 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedHopQA: A Disease-Centered Multi-Hop Reasoning Benchmark and Evaluation Framework for LLM-Based Biomedical Question Answering
May 12, 2026Evaluating large language models (LLMs) in the biomedical domain requires benchmarks that can distinguish reasoning from pattern matching and remain discriminative as model capabilities improve. Existing biomedical question answering (QA) benchmarks are limited in this respect. Multiple-choice formats can allow models to succeed through answer elimination rather than inference, while widely circulated exam-style datasets are increasingly vulnerable to performance saturation and training data contamination. Multi-hop reasoning, defined as the ability to integrate information across multiple sources to derive an answer, is central to clinically meaningful tasks such as diagnostic support, literature-based discovery, and hypothesis generation, yet remains underrepresented in current biomedical QA benchmarks. MedHopQA is a disease-centered multi-hop reasoning benchmark consisting of 1,000 expert-curated question-answer pairs introduced as a shared task at BioCreative IX. Each question requires synthesis of information across two distinct Wikipedia articles, and answers are provided in an open-ended free-text format. Gold annotations are augmented with ontology-grounded synonym sets from MONDO, NCBI Gene, and NCBI Taxonomy to support both lexical and concept-level evaluation. MedHopQA was constructed through a structured process combining human annotation, triage, iterative verification, and LLM-as-a-judge validation. To reduce leaderboard gaming and contamination risk, the 1,000 scored questions are embedded within a publicly downloadable set of 10,000 questions, with answers withheld, on a CodaBench leaderboard. MedHopQA provides both a benchmark and a reusable framework for constructing future biomedical QA datasets that prioritize compositional reasoning, saturation resistance, and contamination resistance as core design constraints.
Knowledge-guided Contextual Gene Set Analysis Using Large Language Models
Jun 04, 2025



Gene set analysis (GSA) is a foundational approach for interpreting genomic data of diseases by linking genes to biological processes. However, conventional GSA methods overlook clinical context of the analyses, often generating long lists of enriched pathways with redundant, nonspecific, or irrelevant results. Interpreting these requires extensive, ad-hoc manual effort, reducing both reliability and reproducibility. To address this limitation, we introduce cGSA, a novel AI-driven framework that enhances GSA by incorporating context-aware pathway prioritization. cGSA integrates gene cluster detection, enrichment analysis, and large language models to identify pathways that are not only statistically significant but also biologically meaningful. Benchmarking on 102 manually curated gene sets across 19 diseases and ten disease-related biological mechanisms shows that cGSA outperforms baseline methods by over 30%, with expert validation confirming its increased precision and interpretability. Two independent case studies in melanoma and breast cancer further demonstrate its potential to uncover context-specific insights and support targeted hypothesis generation.
Enhancing Biomedical Relation Extraction with Directionality
Jan 23, 2025



Biological relation networks contain rich information for understanding the biological mechanisms behind the relationship of entities such as genes, proteins, diseases, and chemicals. The vast growth of biomedical literature poses significant challenges updating the network knowledge. The recent Biomedical Relation Extraction Dataset (BioRED) provides valuable manual annotations, facilitating the develop-ment of machine-learning and pre-trained language model approaches for automatically identifying novel document-level (inter-sentence context) relationships. Nonetheless, its annotations lack directionality (subject/object) for the entity roles, essential for studying complex biological networks. Herein we annotate the entity roles of the relationships in the BioRED corpus and subsequently propose a novel multi-task language model with soft-prompt learning to jointly identify the relationship, novel findings, and entity roles. Our results in-clude an enriched BioRED corpus with 10,864 directionality annotations. Moreover, our proposed method outperforms existing large language models such as the state-of-the-art GPT-4 and Llama-3 on two benchmarking tasks. Our source code and dataset are available at https://github.com/ncbi-nlp/BioREDirect.
GeneAgent: Self-verification Language Agent for Gene Set Knowledge Discovery using Domain Databases
May 25, 2024



Gene set knowledge discovery is essential for advancing human functional genomics. Recent studies have shown promising performance by harnessing the power of Large Language Models (LLMs) on this task. Nonetheless, their results are subject to several limitations common in LLMs such as hallucinations. In response, we present GeneAgent, a first-of-its-kind language agent featuring self-verification capability. It autonomously interacts with various biological databases and leverages relevant domain knowledge to improve accuracy and reduce hallucination occurrences. Benchmarking on 1,106 gene sets from different sources, GeneAgent consistently outperforms standard GPT-4 by a significant margin. Moreover, a detailed manual review confirms the effectiveness of the self-verification module in minimizing hallucinations and generating more reliable analytical narratives. To demonstrate its practical utility, we apply GeneAgent to seven novel gene sets derived from mouse B2905 melanoma cell lines, with expert evaluations showing that GeneAgent offers novel insights into gene functions and subsequently expedites knowledge discovery.
EnzChemRED, a rich enzyme chemistry relation extraction dataset
Apr 22, 2024Expert curation is essential to capture knowledge of enzyme functions from the scientific literature in FAIR open knowledgebases but cannot keep pace with the rate of new discoveries and new publications. In this work we present EnzChemRED, for Enzyme Chemistry Relation Extraction Dataset, a new training and benchmarking dataset to support the development of Natural Language Processing (NLP) methods such as (large) language models that can assist enzyme curation. EnzChemRED consists of 1,210 expert curated PubMed abstracts in which enzymes and the chemical reactions they catalyze are annotated using identifiers from the UniProt Knowledgebase (UniProtKB) and the ontology of Chemical Entities of Biological Interest (ChEBI). We show that fine-tuning pre-trained language models with EnzChemRED can significantly boost their ability to identify mentions of proteins and chemicals in text (Named Entity Recognition, or NER) and to extract the chemical conversions in which they participate (Relation Extraction, or RE), with average F1 score of 86.30% for NER, 86.66% for RE for chemical conversion pairs, and 83.79% for RE for chemical conversion pairs and linked enzymes. We combine the best performing methods after fine-tuning using EnzChemRED to create an end-to-end pipeline for knowledge extraction from text and apply this to abstracts at PubMed scale to create a draft map of enzyme functions in literature to guide curation efforts in UniProtKB and the reaction knowledgebase Rhea. The EnzChemRED corpus is freely available at https://ftp.expasy.org/databases/rhea/nlp/.
PubTator 3.0: an AI-powered Literature Resource for Unlocking Biomedical Knowledge
Jan 19, 2024

PubTator 3.0 (https://www.ncbi.nlm.nih.gov/research/pubtator3/) is a biomedical literature resource using state-of-the-art AI techniques to offer semantic and relation searches for key concepts like proteins, genetic variants, diseases, and chemicals. It currently provides over one billion entity and relation annotations across approximately 36 million PubMed abstracts and 6 million full-text articles from the PMC open access subset, updated weekly. PubTator 3.0's online interface and API utilize these precomputed entity relations and synonyms to provide advanced search capabilities and enable large-scale analyses, streamlining many complex information needs. We showcase the retrieval quality of PubTator 3.0 using a series of entity pair queries, demonstrating that PubTator 3.0 retrieves a greater number of articles than either PubMed or Google Scholar, with higher precision in the top 20 results. We further show that integrating ChatGPT (GPT-4) with PubTator APIs dramatically improves the factuality and verifiability of its responses. In summary, PubTator 3.0 offers a comprehensive set of features and tools that allow researchers to navigate the ever-expanding wealth of biomedical literature, expediting research and unlocking valuable insights for scientific discovery.
BioREx: Improving Biomedical Relation Extraction by Leveraging Heterogeneous Datasets
Jun 19, 2023



Biomedical relation extraction (RE) is the task of automatically identifying and characterizing relations between biomedical concepts from free text. RE is a central task in biomedical natural language processing (NLP) research and plays a critical role in many downstream applications, such as literature-based discovery and knowledge graph construction. State-of-the-art methods were used primarily to train machine learning models on individual RE datasets, such as protein-protein interaction and chemical-induced disease relation. Manual dataset annotation, however, is highly expensive and time-consuming, as it requires domain knowledge. Existing RE datasets are usually domain-specific or small, which limits the development of generalized and high-performing RE models. In this work, we present a novel framework for systematically addressing the data heterogeneity of individual datasets and combining them into a large dataset. Based on the framework and dataset, we report on BioREx, a data-centric approach for extracting relations. Our evaluation shows that BioREx achieves significantly higher performance than the benchmark system trained on the individual dataset, setting a new SOTA from 74.4% to 79.6% in F-1 measure on the recently released BioRED corpus. We further demonstrate that the combined dataset can improve performance for five different RE tasks. In addition, we show that on average BioREx compares favorably to current best-performing methods such as transfer learning and multi-task learning. Finally, we demonstrate BioREx's robustness and generalizability in two independent RE tasks not previously seen in training data: drug-drug N-ary combination and document-level gene-disease RE. The integrated dataset and optimized method have been packaged as a stand-alone tool available at https://github.com/ncbi/BioREx.
Bioformer: an efficient transformer language model for biomedical text mining
Feb 03, 2023Pretrained language models such as Bidirectional Encoder Representations from Transformers (BERT) have achieved state-of-the-art performance in natural language processing (NLP) tasks. Recently, BERT has been adapted to the biomedical domain. Despite the effectiveness, these models have hundreds of millions of parameters and are computationally expensive when applied to large-scale NLP applications. We hypothesized that the number of parameters of the original BERT can be dramatically reduced with minor impact on performance. In this study, we present Bioformer, a compact BERT model for biomedical text mining. We pretrained two Bioformer models (named Bioformer8L and Bioformer16L) which reduced the model size by 60% compared to BERTBase. Bioformer uses a biomedical vocabulary and was pre-trained from scratch on PubMed abstracts and PubMed Central full-text articles. We thoroughly evaluated the performance of Bioformer as well as existing biomedical BERT models including BioBERT and PubMedBERT on 15 benchmark datasets of four different biomedical NLP tasks: named entity recognition, relation extraction, question answering and document classification. The results show that with 60% fewer parameters, Bioformer16L is only 0.1% less accurate than PubMedBERT while Bioformer8L is 0.9% less accurate than PubMedBERT. Both Bioformer16L and Bioformer8L outperformed BioBERTBase-v1.1. In addition, Bioformer16L and Bioformer8L are 2-3 fold as fast as PubMedBERT/BioBERTBase-v1.1. Bioformer has been successfully deployed to PubTator Central providing gene annotations over 35 million PubMed abstracts and 5 million PubMed Central full-text articles. We make Bioformer publicly available via https://github.com/WGLab/bioformer, including pre-trained models, datasets, and instructions for downstream use.
AIONER: All-in-one scheme-based biomedical named entity recognition using deep learning
Dec 19, 2022



Biomedical named entity recognition (BioNER) seeks to automatically recognize biomedical entities in natural language text, serving as a necessary foundation for downstream text mining tasks and applications such as information extraction and question answering. Manually labeling training data for the BioNER task is costly, however, due to the significant domain expertise required for accurate annotation. The resulting data scarcity causes current BioNER approaches to be prone to overfitting, to suffer from limited generalizability, and to address a single entity type at a time (e.g., gene or disease). We therefore propose a novel all-in-one (AIO) scheme that uses external data from existing annotated resources to improve generalization. We further present AIONER, a general-purpose BioNER tool based on cutting-edge deep learning and our AIO schema. We evaluate AIONER on 14 BioNER benchmark tasks and show that AIONER is effective, robust, and compares favorably to other state-of-the-art approaches such as multi-task learning. We further demonstrate the practical utility of AIONER in three independent tasks to recognize entity types not previously seen in training data, as well as the advantages of AIONER over existing methods for processing biomedical text at a large scale (e.g., the entire PubMed data).
LitCovid in 2022: an information resource for the COVID-19 literature
Sep 27, 2022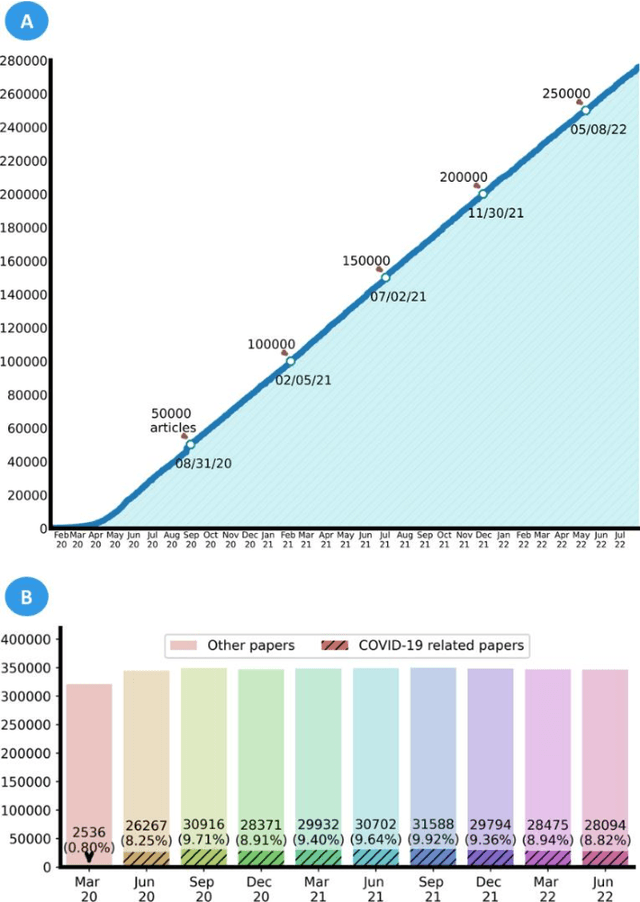

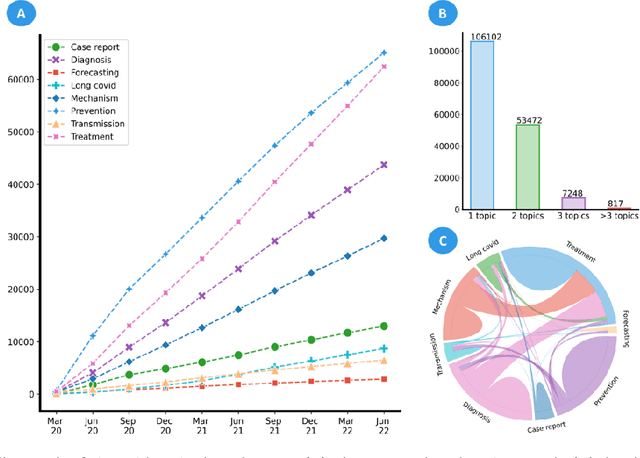
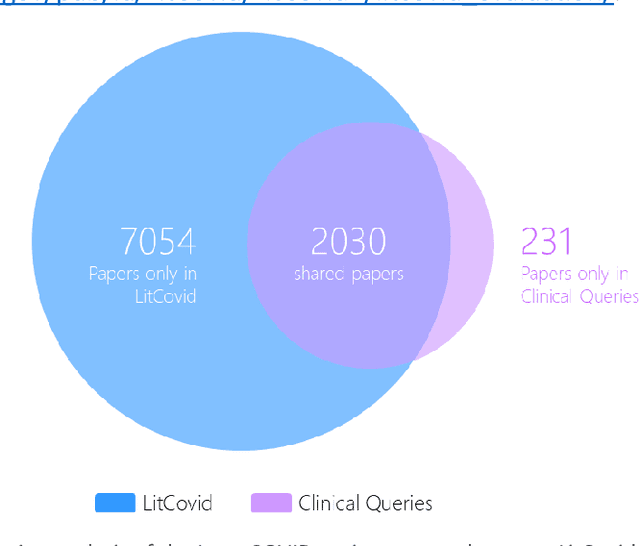
LitCovid (https://www.ncbi.nlm.nih.gov/research/coronavirus/), first launched in February 2020, is a first-of-its-kind literature hub for tracking up-to-date published research on COVID-19. The number of articles in LitCovid has increased from 55,000 to ~300,000 over the past two and half years, with a consistent growth rate of ~10,000 articles per month. In addition to the rapid literature growth, the COVID-19 pandemic has evolved dramatically. For instance, the Omicron variant has now accounted for over 98% of new infections in the U.S. In response to the continuing evolution of the COVID-19 pandemic, this article describes significant updates to LitCovid over the last two years. First, we introduced the Long Covid collection consisting of the articles on COVID-19 survivors experiencing ongoing multisystemic symptoms, including respiratory issues, cardiovascular disease, cognitive impairment, and profound fatigue. Second, we provided new annotations on the latest COVID-19 strains and vaccines mentioned in the literature. Third, we improved several existing features with more accurate machine learning algorithms for annotating topics and classifying articles relevant to COVID-19. LitCovid has been widely used with millions of accesses by users worldwide on various information needs and continues to play a critical role in collecting, curating, and standardizing the latest knowledge on the COVID-19 literature.