 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CUTS+: High-dimensional Causal Discovery from Irregular Time-series
May 10, 2023
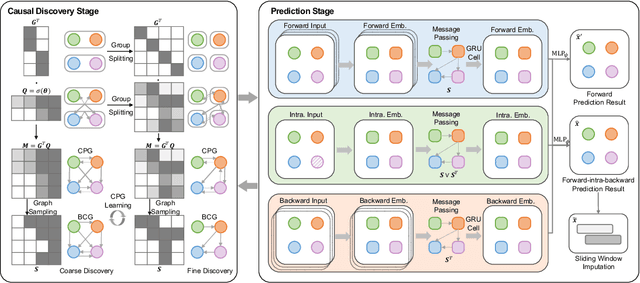
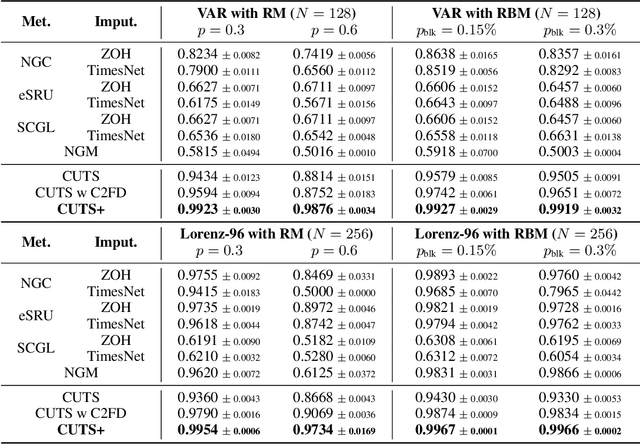
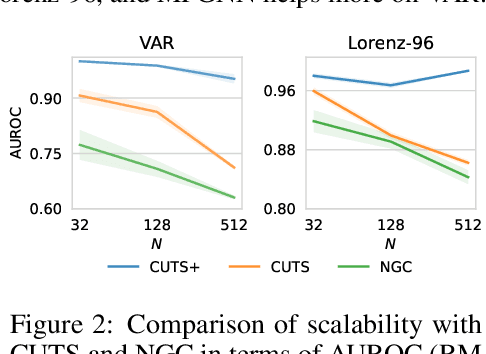
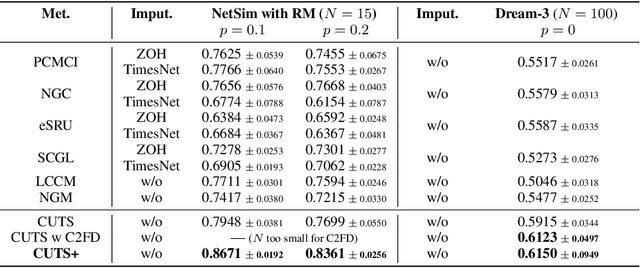
Causal discovery in time-series is a fundamental problem in the machine learning community, enabling causal reasoning and decision-making in complex scenarios. Recently, researchers successfully discover causality by combining neural networks with Granger causality, but their performances degrade largely when encountering high-dimensional data because of the highly redundant network design and huge causal graphs. Moreover, the missing entries in the observations further hamper the causal structural learning. To overcome these limitations, We propose CUTS+, which is built on the Granger-causality-based causal discovery method CUTS and raises the scalability by introducing a technique called Coarse-to-fine-discovery (C2FD) and leveraging a message-passing-based graph neural network (MPGNN). Compared to previous methods on simulated, quasi-real, and real datasets, we show that CUTS+ largely improves the causal discovery performance on high-dimensional data with different types of irregular sampling.
Learning Regionalization within a Differentiable High-Resolution Hydrological Model using Accurate Spatial Cost Gradients
Aug 02, 2023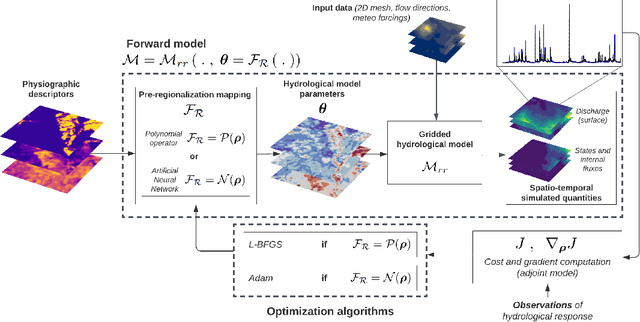

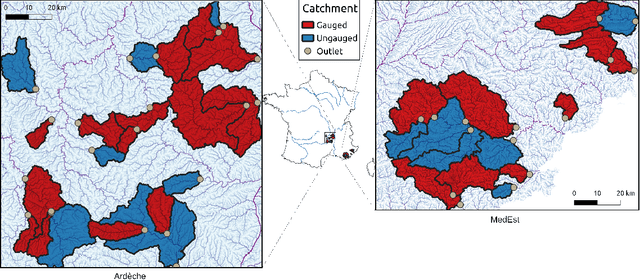
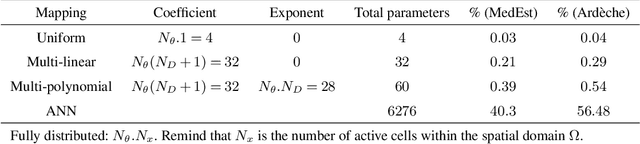
Estimating spatially distributed hydrological parameters in ungauged catchments poses a challenging regionalization problem and requires imposing spatial constraints given the sparsity of discharge data. A possible approach is to search for a transfer function that quantitatively relates physical descriptors to conceptual model parameters. This paper introduces a Hybrid Data Assimilation and Parameter Regionalization (HDA-PR) approach incorporating learnable regionalization mappings, based on either multivariate regressions or neural networks, into a differentiable hydrological model. It enables the exploitation of heterogeneous datasets across extensive spatio-temporal computational domains within a high-dimensional regionalization context, using accurate adjoint-based gradients. The inverse problem is tackled with a multi-gauge calibration cost function accounting for information from multiple observation sites. HDA-PR was tested on high-resolution, hourly and kilometric regional modeling of two flash-flood-prone areas located in the South of France. In both study areas, the median Nash-Sutcliffe efficiency (NSE) scores ranged from 0.52 to 0.78 at pseudo-ungauged sites over calibration and validation periods. These results highlight a strong regionalization performance of HDA-PR, improving NSE by up to 0.57 compared to the baseline model calibrated with lumped parameters, and achieving a performance comparable to the reference solution obtained with local uniform calibration (median NSE from 0.59 to 0.79). Multiple evaluation metrics based on flood-oriented hydrological signatures are also employed to assess the accuracy and robustness of the approach. The regionalization method is amenable to state-parameter correction from multi-source data over a range of time scales needed for operational data assimilation, and it is adaptable to other differentiable geophysical models.
Towards Resolving Word Ambiguity with Word Embeddings
Jul 25, 2023
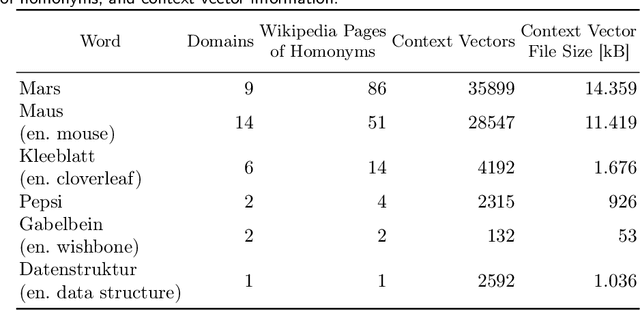
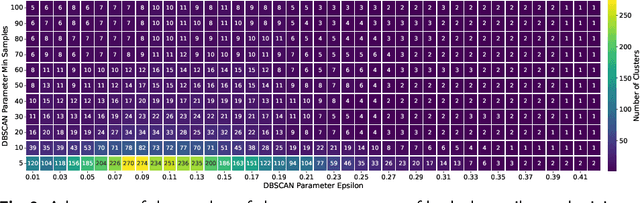
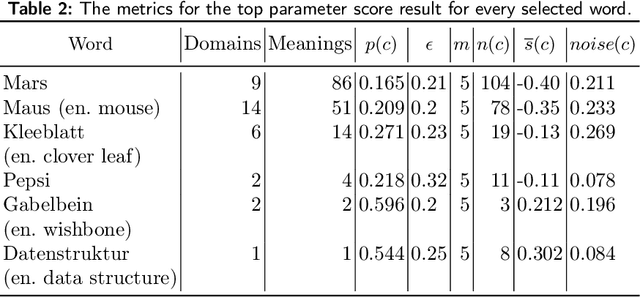
Ambiguity is ubiquitous in natural language. Resolving ambiguous meanings is especially important in information retrieval tasks. While word embeddings carry semantic information, they fail to handle ambiguity well. Transformer models have been shown to handle word ambiguity for complex queries, but they cannot be used to identify ambiguous words, e.g. for a 1-word query. Furthermore, training these models is costly in terms of time, hardware resources, and training data, prohibiting their use in specialized environments with sensitive data. Word embeddings can be trained using moderate hardware resources. This paper shows that applying DBSCAN clustering to the latent space can identify ambiguous words and evaluate their level of ambiguity. An automatic DBSCAN parameter selection leads to high-quality clusters, which are semantically coherent and correspond well to the perceived meanings of a given word.
A short review of the main concerns in A.I. development and application within the public sector supported by NLP and TM
Jul 25, 2023Artificial Intelligence is not a new subject, and business, industry and public sectors have used it in different ways and contexts and considering multiple concerns. This work reviewed research papers published in ACM Digital Library and IEEE Xplore conference proceedings in the last two years supported by fundamental concepts of Natural Language Processing (NLP) and Text Mining (TM). The objective was to capture insights regarding data privacy, ethics, interpretability, explainability, trustworthiness, and fairness in the public sector. The methodology has saved analysis time and could retrieve papers containing relevant information. The results showed that fairness was the most frequent concern. The least prominent topic was data privacy (although embedded in most articles), while the most prominent was trustworthiness. Finally, gathering helpful insights about those concerns regarding A.I. applications in the public sector was also possible.
Joint Channel Estimation and Turbo Equalization of Single-Carrier Systems over Time-Varying Channels
May 16, 2023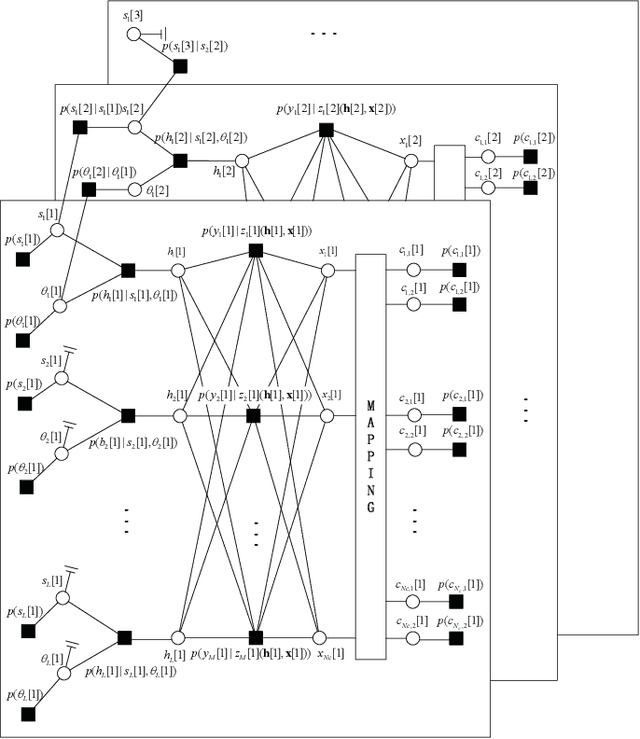
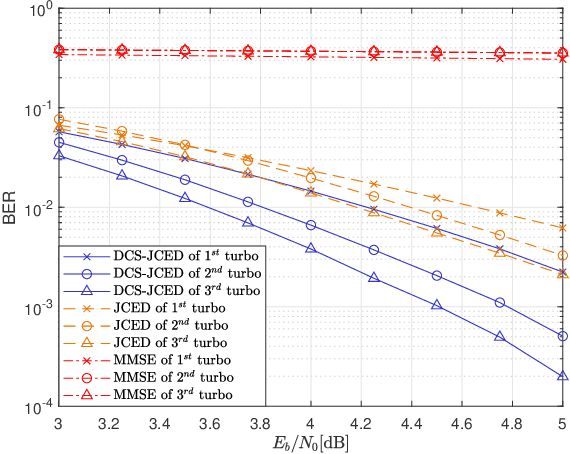
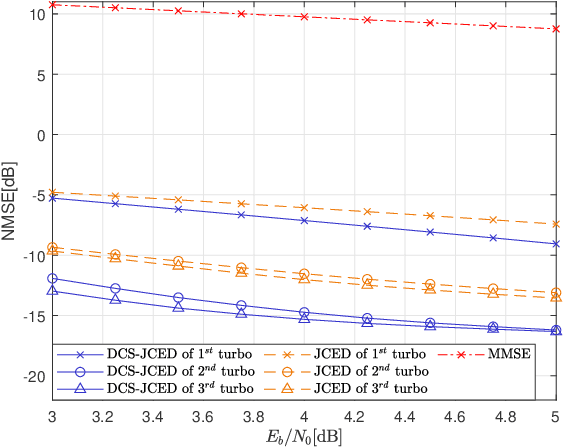
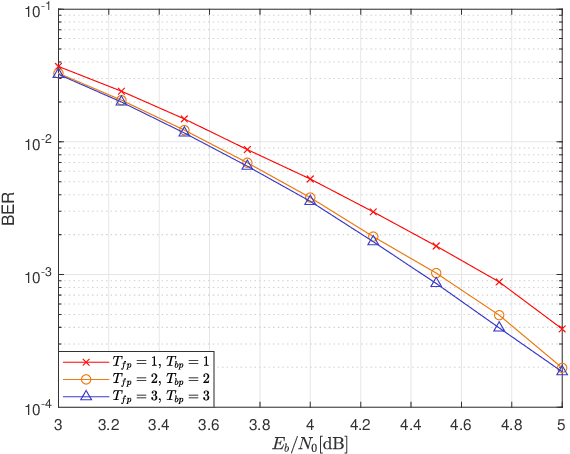
Block transmission systems have been proven successful over frequency-selective channels. For time-varying channel such as in high-speed mobile communication and underwater communication, existing equalizers assume that channels over different data frames are independent. However, the real-world channels over different data frames are correlated, thereby indicating potentials for performance improvement. In this paper, we propose a joint channel estimation and equalization/decoding algorithm for a single-carrier system that exploits temporal correlations of channel between transmitted data frames. Leveraging the concept of dynamic compressive sensing, our method can utilize the information of several data frames to achieve better performance. The information not only passes between the channel and symbol, but also the channels over different data frames. Numerical simulations using an extensively validated underwater acoustic model with a time-varying channel establish that the proposed algorithm outperforms the former bilinear generalized approximate message passing equalizer and classic minimum mean square error turbo equalizer in bit error rate and channel estimation normalized mean square error. The algorithm idea we present can also find applications in other bilinear multiple measurements vector compressive sensing problems.
Mediapipe and CNNs for Real-Time ASL Gesture Recognition
May 09, 2023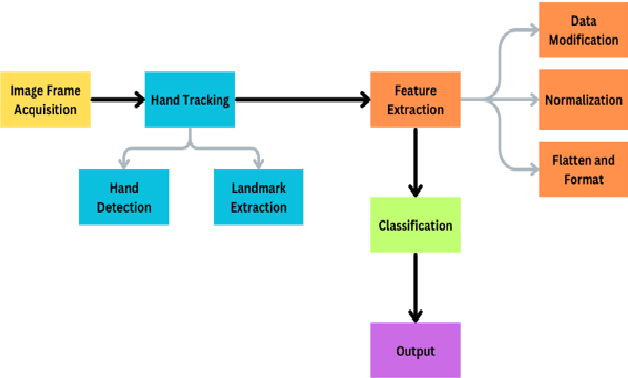

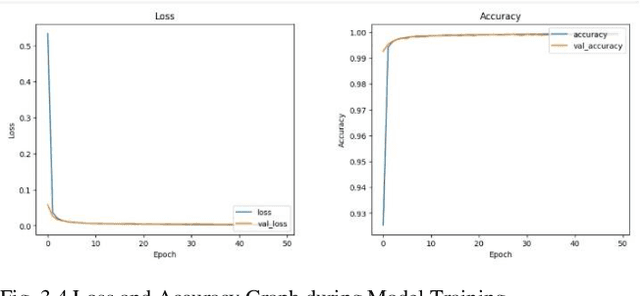
This research paper describes a realtime system for identifying American Sign Language (ASL) movements that employs modern computer vision and machine learning approaches. The suggested method makes use of the Mediapipe library for feature extraction and a Convolutional Neural Network (CNN) for ASL gesture classification. The testing results show that the suggested system can detect all ASL alphabets with an accuracy of 99.95%, indicating its potential for use in communication devices for people with hearing impairments. The proposed approach can also be applied to additional sign languages with similar hand motions, potentially increasing the quality of life for people with hearing loss. Overall, the study demonstrates the effectiveness of using Mediapipe and CNN for real-time sign language recognition, making a significant contribution to the field of computer vision and machine learning.
DETRs Beat YOLOs on Real-time Object Detection
Apr 17, 2023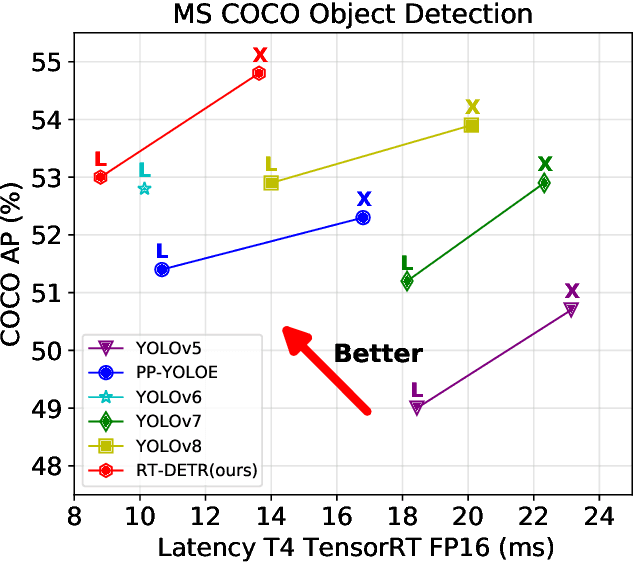
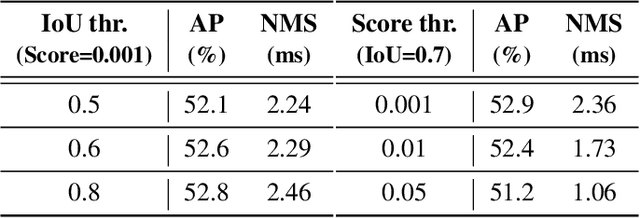
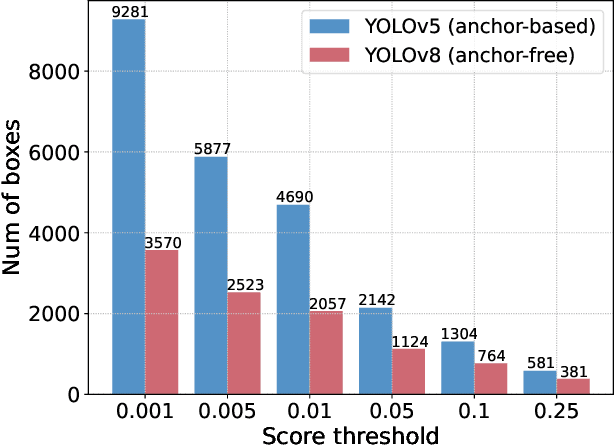
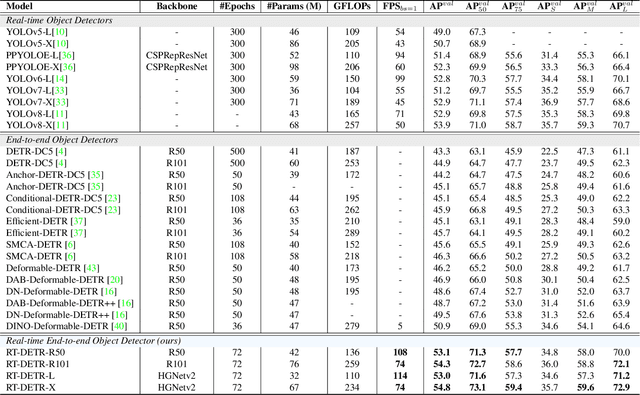
Recently, end-to-end transformer-based detectors (DETRs) have achieved remarkable performance. However, the issue of the high computational cost of DETRs has not been effectively addressed, limiting their practical application and preventing them from fully exploiting the benefits of no post-processing, such as non-maximum suppression (NMS). In this paper, we first analyze the influence of NMS in modern real-time object detectors on inference speed, and establish an end-to-end speed benchmark. To avoid the inference delay caused by NMS, we propose a Real-Time DEtection TRansformer (RT-DETR), the first real-time end-to-end object detector to our best knowledge. Specifically, we design an efficient hybrid encoder to efficiently process multi-scale features by decoupling the intra-scale interaction and cross-scale fusion, and propose IoU-aware query selection to improve the initialization of object queries. In addition, our proposed detector supports flexibly adjustment of the inference speed by using different decoder layers without the need for retraining, which facilitates the practical application of real-time object detectors. Our RT-DETR-L achieves 53.0% AP on COCO val2017 and 114 FPS on T4 GPU, while RT-DETR-X achieves 54.8% AP and 74 FPS, outperforming all YOLO detectors of the same scale in both speed and accuracy. Furthermore, our RT-DETR-R50 achieves 53.1% AP and 108 FPS, outperforming DINO-Deformable-DETR-R50 by 2.2% AP in accuracy and by about 21 times in FPS. Source code and pretrained models will be available at PaddleDetection.
SAS Video-QA: Self-Adaptive Sampling for Efficient Video Question-Answering
Aug 01, 2023
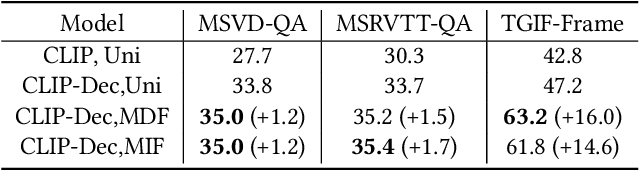

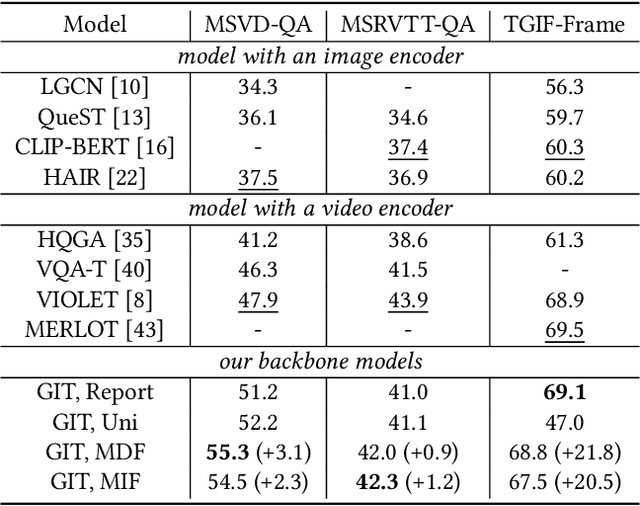
Video question--answering is a fundamental task in the field of video understanding. Although current vision--language models (VLMs) equipped with Video Transformers have enabled temporal modeling and yielded superior results, they are at the cost of huge computational power and thus too expensive to deploy in real-time application scenarios. An economical workaround only samples a small portion of frames to represent the main content of that video and tune an image--text model on these sampled frames. Recent video understanding models usually randomly sample a set of frames or clips, regardless of internal correlations between their visual contents, nor their relevance to the problem. We argue that such kinds of aimless sampling may omit the key frames from which the correct answer can be deduced, and the situation gets worse when the sampling sparsity increases, which always happens as the video lengths increase. To mitigate this issue, we propose two frame sampling strategies, namely the most domain frames (MDF) and most implied frames (MIF), to maximally preserve those frames that are most likely vital to the given questions. MDF passively minimizes the risk of key frame omission in a bootstrap manner, while MIS actively searches key frames customized for each video--question pair with the assistance of auxiliary models. The experimental results on three public datasets from three advanced VLMs (CLIP, GIT and All-in-one) demonstrate that our proposed strategies can boost the performance for image--text pretrained models. The source codes pertaining to the method proposed in this paper are publicly available at https://github.com/declare-lab/sas-vqa.
Real-Time Variational Method for Learning Neural Trajectory and its Dynamics
May 18, 2023
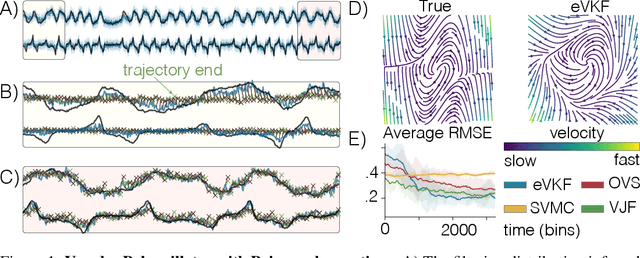

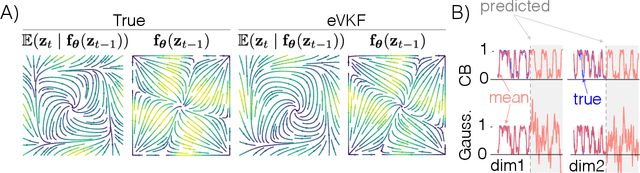
Latent variable models have become instrumental in computational neuroscience for reasoning about neural computation. This has fostered the development of powerful offline algorithms for extracting latent neural trajectories from neural recordings. However, despite the potential of real time alternatives to give immediate feedback to experimentalists, and enhance experimental design, they have received markedly less attention. In this work, we introduce the exponential family variational Kalman filter (eVKF), an online recursive Bayesian method aimed at inferring latent trajectories while simultaneously learning the dynamical system generating them. eVKF works for arbitrary likelihoods and utilizes the constant base measure exponential family to model the latent state stochasticity. We derive a closed-form variational analogue to the predict step of the Kalman filter which leads to a provably tighter bound on the ELBO compared to another online variational method. We validate our method on synthetic and real-world data, and, notably, show that it achieves competitive performance
Channel Modeling for Heterogeneous Vehicular ISAC System with Shared Clusters
Jul 16, 2023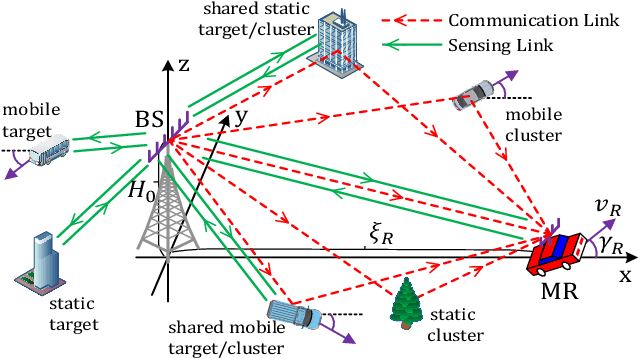
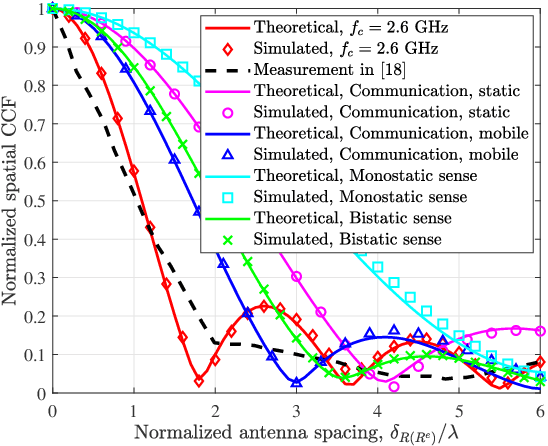
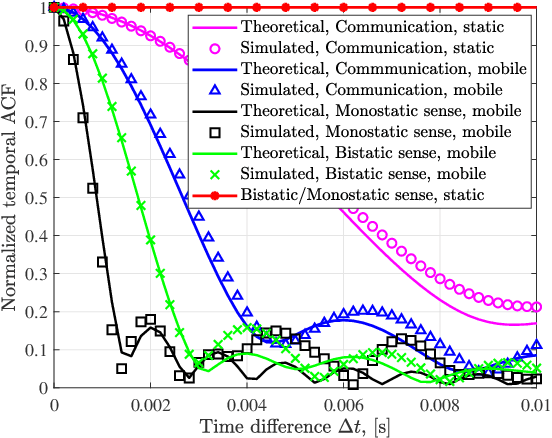

In this paper, we consider the channel modeling of a heterogeneous vehicular integrated sensing and communication (ISAC) system, where a dual-functional multi-antenna base station (BS) intends to communicate with a multi-antenna vehicular receiver (MR) and sense the surrounding environments simultaneously. The time-varying complex channel impulse responses (CIRs) of the sensing and communication channels are derived, respectively, in which the sensing and communication channels are correlated with shared clusters. The proposed models show great generality for the capability in covering both monostatic and bistatic sensing scenarios, and as well for considering both static clusters/targets and mobile clusters/targets. Important channel statistical characteristics, including time-varying spatial cross-correlation function (CCF) and temporal auto-correlation function (ACF), are derived and analyzed. Numerically results are provided to show the propagation characteristics of the proposed ISAC channel model. Finally, the proposed model is validated via the agreement between theoretical and simulated as well as measurement results.