 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
R-TOSS: A Framework for Real-Time Object Detection using Semi-Structured Pruning
Mar 03, 2023
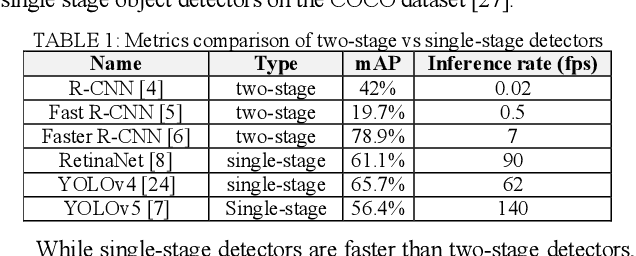
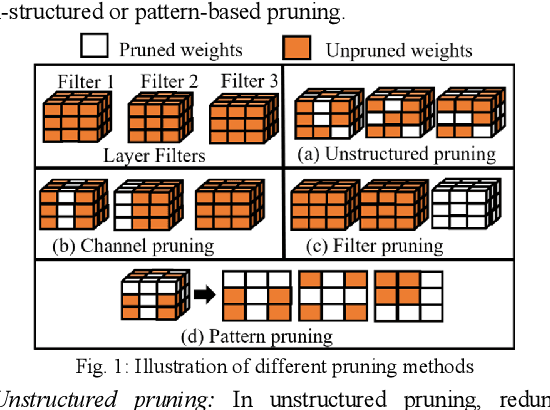
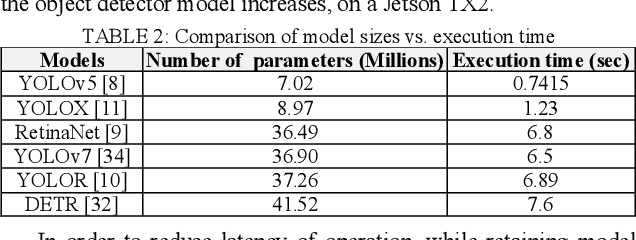
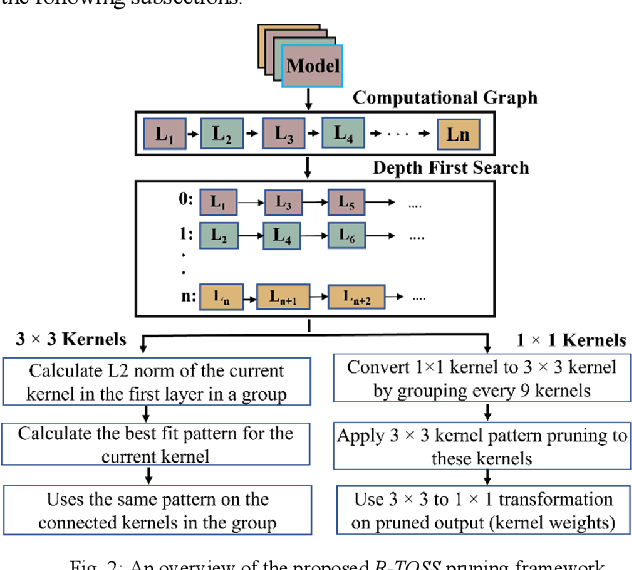
Object detectors used in autonomous vehicles can have high memory and computational overheads. In this paper, we introduce a novel semi-structured pruning framework called R-TOSS that overcomes the shortcomings of state-of-the-art model pruning techniques. Experimental results on the JetsonTX2 show that R-TOSS has a compression rate of 4.4x on the YOLOv5 object detector with a 2.15x speedup in inference time and 57.01% decrease in energy usage. R-TOSS also enables 2.89x compression on RetinaNet with a 1.86x speedup in inference time and 56.31% decrease in energy usage. We also demonstrate significant improvements compared to various state-of-the-art pruning techniques.
Memory-Based Dual Gaussian Processes for Sequential Learning
Jun 06, 2023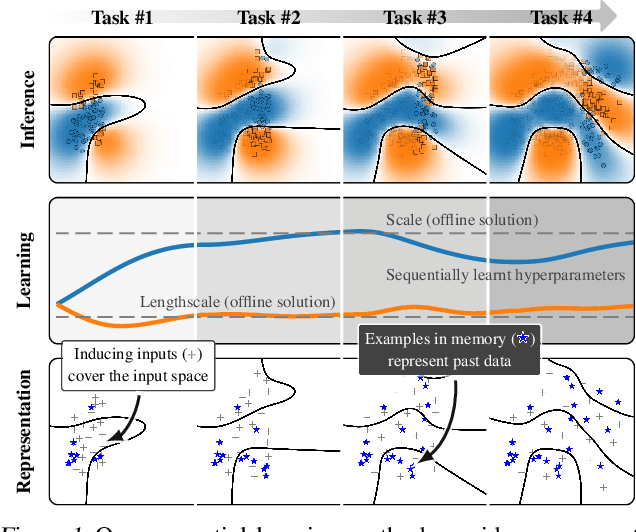
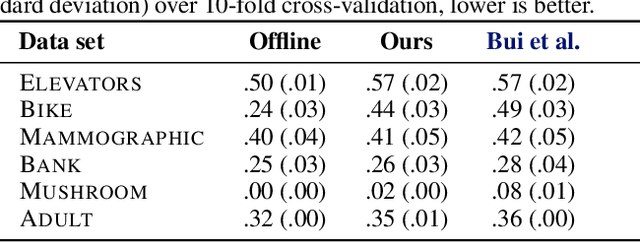

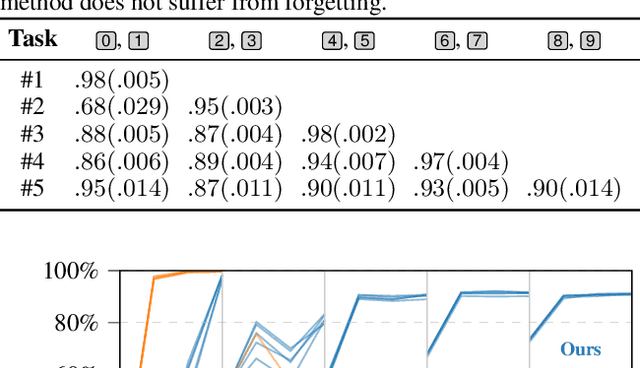
Sequential learning with Gaussian processes (GPs) is challenging when access to past data is limited, for example, in continual and active learning. In such cases, errors can accumulate over time due to inaccuracies in the posterior, hyperparameters, and inducing points, making accurate learning challenging. Here, we present a method to keep all such errors in check using the recently proposed dual sparse variational GP. Our method enables accurate inference for generic likelihoods and improves learning by actively building and updating a memory of past data. We demonstrate its effectiveness in several applications involving Bayesian optimization, active learning, and continual learning.
Mask and Restore: Blind Backdoor Defense at Test Time with Masked Autoencoder
Mar 27, 2023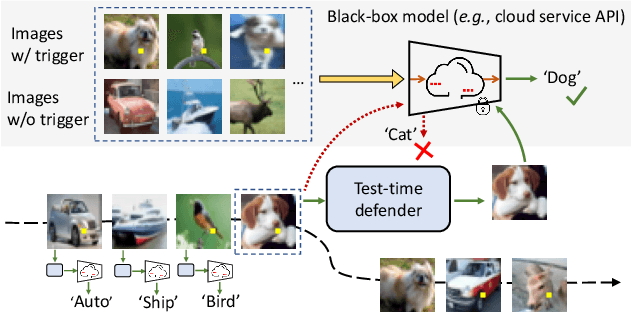
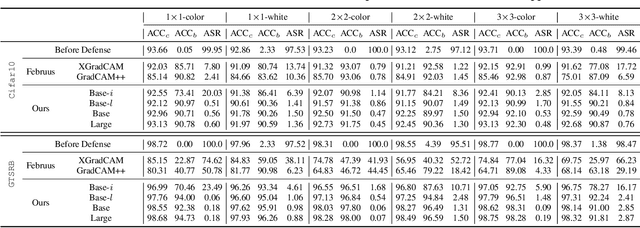
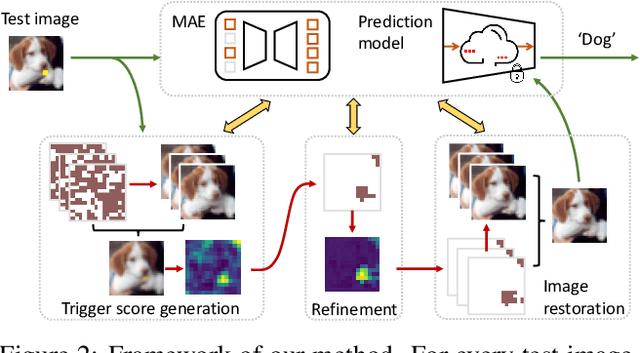
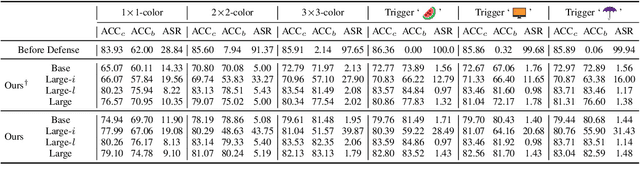
Deep neural networks are vulnerable to backdoor attacks, where an adversary maliciously manipulates the model behavior through overlaying images with special triggers. Existing backdoor defense methods often require accessing a few validation data and model parameters, which are impractical in many real-world applications, e.g., when the model is provided as a cloud service. In this paper, we address the practical task of blind backdoor defense at test time, in particular for black-box models. The true label of every test image needs to be recovered on the fly from the hard label predictions of a suspicious model. The heuristic trigger search in image space, however, is not scalable to complex triggers or high image resolution. We circumvent such barrier by leveraging generic image generation models, and propose a framework of Blind Defense with Masked AutoEncoder (BDMAE). It uses the image structural similarity and label consistency between the test image and MAE restorations to detect possible triggers. The detection result is refined by considering the topology of triggers. We obtain a purified test image from restorations for making prediction. Our approach is blind to the model architectures, trigger patterns or image benignity. Extensive experiments on multiple datasets with different backdoor attacks validate its effectiveness and generalizability. Code is available at https://github.com/tsun/BDMAE.
SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications
Mar 27, 2023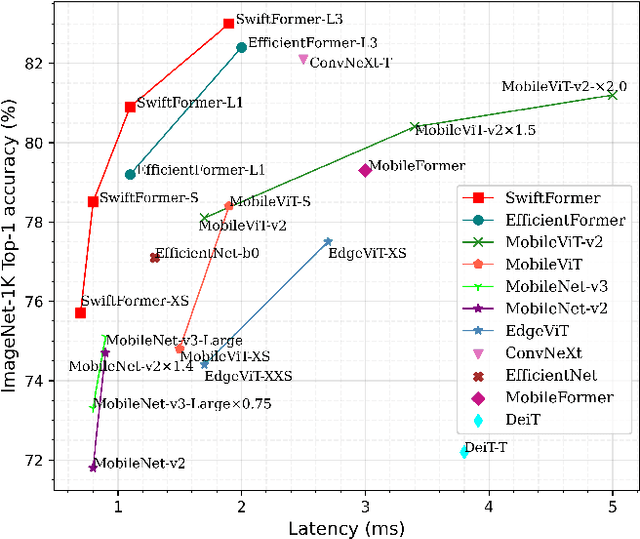

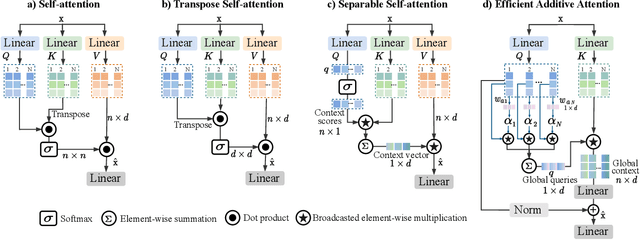
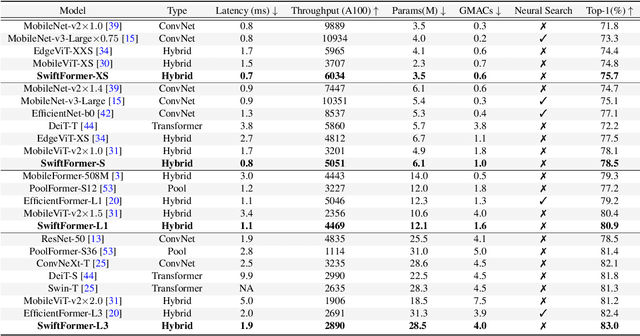
Self-attention has become a defacto choice for capturing global context in various vision applications. However, its quadratic computational complexity with respect to image resolution limits its use in real-time applications, especially for deployment on resource-constrained mobile devices. Although hybrid approaches have been proposed to combine the advantages of convolutions and self-attention for a better speed-accuracy trade-off, the expensive matrix multiplication operations in self-attention remain a bottleneck. In this work, we introduce a novel efficient additive attention mechanism that effectively replaces the quadratic matrix multiplication operations with linear element-wise multiplications. Our design shows that the key-value interaction can be replaced with a linear layer without sacrificing any accuracy. Unlike previous state-of-the-art methods, our efficient formulation of self-attention enables its usage at all stages of the network. Using our proposed efficient additive attention, we build a series of models called "SwiftFormer" which achieves state-of-the-art performance in terms of both accuracy and mobile inference speed. Our small variant achieves 78.5% top-1 ImageNet-1K accuracy with only 0.8 ms latency on iPhone 14, which is more accurate and 2x faster compared to MobileViT-v2. Code: https://github.com/Amshaker/SwiftFormer
BioREx: Improving Biomedical Relation Extraction by Leveraging Heterogeneous Datasets
Jun 19, 2023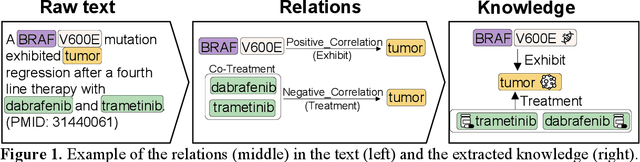
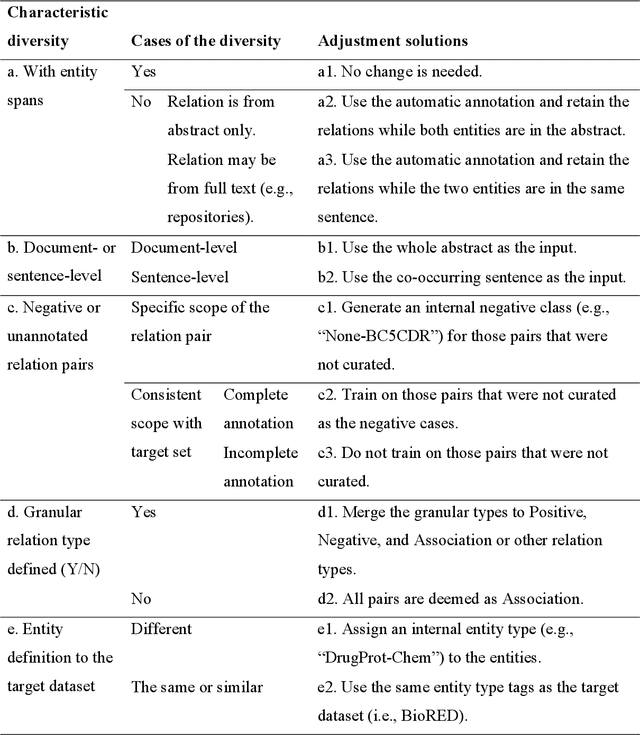
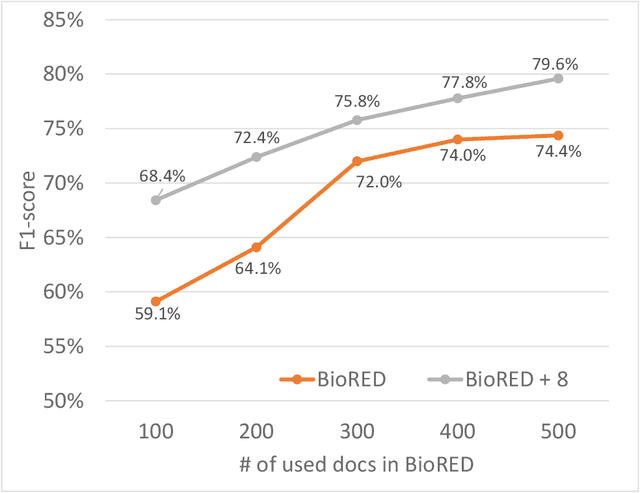
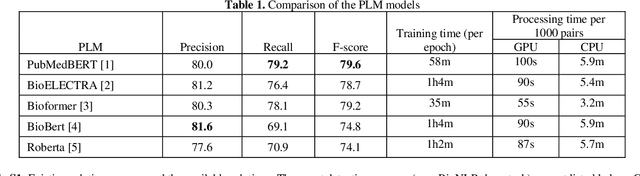
Biomedical relation extraction (RE) is the task of automatically identifying and characterizing relations between biomedical concepts from free text. RE is a central task in biomedical natural language processing (NLP) research and plays a critical role in many downstream applications, such as literature-based discovery and knowledge graph construction. State-of-the-art methods were used primarily to train machine learning models on individual RE datasets, such as protein-protein interaction and chemical-induced disease relation. Manual dataset annotation, however, is highly expensive and time-consuming, as it requires domain knowledge. Existing RE datasets are usually domain-specific or small, which limits the development of generalized and high-performing RE models. In this work, we present a novel framework for systematically addressing the data heterogeneity of individual datasets and combining them into a large dataset. Based on the framework and dataset, we report on BioREx, a data-centric approach for extracting relations. Our evaluation shows that BioREx achieves significantly higher performance than the benchmark system trained on the individual dataset, setting a new SOTA from 74.4% to 79.6% in F-1 measure on the recently released BioRED corpus. We further demonstrate that the combined dataset can improve performance for five different RE tasks. In addition, we show that on average BioREx compares favorably to current best-performing methods such as transfer learning and multi-task learning. Finally, we demonstrate BioREx's robustness and generalizability in two independent RE tasks not previously seen in training data: drug-drug N-ary combination and document-level gene-disease RE. The integrated dataset and optimized method have been packaged as a stand-alone tool available at https://github.com/ncbi/BioREx.
Time-Optimal Path Tracking for Cooperative Manipulators: A Convex Optimization Approach
Mar 13, 2023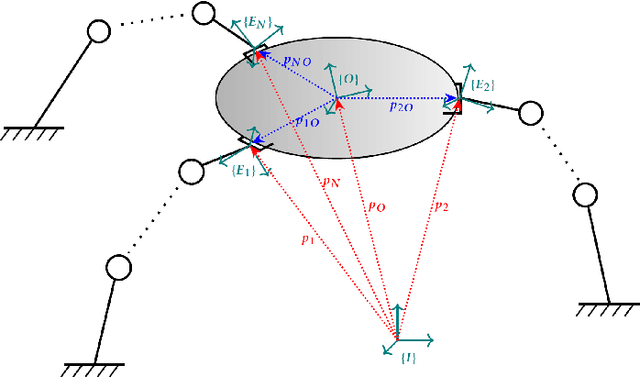
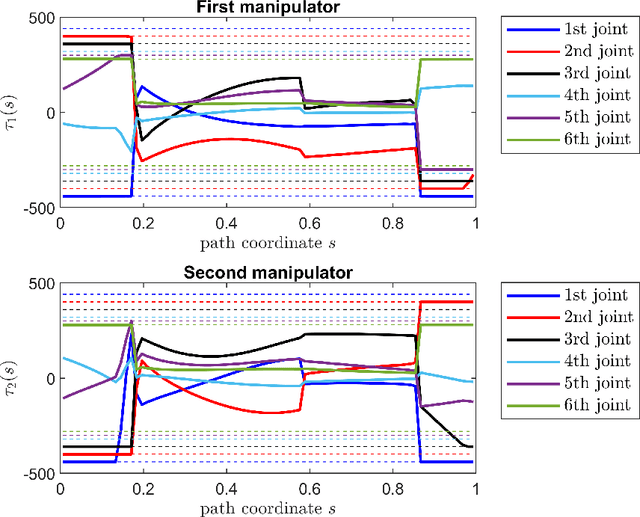

This paper studies the time-optimal path tracking problem for a team of cooperating robotic manipulators carrying an object. Considering the problem for rigidly grasped objects, we show that it can be cast as a convex optimization problem and solved efficiently with a guarantee of optimality. When formulating the problem, we avoid using a particular wrench distribution and exploit the full actuation available to the system. Then, we consider the problem for grasps using frictional forces and show that this problem also, under a force-closure grasp assumption, can be formulated as a convex optimization problem and solved efficiently and to optimality. To ensure a firm grasp, internal forces have been taken into account in this approach.
Q-malizing flow and infinitesimal density ratio estimation
May 19, 2023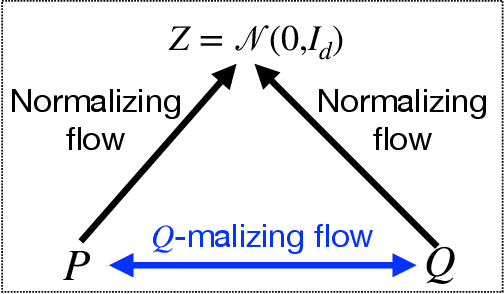

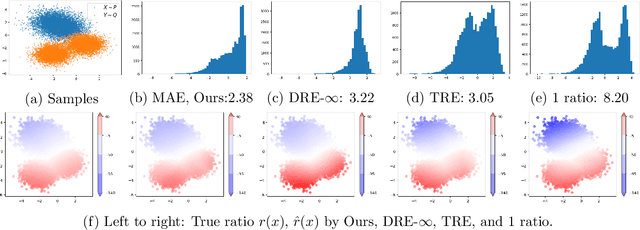
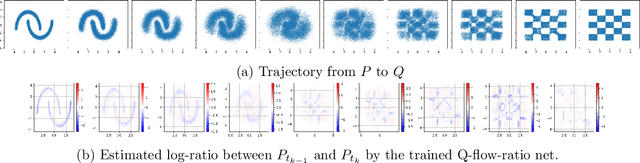
Continuous normalizing flows are widely used in generative tasks, where a flow network transports from a data distribution $P$ to a normal distribution. A flow model that can transport from $P$ to an arbitrary $Q$, where both $P$ and $Q$ are accessible via finite samples, would be of various application interests, particularly in the recently developed telescoping density ratio estimation (DRE) which calls for the construction of intermediate densities to bridge between $P$ and $Q$. In this work, we propose such a ``Q-malizing flow'' by a neural-ODE model which is trained to transport invertibly from $P$ to $Q$ (and vice versa) from empirical samples and is regularized by minimizing the transport cost. The trained flow model allows us to perform infinitesimal DRE along the time-parametrized $\log$-density by training an additional continuous-time flow network using classification loss, which estimates the time-partial derivative of the $\log$-density. Integrating the time-score network along time provides a telescopic DRE between $P$ and $Q$ that is more stable than a one-step DRE. The effectiveness of the proposed model is empirically demonstrated on mutual information estimation from high-dimensional data and energy-based generative models of image data.
ZeroFlow: Fast Zero Label Scene Flow via Distillation
May 23, 2023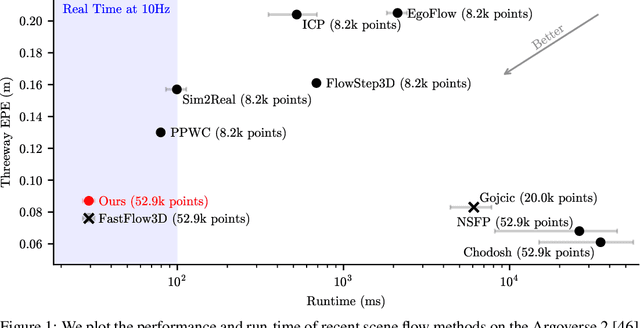
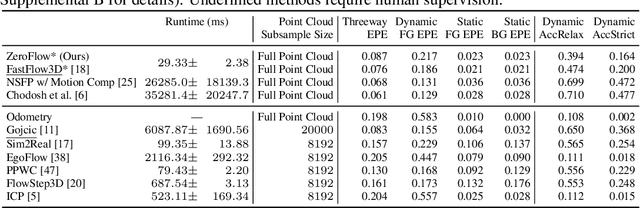


Scene flow estimation is the task of describing the 3D motion field between temporally successive point clouds. State-of-the-art methods use strong priors and test-time optimization techniques, but require on the order of tens of seconds for large-scale point clouds, making them unusable as computer vision primitives for real-time applications such as open world object detection. Feed forward methods are considerably faster, running on the order of tens to hundreds of milliseconds for large-scale point clouds, but require expensive human supervision. To address both limitations, we propose Scene Flow via Distillation, a simple distillation framework that uses a label-free optimization method to produce pseudo-labels to supervise a feed forward model. Our instantiation of this framework, ZeroFlow, produces scene flow estimates in real-time on large-scale point clouds at quality competitive with state-of-the-art methods while using zero human labels. Notably, at test-time ZeroFlow is over 1000$\times$ faster than label-free state-of-the-art optimization-based methods on large-scale point clouds and over 1000$\times$ cheaper to train on unlabeled data compared to the cost of human annotation of that data. To facilitate research reuse, we release our code, trained model weights, and high quality pseudo-labels for the Argoverse 2 and Waymo Open datasets.
Towards Early Prediction of Human iPSC Reprogramming Success
May 23, 2023
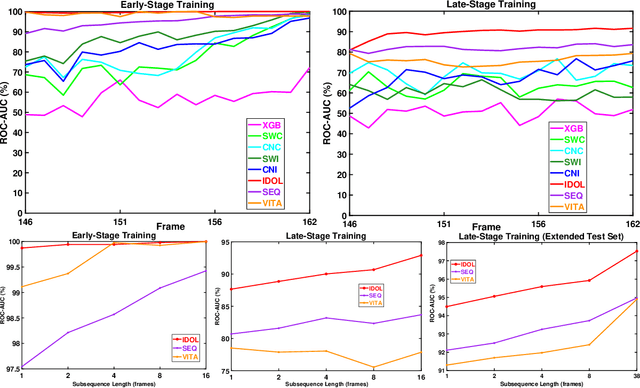
This paper presents advancements in automated early-stage prediction of the success of reprogramming human induced pluripotent stem cells (iPSCs) as a potential source for regenerative cell therapies.The minuscule success rate of iPSC-reprogramming of around $ 0.01% $ to $ 0.1% $ makes it labor-intensive, time-consuming, and exorbitantly expensive to generate a stable iPSC line. Since that requires culturing of millions of cells and intense biological scrutiny of multiple clones to identify a single optimal clone. The ability to reliably predict which cells are likely to establish as an optimal iPSC line at an early stage of pluripotency would therefore be ground-breaking in rendering this a practical and cost-effective approach to personalized medicine. Temporal information about changes in cellular appearance over time is crucial for predicting its future growth outcomes. In order to generate this data, we first performed continuous time-lapse imaging of iPSCs in culture using an ultra-high resolution microscope. We then annotated the locations and identities of cells in late-stage images where reliable manual identification is possible. Next, we propagated these labels backwards in time using a semi-automated tracking system to obtain labels for early stages of growth. Finally, we used this data to train deep neural networks to perform automatic cell segmentation and classification. Our code and data are available at https://github.com/abhineet123/ipsc_prediction.
Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training
May 23, 2023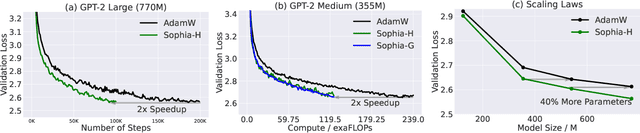


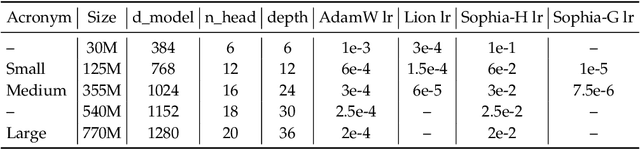
Given the massive cost of language model pre-training, a non-trivial improvement of the optimization algorithm would lead to a material reduction on the time and cost of training. Adam and its variants have been state-of-the-art for years, and more sophisticated second-order (Hessian-based) optimizers often incur too much per-step overhead. In this paper, we propose Sophia, Second-order Clipped Stochastic Optimization, a simple scalable second-order optimizer that uses a light-weight estimate of the diagonal Hessian as the pre-conditioner. The update is the moving average of the gradients divided by the moving average of the estimated Hessian, followed by element-wise clipping. The clipping controls the worst-case update size and tames the negative impact of non-convexity and rapid change of Hessian along the trajectory. Sophia only estimates the diagonal Hessian every handful of iterations, which has negligible average per-step time and memory overhead. On language modeling with GPT-2 models of sizes ranging from 125M to 770M, Sophia achieves a 2x speed-up compared with Adam in the number of steps, total compute, and wall-clock time. Theoretically, we show that Sophia adapts to the curvature in different components of the parameters, which can be highly heterogeneous for language modeling tasks. Our run-time bound does not depend on the condition number of the loss.