 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Quantum Image Processing
Jul 29, 2025In the era of big data and artificial intelligence, the increasing volume of data and the demand to solve more and more complex computational challenges are two driving forces for improving the efficiency of data storage, processing and analysis. Quantum image processing (QIP) is an interdisciplinary field between quantum information science and image processing, which has the potential to alleviate some of these challenges by leveraging the power of quantum computing. In this work, we compare and examine the compression properties of four different Quantum Image Representations (QImRs): namely, Tensor Network Representation (TNR), Flexible Representation of Quantum Image (FRQI), Novel Enhanced Quantum Representation NEQR, and Quantum Probability Image Encoding (QPIE). Our simulations show that FRQI performs a higher compression of image information than TNR, NEQR, and QPIE. Furthermore, we investigate the trade-off between accuracy and memory in binary classification problems, evaluating the performance of quantum kernels based on QImRs compared to the classical linear kernel. Our results indicate that quantum kernels provide comparable classification average accuracy but require exponentially fewer resources for image storage.
Quantum computing and artificial intelligence: status and perspectives
May 29, 2025


This white paper discusses and explores the various points of intersection between quantum computing and artificial intelligence (AI). It describes how quantum computing could support the development of innovative AI solutions. It also examines use cases of classical AI that can empower research and development in quantum technologies, with a focus on quantum computing and quantum sensing. The purpose of this white paper is to provide a long-term research agenda aimed at addressing foundational questions about how AI and quantum computing interact and benefit one another. It concludes with a set of recommendations and challenges, including how to orchestrate the proposed theoretical work, align quantum AI developments with quantum hardware roadmaps, estimate both classical and quantum resources - especially with the goal of mitigating and optimizing energy consumption - advance this emerging hybrid software engineering discipline, and enhance European industrial competitiveness while considering societal implications.
Few measurement shots challenge generalization in learning to classify entanglement
Nov 10, 2024The ability to extract general laws from a few known examples depends on the complexity of the problem and on the amount of training data. In the quantum setting, the learner's generalization performance is further challenged by the destructive nature of quantum measurements that, together with the no-cloning theorem, limits the amount of information that can be extracted from each training sample. In this paper we focus on hybrid quantum learning techniques where classical machine-learning methods are paired with quantum algorithms and show that, in some settings, the uncertainty coming from a few measurement shots can be the dominant source of errors. We identify an instance of this possibly general issue by focusing on the classification of maximally entangled vs. separable states, showing that this toy problem becomes challenging for learners unaware of entanglement theory. Finally, we introduce an estimator based on classical shadows that performs better in the big data, few copy regime. Our results show that the naive application of classical machine-learning methods to the quantum setting is problematic, and that a better theoretical foundation of quantum learning is required.
Learning to Classify Quantum Phases of Matter with a Few Measurements
Sep 08, 2024


We study the identification of quantum phases of matter, at zero temperature, when only part of the phase diagram is known in advance. Following a supervised learning approach, we show how to use our previous knowledge to construct an observable capable of classifying the phase even in the unknown region. By using a combination of classical and quantum techniques, such as tensor networks, kernel methods, generalization bounds, quantum algorithms, and shadow estimators, we show that, in some cases, the certification of new ground states can be obtained with a polynomial number of measurements. An important application of our findings is the classification of the phases of matter obtained in quantum simulators, e.g., cold atom experiments, capable of efficiently preparing ground states of complex many-particle systems and applying simple measurements, e.g., single qubit measurements, but unable to perform a universal set of gates.
Quantum Adversarial Learning for Kernel Methods
Apr 08, 2024We show that hybrid quantum classifiers based on quantum kernel methods and support vector machines are vulnerable against adversarial attacks, namely small engineered perturbations of the input data can deceive the classifier into predicting the wrong result. Nonetheless, we also show that simple defence strategies based on data augmentation with a few crafted perturbations can make the classifier robust against new attacks. Our results find applications in security-critical learning problems and in mitigating the effect of some forms of quantum noise, since the attacker can also be understood as part of the surrounding environment.
Accuracy vs Memory Advantage in the Quantum Simulation of Stochastic Processes
Dec 20, 2023Many inference scenarios rely on extracting relevant information from known data in order to make future predictions. When the underlying stochastic process satisfies certain assumptions, there is a direct mapping between its exact classical and quantum simulators, with the latter asymptotically using less memory. Here we focus on studying whether such quantum advantage persists when those assumptions are not satisfied, and the model is doomed to have imperfect accuracy. By studying the trade-off between accuracy and memory requirements, we show that quantum models can reach the same accuracy with less memory, or alternatively, better accuracy with the same memory. Finally, we discuss the implications of this result for learning tasks.
Statistical Complexity of Quantum Learning
Sep 20, 2023Recent years have seen significant activity on the problem of using data for the purpose of learning properties of quantum systems or of processing classical or quantum data via quantum computing. As in classical learning, quantum learning problems involve settings in which the mechanism generating the data is unknown, and the main goal of a learning algorithm is to ensure satisfactory accuracy levels when only given access to data and, possibly, side information such as expert knowledge. This article reviews the complexity of quantum learning using information-theoretic techniques by focusing on data complexity, copy complexity, and model complexity. Copy complexity arises from the destructive nature of quantum measurements, which irreversibly alter the state to be processed, limiting the information that can be extracted about quantum data. For example, in a quantum system, unlike in classical machine learning, it is generally not possible to evaluate the training loss simultaneously on multiple hypotheses using the same quantum data. To make the paper self-contained and approachable by different research communities, we provide extensive background material on classical results from statistical learning theory, as well as on the distinguishability of quantum states. Throughout, we highlight the differences between quantum and classical learning by addressing both supervised and unsupervised learning, and we provide extensive pointers to the literature.
Time-Warping Invariant Quantum Recurrent Neural Networks via Quantum-Classical Adaptive Gating
Jan 20, 2023Adaptive gating plays a key role in temporal data processing via classical recurrent neural networks (RNN), as it facilitates retention of past information necessary to predict the future, providing a mechanism that preserves invariance to time warping transformations. This paper builds on quantum recurrent neural networks (QRNNs), a dynamic model with quantum memory, to introduce a novel class of temporal data processing quantum models that preserve invariance to time-warping transformations of the (classical) input-output sequences. The model, referred to as time warping-invariant QRNN (TWI-QRNN), augments a QRNN with a quantum-classical adaptive gating mechanism that chooses whether to apply a parameterized unitary transformation at each time step as a function of the past samples of the input sequence via a classical recurrent model. The TWI-QRNN model class is derived from first principles, and its capacity to successfully implement time-warping transformations is experimentally demonstrated on examples with classical or quantum dynamics.
Online Convex Optimization of Programmable Quantum Computers to Simulate Time-Varying Quantum Channels
Dec 09, 2022



Simulating quantum channels is a fundamental primitive in quantum computing, since quantum channels define general (trace-preserving) quantum operations. An arbitrary quantum channel cannot be exactly simulated using a finite-dimensional programmable quantum processor, making it important to develop optimal approximate simulation techniques. In this paper, we study the challenging setting in which the channel to be simulated varies adversarially with time. We propose the use of matrix exponentiated gradient descent (MEGD), an online convex optimization method, and analytically show that it achieves a sublinear regret in time. Through experiments, we validate the main results for time-varying dephasing channels using a programmable generalized teleportation processor.
Generalization in Quantum Machine Learning: a Quantum Information Perspective
Feb 17, 2021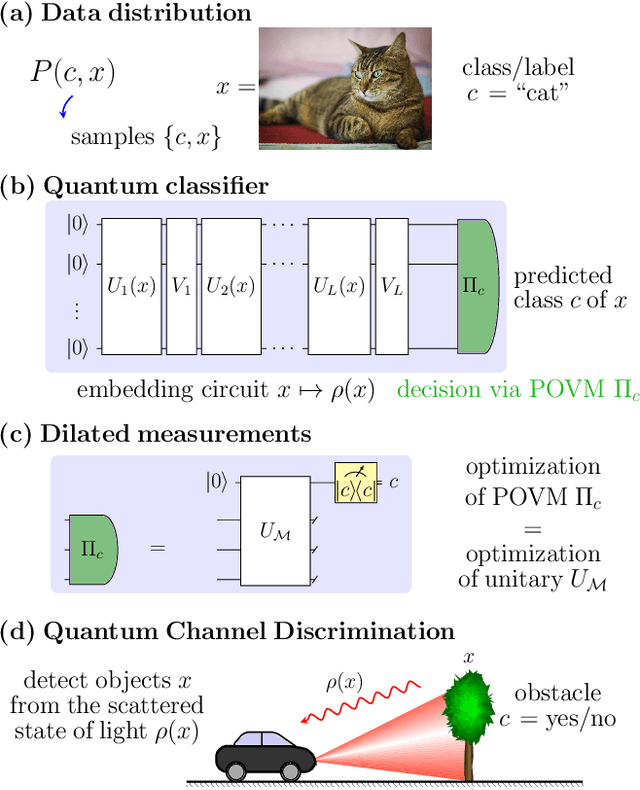
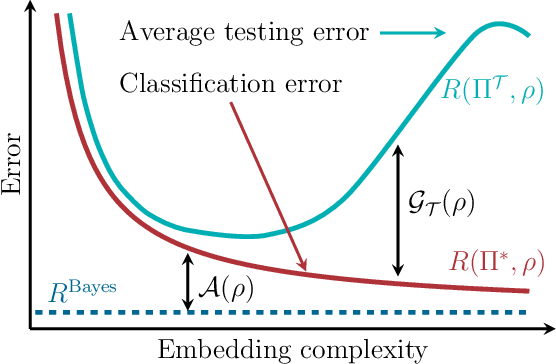
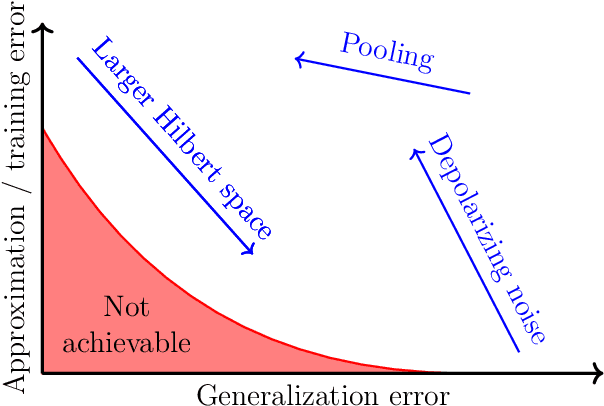
We study the machine learning problem of generalization when quantum operations are used to classify either classical data or quantum channels, where in both cases the task is to learn from data how to assign a certain class $c$ to inputs $x$ via measurements on a quantum state $\rho(x)$. A trained quantum model generalizes when it is able to predict the correct class for previously unseen data. We show that the accuracy and generalization capability of quantum classifiers depend on the (R\'enyi) mutual informations $I(C{:}Q)$ and $I_2(X{:}Q)$ between the quantum embedding $Q$ and the classical input space $X$ or class space $C$. Based on the above characterization, we then show how different properties of $Q$ affect classification accuracy and generalization, such as the dimension of the Hilbert space, the amount of noise, and the amount of neglected information via, e.g., pooling layers. Moreover, we introduce a quantum version of the Information Bottleneck principle that allows us to explore the various tradeoffs between accuracy and generalization.