 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Perch a quadrotor on planes by the ceiling effect
Jul 03, 2023

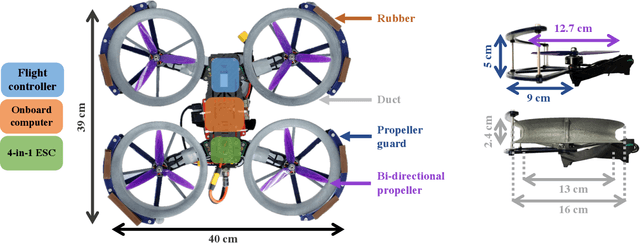
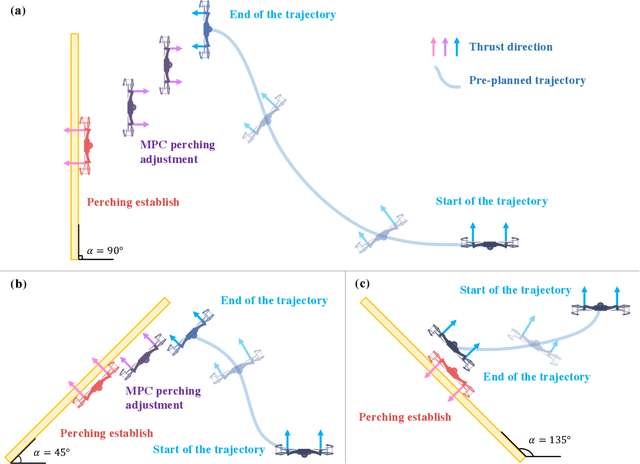
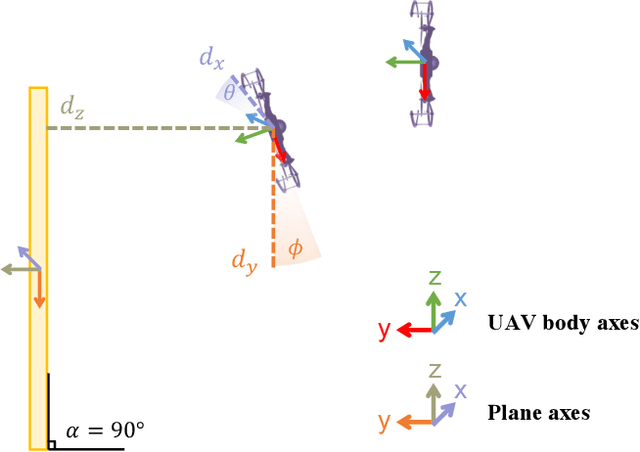
Perching is a promising solution for a small unmanned aerial vehicle (UAV) to save energy and extend operation time. This paper proposes a quadrotor that can perch on planar structures using the ceiling effect. Compared with the existing work, this perching method does not require any claws, hooks, or adhesive pads, leading to a simpler system design. This method does not limit the perching by surface angle or material either. The design of the quadrotor that only uses its propeller guards for surface contact is presented in this paper. We also discussed the automatic perching strategy including trajectory generation and power management. Experiments are conducted to verify that the approach is practical and the UAV can perch on planes with different angles. Energy consumption in the perching state is assessed, showing that more than 30% of power can be saved. Meanwhile, the quadrotor exhibits improved stability while perching compared to when it is hovering.
SAS Video-QA: Self-Adaptive Sampling for Efficient Video Question-Answering
Jul 09, 2023
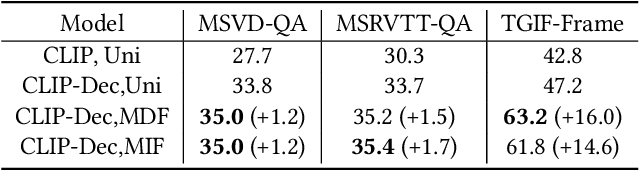

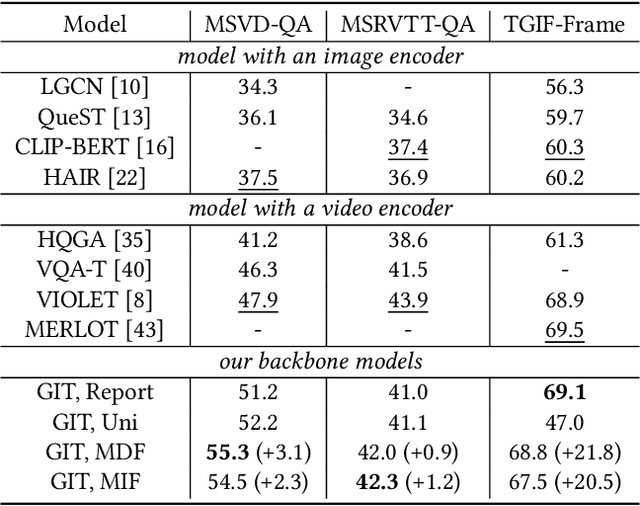
Video question--answering is a fundamental task in the field of video understanding. Although current vision--language models (VLMs) equipped with Video Transformers have enabled temporal modeling and yielded superior results, they are at the cost of huge computational power and thus too expensive to deploy in real-time application scenarios. An economical workaround only samples a small portion of frames to represent the main content of that video and tune an image--text model on these sampled frames. Recent video understanding models usually randomly sample a set of frames or clips, regardless of internal correlations between their visual contents, nor their relevance to the problem. We argue that such kinds of aimless sampling may omit the key frames from which the correct answer can be deduced, and the situation gets worse when the sampling sparsity increases, which always happens as the video lengths increase. To mitigate this issue, we propose two frame sampling strategies, namely the most domain frames (MDF) and most implied frames (MIF), to maximally preserve those frames that are most likely vital to the given questions. MDF passively minimizes the risk of key frame omission in a bootstrap manner, while MIS actively searches key frames customized for each video--question pair with the assistance of auxiliary models. The experimental results on three public datasets from three advanced VLMs (CLIP, GIT and All-in-one) demonstrate that our proposed strategies can boost the performance for image--text pretrained models. The source codes pertaining to the method proposed in this paper are publicly available at https://github.com/declare-lab/sas-vqa.
Nearly-Optimal Hierarchical Clustering for Well-Clustered Graphs
Jun 16, 2023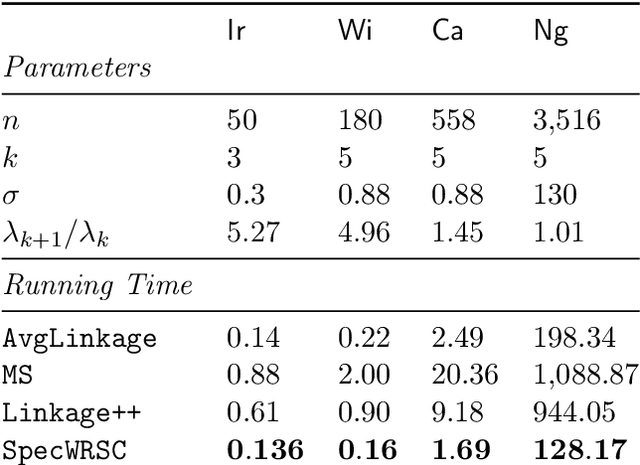
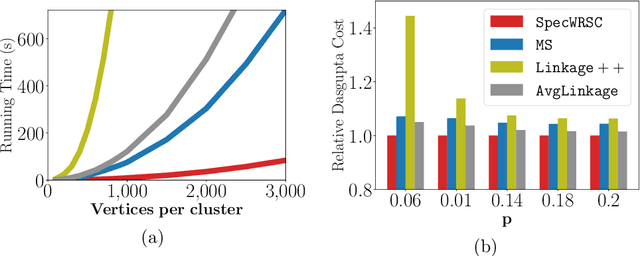
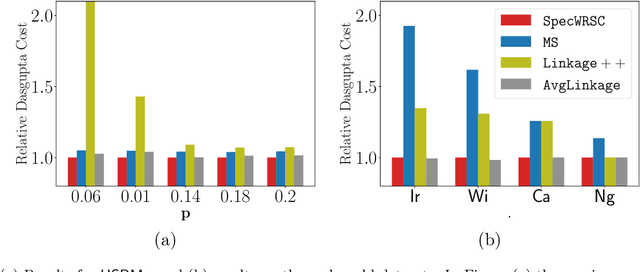
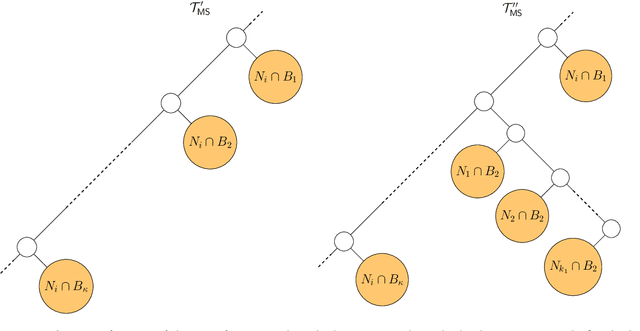
This paper presents two efficient hierarchical clustering (HC) algorithms with respect to Dasgupta's cost function. For any input graph $G$ with a clear cluster-structure, our designed algorithms run in nearly-linear time in the input size of $G$, and return an $O(1)$-approximate HC tree with respect to Dasgupta's cost function. We compare the performance of our algorithm against the previous state-of-the-art on synthetic and real-world datasets and show that our designed algorithm produces comparable or better HC trees with much lower running time.
Leveraging Multi-time Hamilton-Jacobi PDEs for Certain Scientific Machine Learning Problems
Mar 22, 2023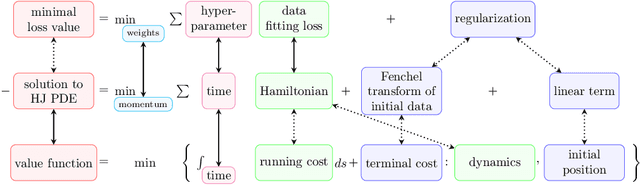

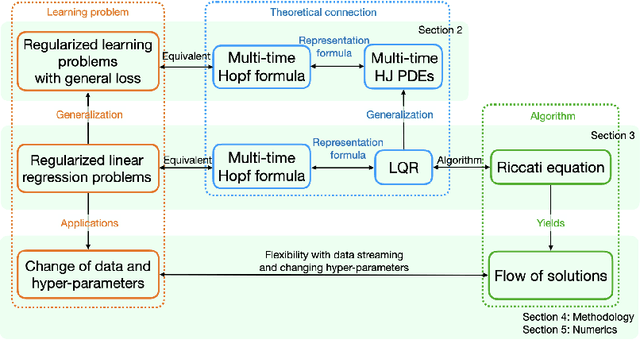
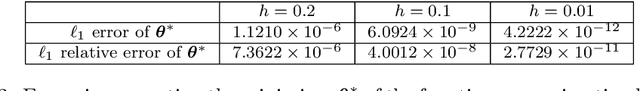
Hamilton-Jacobi partial differential equations (HJ PDEs) have deep connections with a wide range of fields, including optimal control, differential games, and imaging sciences. By considering the time variable to be a higher dimensional quantity, HJ PDEs can be extended to the multi-time case. In this paper, we establish a novel theoretical connection between specific optimization problems arising in machine learning and the multi-time Hopf formula, which corresponds to a representation of the solution to certain multi-time HJ PDEs. Through this connection, we increase the interpretability of the training process of certain machine learning applications by showing that when we solve these learning problems, we also solve a multi-time HJ PDE and, by extension, its corresponding optimal control problem. As a first exploration of this connection, we develop the relation between the regularized linear regression problem and the Linear Quadratic Regulator (LQR). We then leverage our theoretical connection to adapt standard LQR solvers (namely, those based on the Riccati ordinary differential equations) to design new training approaches for machine learning. Finally, we provide some numerical examples that demonstrate the versatility and possible computational advantages of our Riccati-based approach in the context of continual learning, post-training calibration, transfer learning, and sparse dynamics identification.
Diffusion Hyperfeatures: Searching Through Time and Space for Semantic Correspondence
May 23, 2023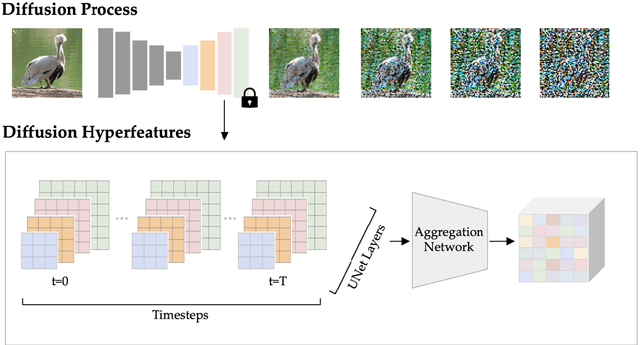
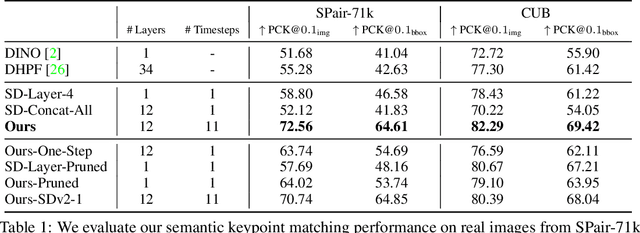
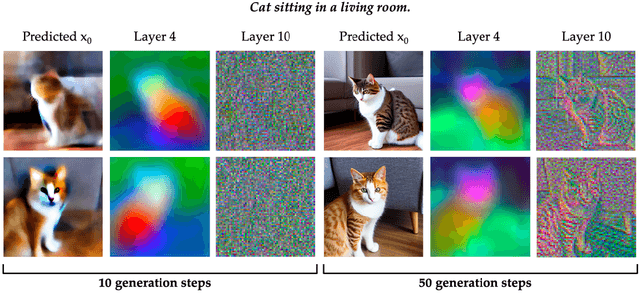
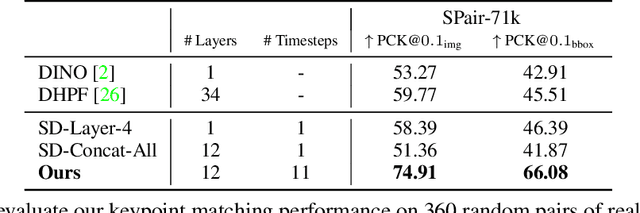
Diffusion models have been shown to be capable of generating high-quality images, suggesting that they could contain meaningful internal representations. Unfortunately, the feature maps that encode a diffusion model's internal information are spread not only over layers of the network, but also over diffusion timesteps, making it challenging to extract useful descriptors. We propose Diffusion Hyperfeatures, a framework for consolidating multi-scale and multi-timestep feature maps into per-pixel feature descriptors that can be used for downstream tasks. These descriptors can be extracted for both synthetic and real images using the generation and inversion processes. We evaluate the utility of our Diffusion Hyperfeatures on the task of semantic keypoint correspondence: our method achieves superior performance on the SPair-71k real image benchmark. We also demonstrate that our method is flexible and transferable: our feature aggregation network trained on the inversion features of real image pairs can be used on the generation features of synthetic image pairs with unseen objects and compositions. Our code is available at \url{https://diffusion-hyperfeatures.github.io}.
Policy Gradient Methods for Discrete Time Linear Quadratic Regulator With Random Parameters
Mar 29, 2023This paper studies an infinite horizon optimal control problem for discrete-time linear system and quadratic criteria, both with random parameters which are independent and identically distributed with respect to time. In this general setting, we apply the policy gradient method, a reinforcement learning technique, to search for the optimal control without requiring knowledge of statistical information of the parameters. We investigate the sub-Gaussianity of the state process and establish global linear convergence guarantee for this approach based on assumptions that are weaker and easier to verify compared to existing results. Numerical experiments are presented to illustrate our result.
A Physics-Informed Low-Shot Learning For sEMG-Based Estimation of Muscle Force and Joint Kinematics
Jul 08, 2023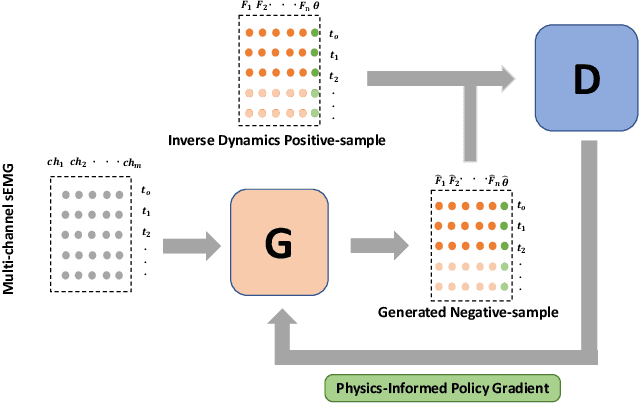
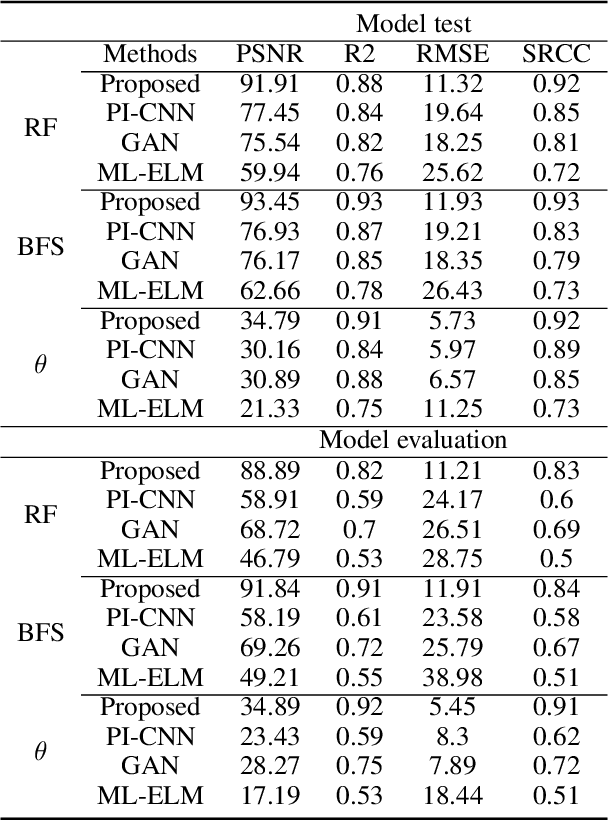
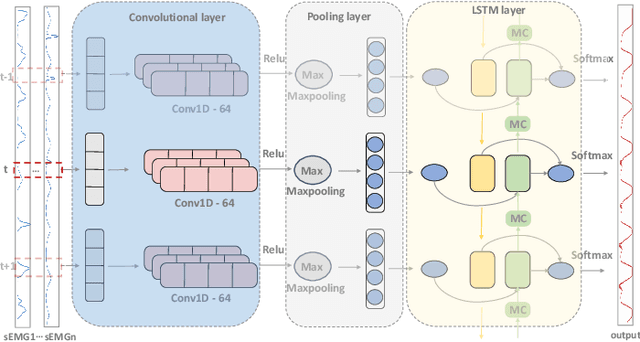
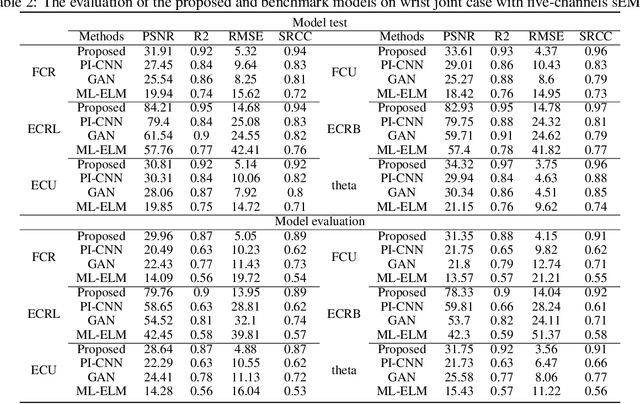
Muscle force and joint kinematics estimation from surface electromyography (sEMG) are essential for real-time biomechanical analysis of the dynamic interplay among neural muscle stimulation, muscle dynamics, and kinetics. Recent advances in deep neural networks (DNNs) have shown the potential to improve biomechanical analysis in a fully automated and reproducible manner. However, the small sample nature and physical interpretability of biomechanical analysis limit the applications of DNNs. This paper presents a novel physics-informed low-shot learning method for sEMG-based estimation of muscle force and joint kinematics. This method seamlessly integrates Lagrange's equation of motion and inverse dynamic muscle model into the generative adversarial network (GAN) framework for structured feature decoding and extrapolated estimation from the small sample data. Specifically, Lagrange's equation of motion is introduced into the generative model to restrain the structured decoding of the high-level features following the laws of physics. And a physics-informed policy gradient is designed to improve the adversarial learning efficiency by rewarding the consistent physical representation of the extrapolated estimations and the physical references. Experimental validations are conducted on two scenarios (i.e. the walking trials and wrist motion trials). Results indicate that the estimations of the muscle forces and joint kinematics are unbiased compared to the physics-based inverse dynamics, which outperforms the selected benchmark methods, including physics-informed convolution neural network (PI-CNN), vallina generative adversarial network (GAN), and multi-layer extreme learning machine (ML-ELM).
Robotic Ultrasound Imaging: State-of-the-Art and Future Perspectives
Jul 08, 2023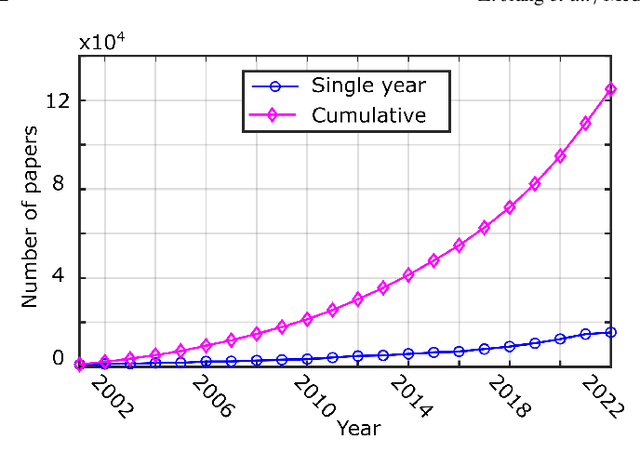
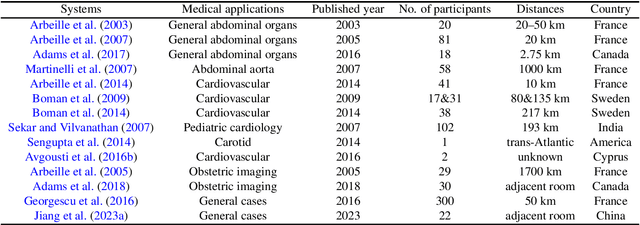
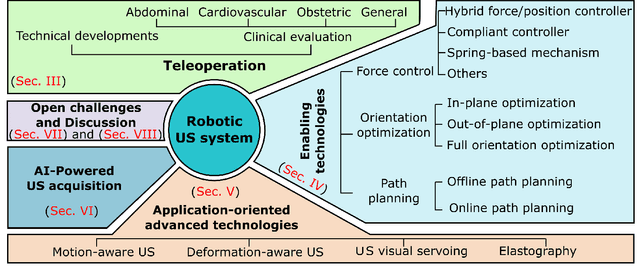
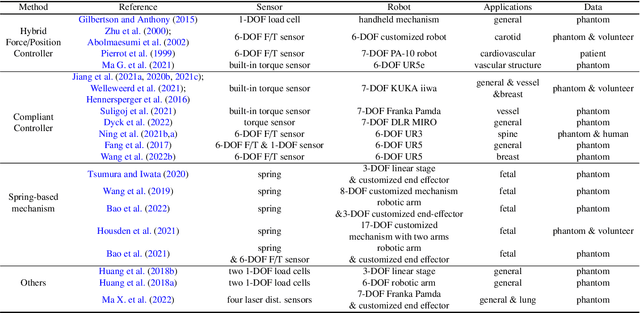
Ultrasound (US) is one of the most widely used modalities for clinical intervention and diagnosis due to the merits of providing non-invasive, radiation-free, and real-time images. However, free-hand US examinations are highly operator-dependent. Robotic US System (RUSS) aims at overcoming this shortcoming by offering reproducibility, while also aiming at improving dexterity, and intelligent anatomy and disease-aware imaging. In addition to enhancing diagnostic outcomes, RUSS also holds the potential to provide medical interventions for populations suffering from the shortage of experienced sonographers. In this paper, we categorize RUSS as teleoperated or autonomous. Regarding teleoperated RUSS, we summarize their technical developments, and clinical evaluations, respectively. This survey then focuses on the review of recent work on autonomous robotic US imaging. We demonstrate that machine learning and artificial intelligence present the key techniques, which enable intelligent patient and process-specific, motion and deformation-aware robotic image acquisition. We also show that the research on artificial intelligence for autonomous RUSS has directed the research community toward understanding and modeling expert sonographers' semantic reasoning and action. Here, we call this process, the recovery of the "language of sonography". This side result of research on autonomous robotic US acquisitions could be considered as valuable and essential as the progress made in the robotic US examination itself. This article will provide both engineers and clinicians with a comprehensive understanding of RUSS by surveying underlying techniques.
VS-TransGRU: A Novel Transformer-GRU-based Framework Enhanced by Visual-Semantic Fusion for Egocentric Action Anticipation
Jul 08, 2023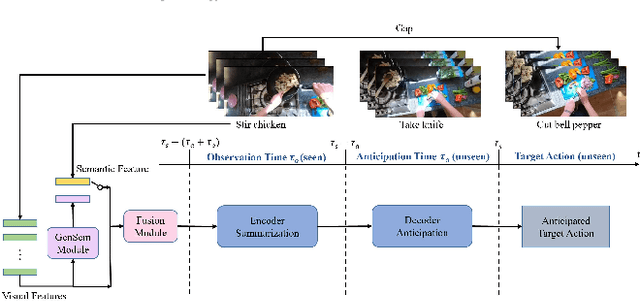
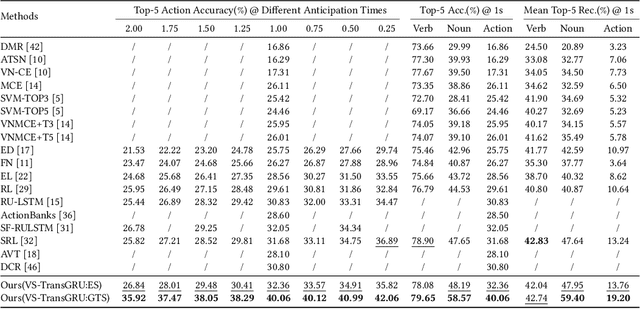

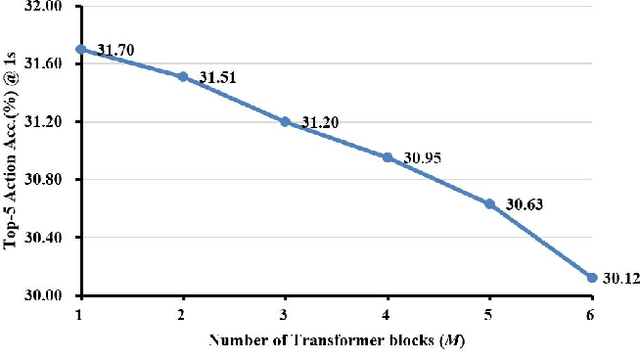
Egocentric action anticipation is a challenging task that aims to make advanced predictions of future actions from current and historical observations in the first-person view. Most existing methods focus on improving the model architecture and loss function based on the visual input and recurrent neural network to boost the anticipation performance. However, these methods, which merely consider visual information and rely on a single network architecture, gradually reach a performance plateau. In order to fully understand what has been observed and capture the dependencies between current observations and future actions well enough, we propose a novel visual-semantic fusion enhanced and Transformer GRU-based action anticipation framework in this paper. Firstly, high-level semantic information is introduced to improve the performance of action anticipation for the first time. We propose to use the semantic features generated based on the class labels or directly from the visual observations to augment the original visual features. Secondly, an effective visual-semantic fusion module is proposed to make up for the semantic gap and fully utilize the complementarity of different modalities. Thirdly, to take advantage of both the parallel and autoregressive models, we design a Transformer based encoder for long-term sequential modeling and a GRU-based decoder for flexible iteration decoding. Extensive experiments on two large-scale first-person view datasets, i.e., EPIC-Kitchens and EGTEA Gaze+, validate the effectiveness of our proposed method, which achieves new state-of-the-art performance, outperforming previous approaches by a large margin.
Serving Graph Neural Networks With Distributed Fog Servers For Smart IoT Services
Jul 04, 2023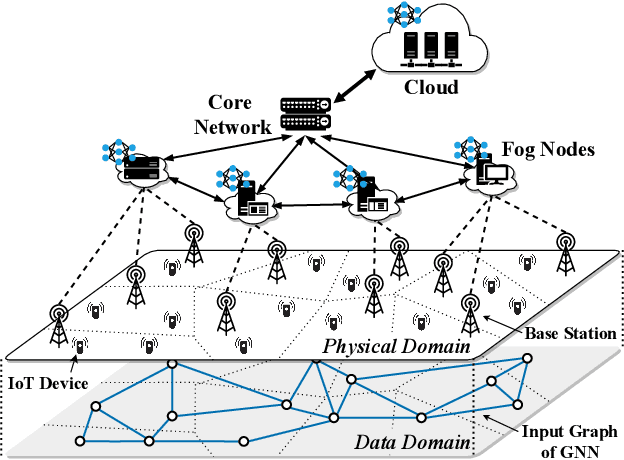
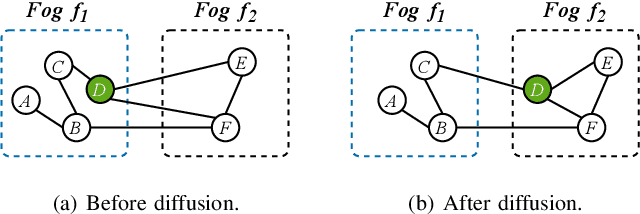
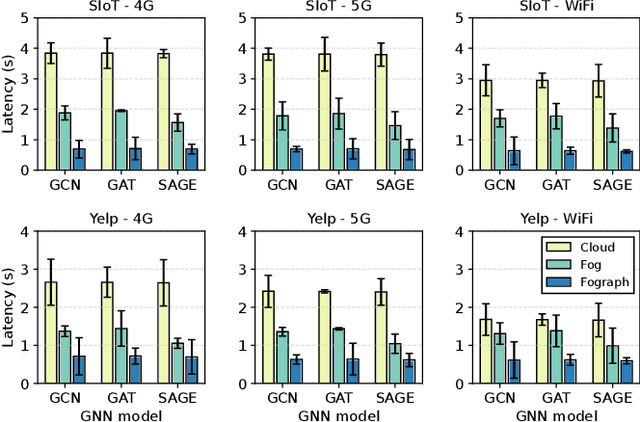
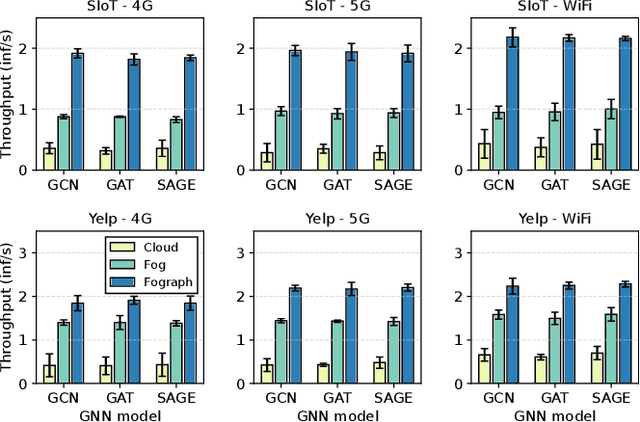
Graph Neural Networks (GNNs) have gained growing interest in miscellaneous applications owing to their outstanding ability in extracting latent representation on graph structures. To render GNN-based service for IoT-driven smart applications, traditional model serving paradigms usually resort to the cloud by fully uploading geo-distributed input data to remote datacenters. However, our empirical measurements reveal the significant communication overhead of such cloud-based serving and highlight the profound potential in applying the emerging fog computing. To maximize the architectural benefits brought by fog computing, in this paper, we present Fograph, a novel distributed real-time GNN inference framework that leverages diverse and dynamic resources of multiple fog nodes in proximity to IoT data sources. By introducing heterogeneity-aware execution planning and GNN-specific compression techniques, Fograph tailors its design to well accommodate the unique characteristics of GNN serving in fog environments. Prototype-based evaluation and case study demonstrate that Fograph significantly outperforms the state-of-the-art cloud serving and fog deployment by up to 5.39x execution speedup and 6.84x throughput improvement.