 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Actuator Trajectory Planning for UAVs with Overhead Manipulator using Reinforcement Learning
Aug 24, 2023

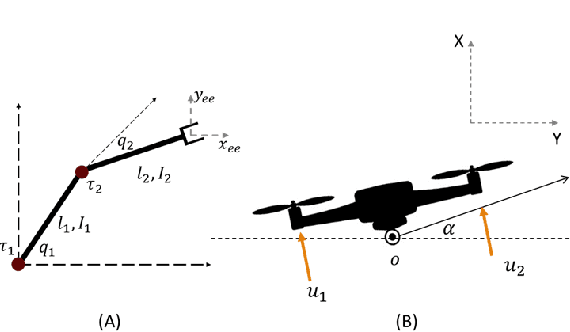
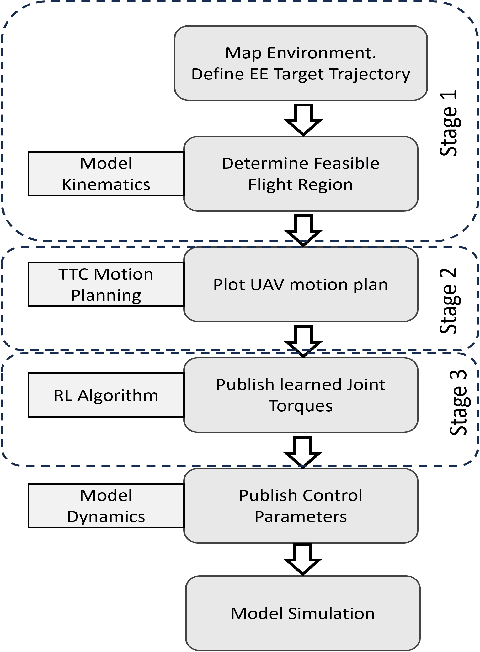
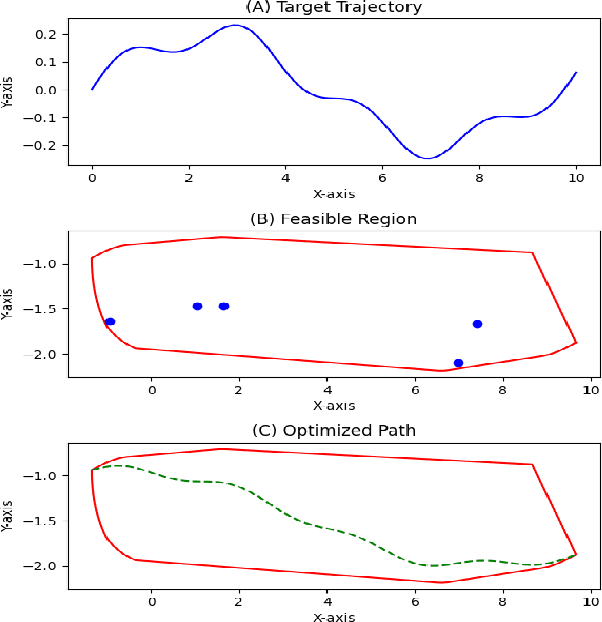
In this paper, we investigate the operation of an aerial manipulator system, namely an Unmanned Aerial Vehicle (UAV) equipped with a controllable arm with two degrees of freedom to carry out actuation tasks on the fly. Our solution is based on employing a Q-learning method to control the trajectory of the tip of the arm, also called \textit{end-effector}. More specifically, we develop a motion planning model based on Time To Collision (TTC), which enables a quadrotor UAV to navigate around obstacles while ensuring the manipulator's reachability. Additionally, we utilize a model-based Q-learning model to independently track and control the desired trajectory of the manipulator's end-effector, given an arbitrary baseline trajectory for the UAV platform. Such a combination enables a variety of actuation tasks such as high-altitude welding, structural monitoring and repair, battery replacement, gutter cleaning, sky scrapper cleaning, and power line maintenance in hard-to-reach and risky environments while retaining compatibility with flight control firmware. Our RL-based control mechanism results in a robust control strategy that can handle uncertainties in the motion of the UAV, offering promising performance. Specifically, our method achieves 92\% accuracy in terms of average displacement error (i.e. the mean distance between the target and obtained trajectory points) using Q-learning with 15,000 episodes
Efficient Joint Optimization of Layer-Adaptive Weight Pruning in Deep Neural Networks
Aug 24, 2023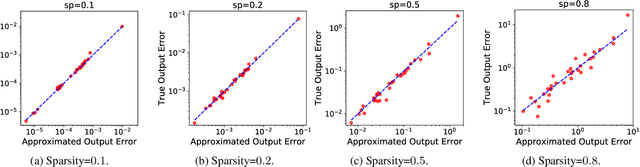
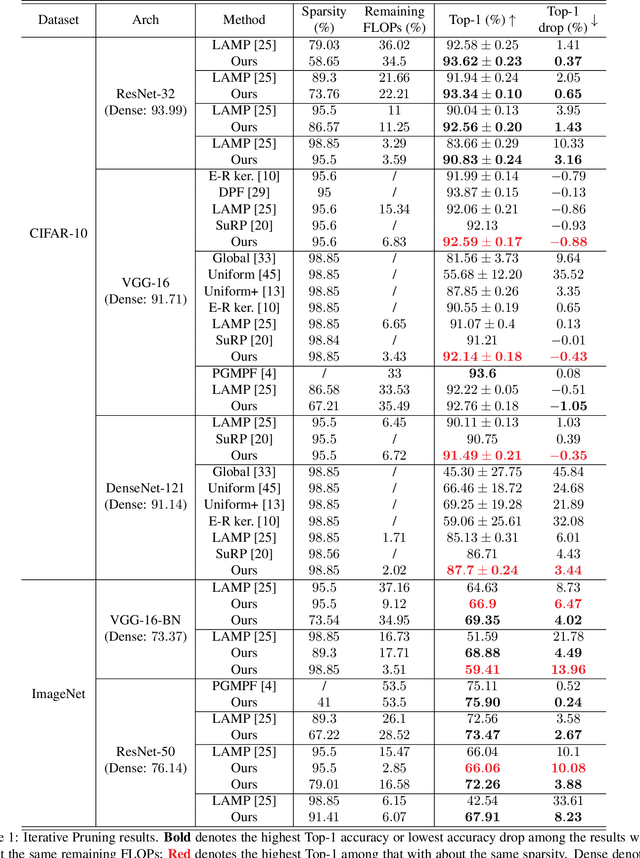
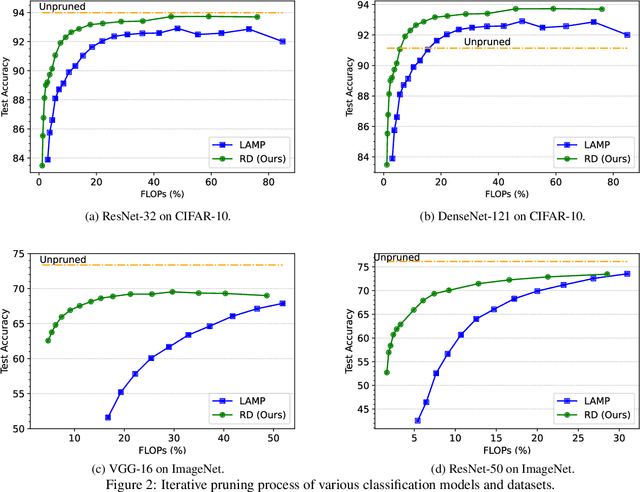
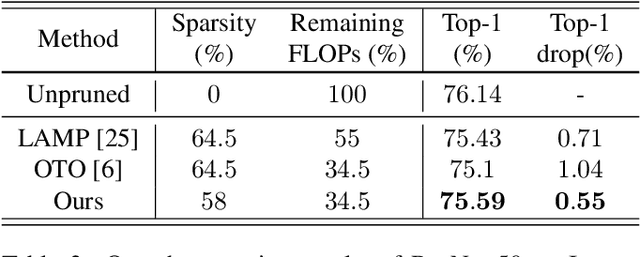
In this paper, we propose a novel layer-adaptive weight-pruning approach for Deep Neural Networks (DNNs) that addresses the challenge of optimizing the output distortion minimization while adhering to a target pruning ratio constraint. Our approach takes into account the collective influence of all layers to design a layer-adaptive pruning scheme. We discover and utilize a very important additivity property of output distortion caused by pruning weights on multiple layers. This property enables us to formulate the pruning as a combinatorial optimization problem and efficiently solve it through dynamic programming. By decomposing the problem into sub-problems, we achieve linear time complexity, making our optimization algorithm fast and feasible to run on CPUs. Our extensive experiments demonstrate the superiority of our approach over existing methods on the ImageNet and CIFAR-10 datasets. On CIFAR-10, our method achieves remarkable improvements, outperforming others by up to 1.0% for ResNet-32, 0.5% for VGG-16, and 0.7% for DenseNet-121 in terms of top-1 accuracy. On ImageNet, we achieve up to 4.7% and 4.6% higher top-1 accuracy compared to other methods for VGG-16 and ResNet-50, respectively. These results highlight the effectiveness and practicality of our approach for enhancing DNN performance through layer-adaptive weight pruning. Code will be available on https://github.com/Akimoto-Cris/RD_VIT_PRUNE.
Motion In-Betweening with Phase Manifolds
Aug 24, 2023
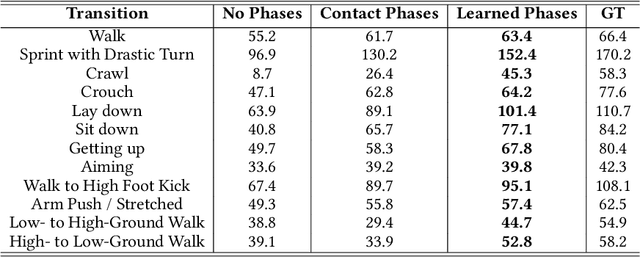
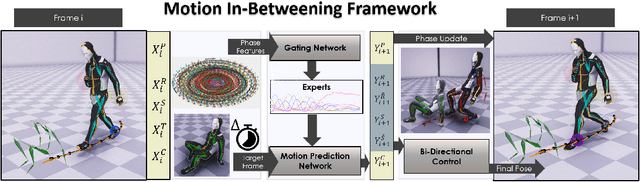

This paper introduces a novel data-driven motion in-betweening system to reach target poses of characters by making use of phases variables learned by a Periodic Autoencoder. Our approach utilizes a mixture-of-experts neural network model, in which the phases cluster movements in both space and time with different expert weights. Each generated set of weights then produces a sequence of poses in an autoregressive manner between the current and target state of the character. In addition, to satisfy poses which are manually modified by the animators or where certain end effectors serve as constraints to be reached by the animation, a learned bi-directional control scheme is implemented to satisfy such constraints. The results demonstrate that using phases for motion in-betweening tasks sharpen the interpolated movements, and furthermore stabilizes the learning process. Moreover, using phases for motion in-betweening tasks can also synthesize more challenging movements beyond locomotion behaviors. Additionally, style control is enabled between given target keyframes. Our proposed framework can compete with popular state-of-the-art methods for motion in-betweening in terms of motion quality and generalization, especially in the existence of long transition durations. Our framework contributes to faster prototyping workflows for creating animated character sequences, which is of enormous interest for the game and film industry.
* 17 pages, 11 figures, conference
Evolutionary Dynamic Optimization Laboratory: A MATLAB Optimization Platform for Education and Experimentation in Dynamic Environments
Aug 24, 2023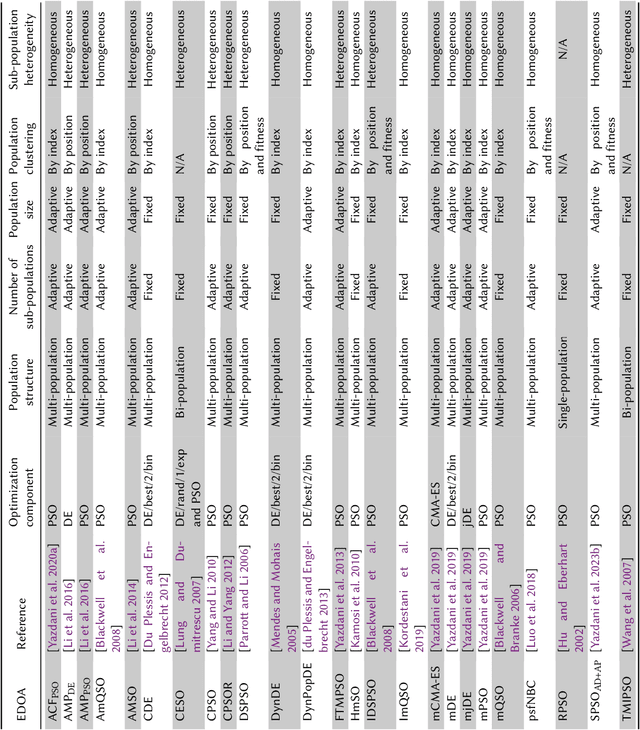
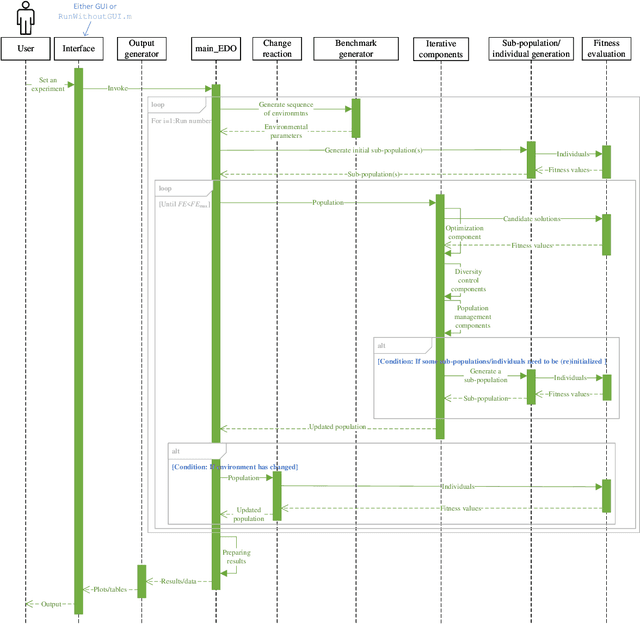
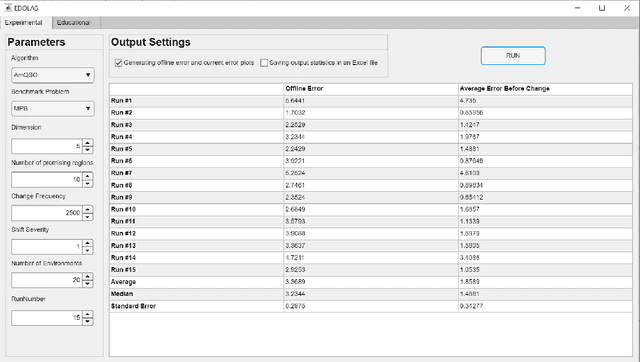

Many real-world optimization problems possess dynamic characteristics. Evolutionary dynamic optimization algorithms (EDOAs) aim to tackle the challenges associated with dynamic optimization problems. Looking at the existing works, the results reported for a given EDOA can sometimes be considerably different. This issue occurs because the source codes of many EDOAs, which are usually very complex algorithms, have not been made publicly available. Indeed, the complexity of components and mechanisms used in many EDOAs makes their re-implementation error-prone. In this paper, to assist researchers in performing experiments and comparing their algorithms against several EDOAs, we develop an open-source MATLAB platform for EDOAs, called Evolutionary Dynamic Optimization LABoratory (EDOLAB). This platform also contains an education module that can be used for educational purposes. In the education module, the user can observe a) a 2-dimensional problem space and how its morphology changes after each environmental change, b) the behaviors of individuals over time, and c) how the EDOA reacts to environmental changes and tries to track the moving optimum. In addition to being useful for research and education purposes, EDOLAB can also be used by practitioners to solve their real-world problems. The current version of EDOLAB includes 25 EDOAs and three fully-parametric benchmark generators. The MATLAB source code for EDOLAB is publicly available and can be accessed from [https://github.com/EDOLAB-platform/EDOLAB-MATLAB].
Selective Concept Models: Permitting Stakeholder Customisation at Test-Time
Jun 14, 2023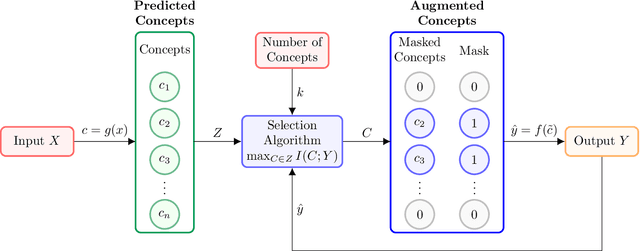
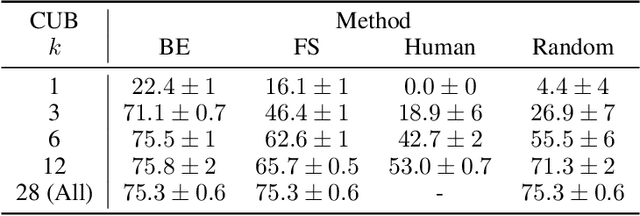
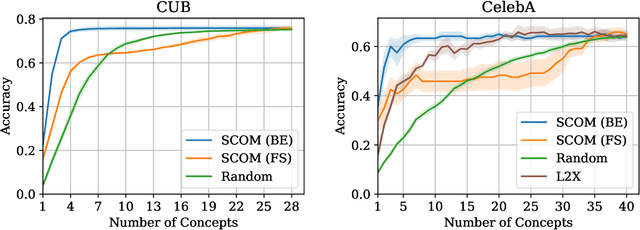

Concept-based models perform prediction using a set of concepts that are interpretable to stakeholders. However, such models often involve a fixed, large number of concepts, which may place a substantial cognitive load on stakeholders. We propose Selective COncept Models (SCOMs) which make predictions using only a subset of concepts and can be customised by stakeholders at test-time according to their preferences. We show that SCOMs only require a fraction of the total concepts to achieve optimal accuracy on multiple real-world datasets. Further, we collect and release a new dataset, CUB-Sel, consisting of human concept set selections for 900 bird images from the popular CUB dataset. Using CUB-Sel, we show that humans have unique individual preferences for the choice of concepts they prefer to reason about, and struggle to identify the most theoretically informative concepts. The customisation and concept selection provided by SCOM improves the efficiency of interpretation and intervention for stakeholders.
Dynamic Mode Decomposition for data-driven analysis and reduced-order modelling of ExB plasmas: I. Extraction of spatiotemporally coherent patterns
Aug 26, 2023
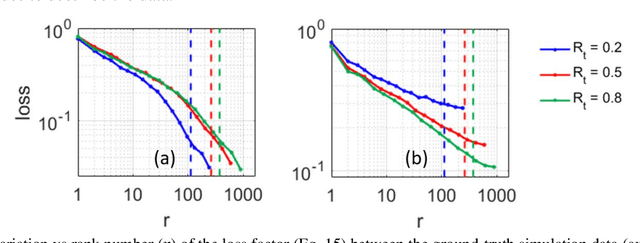
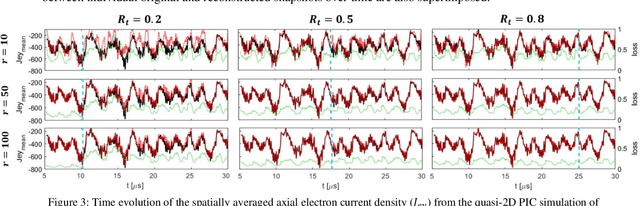
In this two-part article, we evaluate the utility and the generalizability of the Dynamic Mode Decomposition (DMD) algorithm for data-driven analysis and reduced-order modelling of plasma dynamics in cross-field ExB configurations. The DMD algorithm is an interpretable data-driven method that finds a best-fit linear model describing the time evolution of spatiotemporally coherent structures (patterns) in data. We have applied the DMD to extensive high-fidelity datasets generated using a particle-in-cell (PIC) code based on a cost-efficient reduced-order PIC scheme. In this part, we first provide an overview of the concept of DMD and its underpinning Proper Orthogonal and Singular Value Decomposition methods. Two of the main DMD variants are next introduced. We then present and discuss the results of the DMD application in terms of the identification and extraction of the dominant spatiotemporal modes from high-fidelity data over a range of simulation conditions. We demonstrate that the DMD variant based on variable projection optimization (OPT-DMD) outperforms the basic DMD method in identification of the modes underlying the data, leading to notably more reliable reconstruction of the ground-truth. Furthermore, we show in multiple test cases that the discrete frequency spectrum of OPT-DMD-extracted modes is consistent with the temporal spectrum from the Fast Fourier Transform of the data. This observation implies that the OPT-DMD augments the conventional spectral analyses by being able to uniquely reveal the spatial structure of the dominant modes in the frequency spectra, thus, yielding more accessible, comprehensive information on the spatiotemporal characteristics of the plasma phenomena.
Graph Edit Distance Learning via Different Attention
Aug 26, 2023Recently, more and more research has focused on using Graph Neural Networks (GNN) to solve the Graph Similarity Computation problem (GSC), i.e., computing the Graph Edit Distance (GED) between two graphs. These methods treat GSC as an end-to-end learnable task, and the core of their architecture is the feature fusion modules to interact with the features of two graphs. Existing methods consider that graph-level embedding is difficult to capture the differences in local small structures between two graphs, and thus perform fine-grained feature fusion on node-level embedding can improve the accuracy, but leads to greater time and memory consumption in the training and inference phases. However, this paper proposes a novel graph-level fusion module Different Attention (DiffAtt), and demonstrates that graph-level fusion embeddings can substantially outperform these complex node-level fusion embeddings. We posit that the relative difference structure of the two graphs plays an important role in calculating their GED values. To this end, DiffAtt uses the difference between two graph-level embeddings as an attentional mechanism to capture the graph structural difference of the two graphs. Based on DiffAtt, a new GSC method, named Graph Edit Distance Learning via Different Attention (REDRAFT), is proposed, and experimental results demonstrate that REDRAFT achieves state-of-the-art performance in 23 out of 25 metrics in five benchmark datasets. Especially on MSE, it respectively outperforms the second best by 19.9%, 48.8%, 29.1%, 31.6%, and 2.2%. Moreover, we propose a quantitative test Remaining Subgraph Alignment Test (RESAT) to verify that among all graph-level fusion modules, the fusion embedding generated by DiffAtt can best capture the structural differences between two graphs.
Online Transition-Based Feature Generation for Anomaly Detection in Concurrent Data Streams
Aug 17, 2023In this paper, we introduce the transition-based feature generator (TFGen) technique, which reads general activity data with attributes and generates step-by-step generated data. The activity data may consist of network activity from packets, system calls from processes or classified activity from surveillance cameras. TFGen processes data online and will generate data with encoded historical data for each incoming activity with high computational efficiency. The input activities may concurrently originate from distinct traces or channels. The technique aims to address issues such as domain-independent applicability, the ability to discover global process structures, the encoding of time-series data, and online processing capability.
Causal discovery for time series with constraint-based model and PMIME measure
May 31, 2023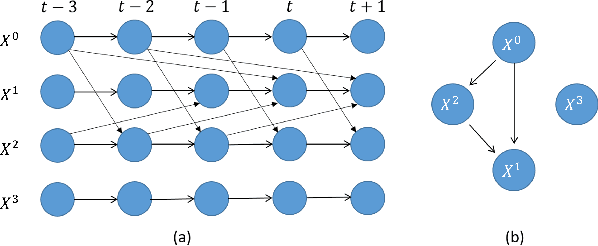
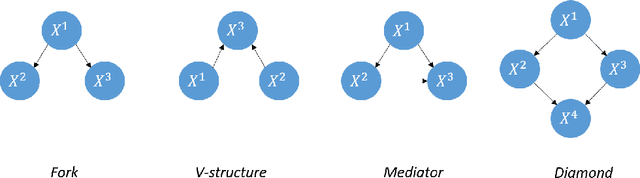
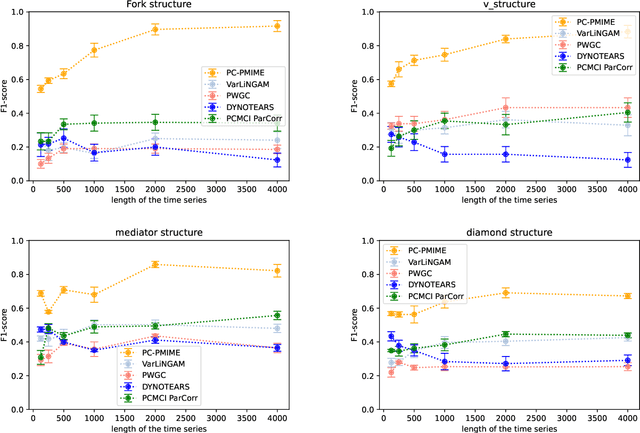
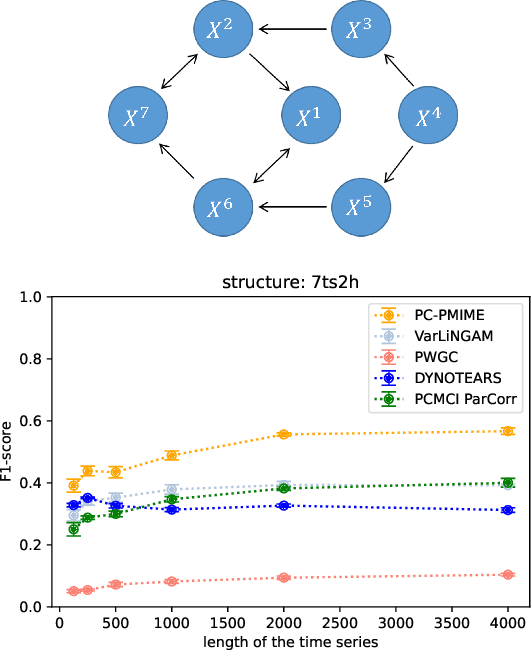
Causality defines the relationship between cause and effect. In multivariate time series field, this notion allows to characterize the links between several time series considering temporal lags. These phenomena are particularly important in medicine to analyze the effect of a drug for example, in manufacturing to detect the causes of an anomaly in a complex system or in social sciences... Most of the time, studying these complex systems is made through correlation only. But correlation can lead to spurious relationships. To circumvent this problem, we present in this paper a novel approach for discovering causality in time series data that combines a causal discovery algorithm with an information theoretic-based measure. Hence the proposed method allows inferring both linear and non-linear relationships and building the underlying causal graph. We evaluate the performance of our approach on several simulated data sets, showing promising results.
TS-MoCo: Time-Series Momentum Contrast for Self-Supervised Physiological Representation Learning
Jun 10, 2023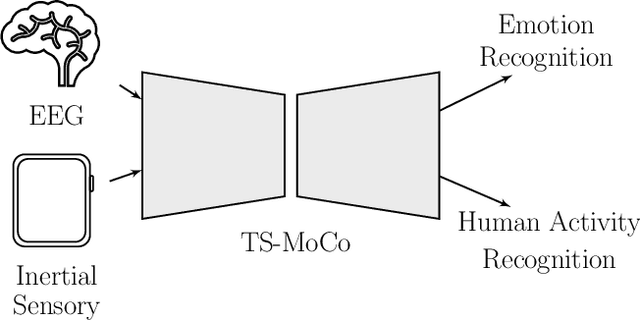

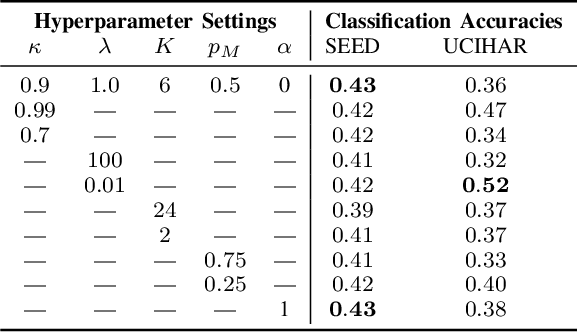
Limited availability of labeled physiological data often prohibits the use of powerful supervised deep learning models in the biomedical machine intelligence domain. We approach this problem and propose a novel encoding framework that relies on self-supervised learning with momentum contrast to learn representations from multivariate time-series of various physiological domains without needing labels. Our model uses a transformer architecture that can be easily adapted to classification problems by optimizing a linear output classification layer. We experimentally evaluate our framework using two publicly available physiological datasets from different domains, i.e., human activity recognition from embedded inertial sensory and emotion recognition from electroencephalography. We show that our self-supervised learning approach can indeed learn discriminative features which can be exploited in downstream classification tasks. Our work enables the development of domain-agnostic intelligent systems that can effectively analyze multivariate time-series data from physiological domains.