 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Pay Attention to the Atlas: Atlas-Guided Test-Time Adaptation Method for Robust 3D Medical Image Segmentation
Jul 02, 2023
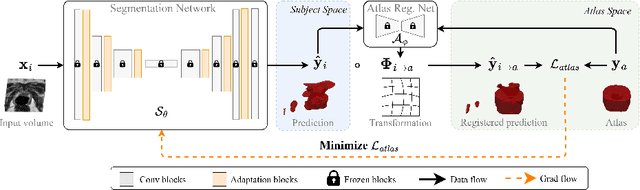
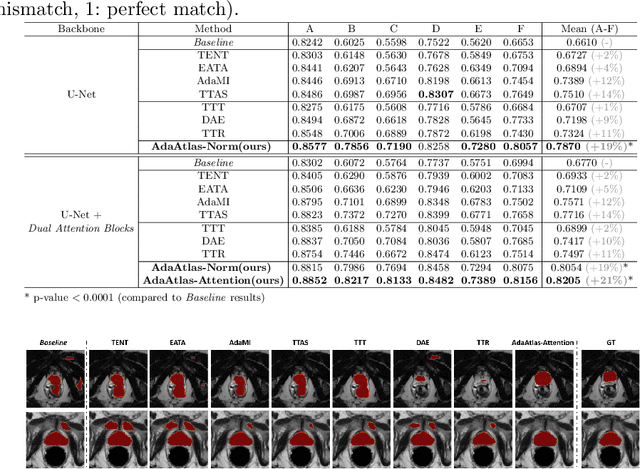


Convolutional neural networks (CNNs) often suffer from poor performance when tested on target data that differs from the training (source) data distribution, particularly in medical imaging applications where variations in imaging protocols across different clinical sites and scanners lead to different imaging appearances. However, re-accessing source training data for unsupervised domain adaptation or labeling additional test data for model fine-tuning can be difficult due to privacy issues and high labeling costs, respectively. To solve this problem, we propose a novel atlas-guided test-time adaptation (TTA) method for robust 3D medical image segmentation, called AdaAtlas. AdaAtlas only takes one single unlabeled test sample as input and adapts the segmentation network by minimizing an atlas-based loss. Specifically, the network is adapted so that its prediction after registration is aligned with the learned atlas in the atlas space, which helps to reduce anatomical segmentation errors at test time. In addition, different from most existing TTA methods which restrict the adaptation to batch normalization blocks in the segmentation network only, we further exploit the use of channel and spatial attention blocks for improved adaptability at test time. Extensive experiments on multiple datasets from different sites show that AdaAtlas with attention blocks adapted (AdaAtlas-Attention) achieves superior performance improvements, greatly outperforming other competitive TTA methods.
Stochastic Configuration Machines for Industrial Artificial Intelligence
Aug 31, 2023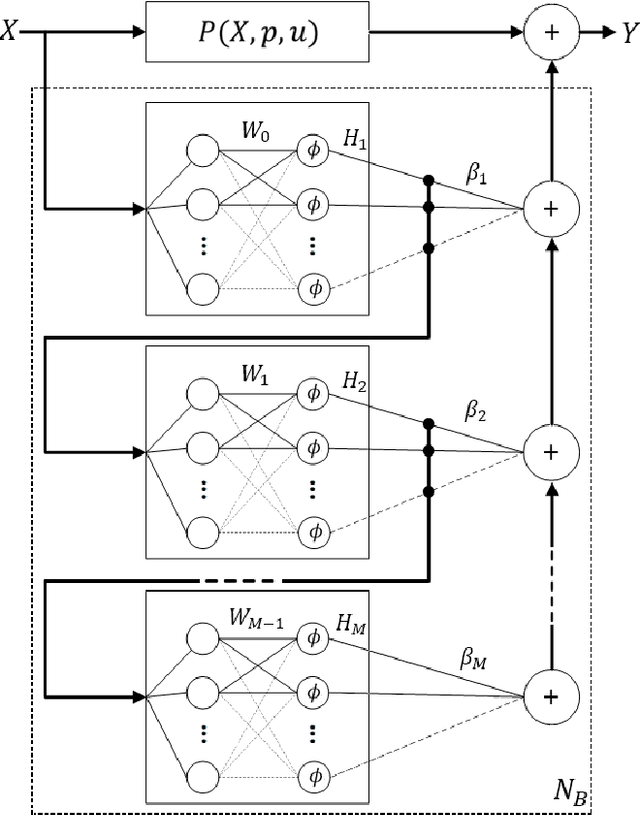
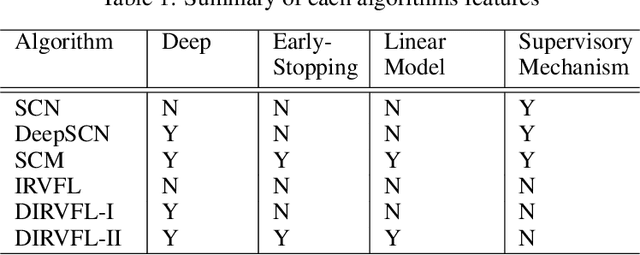
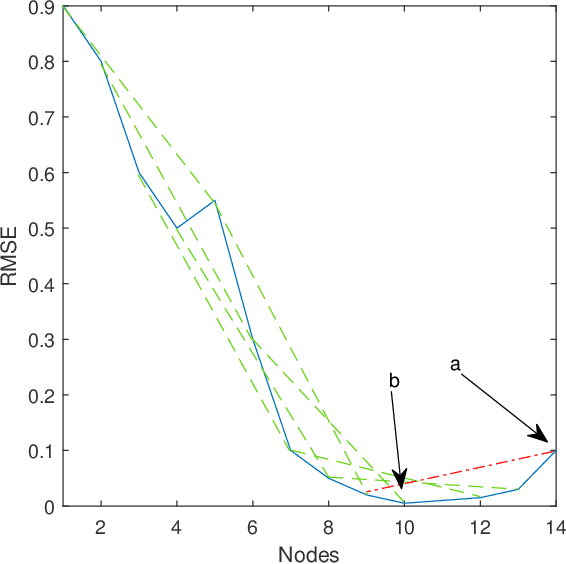
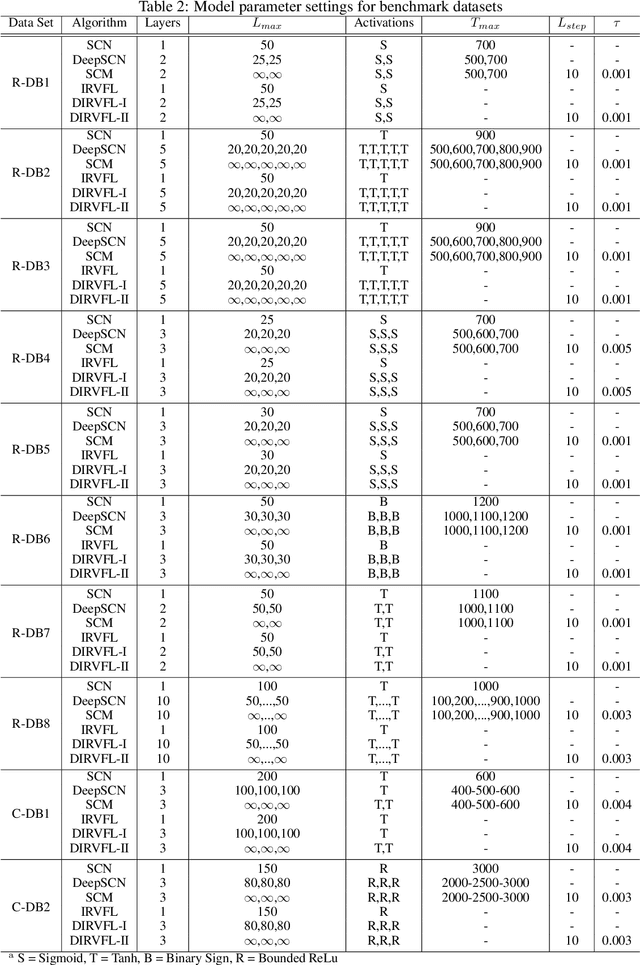
Real-time predictive modelling with desired accuracy is highly expected in industrial artificial intelligence (IAI), where neural networks play a key role. Neural networks in IAI require powerful, high-performance computing devices to operate a large number of floating point data. Based on stochastic configuration networks (SCNs), this paper proposes a new randomized learner model, termed stochastic configuration machines (SCMs), to stress effective modelling and data size saving that are useful and valuable for industrial applications. Compared to SCNs and random vector functional-link (RVFL) nets with binarized implementation, the model storage of SCMs can be significantly compressed while retaining favourable prediction performance. Besides the architecture of the SCM learner model and its learning algorithm, as an important part of this contribution, we also provide a theoretical basis on the learning capacity of SCMs by analysing the model's complexity. Experimental studies are carried out over some benchmark datasets and three industrial applications. The results demonstrate that SCM has great potential for dealing with industrial data analytics.
The Smart Data Extractor, a Clinician Friendly Solution to Accelerate and Improve the Data Collection During Clinical Trials
Aug 31, 2023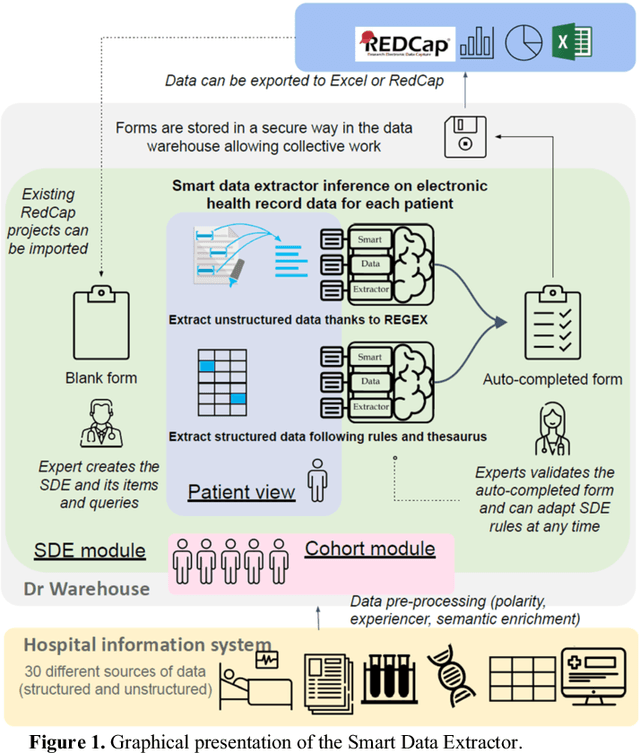
In medical research, the traditional way to collect data, i.e. browsing patient files, has been proven to induce bias, errors, human labor and costs. We propose a semi-automated system able to extract every type of data, including notes. The Smart Data Extractor pre-populates clinic research forms by following rules. We performed a cross-testing experiment to compare semi-automated to manual data collection. 20 target items had to be collected for 79 patients. The average time to complete one form was 6'81'' for manual data collection and 3'22'' with the Smart Data Extractor. There were also more mistakes during manual data collection (163 for the whole cohort) than with the Smart Data Extractor (46 for the whole cohort). We present an easy to use, understandable and agile solution to fill out clinical research forms. It reduces human effort and provides higher quality data, avoiding data re-entry and fatigue induced errors.
Conditioning Score-Based Generative Models by Neuro-Symbolic Constraints
Aug 31, 2023
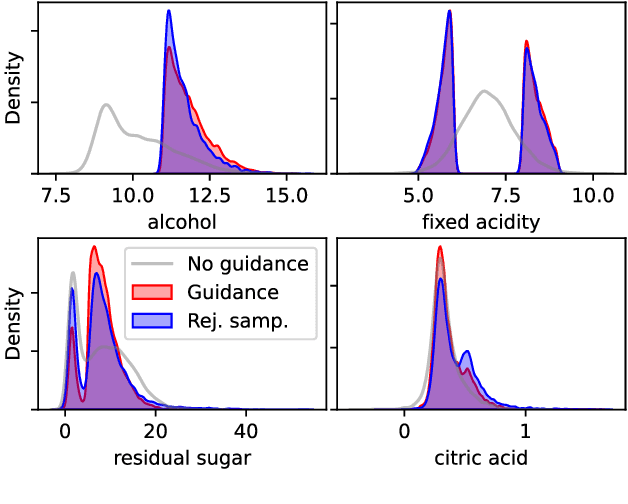

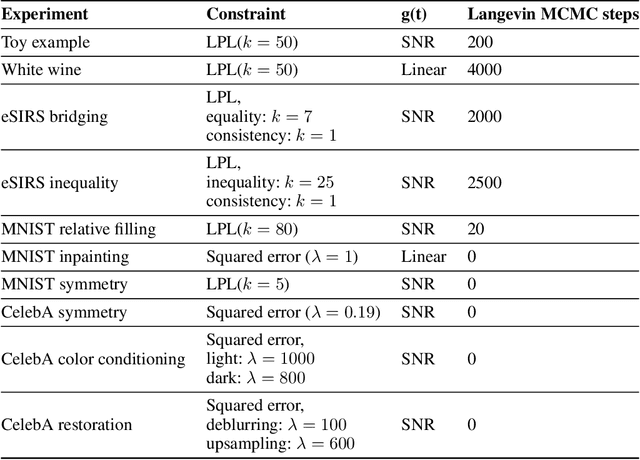
Score-based and diffusion models have emerged as effective approaches for both conditional and unconditional generation. Still conditional generation is based on either a specific training of a conditional model or classifier guidance, which requires training a noise-dependent classifier, even when the classifier for uncorrupted data is given. We propose an approach to sample from unconditional score-based generative models enforcing arbitrary logical constraints, without any additional training. Firstly, we show how to manipulate the learned score in order to sample from an un-normalized distribution conditional on a user-defined constraint. Then, we define a flexible and numerically stable neuro-symbolic framework for encoding soft logical constraints. Combining these two ingredients we obtain a general, but approximate, conditional sampling algorithm. We further developed effective heuristics aimed at improving the approximation. Finally, we show the effectiveness of our approach for various types of constraints and data: tabular data, images and time series.
BenchTemp: A General Benchmark for Evaluating Temporal Graph Neural Networks
Aug 31, 2023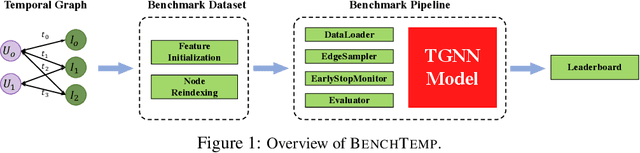

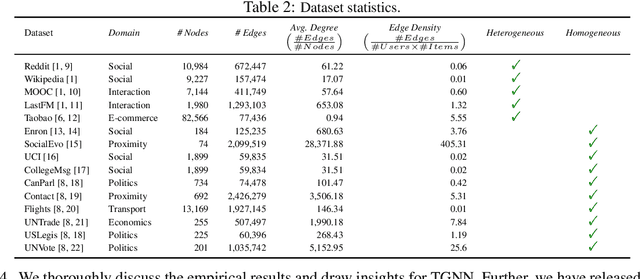
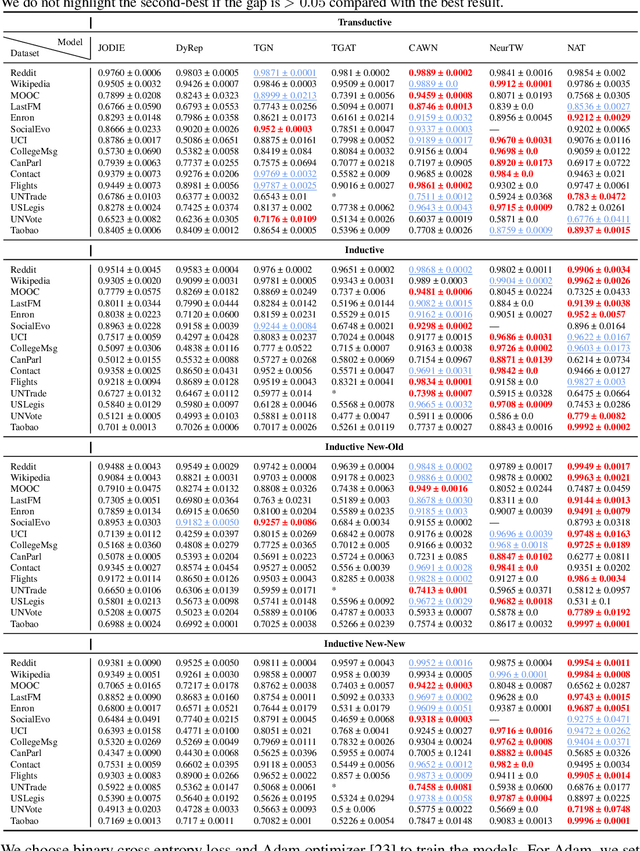
To handle graphs in which features or connectivities are evolving over time, a series of temporal graph neural networks (TGNNs) have been proposed. Despite the success of these TGNNs, the previous TGNN evaluations reveal several limitations regarding four critical issues: 1) inconsistent datasets, 2) inconsistent evaluation pipelines, 3) lacking workload diversity, and 4) lacking efficient comparison. Overall, there lacks an empirical study that puts TGNN models onto the same ground and compares them comprehensively. To this end, we propose BenchTemp, a general benchmark for evaluating TGNN models on various workloads. BenchTemp provides a set of benchmark datasets so that different TGNN models can be fairly compared. Further, BenchTemp engineers a standard pipeline that unifies the TGNN evaluation. With BenchTemp, we extensively compare the representative TGNN models on different tasks (e.g., link prediction and node classification) and settings (transductive and inductive), w.r.t. both effectiveness and efficiency metrics. We have made BenchTemp publicly available at https://github.com/qianghuangwhu/benchtemp.
Temporal-spatial model via Trend Filtering
Aug 31, 2023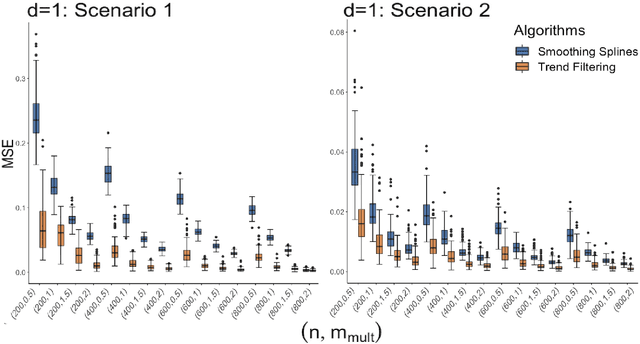
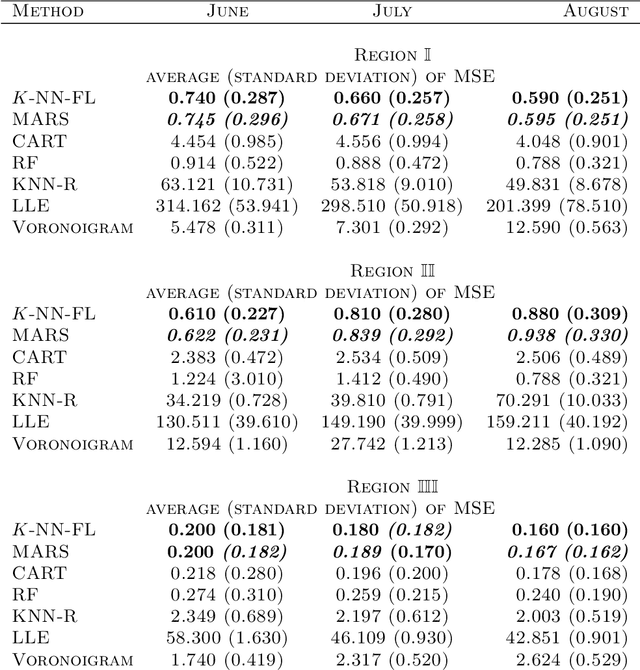
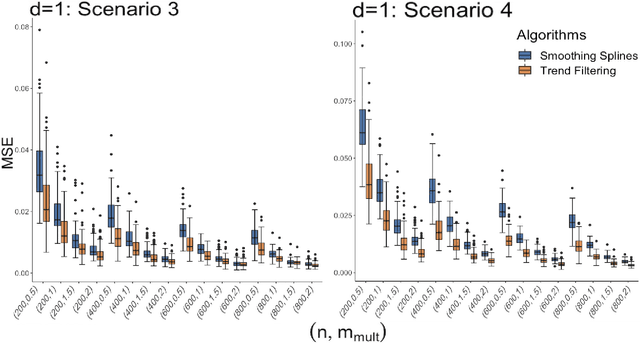
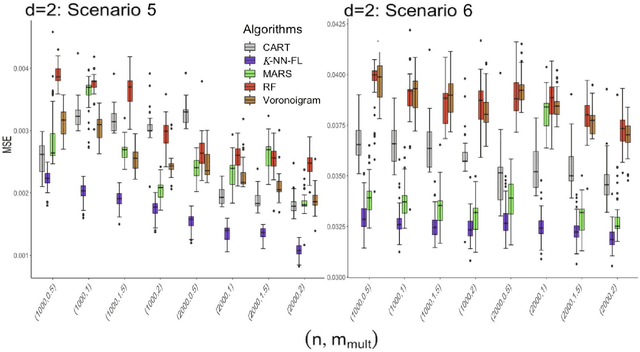
This research focuses on the estimation of a non-parametric regression function designed for data with simultaneous time and space dependencies. In such a context, we study the Trend Filtering, a nonparametric estimator introduced by \cite{mammen1997locally} and \cite{rudin1992nonlinear}. For univariate settings, the signals we consider are assumed to have a kth weak derivative with bounded total variation, allowing for a general degree of smoothness. In the multivariate scenario, we study a $K$-Nearest Neighbor fused lasso estimator as in \cite{padilla2018adaptive}, employing an ADMM algorithm, suitable for signals with bounded variation that adhere to a piecewise Lipschitz continuity criterion. By aligning with lower bounds, the minimax optimality of our estimators is validated. A unique phase transition phenomenon, previously uncharted in Trend Filtering studies, emerges through our analysis. Both Simulation studies and real data applications underscore the superior performance of our method when compared with established techniques in the existing literature.
Sequential Pitch Distributions for Raga Detection
Aug 31, 2023Raga is a fundamental melodic concept in Indian Art Music (IAM). It is characterized by complex patterns. All performances and compositions are based on the raga framework. Raga and tonic detection have been a long-standing research problem in the field of Music Information Retrieval. In this paper, we attempt to detect the raga using a novel feature to extract sequential or temporal information from an audio sample. We call these Sequential Pitch Distributions (SPD), which are distributions taken over pitch values between two given pitch values over time. We also achieve state-of-the-art results on both Hindustani and Carnatic music raga data sets with an accuracy of 99% and 88.13%, respectively. SPD gives a great boost in accuracy over a standard pitch distribution. The main goal of this paper, however, is to present an alternative approach to modeling the temporal aspects of the melody and thereby deducing the raga.
* 16 pages, 6 figures, AI Music Creativity
Leveraging Self-Supervised Vision Transformers for Neural Transfer Function Design
Sep 04, 2023In volume rendering, transfer functions are used to classify structures of interest, and to assign optical properties such as color and opacity. They are commonly defined as 1D or 2D functions that map simple features to these optical properties. As the process of designing a transfer function is typically tedious and unintuitive, several approaches have been proposed for their interactive specification. In this paper, we present a novel method to define transfer functions for volume rendering by leveraging the feature extraction capabilities of self-supervised pre-trained vision transformers. To design a transfer function, users simply select the structures of interest in a slice viewer, and our method automatically selects similar structures based on the high-level features extracted by the neural network. Contrary to previous learning-based transfer function approaches, our method does not require training of models and allows for quick inference, enabling an interactive exploration of the volume data. Our approach reduces the amount of necessary annotations by interactively informing the user about the current classification, so they can focus on annotating the structures of interest that still require annotation. In practice, this allows users to design transfer functions within seconds, instead of minutes. We compare our method to existing learning-based approaches in terms of annotation and compute time, as well as with respect to segmentation accuracy. Our accompanying video showcases the interactivity and effectiveness of our method.
Secure and Efficient Federated Learning in LEO Constellations using Decentralized Key Generation and On-Orbit Model Aggregation
Sep 04, 2023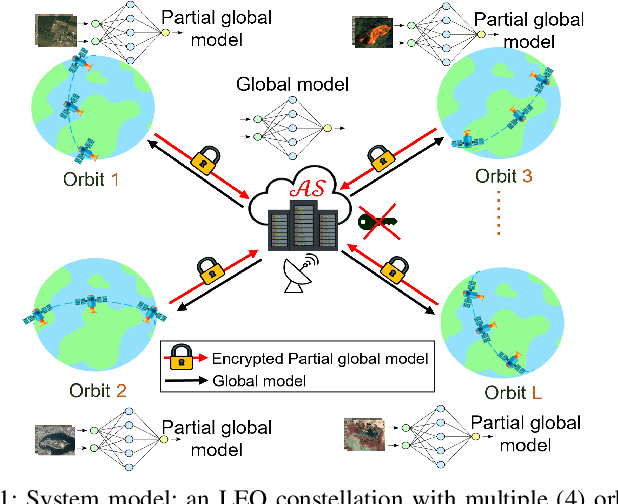
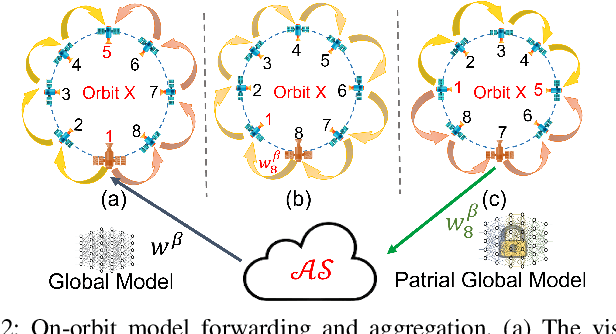
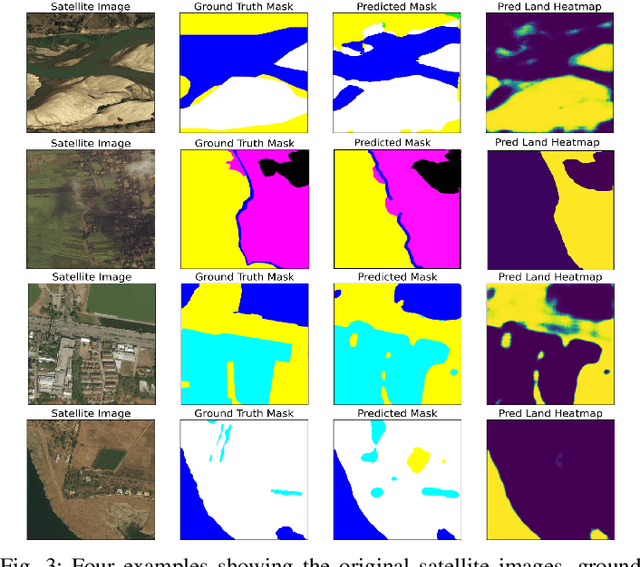

Satellite technologies have advanced drastically in recent years, leading to a heated interest in launching small satellites into low Earth orbit (LEOs) to collect massive data such as satellite imagery. Downloading these data to a ground station (GS) to perform centralized learning to build an AI model is not practical due to the limited and expensive bandwidth. Federated learning (FL) offers a potential solution but will incur a very large convergence delay due to the highly sporadic and irregular connectivity between LEO satellites and GS. In addition, there are significant security and privacy risks where eavesdroppers or curious servers/satellites may infer raw data from satellites' model parameters transmitted over insecure communication channels. To address these issues, this paper proposes FedSecure, a secure FL approach designed for LEO constellations, which consists of two novel components: (1) decentralized key generation that protects satellite data privacy using a functional encryption scheme, and (2) on-orbit model forwarding and aggregation that generates a partial global model per orbit to minimize the idle waiting time for invisible satellites to enter the visible zone of the GS. Our analysis and results show that FedSecure preserves the privacy of each satellite's data against eavesdroppers, a curious server, or curious satellites. It is lightweight with significantly lower communication and computation overheads than other privacy-preserving FL aggregation approaches. It also reduces convergence delay drastically from days to only a few hours, yet achieving high accuracy of up to 85.35% using realistic satellite images.
Computation and Communication Efficient Federated Learning over Wireless Networks
Sep 04, 2023Federated learning (FL) allows model training from local data by edge devices while preserving data privacy. However, the learning accuracy decreases due to the heterogeneity of devices data, and the computation and communication latency increase when updating large scale learning models on devices with limited computational capability and wireless resources. To overcome these challenges, we consider a novel FL framework with partial model pruning and personalization. This framework splits the learning model into a global part with model pruning shared with all devices to learn data representations and a personalized part to be fine tuned for a specific device, which adapts the model size during FL to reduce both computation and communication overhead and minimize the overall training time, and increases the learning accuracy for the device with non independent and identically distributed (non IID) data. Then, the computation and communication latency and the convergence analysis of the proposed FL framework are mathematically analyzed. Based on the convergence analysis, an optimization problem is formulated to maximize the convergence rate under a latency threshold by jointly optimizing the pruning ratio and wireless resource allocation. By decoupling the optimization problem and deploying Karush Kuhn Tucker (KKT) conditions, we derive the closed form solutions of pruning ratio and wireless resource allocation. Finally, experimental results demonstrate that the proposed FL framework achieves a remarkable reduction of approximately 50 percents computation and communication latency compared with the scheme only with model personalization.