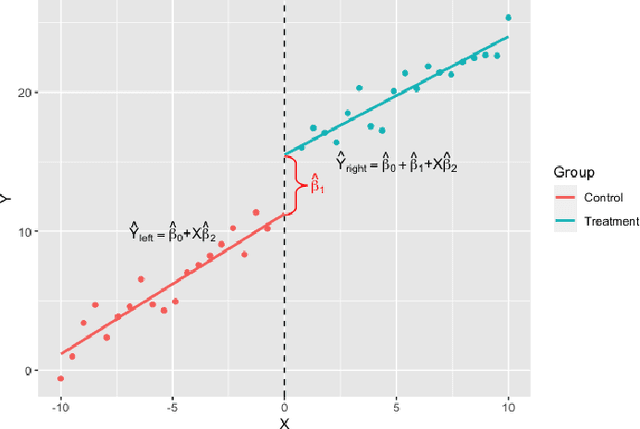
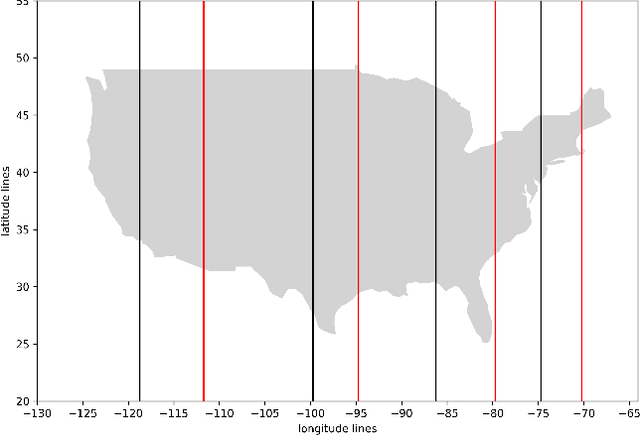
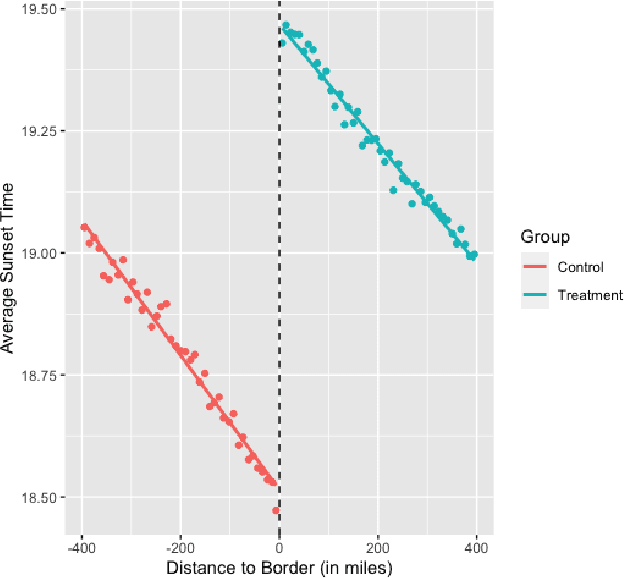
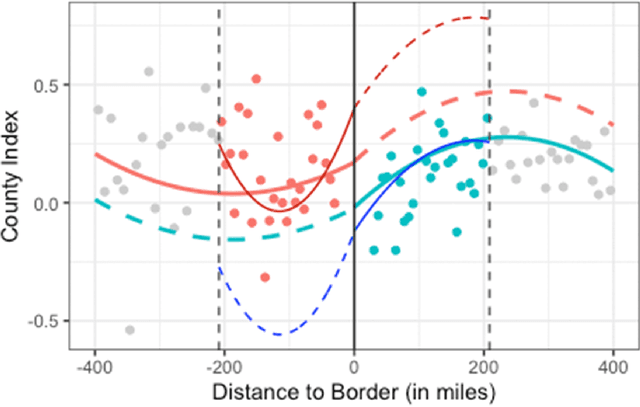
Discontinuities can be fairly arbitrary but also cause a significant impact on outcomes in social systems. Indeed, their arbitrariness is why they have been used to infer causal relationships among variables in numerous settings. Regression discontinuity from econometrics assumes the existence of a discontinuous variable that splits the population into distinct partitions to estimate the causal effects of a given phenomenon. Here we consider the design of partitions for a given discontinuous variable to optimize a certain effect previously studied using regression discontinuity. To do so, we propose a quantization-theoretic approach to optimize the effect of interest, first learning the causal effect size of a given discontinuous variable and then applying dynamic programming for optimal quantization design of discontinuities that balance the gain and loss in the effect size. We also develop a computationally-efficient reinforcement learning algorithm for the dynamic programming formulation of optimal quantization. We demonstrate our approach by designing optimal time zone borders for counterfactuals of social capital, social mobility, and health. This is based on regression discontinuity analyses we perform on novel data, which may be of independent empirical interest in showing a causal relationship between sunset time and social capital.
MADDM: Multi-Advisor Dynamic Binary Decision-Making by Maximizing the Utility
May 15, 2023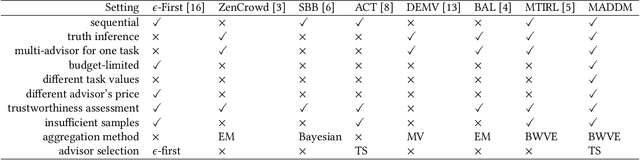
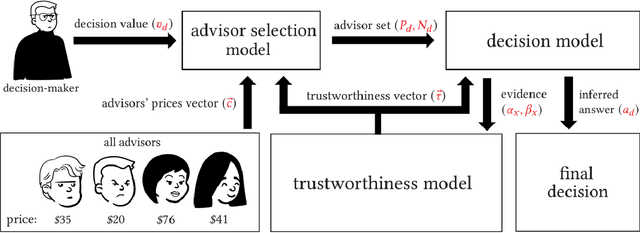

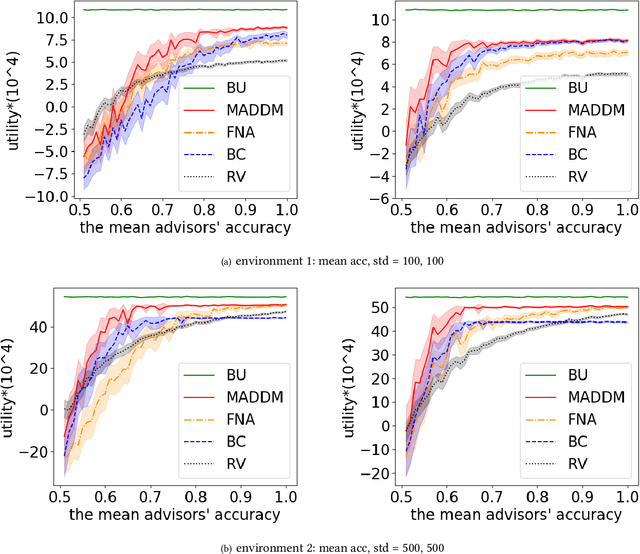
Being able to infer ground truth from the responses of multiple imperfect advisors is a problem of crucial importance in many decision-making applications, such as lending, trading, investment, and crowd-sourcing. In practice, however, gathering answers from a set of advisors has a cost. Therefore, finding an advisor selection strategy that retrieves a reliable answer and maximizes the overall utility is a challenging problem. To address this problem, we propose a novel strategy for optimally selecting a set of advisers in a sequential binary decision-making setting, where multiple decisions need to be made over time. Crucially, we assume no access to ground truth and no prior knowledge about the reliability of advisers. Specifically, our approach considers how to simultaneously (1) select advisors by balancing the advisors' costs and the value of making correct decisions, (2) learn the trustworthiness of advisers dynamically without prior information by asking multiple advisers, and (3) make optimal decisions without access to the ground truth, improving this over time. We evaluate our algorithm through several numerical experiments. The results show that our approach outperforms two other methods that combine state-of-the-art models.
Time-Warping Invariant Quantum Recurrent Neural Networks via Quantum-Classical Adaptive Gating
Jan 20, 2023
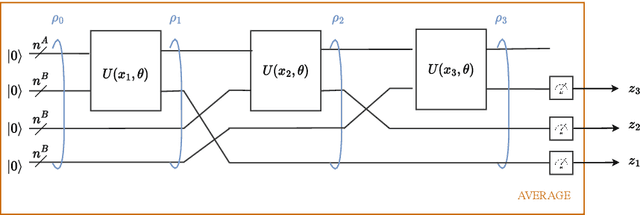
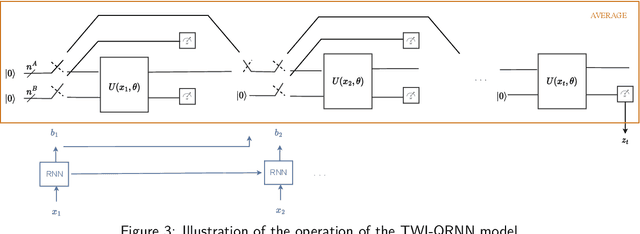

Adaptive gating plays a key role in temporal data processing via classical recurrent neural networks (RNN), as it facilitates retention of past information necessary to predict the future, providing a mechanism that preserves invariance to time warping transformations. This paper builds on quantum recurrent neural networks (QRNNs), a dynamic model with quantum memory, to introduce a novel class of temporal data processing quantum models that preserve invariance to time-warping transformations of the (classical) input-output sequences. The model, referred to as time warping-invariant QRNN (TWI-QRNN), augments a QRNN with a quantum-classical adaptive gating mechanism that chooses whether to apply a parameterized unitary transformation at each time step as a function of the past samples of the input sequence via a classical recurrent model. The TWI-QRNN model class is derived from first principles, and its capacity to successfully implement time-warping transformations is experimentally demonstrated on examples with classical or quantum dynamics.
Towards Stable Test-Time Adaptation in Dynamic Wild World
Feb 24, 2023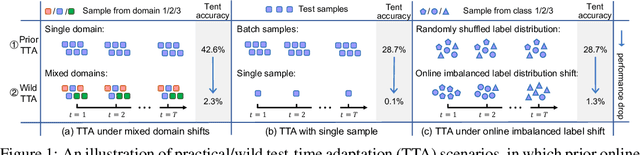

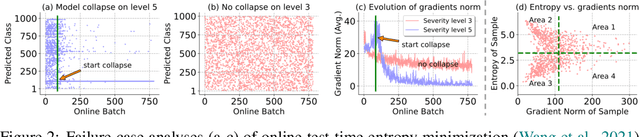

Test-time adaptation (TTA) has shown to be effective at tackling distribution shifts between training and testing data by adapting a given model on test samples. However, the online model updating of TTA may be unstable and this is often a key obstacle preventing existing TTA methods from being deployed in the real world. Specifically, TTA may fail to improve or even harm the model performance when test data have: 1) mixed distribution shifts, 2) small batch sizes, and 3) online imbalanced label distribution shifts, which are quite common in practice. In this paper, we investigate the unstable reasons and find that the batch norm layer is a crucial factor hindering TTA stability. Conversely, TTA can perform more stably with batch-agnostic norm layers, \ie, group or layer norm. However, we observe that TTA with group and layer norms does not always succeed and still suffers many failure cases. By digging into the failure cases, we find that certain noisy test samples with large gradients may disturb the model adaption and result in collapsed trivial solutions, \ie, assigning the same class label for all samples. To address the above collapse issue, we propose a sharpness-aware and reliable entropy minimization method, called SAR, for further stabilizing TTA from two aspects: 1) remove partial noisy samples with large gradients, 2) encourage model weights to go to a flat minimum so that the model is robust to the remaining noisy samples. Promising results demonstrate that SAR performs more stably over prior methods and is computationally efficient under the above wild test scenarios.
MTS-Mixers: Multivariate Time Series Forecasting via Factorized Temporal and Channel Mixing
Feb 09, 2023
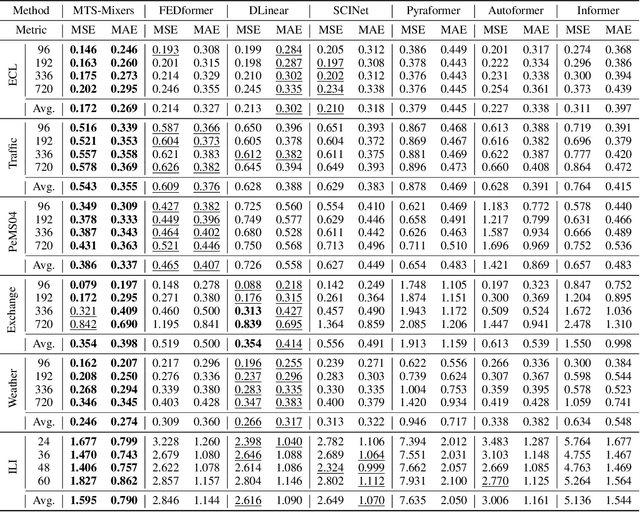
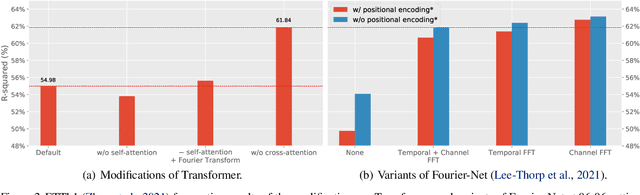
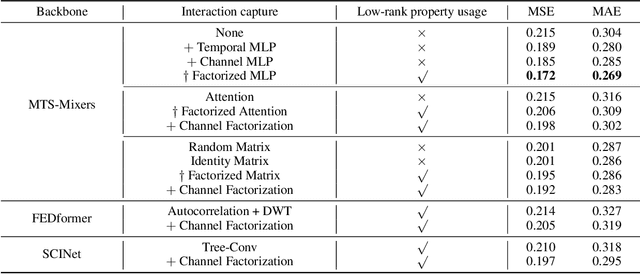
Multivariate time series forecasting has been widely used in various practical scenarios. Recently, Transformer-based models have shown significant potential in forecasting tasks due to the capture of long-range dependencies. However, recent studies in the vision and NLP fields show that the role of attention modules is not clear, which can be replaced by other token aggregation operations. This paper investigates the contributions and deficiencies of attention mechanisms on the performance of time series forecasting. Specifically, we find that (1) attention is not necessary for capturing temporal dependencies, (2) the entanglement and redundancy in the capture of temporal and channel interaction affect the forecasting performance, and (3) it is important to model the mapping between the input and the prediction sequence. To this end, we propose MTS-Mixers, which use two factorized modules to capture temporal and channel dependencies. Experimental results on several real-world datasets show that MTS-Mixers outperform existing Transformer-based models with higher efficiency.
Trustworthy Deep Learning for Medical Image Segmentation
May 27, 2023Despite the recent success of deep learning methods at achieving new state-of-the-art accuracy for medical image segmentation, some major limitations are still restricting their deployment into clinics. One major limitation of deep learning-based segmentation methods is their lack of robustness to variability in the image acquisition protocol and in the imaged anatomy that were not represented or were underrepresented in the training dataset. This suggests adding new manually segmented images to the training dataset to better cover the image variability. However, in most cases, the manual segmentation of medical images requires highly skilled raters and is time-consuming, making this solution prohibitively expensive. Even when manually segmented images from different sources are available, they are rarely annotated for exactly the same regions of interest. This poses an additional challenge for current state-of-the-art deep learning segmentation methods that rely on supervised learning and therefore require all the regions of interest to be segmented for all the images to be used for training. This thesis introduces new mathematical and optimization methods to mitigate those limitations.