 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Compact Implicit Neural Representation for Efficient Storage of Massive 4D Functional Magnetic Resonance Imaging
Nov 30, 2023Functional Magnetic Resonance Imaging (fMRI) data is a kind of widely used four-dimensional biomedical data, demanding effective compression but presenting unique challenges for compression due to its intricate temporal dynamics, low signal-to-noise ratio, and complicated underlying redundancies. This paper reports a novel compression paradigm specifically tailored for fMRI data based on Implicit Neural Representation (INR). The proposed approach focuses on removing the various redundancies among the time series, including (i) conducting spatial correlation modeling for intra-region dynamics, (ii) decomposing reusable neuronal activation patterns, and using proper initialization together with nonlinear fusion to describe the inter-region similarity. The above scheme properly incorporates the unique features of fMRI data, and experimental results on publicly available datasets demonstrate the effectiveness of the proposed method, surpassing state-of-the-art algorithms in both conventional image quality evaluation metrics and fMRI downstream tasks. This work in this paper paves the way for sharing massive fMRI data at low bandwidth and high fidelity.
CausalTime: Realistically Generated Time-series for Benchmarking of Causal Discovery
Oct 03, 2023Time-series causal discovery (TSCD) is a fundamental problem of machine learning. However, existing synthetic datasets cannot properly evaluate or predict the algorithms' performance on real data. This study introduces the CausalTime pipeline to generate time-series that highly resemble the real data and with ground truth causal graphs for quantitative performance evaluation. The pipeline starts from real observations in a specific scenario and produces a matching benchmark dataset. Firstly, we harness deep neural networks along with normalizing flow to accurately capture realistic dynamics. Secondly, we extract hypothesized causal graphs by performing importance analysis on the neural network or leveraging prior knowledge. Thirdly, we derive the ground truth causal graphs by splitting the causal model into causal term, residual term, and noise term. Lastly, using the fitted network and the derived causal graph, we generate corresponding versatile time-series proper for algorithm assessment. In the experiments, we validate the fidelity of the generated data through qualitative and quantitative experiments, followed by a benchmarking of existing TSCD algorithms using these generated datasets. CausalTime offers a feasible solution to evaluating TSCD algorithms in real applications and can be generalized to a wide range of fields. For easy use of the proposed approach, we also provide a user-friendly website, hosted on www.causaltime.cc.
HOPE: High-order Polynomial Expansion of Black-box Neural Networks
Jul 17, 2023



Despite their remarkable performance, deep neural networks remain mostly ``black boxes'', suggesting inexplicability and hindering their wide applications in fields requiring making rational decisions. Here we introduce HOPE (High-order Polynomial Expansion), a method for expanding a network into a high-order Taylor polynomial on a reference input. Specifically, we derive the high-order derivative rule for composite functions and extend the rule to neural networks to obtain their high-order derivatives quickly and accurately. From these derivatives, we can then derive the Taylor polynomial of the neural network, which provides an explicit expression of the network's local interpretations. Numerical analysis confirms the high accuracy, low computational complexity, and good convergence of the proposed method. Moreover, we demonstrate HOPE's wide applications built on deep learning, including function discovery, fast inference, and feature selection. The code is available at https://github.com/HarryPotterXTX/HOPE.git.
SHoP: A Deep Learning Framework for Solving High-order Partial Differential Equations
May 17, 2023Solving partial differential equations (PDEs) has been a fundamental problem in computational science and of wide applications for both scientific and engineering research. Due to its universal approximation property, neural network is widely used to approximate the solutions of PDEs. However, existing works are incapable of solving high-order PDEs due to insufficient calculation accuracy of higher-order derivatives, and the final network is a black box without explicit explanation. To address these issues, we propose a deep learning framework to solve high-order PDEs, named SHoP. Specifically, we derive the high-order derivative rule for neural network, to get the derivatives quickly and accurately; moreover, we expand the network into a Taylor series, providing an explicit solution for the PDEs. We conduct experimental validations four high-order PDEs with different dimensions, showing that we can solve high-order PDEs efficiently and accurately.
CUTS+: High-dimensional Causal Discovery from Irregular Time-series
May 10, 2023



Causal discovery in time-series is a fundamental problem in the machine learning community, enabling causal reasoning and decision-making in complex scenarios. Recently, researchers successfully discover causality by combining neural networks with Granger causality, but their performances degrade largely when encountering high-dimensional data because of the highly redundant network design and huge causal graphs. Moreover, the missing entries in the observations further hamper the causal structural learning. To overcome these limitations, We propose CUTS+, which is built on the Granger-causality-based causal discovery method CUTS and raises the scalability by introducing a technique called Coarse-to-fine-discovery (C2FD) and leveraging a message-passing-based graph neural network (MPGNN). Compared to previous methods on simulated, quasi-real, and real datasets, we show that CUTS+ largely improves the causal discovery performance on high-dimensional data with different types of irregular sampling.
CUTS: Neural Causal Discovery from Irregular Time-Series Data
Feb 15, 2023Causal discovery from time-series data has been a central task in machine learning. Recently, Granger causality inference is gaining momentum due to its good explainability and high compatibility with emerging deep neural networks. However, most existing methods assume structured input data and degenerate greatly when encountering data with randomly missing entries or non-uniform sampling frequencies, which hampers their applications in real scenarios. To address this issue, here we present CUTS, a neural Granger causal discovery algorithm to jointly impute unobserved data points and build causal graphs, via plugging in two mutually boosting modules in an iterative framework: (i) Latent data prediction stage: designs a Delayed Supervision Graph Neural Network (DSGNN) to hallucinate and register unstructured data which might be of high dimension and with complex distribution; (ii) Causal graph fitting stage: builds a causal adjacency matrix with imputed data under sparse penalty. Experiments show that CUTS effectively infers causal graphs from unstructured time-series data, with significantly superior performance to existing methods. Our approach constitutes a promising step towards applying causal discovery to real applications with non-ideal observations.
* https://openreview.net/forum?id=UG8bQcD3Emv
TINC: Tree-structured Implicit Neural Compression
Nov 17, 2022Implicit neural representation (INR) can describe the target scenes with high fidelity using a small number of parameters, and is emerging as a promising data compression technique. However, INR in intrinsically of limited spectrum coverage, and it is non-trivial to remove redundancy in diverse complex data effectively. Preliminary studies can only exploit either global or local correlation in the target data and thus of limited performance. In this paper, we propose a Tree-structured Implicit Neural Compression (TINC) to conduct compact representation for local regions and extract the shared features of these local representations in a hierarchical manner. Specifically, we use MLPs to fit the partitioned local regions, and these MLPs are organized in tree structure to share parameters according to the spatial distance. The parameter sharing scheme not only ensures the continuity between adjacent regions, but also jointly removes the local and non-local redundancy. Extensive experiments show that TINC improves the compression fidelity of INR, and has shown impressive compression capabilities over commercial tools and other deep learning based methods. Besides, the approach is of high flexibility and can be tailored for different data and parameter settings. All the reproducible codes are going to be released on github.
SCI: A spectrum concentrated implicit neural compression for biomedical data
Sep 30, 2022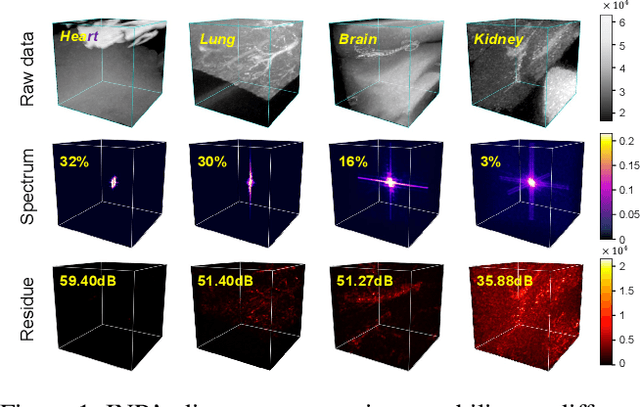
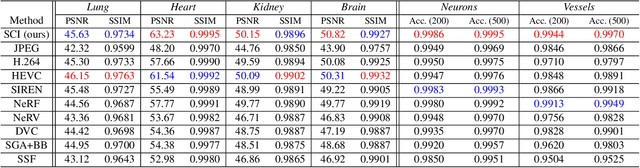
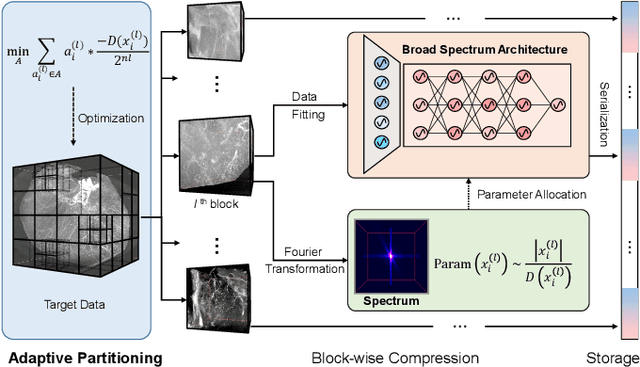
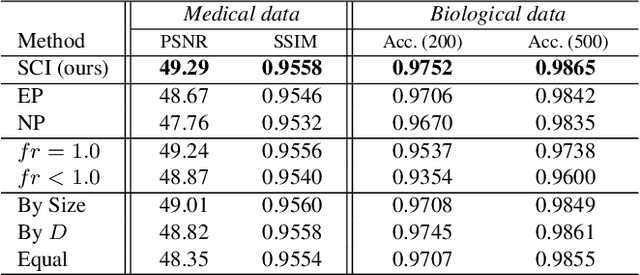
Massive collection and explosive growth of the huge amount of medical data, demands effective compression for efficient storage, transmission and sharing. Readily available visual data compression techniques have been studied extensively but tailored for nature images/videos, and thus show limited performance on medical data which are of different characteristics. Emerging implicit neural representation (INR) is gaining momentum and demonstrates high promise for fitting diverse visual data in target-data-specific manner, but a general compression scheme covering diverse medical data is so far absent. To address this issue, we firstly derive a mathematical explanation for INR's spectrum concentration property and an analytical insight on the design of compression-oriented INR architecture. Further, we design a funnel shaped neural network capable of covering broad spectrum of complex medical data and achieving high compression ratio. Based on this design, we conduct compression via optimization under given budget and propose an adaptive compression approach SCI, which adaptively partitions the target data into blocks matching the concentrated spectrum envelop of the adopted INR, and allocates parameter with high representation accuracy under given compression ratio. The experiments show SCI's superior performance over conventional techniques and wide applicability across diverse medical data.